Estimating the Benefits of Managed Lanes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Federal Register/Vol. 65, No. 233/Monday, December 4, 2000
Federal Register / Vol. 65, No. 233 / Monday, December 4, 2000 / Notices 75771 2 departures. No more than one slot DEPARTMENT OF TRANSPORTATION In notice document 00±29918 exemption time may be selected in any appearing in the issue of Wednesday, hour. In this round each carrier may Federal Aviation Administration November 22, 2000, under select one slot exemption time in each SUPPLEMENTARY INFORMATION, in the first RTCA Future Flight Data Collection hour without regard to whether a slot is column, in the fifteenth line, the date Committee available in that hour. the FAA will approve or disapprove the application, in whole or part, no later d. In the second and third rounds, Pursuant to section 10(a)(2) of the than should read ``March 15, 2001''. only carriers providing service to small Federal Advisory Committee Act (Pub. hub and nonhub airports may L. 92±463, 5 U.S.C., Appendix 2), notice FOR FURTHER INFORMATION CONTACT: participate. Each carrier may select up is hereby given for the Future Flight Patrick Vaught, Program Manager, FAA/ to 2 slot exemption times, one arrival Data Collection Committee meeting to Airports District Office, 100 West Cross and one departure in each round. No be held January 11, 2000, starting at 9 Street, Suite B, Jackson, MS 39208± carrier may select more than 4 a.m. This meeting will be held at RTCA, 2307, 601±664±9885. exemption slot times in rounds 2 and 3. 1140 Connecticut Avenue, NW., Suite Issued in Jackson, Mississippi on 1020, Washington, DC, 20036. November 24, 2000. e. Beginning with the fourth round, The agenda will include: (1) Welcome all eligible carriers may participate. -

Texas Central Picks Preferred High-Speed Train Passenger Station in Houston
FOR IMMEDIATE RELEASE Texas Central picks preferred high-speed train passenger station in Houston • Preferred location will revitalize Northwest Mall site at I-610 and US 290 • Project seen as catalyst for economic growth, new jobs and development • Local connections planned with major employment centers, public transit HOUSTON [Feb. 5, 2018] – Highlighting Houston’s history as a major railway hub, Mayor Sylvester Turner and developers of the Texas Bullet Train announced today the preferred site of the new passenger station, at the Northwest Mall near the interchange of Interstate 610 and US 290. The terminal will be ideally located in a high-growth area, with easy access to employment centers, including the Galleria, the Energy Corridor and downtown. The station not only will be a catalyst for economic growth but it also will offer a convenient, efficient and direct network for passengers to and from local transit systems. The selection comes about a month after federal regulators released an environmental analysis that said the 200-mph, Houston-to-North Texas train would alleviate the strain on the state’s existing infrastructure and is needed to accommodate growing demands. “Houston continues to grow. Growing the smart way includes providing a wider choice of transportation options beyond more private vehicles and more roads. The Texas Bullet Train fits the transportation paradigm shift I have called for. And now with a preferred location for the Houston station, we are one big step closer to boarding for an exciting trip to the Brazos Valley and on to Dallas,” Mayor Sylvester Turner said. Texas Central, the high-speed train developers, released maps and conceptual renderings – final designs are pending – that show a multi-level station on a 45-acre site. -

Louisiana Department of Transportation and Development Supplement to Oversize/Overweight Permit
Rev. 02/15 STATE OF LOUISIANA DEPARTMENT OF TRANSPORTATION AND DEVELOPMENT SUPPLEMENT TO OVERSIZE/OVERWEIGHT PERMIT 1. GENERAL This special permit must be carried with the vehicle using same and must be available at all times for inspection by proper authorities. This permit is subject to revocation or cancellation at any time. The applicant assumes responsibility for and obligates himself to pay for any damages caused to highways, roads, bridges, structures or any other state-owned property while using this permit. Issuance of this permit is not assurance or warranty by the State or DOTD that the highways, roads, bridges and structures are capable of carrying the vehicle and load for which this permit is issued; nor shall issuance stop the State or said department from any claim which may arise for damage to its property. The applicant hereby accepts this permit at his own risk. The applicant agrees to defend, indemnify and hold harmless the Department and its duly appointed agents and employees from and against any and all claims, suits, liabilities, losses, damages, cost or expense including attorney fees sustained by reason of the exercise of the permit, whether or not the same may have been caused by negligence of the Department, its agent or employees. When required, by the permit, the vehicle and load for which the permit is issued shall be accompanied by a proper escort, State Police or otherwise, all at the expense of the user: and such other conditions or requirements as are herein imposed by the Secretary shall be complied with. This permit is issued pursuant to R.S. -

Driving Directions to MD Anderson
Directions to MD Anderson From Bush Intercontinental Airport / U.S. 59 - Traveling South • Take Will Clayton Boulevard east to U.S. 59 • Turn right (south) on U.S. 59 and follow it to Texas 288 • Exit onto Texas 288 and follow it south to the N. MacGregor exit • Turn right (west) onto N. MacGregor and follow it to Braeswood Boulevard • Continue heading straight, onto Braeswood, as N. MacGregor bears right • Follow Braeswood to Holcombe Boulevard • Turn right (west) onto Holcombe and follow it to the appropriate Entrance Marker. From Hardy Toll Road - Traveling South • Take Hardy Toll Road south to Interstate 610 east • Follow I-610 East and exit onto U.S. 59 South • From U.S. 59 exit onto Texas 288 and follow it south to the N. MacGregor exit • Turn right (west) onto N. MacGregor and follow it to Braeswood Boulevard • Continue heading straight, onto Braeswood, as N. MacGregor bears right • Follow Braeswood to Holcombe Boulevard • Turn right (west) onto Holcombe and follow it to the appropriate Entrance Marker. From U.S. 59 - Traveling North • Exit onto Texas 288 and follow it south to the N. MacGregor exit • Turn right (west) onto N. MacGregor and follow it to Braeswood Boulevard • Continue heading straight, onto Braeswood, as N. MacGregor bears right • Follow Braeswood to Holcombe Boulevard • Turn right (west) onto Holcombe and follow it to the appropriate Entrance Marker Directions to MD Anderson From Interstate 45 - Traveling South • Exit onto U.S. 59 south • From U.S. 59, exit onto Texas 288 and follow it south to the N. -

26403 Hanna Road Conroe OM
WOODLANDS AREA DEVELOPMENT OPPORTUNITY 26403 Hanna Road Conroe, Texas 77385 UNRESTRICTED COMMERCIAL LAND | FOR SALE WOODLANDS AREA DEVELOPMENT OPPORTUNITY 26403 Hanna Road Conroe, Texas 77385 SUMMARY • PROPERTY DESCRIPTION • MARKET OVERVIEW • DISCLAIMER OFFERING SUMMARY Sales Price $967,784.00 Price/SF $6.98/SF Property Highlights • Close to The Woodlands Mall • Five minutes from Exxon campus • Half mile from I-45 North • Hard corner at Hanna Road & Geffert Wright Drive • Within South Montgomery County Utility District • 390’ of frontage on heavily- trafficked Hanna Road • 366’ of frontage on Geffert Wright Drive WOODLANDS AREA DEVELOPMENT OPPORTUNITY 26403 Hanna Road Conroe, Texas 77385 SUMMARY • PROPERTY DESCRIPTION • MARKET OVERVIEW • DISCLAIMER PROPERTY INFORMATION Size 3.183 AC/138,651.48 SF A0350 - MONTG CO SCH LAND, TRACT 6E, 6F-1, (AKA First Dane Hanna Road, Legal Description BLOCK 1, RES A #2017082839), ACRES 3.183 ID Number 0350-00-00610 Access Hanna Road and Geffert Wright Drive 390’ of frontage on Hanna Road Frontage 366’ of frontage on Geffert Wright Drive Zoning Unrestricted Electric, Water, Sewer, and Utilities Telephone Available Flood Plain Property is not in the flood plain Traffic Counts Hanna Road: ~6,220 VPD Interstate 45: ~116,980 VPD WOODLANDS AREA DEVELOPMENT OPPORTUNITY 26403 Hanna Road Conroe, Texas 77385 SUMMARY • PROPERTY DESCRIPTION • MARKET OVERVIEW • DISCLAIMER WOODLANDS AREA DEVELOPMENT OPPORTUNITY 26403 Hanna Road Conroe, Texas 77385 26403 Hanna Rd SUMMARY • PROPERTY DESCRIPTION • MARKET OVERVIEW • DISCLAIMER Texas, AC +/- Flood Plain Map 100 Year 500 Year Unmapped/ Boundary Floodway Special Floodplain Floodplain Not Included The information contained herein was obtained from sources Aaron Morris deemed to be reliable. -

±51.75 Acres
±51.75 A CRE O PP O RTUNITY F O R C O RP O R ATE H E A DQU A RTERS O R M IXED - USE D EVEL O P M ENT HOUSTON, TEXAS Greenway Galleria Plaza Memorial To S a n A n t o n i o Memorial Park Marq*E Center Awty International To D o w n t o w n Walmart School Ravenna H o u s t o n North Post Oak Road (Under Construction) Multi-family Under Construction Hempstead Highway ±51.75 Acres Houston ISD West 18th Street Athletic Campus der Constructio Grand Pkwy Un n 69 LIBERTY Lake COUNTY The Woodlands Houston State Park struction MONTGOMERY on C er ExxonMobil d COUNTY n Corporate Headquarters U y w k Eastex Frwy P nd ra G EXECUTIVE SUMMARY HARRIS COUNTY HFF, as exclusive advisor to the seller, is pleased to offer the unique Proposed George Bush opportunity to acquire Northwest Mall, a ±51.75 acre infill redevelopment Intercontinental Airport Grand site (the “Property”) located at the intersection of I-610 and US-290 in Pkwy Sam Houston Pkwy Houston, Texas. Currently, the Property is positioned as an 800,000 Lake Houston square foot enclosed mall with an established mix of national retailers as well as a variety of smaller specialty stores. Northwest Mall is in an Hardy Toll Road 69 Northwest Frwy North Frwy Sheldon excellent position to take advantage of a major roadway expansion along Reservoir US-290, positive demographic growth, and surrounding redevelopment ±51.75 Acres activity. At ±51.75 acres, this offering represents an unprecedented Beaumont Hwy North opportunity to acquire a site of this size and scale with excellent ingress/ Loop Baytown East Frwy egress between two of Houston’s most dynamic neighborhoods. -

Highway Advisory Radio (HAR)
Offices of Research and Development HIGHWAY ADVISORY* RADIO Washington, D.C. 20690 MESSAGE DEVELOPMENT GUIDE Report No. FHWA/RD-82/059 Final Report October 1982 U.S. Department of Transportation Federal Highway Administration This document is available to the U.S. public through the National Technical Information Service, Springfield, Virginia 22161 FOREWORD This report presents guidelines for the development of messages or, "audio signs",for Highway Advisory Radio (HAR). The report provides an overview of HAR, message development principles, and application oriented examples. Also included in Appendix B of the report are some basic HAR operating considerations. This report is written in a non-technical format for users of HAR systems and will be a useful addition for the HAR operations community. The report should .be of interest to highway and/or traffic engineers either planning to use or currently using HAR. Distribution of this report is by FHWA memorandum with two copies of the report for each regional office, one for each division office and one for each State highway agency. Direct distribution is being made to the division office with sufficient copies to provide one report for each State agency. Director, Office of Research NOTICE This document is disseminated under the sponsorship of the Department of Transportation in the interest of information exchange. The United States Government assumes no liability for its contents or use thereof. The contents of this report reflect the views of the authors who are responsible for the facts and accuracy of the data presented herein. The contents do not necessarily reflect the official policy of the Department of Transportation. -

Federal Register/Vol. 63, No. 110/Tuesday, June 9, 1998/Notices
Federal Register / Vol. 63, No. 110 / Tuesday, June 9, 1998 / Notices 31549 Information on Services for Individuals designations that: (1) specify highway on the Internet at: With Disabilities routes over which hazardous materials http://www.fhwa.dot.gov. For information on facilities or (HM) may, or may not, be transported Section 5112(c) of title 49, United services for individuals with disabilities within their jurisdictions; and/or (2) States Code, requires the Secretary of or to request special assistance at the impose limitations or requirements with Transportation, in coordination with the meeting, contact Mr. Payne as soon as respect to highway routing of HM. States, to update and publish possible. States and Indian Tribes are also periodically a list of current effective required to furnish updated HM route hazardous materials highway routing Dated: June 4, 1998. information to the FHWA. designations. In addition, 49 CFR Joseph J. Angelo, FOR FURTHER INFORMATION CONTACT: 397.73(b) requires each State or Indian Director of Standards, Marine Safety and Tribe to furnish information on any new Mr. Kenneth Rodgers, Safety and Environmental Protection. or changed HM routing designations to Hazardous Materials Division (HSA±10), [FR Doc. 98±15425 Filed 6±8±98; 8:45 am] the FHWA within 60 days after Office of Motor Carrier Safety, (202) BILLING CODE 4910±15±M establishment. The FHWA maintains a 366±4016; or Mr. Raymond W. Cuprill, listing of all current State routing Office of the Chief Counsel, Motor designations and restrictions. In Carrier Law Division (HCC±20), (202) DEPARTMENT OF TRANSPORTATION addition, the FHWA has designated a 366±0834, Federal Highway point of contact in each FHWA Division Administration, 400 Seventh Street, Federal Highway Administration Office to provide local coordination SW., Washington, DC, 20590±0001. -
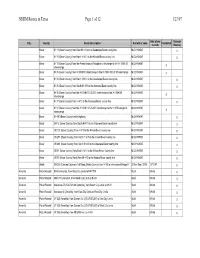
NRHM Routes in Texas Page 1 of 12 1/23/07
NRHM Routes in Texas Page 1 of 12 1/23/07 Date of ord Through City County Route Description # of ord or code Prohibited or code Routing Bexar IH 10 (Bexar County) from East IH 410 to the Guadalupe/Bexar county line M.O.#108547 X Bexar IH 10 (Bexar County) from North IH 410 to the Kendall/Bexar county line M.O.#108547 X Bexar IH 10 (Bexar County) from the Fredericksburg/Woodlawn interchange to the IH 10/IH 35 M.O.#108547 X interchange Bexar IH 35 (Bexar County) from IH 35/IH 10 interchange to the IH 10/IH 35/US 90 interchange M.O.#108547 X Bexar IH 35 (Bexar County) from North IH 410 to the Guadalupe/Bexar county line M.O.#108547 X Bexar IH 35 (Bexar County) from South IH 410 to the Atascosa/Bexar county line M.O.#108547 X Bexar IH 35 (Bexar County) from the IH 35/IH 37/US 281 interchange to the IH 10/IH 35 M.O.#108547 X interchange Bexar IH 37 (Bexar County) from IH 410 to the Atascosa/Bexar county line M.O.#108547 X Bexar IH 37 (Bexar County) from the IH 35/IH 37/US 281 interchange to the IH 37/Durango St. M.O.#108547 X interchange Bexar IH 410 (Bexar County) entire highway M.O.#108547 X Bexar SH 16 (Bexar County) from South IH 410 to the Atascosa/Bexar county line M.O.#108547 X Bexar US 181 (Bexar County) from IH 410 to the Wilson/Bexar county line M.O.#108547 X Bexar US 281 (Bexar County) from North IH 410 to the Comal/Bexar county line M.O.#108547 X Bexar US 281 (Bexar County) from South IH 410 to the Atascosa/Bexar county line M.O.#108547 X Bexar US 87 (Bexar County) from East IH 410 to the Wilson/Bexar County line M.O.#108547 X Bexar -

1919 North Loop West
1919Houston, Texas North Loop West JLL | | 1919 North Loop West – Houston, TX JLL | | 1919 North Loop West – Houston, TX 1919 North Loop West | Houston, TX The Offering JLL Capital Markets, as exclusive advisor to the owner of 1919 North Loop West (“The Property”), is pleased to present the opportunity to acquire the fee simple interest in the 129,250 square foot Class B office building prominently located in Houston’s North Loop submarket, just north of the Galleria. The Property benefits from being highly visible and accessible to two of Houston’s most highly trafficked freeways, US Highway 290 and Interstate 610. The Property is institutionally owned and maintained, with recent capital improvements totaling in excess of $1.7 million with few ongoing capital needs. The Property is one of the top three office assets in the submarket and at 82.8% leased today, the Offering provides investors near-term value add opportunity at a significant discount to replacement cost. Healthcare Driven Demand The North Loop submarket has historically been a hybrid of office and medical, with office tenants occupying the majority of space. However that trend has shifted with the emergence of higher-cost housing and the transformation of surrounding neighborhoods. Current total square footage of buildings with over 25% medical is over 525,000 square feet, including the Property. Within this aforementioned medical office space, occupancy is 92%. All buildings are quoting $22 to 24 gross, with the exception of the best-in-class 1900 North Loop West, which is quoting $35 gross. 1900 North Loop West has been totally renovated with a new façade, new lobby, and new building systems. -

Current List of Designated Preferred and Restricted Routes
LEGEND Restrictions (Columns A to K) Designations (Columns L to P) 0 = All Hazmats A = All NRHM Hazmats 1 = Class 1 Explosives B = Class 1 Explosives 2 = Class 2 - Gas P = Class 7 HRCQ Radioactive 3 = Class 3 - Flammable I = Toxic Inhalation Hazard (TIH) 4 = Class 4 - Flammable Solid/Combustible M = Medical Waste 5 = Class 5 - Organic 6 = Class 6 - Poison 7 = Class 7 - Radioactive ID 8 = Class 8 - Corrosives REST = Restricted Route 9 = Class 9 - Dangerous (Other) PREF = Preferred Route i = Toxic Inhalation Hazard (TIH) PRES = Prescribed Route RECOM - Recommended Route YEAR DATE ID A B C D E F G HIJ K BLANK L NO P M STATE_ TEXT STATE CITY COUNTY ABBR ALABAMA YEAR DATE ID A B C D E F G HIJ K BLANK L NO P M STATE_ TEXT STATE CITY COUNTY ABBR 1996 08/26/96 PREF - ---------- ---P- ALBattleship Parkway [Mobile] froma By Bridge Rd. Alabama Mobile [Mobile] to Interstate 10 [exit 27] 1996 08/26/96 PREF - ---------- ---P- ALBay Bridge Rd. [Mobile] from Interstate 165 to Alabama Mobile Battleship Parkway [over Africa Town Cochran Bridge] [Westbound Traffic: Head south on I165; To by-pass the downtown area, head north on I165.] 1996 08/26/96 PREF - ---------- ---P- ALInterstate 10 from Mobile City Limits to Exit 26B Alabama Mobile [Water St] [Eastbound Traffic: To avoid the downtown area, exit on I-65 North] 1996 08/26/96 PREF - ---------- ---P- ALInterstate 10 from Mobile City Limits to Exit 27 Alabama Mobile 1996 08/26/96 PREF - ---------- ---P- ALInterstate 65 from Interstate 10 ton Iterstate 165 Alabama Mobile [A route for trucks wishing to by-pass the downtown area.] 1996 08/26/96 PREF - ---------- ---P- ALInterstate 65 from Mobile City Limits to Interstate Alabama Mobile 165 1996 08/26/96 PREF - ---------- ---P- ALInterstate 165 from Water St. -

ADDRESS Countofaddress US 59 4309 IH 10 2760 IH 610 1600 2200
ADDRESS CountOfADDRESS US 59 4309 IH 10 2760 IH 610 1600 2200 Durham 1636 IH 45 1429 SH 288 1023 12200 GULF FREEWAY EAST SERVICE ROAD 953 853 US-59 781 GULF FREEWAY COLLECTOR ROADWAY 758 MAIN 717 IH-10 686 2200 DURHAM 663 764 IH 10 659 9200 WESTHEIMER 582 SL-8 437 22200 EASTEX FWY E SR 433 4100 GULF FREEWAY WEST SERVICE ROAD 399 762 IH 10 363 IH-45 349 IH-610 344 4900 NORTH SHEPHERD 333 3200 HAMILTON 326 SH-249 325 700 NORTH SHEPHERD 312 3000 SAN JACINTO 303 751 IH 10 303 GULF FREEWAY SERVICE ROAD 298 10500 WESTPARK 294 10300 BELLAIRE 291 US 290 285 765 IH 10 280 763 IH 10 277 EASTEX FREEWAY SERVICE ROAD 267 3000 LOUISIANA 258 US 59 (SOUTHBOUND) 255 4600 NORTH SHEPHERD 249 8400 HEMPSTEAD ROAD 245 3400 NORTH SHEPHERD 242 IH10 241 US59 239 12500 ALIEF CLODINE 232 9900 WESTHEIMER 227 7800 NORTH FREEWAY EAST SERVICE ROAD 224 2900 LOUISIANA 219 4200 WESTPARK DRIVE 218 13000 EAST FREEWAY NORTH SERVICE ROAD 216 4000 SAN FELIPE 214 EASTEX FREEWAY EAST SERVICE ROAD 212 763 IH-10 210 61 IH 45 208 GULF FREEWAY EAST SERVICE ROAD 203 5200 SOUTH WILLOW 202 ALLEN PARKWAY 201 1100 CHARTRES 200 2400 DURHAM 198 2500 DURHAM 197 2000 JEFFERSON 191 4700 NORTH SHEPHERD 188 779 IH 10 187 US 90A 185 100 MEMORIAL DRIVE (EASTBOUND) 179 9800 WESTHEIMER 175 100 SHEPHERD 174 IH610 172 10500 BELLAIRE BOULEVARD 164 5900 NORTH FREEWAY EAST SERVICE ROAD 164 900 YALE STREET 161 1000 WEST 43RD 158 9900 WESTHEIMER ROAD 158 4400 GULF FREEWAY WEST SERVICE ROAD 155 US 59 (NB) 153 GULF FREEWAY 152 2600 LITTLE YORK 151 13100 ALIEF CLODINE 150 STATE HIGHWAY 288 149 1900 EASTEX