Empirical Validation of Network Learning with Taxi GPS Data from Wuhan, China
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Osprey Nest Queen Size Page 2 LC Cutting Correction
Template Layout Sheets Organizing, Bags, Foundation Papers, and Template Layout Sheets Sort the Template Layout Sheets as shown in the graphics below. Unit A, Temp 1 Unit A, Temp 1 Layout UNIT A TEMPLATE LAYOUT SHEET CUT 3" STRIP BACKGROUND FABRIC E E E ID ID ID S S S Please read through your original instructions before beginning W W W E E E Sheet. Place (2) each in Bag S S S TEMP TEMP TEMP S S S E E A-1 A-1 A-1 E W W W S S S I I I D D D E E E C TEMP C TEMP TEMP U U T T A-1 A-1 T A-1 #6, #7, #8, and #9 L L I the queen expansion set. The instructions included herein only I C C C N N U U U T T T T E E L L L I I I N N N E E replace applicable information in the pattern. E Unit A, Temp 2, UNIT A TEMPLATE LAYOUT SHEET Unit A, Temp 2 Layout CUT 3" STRIP BACKGROUND FABRIC S S S E E E The Queen Foundation Set includes the following Foundation Papers: W W W S S S ID ID ID E TEMP E TEMP E TEMP Sheet. Place (2) each in Bag A-2 A-2 A-2 E E E D D D I I TEMP I TEMP TEMP S S S A-2 A-2 A-2 W W W C E C E E S S S U C C U C U U U T T T T T T L L L L IN IN L IN I I N #6, #7, #8, and #9 E E N E E NP 202 (Log Cabin Full Blocks) ~ 10 Pages E NP 220 (Log Cabin Half Block with Unit A Geese) ~ 2 Pages NP 203 (Log Cabin Half Block with Unit B Geese) ~ 1 Page Unit B, Temp 1, ABRIC F BACKGROUND Unit B, Temp 1 Layout E E T SHEE YOUT LA TE TEMPLA A T UNI E D I D I D I S S STRIP 3" T CU S W W E W TP 101 (Template Layout Sheets for Log Cabins and Geese) ~ 2 Pages E S S E S TEMP TEMP TEMP S S S E E E 1 A- 1 A- 1 A- W W W S S S I I I D D D E E E C C Sheet. -

Poly Property Group Co., Limited 保利置業集團有限公司 (Incorporated in Hong Kong with Limited Liability) (Stock Code: 119)
Hong Kong Exchanges and Clearing Limited and The Stock Exchange of Hong Kong Limited take no responsibility for the contents of this announcement, make no representation as to its accuracy or completeness and expressly disclaim any liability whatsoever for any loss howsoever arising from or in reliance upon the whole or any part of the contents of this announcement. Poly Property Group Co., Limited 保利置業集團有限公司 (Incorporated in Hong Kong with limited liability) (Stock code: 119) RESULTS ANNOUNCEMENT FOR THE YEAR ENDED 31ST DECEMBER, 2017 RESULTS The directors (the “Directors”) of Poly Property Group Co., Limited (the “Company”) presented the audited consolidated financial statements of the Company and its subsidiaries (the “Group”) for the year ended 31st December, 2017, together with the independent auditor’s report issued by BDO Limited, as follows: – 1 – INDEPENDENT AUDITOR’S REPORT TO THE MEMBERS OF POLY PROPERTY GROUP CO., LIMITED (incorporated in Hong Kong with limited liability) Opinion We have audited the consolidated financial statements of Poly Property Group Co., Limited and its subsidiaries (together “the Group”) set out on pages 9 to 120, which comprise the consolidated statement of financial position as at 31st December, 2017, the consolidated statement of profit or loss, the consolidated statement of comprehensive income, the consolidated statement of changes in equity and the consolidated statement of cash flows for the year then ended and notes to the consolidated financial statements, including a summary of significant accounting policies. In our opinion, the consolidated financial statements give a true and fair view of the consolidated financial position of the Group as at 31st December, 2017 and of its consolidated financial performance and its consolidated cash flows for the year then ended in accordance with Hong Kong Financial Reporting Standards (“HKFRSs”) issued by the Hong Kong Institute of Certified Public Accountants (“HKICPA”) and have been properly prepared in compliance with the Hong Kong Companies Ordinance. -

Here You Can Taste Wuhan Featured Food
Contents Basic Mandarin Chinese Words and Phrases............................................... 2 Useful Sayings....................................................................................... 2 In Restaurants....................................................................................... 3 Numbers................................................................................................3 Dinning and cafes..........................................................................................5 Eating Out in Wuhan.............................................................................5 List of Restaurants and Food Streets (sort by distance).......................6 4 Places Where You Can Taste Wuhan Featured Food.........................7 Restaurants and cafes in Walking Distance........................................11 1 Basic Mandarin Chinese Words and Phrases Useful Sayings nǐ hǎo Hello 你 好 knee how zài jiàn Goodbye 再 见 zi gee’en xiè xiè Thank You 谢 谢! sheh sheh bú yòng le, xiè xiè No, thanks. 不 用 了,谢 谢 boo yong la, sheh sheh bú yòng xiè You are welcome. 不 用 谢 boo yong sheh wǒ jiào… My name is… 我 叫… wore jeow… shì Yes 是 shr bú shì No 不 是 boo shr hǎo Good 好 how bù hǎo Bad 不 好 boo how duì bù qǐ Excuse Me 对 不 起 dway boo chee wǒ tīng bù dǒng I do not understand 我 听 不 懂 wore ting boo dong duō shǎo qián How much? 多 少 钱? dor sheow chen Where is the xǐ shǒu jiān zài nǎ lǐ See-sow-jian zai na-lee washroom? 洗 手 间 在 哪 里 2 In Restaurants In China, many people call a male waiter as handsome guy and a female waitress as beautiful girl. It is also common to call “fú wù yuan” for waiters of both genders. cài dān Menu 菜 单 tsai dan shuài gē Waiter(Handsome) 帅 哥 shuai ge měi nǚ Waitress(Beautiful) 美 女 may nyu fú wù yuán Waiter/Waitress 服 务 员 fu woo yuan wǒ xiǎng yào zhè ge 我 I would like this. -

5G for Trains
5G for Trains Bharat Bhatia Chair, ITU-R WP5D SWG on PPDR Chair, APT-AWG Task Group on PPDR President, ITU-APT foundation of India Head of International Spectrum, Motorola Solutions Inc. Slide 1 Operations • Train operations, monitoring and control GSM-R • Real-time telemetry • Fleet/track maintenance • Increasing track capacity • Unattended Train Operations • Mobile workforce applications • Sensors – big data analytics • Mass Rescue Operation • Supply chain Safety Customer services GSM-R • Remote diagnostics • Travel information • Remote control in case of • Advertisements emergency • Location based services • Passenger emergency • Infotainment - Multimedia communications Passenger information display • Platform-to-driver video • Personal multimedia • In-train CCTV surveillance - train-to- entertainment station/OCC video • In-train wi-fi – broadband • Security internet access • Video analytics What is GSM-R? GSM-R, Global System for Mobile Communications – Railway or GSM-Railway is an international wireless communications standard for railway communication and applications. A sub-system of European Rail Traffic Management System (ERTMS), it is used for communication between train and railway regulation control centres GSM-R is an adaptation of GSM to provide mission critical features for railway operation and can work at speeds up to 500 km/hour. It is based on EIRENE – MORANE specifications. (EUROPEAN INTEGRATED RAILWAY RADIO ENHANCED NETWORK and Mobile radio for Railway Networks in Europe) GSM-R Stanadardisation UIC the International -
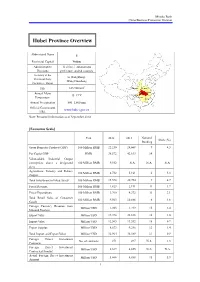
Hubei Province Overview
Mizuho Bank China Business Promotion Division Hubei Province Overview Abbreviated Name E Provincial Capital Wuhan Administrative 12 cities, 1 autonomous Divisions prefecture, and 64 counties Secretary of the Li Hongzhong; Provincial Party Wang Guosheng Committee; Mayor 2 Size 185,900 km Shaanxi Henan Annual Mean Hubei Anhui 15–17°C Chongqing Temperature Hunan Jiangxi Annual Precipitation 800–1,600 mm Official Government www.hubei.gov.cn URL Note: Personnel information as of September 2014 [Economic Scale] Unit 2012 2013 National Share (%) Ranking Gross Domestic Product (GDP) 100 Million RMB 22,250 24,668 9 4.3 Per Capita GDP RMB 38,572 42,613 14 - Value-added Industrial Output (enterprises above a designated 100 Million RMB 9,552 N.A. N.A. N.A. size) Agriculture, Forestry and Fishery 100 Million RMB 4,732 5,161 6 5.3 Output Total Investment in Fixed Assets 100 Million RMB 15,578 20,754 9 4.7 Fiscal Revenue 100 Million RMB 1,823 2,191 11 1.7 Fiscal Expenditure 100 Million RMB 3,760 4,372 11 3.1 Total Retail Sales of Consumer 100 Million RMB 9,563 10,886 6 4.6 Goods Foreign Currency Revenue from Million USD 1,203 1,219 15 2.4 Inbound Tourism Export Value Million USD 19,398 22,838 16 1.0 Import Value Million USD 12,565 13,552 18 0.7 Export Surplus Million USD 6,833 9,286 12 1.4 Total Import and Export Value Million USD 31,964 36,389 17 0.9 Foreign Direct Investment No. -

China Clean Energy Study Tour for Urban Infrastructure Development
China Clean Energy Study Tour for Urban Infrastructure Development BUSINESS ROUNDTABLE Tuesday, August 13, 2019 Hyatt Centric Fisherman’s Wharf Hotel • San Francisco, CA CONNECT WITH USTDA AGENDA China Urban Infrastructure Development Business Roundtable for U.S. Industry Hosted by the U.S. Trade and Development Agency (USTDA) Tuesday, August 13, 2019 ____________________________________________________________________ 9:30 - 10:00 a.m. Registration - Banquet AB 9:55 - 10:00 a.m. Administrative Remarks – KEA 10:00 - 10:10 a.m. Welcome and USTDA Overview by Ms. Alissa Lee - Country Manager for East Asia and the Indo-Pacific - USTDA 10:10 - 10:20 a.m. Comments by Mr. Douglas Wallace - Director, U.S. Department of Commerce Export Assistance Center, San Francisco 10:20 - 10:30 a.m. Introduction of U.S.-China Energy Cooperation Program (ECP) Ms. Lucinda Liu - Senior Program Manager, ECP Beijing 10:30 a.m. - 11:45 a.m. Delegate Presentations 10:30 - 10:45 a.m. Presentation by Professor ZHAO Gang - Director, Chinese Academy of Science and Technology for Development 10:45 - 11:00 a.m. Presentation by Mr. YAN Zhe - General Manager, Beijing Public Transport Tram Corporation 11:00 - 11:15 a.m. Presentation by Mr. LI Zhongwen - Head of Safety Department, Shenzhen Metro 11:15 - 11:30 a.m. Tea/Coffee Break 11:30 - 11:45 a.m. Presentation by Ms. WANG Jianxin - Deputy General Manager, Tianjin Metro Operation Corporation 11:45 a.m. - 12:00 p.m. Presentation by Mr. WANG Changyu - Director of General Engineer's Office, Wuhan Metro Group 12:00 - 12:15 p.m. -

Characteristics of Metro Networks and Methodology for Their Evaluation
22 TRANSPORTATION RESEARCH RECORD 1162 Characteristics of Metro Networks and Methodology for Their Evaluation ANTONIO Musso AND VuKAN R. VucH1c PURPOSE, ORGANIZATION, AND SCOPE Presented In this paper are the results of research on metro (rapid transit) networks, focusing on their geometric charac teristics. The object Is to define the most important measures, Presented in this paper is a systematic set of quantitative Indicators, and characteristics of geometric forms that can elements that defines the network characteristics of metro sys Improve the present predominantly empirical methods used in tems that can be used for their description, evaluation, and metro network planning and analysis. Several measures of comparative analysis. Examples of such evaluations include metro network size and rorm, including length, number or planning of new or analysis of existing networks, their com lines, and stations, which express the extensiveness of the sys parison with networks of other cities, and comparison of alter tem, are selected; they are also needed for derivations of various indicators. A number of selected indicators are then native network extensions. presented. These represent the most effective tool for network The quantitative elements are grouped into five general cate comparison because most of them are Independent of network gories, as follows: size. Several Indicators relating metro network to the city size and population express the degree of adequacy of the network 1. Measures of network size and form, to meet the city's needs. Based on experiences from a number of metro systems, characteristics of different types of lines 2. Indicators of network topology, (radial, diametrical, circumferential, and other) are defined. -

Evergrande Real Estate Group Limited 恒 大 地 產 集 團 有 限 公 司 (Incorporated in the Cayman Islands with Limited Liability) (Stock Code: 3333)
Hong Kong Exchanges and Clearing Limited and The Stock Exchange of Hong Kong Limited take no responsibility for the contents of this announcement, make no representation as to its accuracy or completeness and expressly disclaim any liability whatsoever for any loss howsoever arising from or in reliance upon the whole or any part of the contents of this announcement. Evergrande Real Estate Group Limited 恒 大 地 產 集 團 有 限 公 司 (Incorporated in the Cayman Islands with limited liability) (Stock Code: 3333) DISCLOSEABLE TRANSACTION The Board announces that on 2 December 2015, Shengyu (BVI) Limited, a wholly-owned subsidiary of the Company, as the purchaser, entered into three agreements respectively with the Vendor, pursuant to which the Purchaser agreed to acquire the interests in the relevant shares in and loans to the target companies held by the Vendor. These target companies hold the interests in the Haikou Project, the Huiyang Project and two projects located in Wuhan. Since the Vendor is the seller in these three agreements, such agreements will be aggregated in accordance with Rule 14.22 of the Listing Rules. As the applicable percentage ratios for the Acquisition exceed 5% but are less than 25%, the Acquisition constitutes a discloseable transaction for the Company under Chapter 14 of the Listing Rules and is subject to the reporting and announcement requirements under Chapter 14 of the Listing Rules. 1. INTRODUCTION The Board announces that on 2 December 2015, Shengyu (BVI) Limited, a wholly-owned subsidiary of the Company, as the purchaser, entered into three agreements respectively with the Vendor, pursuant to which the Purchaser agreed to acquire the interests in the relevant shares in and loans to the target companies held by the Vendor. -

Wuhan Sanyang Road Yangtze River Tunnel
Wuhan Sanyang Road Yangtze River Tunnel CHINA Presented by : Sun Feng Miami, USA 18th November 2019 Contents 1. Overview of the project 2. Why choose road tunnel and metro co-construction 3. Overall design of the tunnel 4. Project difficulties and solutions 5. Engineering photos Miami, USA 18th November 2019 1. Overview of the Project BEI JING WU HAN Sanyang Road Yangtze River Tunnel located in Wuhan, China Miami, USA 18th November 2019 1. Overview of the Project • Sanyang Road Yangtze River Tunnel connects the core areas of Hankou and Sanyang Road Wuchang. Yangtze River HAN KOU Tunnel • This tunnel is the world’s first Road- Metro shield tunnel. WU CHANG • This tunnel can meet the huge number of people and vehicles across the Yangtze River. Tunnel Location Miami, USA 18th November 2019 A Ramp C Ramp E Ramp B Ramp D Ramp San Yang Road Station F Ramp G Ramp Xu Jia Peng Station H Ramp ◆ Main tunnel(road) total length 4660 meters. ◆ There are 4 ramp tunnels on both sides of the Yangtze River connecting with urban roads. The total length of the eight ramp tunnels is 2680m. ◆ Station of the Metro Line 7 and the tunnel are located below the road tunnel. Miami, USA 18th November 2019 1. Overview of the Project ⚫ Project Start Time: 14, February 2014 ; ⚫ Project Completion Time :1,October 2018; ⚫ Total investment: RMB 7.39 billion($ 1.05 billion) ⚫ Owners :Wuhan Metro Group Co.,Ltd Miami, USA 18th November 2019 1. Overview of the Project Overall design • China Railway SIYUAN Survey and Design Group Co.,Ltd • Hubei Provincial Communications Planning -

High Speed Rail: Wuhan Urban Garden 5-Day Trip
High Speed Rail: Wuhan Urban Garden 5-Day Trip Day 1 Itinerary Suggested Transportation Hong Kong → Wuhan High Speed Rail [Hong Kong West Kowloon Station → Wuhan Railway Station] To hotel: Recommend to stay in a hotel by the river in Wuchang District. Metro: From Wuhan Railway Hotel for reference: Station, take Metro Line 4 The Westin Wuhan Wuchang Hotel towards Huangjinkou. Address: 96 Linjiang Boulevard, Wuchang District, Wuhan Change to Line 2 at Hongshan Square Station towards Tianhe International Airport. Get off at Jiyuqiao Station and walk for about 7 minutes. (Total travel time about 46 minutes) Taxi: About 35 minutes. Enjoy lunch near the hotel On foot: Walk for about 5 minutes Restaurant for reference: Zhen Bafang Hot Pot from the hotel. Address: No. 43 & 44, Building 12-13, Qianjin Road, Wanda Plaza, Jiyu Bridge, Wuchang District, Wuhan Stand the Test of Time: Yellow Crane Tower Bus: Walk for about 4 minutes from the restaurant to Jiyuqiao Metro Station. Take bus 804 towards Nanhu Road Jiangnan Village. Get off at Yue Ma Chang Station and walk for about 6 minutes. (Total travel time about 37 minutes) Taxi: About 15 minutes. Known as “The No. 1 Tower in the World”, the Yellow Crane Tower is a landmark for Wuhan City and Hubei Province and a must-see attraction. The tower was built in the Three Kingdoms era and was named after its erection on Huangjiji, a submerged rock. Well-known ancient characters such as Li Bai, Bai Juyi, Lu You and Yue Fei had all referenced the tower in their poetry works. -

Leading New ICT Building a Smart Urban Rail
Leading New ICT Building A Smart Urban Rail 2017 HUAWEI TECHNOLOGIES CO., LTD. Bantian, Longgang District Shenzhen518129, P. R. China Tel:+86-755-28780808 Huawei Digital Urban Rail Solution Digital Urban Rail Solution LTE-M Solution 04 Next-Generation DCS Solution 10 Urban Rail Cloud Solution 15 Huawei Digital Urban Rail Solution Huawei Digital Urban Rail Solution Huawei LTE-M Solution for Urban Rail Huawei and Alstom the Completed World’s Huawei Digital Urban Rail LTE-M Solution First CBTC over LTE Live Pilot On June 29th, 2015, Huawei and Alstom, one of the world’s leading energy solutions and transport companies, announced the successful completion of the world’s first live pilot test of 4G LTE multi-services based on Communications- based Train Control (CBTC), a railway signalling system based on wireless ground-to-train CBTC PIS CCTV Dispatching communication. The successful pilot, which CURRENT STATUS IN URBAN RAIL covered the unified multi-service capabilities TV Wall ATS Server Terminal In recent years, public Wi-Fi access points have become a OCC of several systems including CBTC, Passenger popular commodity in urban areas. Due to the explosive growth Information System (PIS), and closed-circuit in use of multimedia devices like smart phones, tablets and NMS LTE CN television (CCTV), marks a major step forward in notebooks, the demand on services of these devices in crowded the LTE commercialization of CBTC services. Line/Station Section/Depot Station places such as metro stations has dramatically increased. Huge BBU numbers of Wi-Fi devices on the platforms and in the trains RRU create chances of interference with Wi-Fi networks, which TAU TAU Alstom is the world’s first train manufacturer to integrate LTE 4G into its signalling system solution, the Urbalis Fluence CBTC Train AR IPC PIS AP TCMS solution, which greatly improves the suitability of eLTE, providing a converged ground-to-train wireless communication network Terminal When the CBTC system uses Wi-Fi technology to implement for metro operations. -

Table of Contents
International Conference on Soft Computing and Machine Learning (SCML2019) April 26th-29th, 2019, Wuhan, China Content Part I Conference Schedule ................................................................................................................................ 2 Part II Keynote Speeches .................................................................................................................................... 5 Keynote Speech 1: Fuzzy Logic and Signal Processing/Machine Learning for Brain-Computer Interface (BCI) ......................................................................................................................................................................... 5 Keynote Speech 2: Soft Computing and Machine Learning Services to Realize and Understand More About Our World ........................................................................................................................................................ 6 Part III Oral Sessions ........................................................................................................................................... 7 Oral Session_1 Deep Neural Networks ........................................................................................................... 8 Oral Session_2 Soft Computing ....................................................................................................................... 9 Oral Session_3 Machine Learning ................................................................................................................