Hardware-Software Codesign for Soc
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Formal Hardware Specification Languages for Protocol Compliance Verification
Formal Hardware Specification Languages for Protocol Compliance Verification ANNETTE BUNKER and GANESH GOPALAKRISHNAN University of Utah and SALLY A. MCKEE Cornell University The advent of the system-on-chip and intellectual property hardware design paradigms makes pro- tocol compliance verification increasingly important to the success of a project. One of the central tools in any verification project is the modeling language, and we survey the field of candidate languages for protocol compliance verification, limiting our discussion to languages originally in- tended for hardware and software design and verification activities. We frame our comparison by first constructing a taxonomy of these languages, and then by discussing the applicability of each approach to the compliance verification problem. Each discussion includes a summary of the devel- opment of the language, an evaluation of the language’s utility for our problem domain, and, where feasible, an example of how the language might be used to specify hardware protocols. Finally, we make some general observations regarding the languages considered. Categories and Subject Descriptors: B.4.3 [Input/Output and Data Communications]: Inter- connections (Subsystems)—Interfaces; B.4.5 [Input/Output and Data Communications]: Reli- ability, Testing, and Fault-Tolerance—Hardware reliability; B.7.2 [Integrated Circuits]: Design aids—Verification; C.2.2 [Computer-Communication Networks]: Network Protocols—Protocol verification; D.3.3 [Programming Languages]: Language Constructs and Features—Data types -

Introduction to Verilog HDL
Introduction to Verilog HDL Jorge Ramírez Corp Application Engineer Synopsys University Courseware Copyright © 2011 Synopsys, Inc. All rights reserved. Developed by: Jorge Ramirez Outline Lexical elements • HDL Verilog Data type representation Structures and Hierarchy • Synthesis Verilog tutorial Operators • Assignments Synthesis coding guidelines Control statements • Verilog - Test bench Task and functions Generate blocks • Fine State Machines • References Synopsys University Courseware Copyright © 2011 Synopsys, Inc. All rights reserved. Developed by: Jorge Ramirez HDL VERILOG Synopsys University Courseware Copyright © 2011 Synopsys, Inc. All rights reserved. Developed by: Jorge Ramirez What is HDL? • Hard & Difficult Language? – No, means Hardware Description Language • High Level Language – To describe the circuits by syntax and sentences – As oppose to circuit described by schematics • Widely used HDLs – Verilog – Similar to C – SystemVerilog – Similar to C++ – VHDL – Similar to PASCAL Synopsys University Courseware Copyright © 2011 Synopsys, Inc. All rights reserved. Developed by: Jorge Ramirez Verilog • Verilog was developed by Gateway Design Automation as a proprietary language for logic simulation in 1984. • Gateway was acquired by Cadence in 1989 • Verilog was made an open standard in 1990 under the control of Open Verilog International. • The language became an IEEE standard in 1995 (IEEE STD 1364) and was updated in 2001 and 2005. Synopsys University Courseware Copyright © 2011 Synopsys, Inc. All rights reserved. Developed by: Jorge Ramirez SystemVerilog • SystemVerilog is the industry's first unified hardware description and verification language • Started with Superlog language to Accellera in 2002 • Verification functionality (base on OpenVera language) came from Synopsys • In 2005 SystemVerilog was adopted as IEEE Standard (1800-2005). The current version is 1800-2009 Synopsys University Courseware Copyright © 2011 Synopsys, Inc. -

UVM Verification Framework
UVM Verification Framework Mads Bergan Roligheten Electronics System Design and Innovation Submission date: June 2014 Supervisor: Kjetil Svarstad, IET Co-supervisor: Vitaly Marchuk, Atmel Norway AS Norwegian University of Science and Technology Department of Electronics and Telecommunications i Problem description Atmel has a wide range of IP designs and a good, reusable and efficient verification framework is extremely important to have short time to market. UVM (Universal Verification Methodology) is a methodology for functional verification using Sys- temVerilog, which is a set of standardized libraries of SystemVerilog. The student will investigate how UVM can be used to build a reusable verification framework. He has to take decisions on the following tasks: - Synchronization between transaction level and RTL design; - Packing and unpacking transactions and driving them to the design under test; - Configuration database and reusability; - Constrained randomization; - Functional coverage and test execution control; The verification framework can be used on any open source RTL. This is interesting and challenging work on top edge of industry verification. It requires knowledge of SystemVerilog, object-oriented programming and digital systems. Assignment given: January 2014 Supervisor: Kjetil Svarstad, IET Assignment proposer / Co-supervisor: Vitaly Marchuk, Atmel Norway AS ii Abstract iii Abstract The importance of verification is increasing with the size of hardware designs, and reducing the effort required for is necessary to increase productivity. This thesis covers the creation of a reusable verification framework for processor verification using the Universal Verification Methodology (UVM). The framework is used to verify three simple processor designs to evaluate its potential for reuse. The three processors include a synchronous, asynchronous and a stack based processor. -

C 2011 MICHAEL KAHN KATELMAN a META-LANGUAGE for FUNCTIONAL VERIFICATION
c 2011 MICHAEL KAHN KATELMAN A META-LANGUAGE FOR FUNCTIONAL VERIFICATION BY MICHAEL KAHN KATELMAN DISSERTATION Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Computer Science in the Graduate College of the University of Illinois at Urbana-Champaign, 2011 Urbana, Illinois Doctoral Committee: Professor Jos´eMeseguer, Chair and Director of Research Professor Arvind, Massachusetts Institute of Technology Associate Professor Grigore Ros, u Professor Josep Torrellas ABSTRACT This dissertation perceives a similarity between two activities: that of coordi- nating the search for simulation traces toward reaching verification closure, and that of coordinating the search for a proof within a theorem prover. The programmatic coordination of simulation is difficult with existing tools for dig- ital circuit verification because stimuli generation, simulation execution, and analysis of simulation results are all decoupled. A new programming language to address this problem, analogous to the mechanism for orchestrating proof search tactics within a theorem prover, is defined wherein device simulation is made a first-class notion. This meta-language for functional verification is first formalized in a parametric way over hardware description languages using rewriting logic, and subsequently a more richly featured software tool for Verilog designs, implemented as an embedded domain-specific language in Haskell, is described and used to demonstrate the novelty of the programming language and to conduct two case studies. Additionally, three hardware description languages are given formal semantics using rewriting logic and we demonstrate the use of executable rewriting logic tools to formally analyze devices implemented in those languages. ii This dissertation is dedicated to MIPS Technologies, Inc., in appreciation for having provided me with the opportunity to closely observe the functional verification effort of the 74K microprocessor. -

Vysok´E Uˇcení Technick´E V Brnˇe
VYSOKEU´ CENˇ ´I TECHNICKE´ V BRNEˇ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMACNˇ ´ICH TECHNOLOGI´I USTAV´ POCˇ ´ITACOVˇ YCH´ SYSTEM´ U˚ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS NEW METHODS FOR INCREASING EFFICIENCY AND SPEED OF FUNCTIONAL VERIFICATION DIZERTACNˇ ´I PRACE´ PHD THESIS AUTOR PRACE´ Ing. MARCELA SIMKOVˇ A´ AUTHOR BRNO 2015 VYSOKEU´ CENˇ ´I TECHNICKE´ V BRNEˇ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMACNˇ ´ICH TECHNOLOGI´I USTAV´ POCˇ ´ITACOVˇ YCH´ SYSTEM´ U˚ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF COMPUTER SYSTEMS METODY AKCELERACE VERIFIKACE LOGICKYCH´ OBVODU˚ NEW METHODS FOR INCREASING EFFICIENCY AND SPEED OF FUNCTIONAL VERIFICATION DIZERTACNˇ ´I PRACE´ PHD THESIS AUTOR PRACE´ Ing. MARCELA SIMKOVˇ A´ AUTHOR VEDOUC´I PRACE´ Doc. Ing. ZDENEKˇ KOTASEK,´ CSc. SUPERVISOR BRNO 2015 Abstrakt Priˇ vyvoji´ soucasnˇ ych´ cˇ´ıslicovych´ system´ u,˚ napr.ˇ vestavenˇ ych´ systemu´ a pocˇ´ıtacovˇ eho´ hardware, je nutne´ hledat postupy, jak zvy´sitˇ jejich spolehlivost. Jednou z moznostˇ ´ı je zvysovˇ an´ ´ı efektivity a rychlosti verifikacnˇ ´ıch procesu,˚ ktere´ se provad´ ejˇ ´ı v ranych´ faz´ ´ıch navrhu.´ V teto´ dizertacnˇ ´ı praci´ se pozornost venujeˇ verifikacnˇ ´ımu prˇ´ıstupu s nazvem´ funkcnˇ ´ı verifikace. Je identifikovano´ nekolikˇ vyzev´ a problemu´ tykaj´ ´ıc´ıch se efektivity a rychlosti funkcnˇ ´ı verifikace a ty jsou nasledn´ eˇ reˇ senyˇ v c´ılech dizertacnˇ ´ı prace.´ Prvn´ı c´ıl se zameˇrujeˇ na redukci simulacnˇ ´ıho casuˇ v prub˚ ehuˇ verifikace komplexn´ıch system´ u.˚ Duvodem˚ je, zeˇ simulace inherentneˇ paraleln´ıho hardwaroveho´ systemu´ trva´ velmi dlouho v porovnan´ ´ı s behemˇ v skutecnˇ em´ hardware. Je proto navrhnuta optimalizacnˇ ´ı technika, ktera´ umist’uje verifikovany´ system´ do FPGA akceleratoru,´ zat´ım co cˇast´ verifikacnˇ ´ıho prostredˇ ´ı stale´ beˇzˇ´ı v simulaci. -

Parallel Systemc Simulation for Electronic System Level Design
Parallel SystemC Simulation for Electronic System Level Design Von der Fakultät für Elektrotechnik und Informationstechnik der Rheinisch–Westfälischen Technischen Hochschule Aachen zur Erlangung des akademischen Grades eines Doktors der Ingenieurwissenschaften genehmigte Dissertation vorgelegt von Diplom–Ingenieur Jan Henrik Weinstock aus Göttingen Berichter: Universitätsprofessor Dr. rer. nat. Rainer Leupers Universitätsprofessor Dr.-Ing. Diana Göhringer Tag der mündlichen Prüfung: 19.06.2018 Diese Dissertation ist auf den Internetseiten der Hochschulbibliothek online verfügbar. Abstract Over the past decade, Virtual Platforms (VPs) have established themselves as essential tools for embedded system design. Their application fields range from rapid proto- typing over design space exploration to early software development. This makes VPs a core enabler for concurrent HW/SW design – an indispensable design approach for meeting today’s aggressive marketing schedules. VPs are essentially a simulation of a complete microprocessor system, detailed enough to run unmodified target binary code. During simulation, VPs provide non-intrusive debugging access as well as re- porting on non-functional system parameters, such as execution timing and estimated power and energy consumption. To accelerate the construction of a VP for new systems, developers typically rely on pre-existing simulation environments. SystemC is a popular example for this and has become the de-facto reference for VP design since it became an official IEEE stan- dard in 2005. Since then, however, SystemC has failed to keep pace with its user’s demands for high simulation speed, especially when embedded multi-core systems are concerned. Because SystemC only utilizes a single processor of the host computer, the underlying sequential discrete event simulation algorithm becomes a performance bottleneck when simulating multiple virtual processors. -

Writing Testbenches.Book
PREFACE If you survey hardware design groups, you will learn that between 60% and 80% of their effort is now dedicated to verification. Unlike synthesizeable coding, there is no particular coding style nor language required for verification. The freedom of using any lan- guage that can be interfaced to a simulator and of using any features of that language has produced a wide array of techniques and approaches to verification. The absence of constraints and historical lack of available expertise and references in verification has resulted in ad hoc approaches. The consequences of an informal verification process can range from a non-functional design requir- ing several re-spins, through a design with only a subset of the intended functionality, to a delayed product shipment. WHY THIS BOOK IS IMPORTANT Take a survey of the books about Verilog or VHDL currently avail- able. You will notice that the majority of the pages are devoted to explaining the details of the languages. In addition, several chapters are focused on the synthesizeable—or RTL—coding style replete with examples. Some books are even devoted entirely to the subject of RTL coding. When verification is addressed, only one or two chapters are dedi- cated to the topic. And often, the primary focus is to introduce more language constructs. Verification is usually presented in a very rudi- Writing Testbenches: Functional Verification of HDL Models xix Preface mentary fashion, using simple, non-scalable techniques that become tedious in large-scale, real-life designs. The first edition of this book was the first book specifically devoted to functional verification techniques for hardware models. -
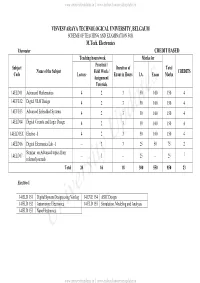
PG Syllabus 2014-16.Pdf
www.universityupdates.in || www.android.universityupdates.in VISVESVARAYA TECHNOLOGICAL UNIVERSITY, BELGAUM SCHEME OF TEACHING AND EXAMINATION FOR M.Tech. Electronics I Semester CREDIT BASED Teaching hours/week Marks for Practical / Subject Duration of Total Name of the Subject Field Work / CREDITS Code Lecture Exam in Hours I.A. Exam Marks Assignment/ Tutorials 14ELD11 Advanced Mathematics 4 2 3 50 100 150 4 14EVE12 Digital VLSI Design 4 2 3 50 100 150 4 14EVE13 Advanced Embedded Systems 4 2 3 50 100 150 4 14ELD14 Digital Circuits and Logic Design 4 2 3 50 100 150 4 14ELD15X Elective - I 4 2 3 50 100 150 4 14ELD16 Digital Electronics Lab -1 -- 3 3 25 50 75 2 Seminar on Advanced topics from 14ELD17 -- 3 -- 25 -- 25 1 refereed journals Total 20 16 18 300 550 850 23 Elective-1 14 ELD 151 Digital System Design using Verilog 14 EVE 154 ASIC Design 14 ELD 152 Automotive Electronics 14 ELD 155 Simulation, Modeling and Analysis 14 ELD 153 NanoElectronics University Updates www.universityupdates.in || www.android.universityupdates.in www.universityupdates.in || www.android.universityupdates.in VISVESVARAYA TECHNOLOGICAL UNIVERSITY, BELGAUM SCHEME OF TEACHING AND EXAMINATION FOR M.Tech. Electronics II Semester CREDIT BASED Teaching hours/week Marks for Practical / Duration of Total Subject Code Name of the Subject Field Work / CREDITS Lecture Exam in Hours I.A. Exam Marks Assignment/ Tutorials 14ELD21 Modern DSP 4 2 3 50 100 150 4 14ELD22 Coding Theory 4 2 3 50 100 150 4 14ELD23 Digital Signal Compression 4 2 3 50 100 150 4 14ELD24 Real Time Operating -

SRAM-Based FPGA Systems for Safety-Critical Applications: a Survey on Design Standards and Proposed Methodologies∗
SRAM-based FPGA Systems for Safety-Critical Applications: A Survey on Design Standards and Proposed Methodologies∗ Cinzia Bernardeschi Luca Cassano Member, IEEE Andrea Domenici† March 29, 2019 Abstract As the ASIC design cost becomes affordable only for very large scale productions, the FPGA technology is currently becoming the leading technology for those applications that require a small scale production. FPGAs can be considered as a technology crossing be- tween hardware and software. Only a small number of standards for the design of safety-critical systems give guidelines and recommenda- tions that take the peculiarities of the FPGA technology into consid- eration. The main contribution of this paper is an overview of the existing design standards that regulate the design and verification of FPGA-based systems in safety-critical application fields. Moreover, the paper proposes a survey of significant published research propos- als and existing industrial guidelines about the topic, and collects and reports about some lessons learned from industrial and research projects involving the use of FPGA devices. Keywords: Design Verification, Electronic Design, Safety-critical Sys- tems, SRAM-based FPGA ∗Postprint. Published in: Journal of Computer Science and Technology March 2015, Volume 30, Issue 2, pp 373390. The final authenticated version is available online at: https://doi.org/10.1007/s11390-015-1530-5 †C. Bernardeschi and A. Domenici are with the Department of Information Engineering, University of Pisa, Italy. L. Cassano is with the Dipartimento di Elettronica, Informazione e Bioingegneria, Politecnico di Milano, Italy. 1 1 Introduction and Motivations Since the first FPGA device was developed by Xilinx in 1984 with the XC2064 chip, the FPGA technology has enormously grown in terms of flexibility, reliability and computational power. -

FPGA Compiler II™ User Guide
FPGA Compiler II™ User Guide Version 2002.05-FC3.7.1, June 2002 Comments? E-mail your comments about Synopsys documentation to [email protected] Copyright Notice and Proprietary Information Copyright 2002 Synopsys, Inc. All rights reserved. This software and documentation contain confidential and proprietary information that is the property of Synopsys, Inc. The software and documentation are furnished under a license agreement and may be used or copied only in accordance with the terms of the license agreement. No part of the software and documentation may be reproduced, transmitted, or translated, in any form or by any means, electronic, mechanical, manual, optical, or otherwise, without prior written permission of Synopsys, Inc., or as expressly provided by the license agreement. Right to Copy Documentation The license agreement with Synopsys permits licensee to make copies of the documentation for its internal use only. Each copy shall include all copyrights, trademarks, service marks, and proprietary rights notices, if any. Licensee must assign sequential numbers to all copies. These copies shall contain the following legend on the cover page: “This document is duplicated with the permission of Synopsys, Inc., for the exclusive use of __________________________________________ and its employees. This is copy number __________.” Destination Control Statement All technical data contained in this publication is subject to the export control laws of the United States of America. Disclosure to nationals of other countries contrary to United States law is prohibited. It is the reader’s responsibility to determine the applicable regulations and to comply with them. Disclaimer SYNOPSYS, INC., AND ITS LICENSORS MAKE NO WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, WITH REGARD TO THIS MATERIAL, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. -

SYNOPSYS, INC. (Exact Name of Registrant As Specified in Its Charter)
Systemic solutions delivering EDA productivity 2004 Annual Report Dear Fellow Shareholders Fiscal 2004 was an important transition year for Synopsys. In our fourth quarter, we shifted our target license mix to From a technology standpoint, we made great strides in consist almost entirely of subscription licenses. These permit transforming our product line from a collection of point tools the customer to make payments over time, and in turn, we into complete, correlated platforms. Our focus on customer recognize revenue from these licenses over time as well. productivity brought us increased customer interest and benchmarking wins. We entered fiscal 2005 with increased This shift has many positive effects. Going forward, in each confidence in our competitive technology strength. quarter we expect that at least 90 percent of our quarterly revenue will come from backlog. This will give us better vis- Financially, we made changes to our license model that put ibility into our revenue results and will help us derive more us on solid footing for sustained growth in revenue and value for the new technology we will roll out in fiscal 2005. profitability. We expect to build significant backlog in 2005, which will provide predictability to our financial results. Another effect of the shift is that our fiscal 2005 revenue promises to be lower than it would have been under the old Fiscal Year Results license model. However, we expect to add significantly to our Fiscal 2004 was a challenging year for the Company backlog, which will help grow revenue in 2006 and beyond. financially. Revenue was $1.09 billion, down 7 percent from Technology Leadership 2003. -

Arm Cortex M7 Technical Reference Manual
Arm cortex m7 technical reference manual Continue ARM Cortex-M is a family of IP cores, mainly for 32-bit microcontrollers developed by ARM and licensed by various manufacturers. The kernel introduces a reduced computer instruction kit (RISC), is part of the architecture of ARMv6 or ARMv6 ARMv7 and is divided into ascendable complexity into units of Cortex-M0, Cortex-M0, Cortex-M1, Cortex-M3, Cortex-M3, Cortex-M4, Cortex-M7 and cortex-M33. ARM Cortex-M0 and M3 microcontrollers from NXP and Silicon Laboratories General ARM Limited do not produce microprocessors or microcontrollers themselves, but licenses the core to chip manufacturers and manufacturers, so-called Integrated Device Manufacturers (IDM), which are the actual core of ARM for proprietary and productive peripherals such as Controller Area Network (CAN), Expand serial interfaces, Ethernet interfaces, pulse width modulation outputs, analog to digital converters , Universal asynchronous receiver transmitter (UART) and more. These devices are connected to the ARM core with the Advanced Microcontroller (AMBA) bus architecture. ARM Limited offers a variety of kernel licensing models that differ in cost and volume of data provided. In all cases, the right is to freely distribute your own equipment with ARM processors. ARM Cortex-M processors are available to licensees as IP cores in Verilog hardware description language and can be displayed as a digital hardware circuit using logic synthesis, and can then be used either in the arrays (FPGAs) field programmable gates or specific integrated circuit applications (ASICs). Depending on the license model, either the IP core (IP-Core license) is allowed, or a brand new, proprietary microarchitecture can be developed that implements the ISA ARM (architectural license).