Crop Insurance Premium Ratemaking Based on Survey Data: a Case Study from Dingxing County, China
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Evaluation of the Development of Rural Inclusive Finance: a Case Study of Baoding, Hebei Province
2018 4th International Conference on Economics, Management and Humanities Science(ECOMHS 2018) Evaluation of the Development of Rural Inclusive Finance: A Case Study of Baoding, Hebei province Ziqi Yang1, Xiaoxiao Li1 Hebei Finance University, Baoding, Hebei Province, China Keywords: inclusive finance; evaluation; rural inclusive finance; IFI index method Abstract: "Inclusive Finance", means that everyone has financial needs to access high-quality financial services at the right price in a timely and convenient manner with dignity. This paper uses IFI index method to evaluate the development level of rural inclusive finance in various counties of Baoding, Hebei province in 2016, and finds that rural inclusive finance in each country has a low level of development, banks and other financial institutions have few branches and product types, the farmers in that area have conservative financial concepts and rural financial service facilities are not perfect. In response to these problems, it is proposed to increase the development of inclusive finance; encourage financial innovation; establish financial concepts and cultivate financial needs; improve broadband coverage and accelerate the popularization of information. 1. Introduction "Inclusive Finance", means that everyone with financial needs to access high-quality financial services at the right price in a timely and convenient manner with dignity. This paper uses IFI index method to evaluate the development level of rural Inclusive Finance in various counties of Baoding, Hebei province -
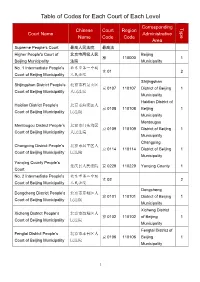
Table of Codes for Each Court of Each Level
Table of Codes for Each Court of Each Level Corresponding Type Chinese Court Region Court Name Administrative Name Code Code Area Supreme People’s Court 最高人民法院 最高法 Higher People's Court of 北京市高级人民 Beijing 京 110000 1 Beijing Municipality 法院 Municipality No. 1 Intermediate People's 北京市第一中级 京 01 2 Court of Beijing Municipality 人民法院 Shijingshan Shijingshan District People’s 北京市石景山区 京 0107 110107 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Haidian District of Haidian District People’s 北京市海淀区人 京 0108 110108 Beijing 1 Court of Beijing Municipality 民法院 Municipality Mentougou Mentougou District People’s 北京市门头沟区 京 0109 110109 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Changping Changping District People’s 北京市昌平区人 京 0114 110114 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Yanqing County People’s 延庆县人民法院 京 0229 110229 Yanqing County 1 Court No. 2 Intermediate People's 北京市第二中级 京 02 2 Court of Beijing Municipality 人民法院 Dongcheng Dongcheng District People’s 北京市东城区人 京 0101 110101 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Xicheng District Xicheng District People’s 北京市西城区人 京 0102 110102 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Fengtai District of Fengtai District People’s 北京市丰台区人 京 0106 110106 Beijing 1 Court of Beijing Municipality 民法院 Municipality 1 Fangshan District Fangshan District People’s 北京市房山区人 京 0111 110111 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Daxing District of Daxing District People’s 北京市大兴区人 京 0115 -

Social Monitoring Report
Social Monitoring Report Project Number: 36437 June 2012 PRC: Integrated Ecosystem and Water Resources Management in the Baiyangdian Basin Prepared by Hohai University For Hebei Baoding Baiyangdian Project Management Office This report has been submitted to ADB by the Hebei Baoding Baiyangdian Project Management Office and is made publicly available in accordance with ADB’s public communications policy (2005). It does not necessarily reflect the views of ADB . Integrated Ecosystem and Water Resources Management in the Baiyangdian Basin Project Financed by Asian Development Bank Monitoring and Evaluation Report on the Resettlement of Integrated Ecosystem and Water Resources Management in the Baiyangdian Basin Project (No. 5) National Research Center of Resettlement Hohai University, Nanjing, Jiangsu, China June, 2012 1 Persons in Charge : Shi Guoqing, Sun Yan Independent Monitoring and Shi Guoqing, Sun Yan, Hou Ronggui, : Evaluation Staff Lv Qiulong, Yuan Lin, Liu Yiying Shi Guoqing, Sun Yan, Hou Ronggui, Report Writers : Lv Qiulong, Yuan Lin, Liu Yiying Independent Monitoring and National Research Center of Resettlement : Evaluation Institute Hohai University No.1 Xikang Road Address : Nanjing, Jiangsu, China Post Code : 210098 Telephone : 0086-25-83786503 Fax : 0086-25-83718914 E-mail : [email protected] [email protected] 2 CONTENT 1 SUMMARY ................................................................................................................................................ 6 1.1 Introduction of Project ............................................................................................. -

Integrated Ecosystem Management and Environmental Protection of the Baiyangdian Lake Catchment Project in Baoding City, Hebei Province, Which Is Funded by ADB
APPENDIX D-1: Dingxing County WWTP Resettlement Plan Dingxing County WWTP Resettlement Plan Integrated Ecosystem and Water Resources Management in Baiyangdian Basin Project Wastewater Treatment Plant Project, Dingxing County Resettlement Plan Urban Construction and Development Corporation, Dingxing County July 2007 Dingxing County WWTP Resettlement Plan Catalogue 1 PROJECT INTRODUCTION ..................................................................................................1 1.1 BRIEF INTRODUCTION OF THE PROJECT...............................................................................1 1.1.1 Project Composition and Scope of Land Acquisition................................................1 1.1.2 Project Impacts........................................................................................................4 1.2 PROJECT ESTIMATED SOCIO-ECONOMIC BENEFITS ..............................................................4 1.3 COST ESTIMATE AND IMPLEMENTATION PLAN .......................................................................5 2 PROJECT IMPACTS AND SOCIOECONOMIC STATUS OF THE PROJECT AREA ............6 2.1 MEASURES TO AVOID OR MINIMIZE THE IMPACTS OF LAND ACQUISITION .............................6 2.1.1 Project Design and Site-selection Principle .............................................................6 2.1.2 Project Scheme Comparison ...................................................................................6 2.2 SURVEY MEASURES AND PROCESS.....................................................................................7 -

Distribution, Genetic Diversity and Population Structure of Aegilops Tauschii Coss. in Major Whea
Supplementary materials Title: Distribution, Genetic Diversity and Population Structure of Aegilops tauschii Coss. in Major Wheat Growing Regions in China Table S1. The geographic locations of 192 Aegilops tauschii Coss. populations used in the genetic diversity analysis. Population Location code Qianyuan Village Kongzhongguo Town Yancheng County Luohe City 1 Henan Privince Guandao Village Houzhen Town Liantian County Weinan City Shaanxi 2 Province Bawang Village Gushi Town Linwei County Weinan City Shaanxi Prov- 3 ince Su Village Jinchengban Town Hancheng County Weinan City Shaanxi 4 Province Dongwu Village Wenkou Town Daiyue County Taian City Shandong 5 Privince Shiwu Village Liuwang Town Ningyang County Taian City Shandong 6 Privince Hongmiao Village Chengguan Town Renping County Liaocheng City 7 Shandong Province Xiwang Village Liangjia Town Henjin County Yuncheng City Shanxi 8 Province Xiqu Village Gujiao Town Xinjiang County Yuncheng City Shanxi 9 Province Shishi Village Ganting Town Hongtong County Linfen City Shanxi 10 Province 11 Xin Village Sansi Town Nanhe County Xingtai City Hebei Province Beichangbao Village Caohe Town Xushui County Baoding City Hebei 12 Province Nanguan Village Longyao Town Longyap County Xingtai City Hebei 13 Province Didi Village Longyao Town Longyao County Xingtai City Hebei Prov- 14 ince 15 Beixingzhuang Town Xingtai County Xingtai City Hebei Province Donghan Village Heyang Town Nanhe County Xingtai City Hebei Prov- 16 ince 17 Yan Village Luyi Town Guantao County Handan City Hebei Province Shanqiao Village Liucun Town Yaodu District Linfen City Shanxi Prov- 18 ince Sabxiaoying Village Huqiao Town Hui County Xingxiang City Henan 19 Province 20 Fanzhong Village Gaosi Town Xiangcheng City Henan Province Agriculture 2021, 11, 311. -

Minimum Wage Standards in China August 11, 2020
Minimum Wage Standards in China August 11, 2020 Contents Heilongjiang ................................................................................................................................................. 3 Jilin ............................................................................................................................................................... 3 Liaoning ........................................................................................................................................................ 4 Inner Mongolia Autonomous Region ........................................................................................................... 7 Beijing......................................................................................................................................................... 10 Hebei ........................................................................................................................................................... 11 Henan .......................................................................................................................................................... 13 Shandong .................................................................................................................................................... 14 Shanxi ......................................................................................................................................................... 16 Shaanxi ...................................................................................................................................................... -

Minimum Wage Standards in China June 28, 2018
Minimum Wage Standards in China June 28, 2018 Contents Heilongjiang .................................................................................................................................................. 3 Jilin ................................................................................................................................................................ 3 Liaoning ........................................................................................................................................................ 4 Inner Mongolia Autonomous Region ........................................................................................................... 7 Beijing ......................................................................................................................................................... 10 Hebei ........................................................................................................................................................... 11 Henan .......................................................................................................................................................... 13 Shandong .................................................................................................................................................... 14 Shanxi ......................................................................................................................................................... 16 Shaanxi ....................................................................................................................................................... -

A12 List of China's City Gas Franchising Zones
附录 A12: 中国城市管道燃气特许经营区收录名单 Appendix A03: List of China's City Gas Franchising Zones • 1 Appendix A12: List of China's City Gas Franchising Zones 附录 A12:中国城市管道燃气特许经营区收录名单 No. of Projects / 项目数:3,404 Statistics Update Date / 统计截止时间:2017.9 Source / 来源:http://www.chinagasmap.com Natural gas project investment in China was relatively simple and easy just 10 CNG)、控股投资者(上级管理机构)和一线运营单位的当前主官经理、公司企业 years ago because of the brand new downstream market. It differs a lot since 所有制类型和联系方式。 then: LNG plants enjoyed seller market before, while a LNG plant investor today will find himself soon fighting with over 300 LNG plants for buyers; West East 这套名录的作用 Gas Pipeline 1 enjoyed virgin markets alongside its paving route in 2002, while today's Xin-Zhe-Yue Pipeline Network investor has to plan its route within territory 1. 在基础数据收集验证层面为您的专业信息团队节省 2,500 小时之工作量; of a couple of competing pipelines; In the past, city gas investors could choose to 2. 使城市燃气项目投资者了解当前特许区域最新分布、其他燃气公司的控股势力范 sign golden areas with best sales potential and easy access to PNG supply, while 围;结合中国 LNG 项目名录和中国 CNG 项目名录时,投资者更易于选择新项 today's investors have to turn their sights to areas where sales potential is limited 目区域或谋划收购对象; ...Obviously, today's investors have to consider more to ensure right decision 3. 使 LNG 和 LNG 生产商掌握采购商的最新布局,提前为充分市场竞争做准备; making in a much complicated gas market. China Natural Gas Map's associated 4. 便于 L/CNG 加气站投资者了解市场进入壁垒,并在此基础上谨慎规划选址; project directories provide readers a fundamental analysis tool to make their 5. 结合中国天然气管道名录时,长输管线项目的投资者可根据竞争性供气管道当前 decisions. With a completed idea about venders, buyers and competitive projects, 格局和下游用户的分布,对管道路线和分输口建立初步规划框架。 analyst would be able to shape a better market model when planning a new investment or marketing program. -

Download 288.53 KB
APPENDIX D-0: Summary Draft Resettlement Plan 1. Introduction The Integrated Ecosystem Management and Environmental Protection of the Baiyangdian Lake Catchment Project comprises seven categories including 22 subprojects: (i) wastewater treatment (13 subprojects); (ii) water supply (3 subprojects); (iii) reforestation (2 subprojects); (iv) water resources reallocation (1 subproject); (v) watershed rehabilitation (1 subproject); (vi) clean energy (1 subproject) and (vii) flood control (1 subproject). Among the 22 subprojects, there are 17 subprojects involving some land acquisition and resettlement impacts. The IAs, with the assistance from design institutes, have prepared 3 full resettlement plans (RPs) and 14 short resettlement plans (RPs), which have been prepared based on ADB procedures and requirements. Table 2.1 provides more details. All affected persons (APs) will be eligible for compensation and assistance. The Baoding Municipal Government issued an announcement about the eligibility cut-off date for compensation and assistance, which is effective as of 31st March,2007. Once the detailed drawing of each subproject is finalized, the RPs will be updated if necessary to reflect any design changes. 2. Policy and Legal Framework The legal framework and policies that have been used for the preparation of the resettlement plans for the Project include the following: - Involuntary Resettlement, Asian Development Bank (ADB), Manila,1995; - Resettlement Handbook: A Guide to Good Practice. ADB Manila, 1998; - Gender Checklist: Involuntary Resettlement, ADB Manila, February 2003; - OM Section F2 - Operations Manual: Bank Policies (BP) and Operational Procedures (OP), ADB, Manila. Issued on 29 October 2003; - Land Administration Law of the People’s Republic of China (effective as of 28 August, 2004); - Regulations on Basic Farmland Protection (effective as of 1January, 1999); - State Council Circular on the Decisions of Deepening Reform and Administrating Land Strictly (State Council [2004] No. -

Annual Development Report on China's Trademark Strategy 2014
Annual Development Report on China's Trademark Strategy 2014 TRADEMARK OFFICE/TRADEMARK REVIEW AND ADJUDICATION BOARD OF STATE ADMINISTRATION FOR INDUSTRY AND COMMERCE PEOPLE’S REPUBLIC OF CHINA China Industry & Commerce Press Preface Preface In 2014, Trademark staff in AICs and market supervision departments at all levels seriously implemented the spirit of the 18th National Congress of the CPC, and the third and fourth plenary meetings of 18th CPC Central Committee, followed the decisions and deployments of the Leading Party Group of SAIC, took the opportunity of enforcement of the revised Trademark Law, forged ahead with determination, insisted in exploration and innovation and promoted the reform and development of trademark to a new stage. ——Continuous Efforts to Facilitate Application for Trademark Registration. In 2014, with China’s economic transformation upgraded, the reform of business registration system has constantly increased the creativity and vitality of the market participants. The trademark application grew quickly and passed 2 million for the first time, reaching 2,285 millions, with a year-on-year growth of 21.5%, hitting a new record in the history and keeping the highest amount of the world for consecutive 13 years. The Trademark Office and Trademark Review and Adjudication Board of SAIC faced and overcame the difficulties, such as the application growing quickly, the running of Phase III system and the limited period of trademark examination and review, took emergency measures to improve the examination efficiency and complete the task of trademark examination by overtime working. The office examined 2.426 million trademark applications, which was over 2 million for the first time, an increase of 70.3%; the average examining period was kept in 9 months by the law. -

Religious Repression in China Persists
April 27, 1992 Volume 4, Number 11 RELIGIOUS REPRESSION IN CHINA PERSISTS A new list of religious prisoners from Hebei indicates that the crackdown on religious freedom in that northeastern province is continuing. As noted in an earlier Asia Watch report,1 not only do a considerable percentage of China's Catholics live in Hebei, but many of those who do maintain their loyalty to the Pope, eschewing ties with the "official" Chinese Catholic Patriotic Association. Beginning in 19892 and intensifying over the past two years, officials from the highest levels of Party and government have directed a determined effort to root out these "underground" bishops, priests and laypersons, maintaining that their responsibility for "hostile infiltration from abroad" threatens the motherland. At the same time, Chinese officials have gone to considerable lengths to publicize the releases of those who they say have broken the law, but have truly repented.3 The newest information severely undermines Chinese assertions of leniency. The pattern of arrests and trials established in Hebei in 1989 continues, and alleged releases are not releases at all. Asia Watch has been informed, for example, that two bishops, Paul Liu Shuhe and Peter Chen Jianzhang are being held against their will. The Chinese authorities insist that the bishops were never accused of wrongdoing and that they have been freed and are now being cared for in "old-age homes." However, 1Freedom of Religion in China, January 1992. 2See Central Office Document No.3, Circular on Stepping Up Control Over the Catholic Church to Meet the New Situation, February 17, 1989. -

Supplementary Material Continued
1 Supplementary Material 2 Table S1. Counties in the Jingjinji region. No City County No City County 1 Beijing Dongcheng District 26 Tianjin Beichen District 2 Beijing Xicheng District 27 Tianjin Wuqing District 3 Beijing Chaoyang District 28 Tianjin Baodi District 4 Beijing Fengtai District 29 Tianjin Binhai New District 5 Beijing Shijingshan District 30 Tianjin Ninghe District 6 Beijing Haidian District 31 Tianjin Jinghai District 7 Beijing Mentougou District 32 Tianjin Jizhou District 8 Beijing Fangshan District 33 Shijiazhuang Chang'an District 9 Beijing Tongzhou District 34 Shijiazhuang Qiaoxi District 10 Beijing Shunyi District 35 Shijiazhuang Xinhua District 11 Beijing Changping District 36 Shijiazhuang Jingxing Mining Area 12 Beijing Daxing District 37 Shijiazhuang Yuhua District 13 Beijing Huairou District 38 Shijiazhuang Gaocheng District 14 Beijing Pinggu District 39 Shijiazhuang Luquan District 15 Beijing Miyun District 40 Shijiazhuang Luancheng District 16 Beijing Yanqing District 41 Shijiazhuang Jingxing County 17 Tianjin Heping District 42 Shijiazhuang Zhengding County 18 Tianjin Hedong District 43 Shijiazhuang Xingtang County 19 Tianjin Hexi District 44 Shijiazhuang Lingshou County 20 Tianjin Nankai District 45 Shijiazhuang Gaoyi County 21 Tianjin Hebei District 46 Shijiazhuang Shenze County 22 Tianjin Hongqiao District 47 Shijiazhuang Zanhuang County 23 Tianjin Dongli District 48 Shijiazhuang Wuji County 24 Tianjin Xiqing District 49 Shijiazhuang Pingshan County 25 Tianjin Jinnan District 50 Shijiazhuang Yuanshi County