Host Cell Factors Involved in the HCV Replication Cycle
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Combination of Photodynamic Therapy with Fenretinide and C6
Wayne State University Wayne State University Theses 1-1-2015 Combination Of Photodynamic Therapy With Fenretinide And C6-Pyridinium Ceramide Enhances Killing Of Scc17b Human Head And Neck Squamous Cell Carcinoma Cells Via The eD Novo Sphingolipid Biosynthesis And Mitochondrial Apoptosis Nithin Bhargava Boppana Wayne State University, Follow this and additional works at: https://digitalcommons.wayne.edu/oa_theses Part of the Medicinal Chemistry and Pharmaceutics Commons Recommended Citation Boppana, Nithin Bhargava, "Combination Of Photodynamic Therapy With Fenretinide And C6-Pyridinium Ceramide Enhances Killing Of Scc17b Human Head And Neck Squamous Cell Carcinoma Cells Via The eD Novo Sphingolipid Biosynthesis And Mitochondrial Apoptosis" (2015). Wayne State University Theses. 431. https://digitalcommons.wayne.edu/oa_theses/431 This Open Access Thesis is brought to you for free and open access by DigitalCommons@WayneState. It has been accepted for inclusion in Wayne State University Theses by an authorized administrator of DigitalCommons@WayneState. COMBINATION OF PHOTODYNAMIC THERAPY WITH FENRETINIDE AND C6-PYRIDINIUM CERAMIDE ENHANCES KILLING OF SCC17B HUMAN HEAD AND NECK SQUAMOUS CELL CARCINOMA CELLS VIA THE DE NOVO SPHINGOLIPID BIOSYNTHESIS AND MITOCHONDRIAL APOPTOSIS by NITHIN BHARGAVA BOPPANA THESIS Submitted to the Graduate School of Wayne State University, Detroit, Michigan in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE 2015 MAJOR: PHARMACEUTICAL SCIENCES Approved By: ________________________________ Advisor Date © COPYRIGHT BY NITHIN BHARGAVA BOPPANA 2015 All Rights Reserved DEDICATION Dedicated to my mom Rekha Vasireddy for always believing in me and helping me in becoming the person who I am today. ii ACKNOWLEDGEMENTS I am grateful to my advisor, Dr. Duska Separovic for her invaluable mentorship throughout the project. -

Human Placenta Exosomes: Biogenesis, Isolation, Composition, and Prospects for Use in Diagnostics
International Journal of Molecular Sciences Review Human Placenta Exosomes: Biogenesis, Isolation, Composition, and Prospects for Use in Diagnostics Evgeniya E. Burkova 1,* , Sergey E. Sedykh 1,2 and Georgy A. Nevinsky 1,2 1 SB RAS Institute of Chemical Biology and Fundamental Medicine, 630090 Novosibirsk, Russia; [email protected] (S.E.S.); [email protected] (G.A.N.) 2 Department of Natural Sciences, Novosibirsk State University, 630090 Novosibirsk, Russia * Correspondence: [email protected]; Tel.: +7-(383)-363-51-27 Abstract: Exosomes are 40–100 nm nanovesicles participating in intercellular communication and transferring various bioactive proteins, mRNAs, miRNAs, and lipids. During pregnancy, the placenta releases exosomes into the maternal circulation. Placental exosomes are detected in the maternal blood even in the first trimester of pregnancy and their numbers increase significantly by the end of pregnancy. Exosomes are necessary for the normal functioning of the placenta and fetal development. Effects of exosomes on target cells depend not only on their concentration but also on their intrinsic components. The biochemical composition of the placental exosomes may cause various complications of pregnancy. Some studies relate the changes in the composition of nanovesicles to placental dysfunction. Isolation of placental exosomes from the blood of pregnant women and the study of protein, lipid, and nucleic composition can lead to the development of methods for early diagnosis of pregnancy pathologies. This review describes the biogenesis of exosomes, methods Citation: Burkova, E.E.; Sedykh, S.E.; of their isolation, analyzes their biochemical composition, and considers the prospects for using Nevinsky, G.A. Human Placenta exosomes to diagnose pregnancy pathologies. -

Deletion of the Gene Encoding the Reductase Component of 3
Yeh et al. Microbial Cell Factories 2014, 13:130 http://www.microbialcellfactories.com/content/13/1/130 RESEARCH Open Access Deletion of the gene encoding the reductase component of 3-ketosteroid 9α-hydroxylase in Rhodococcus equi USA-18 disrupts sterol catabolism, leading to the accumulation of 3-oxo-23,24-bisnorchola-1,4-dien-22-oic acid and 1,4-androstadiene-3,17-dione Chin-Hsing Yeh1, Yung-Shun Kuo1, Che-Ming Chang1, Wen-Hsiung Liu2, Meei-Ling Sheu3 and Menghsiao Meng1* Abstract The gene encoding the putative reductase component (KshB) of 3-ketosteroid 9α-hydroxylase was cloned from Rhodococcus equi USA-18, a cholesterol oxidase-producing strain formerly named Arthrobacter simplex USA-18, by PCR according to consensus amino acid motifs of several bacterial KshB subunits. Deletion of the gene in R. equi USA-18 by a PCR-targeted gene disruption method resulted in a mutant strain that could accumulate up to 0.58 mg/ml 1,4-androstadiene-3,17-dione (ADD) in the culture medium when 0.2% cholesterol was used as the carbon source, indicating the involvement of the deleted enzyme in 9α-hydroxylation of steroids. In addition, this mutant also accumulated 3-oxo-23,24-bisnorchola-1,4-dien-22-oic acid (Δ1,4-BNC). Because both ADD and Δ1,4-BNC are important intermediates for the synthesis of steroid drugs, this mutant derived from R. equi USA-18 may deserve further investigation for its application potential. Background generally believed to be carried out by cholesterol oxidase, Steroid drugs, including androgens, anabolic steroids, es- which catalyzes the oxidation of the 3β-hydroxyl moiety of trogens and corticosteroids, have been widely used for a sterols with the simultaneous isomerization of Δ5 to Δ4, variety of health purposes. -

Supporting Information
Supporting Information Edgar et al. 10.1073/pnas.1601895113 SI Methods (Actimetrics), and recordings were analyzed using LumiCycle Mice. Sample size was determined using the resource equation: Data Analysis software (Actimetrics). E (degrees of freedom in ANOVA) = (total number of exper- – Cell Cycle Analysis of Confluent Cell Monolayers. NIH 3T3, primary imental animals) (number of experimental groups), with −/− sample size adhering to the condition 10 < E < 20. For com- WT, and Bmal1 fibroblasts were sequentially transduced − − parison of MuHV-4 and HSV-1 infection in WT vs. Bmal1 / with lentiviral fluorescent ubiquitin-based cell cycle indicators mice at ZT7 (Fig. 2), the investigator did not know the genotype (FUCCI) mCherry::Cdt1 and amCyan::Geminin reporters (32). of the animals when conducting infections, bioluminescence Dual reporter-positive cells were selected by FACS (Influx Cell imaging, and quantification. For bioluminescence imaging, Sorter; BD Biosciences) and seeded onto 35-mm dishes for mice were injected intraperitoneally with endotoxin-free lucif- subsequent analysis. To confirm that expression of mCherry:: Cdt1 and amCyan::Geminin correspond to G1 (2n DNA con- erin (Promega E6552) using 2 mg total per mouse. Following < ≤ anesthesia with isofluorane, they were scanned with an IVIS tent) and S/G2 (2 n 4 DNA content) cell cycle phases, Lumina (Caliper Life Sciences), 15 min after luciferin admin- respectively, cells were stained with DNA dye DRAQ5 (abcam) and analyzed by flow cytometry (LSR-Fortessa; BD Biosci- istration. Signal intensity was quantified using Living Image ences). To examine dynamics of replicative activity under ex- software (Caliper Life Sciences), obtaining maximum radiance perimental confluent conditions, synchronized FUCCI reporter for designated regions of interest (photons per second per − − − monolayers were observed by time-lapse live cell imaging over square centimeter per Steradian: photons·s 1·cm 2·sr 1), relative 3 d (Nikon Eclipse Ti-E inverted epifluorescent microscope). -

Table SI. Primer List of Genes Used for Reverse Transcription‑Quantitative PCR Validation
Table SI. Primer list of genes used for reverse transcription‑quantitative PCR validation. Genes Forward (5'‑3') Reverse (5'‑3') Length COL1A1 AGTGGTTTGGATGGTGCCAA GCACCATCATTTCCACGAGC 170 COL6A1 CCCCTCCCCACTCATCACTA CGAATCAGGTTGGTCGGGAA 65 COL2A1 GGTCCTGCAGGTGAACCC CTCTGTCTCCTTGCTTGCCA 181 DCT CTACGAAACCAGGATGACCGT ACCATCATTGGTTTGCCTTTCA 192 PDE4D ATTGCCCACGATAGCTGCTC GCAGATGTGCCATTGTCCAC 181 RP11‑428C19.4 ACGCTAGAAACAGTGGTGCG AATCCCCGGAAAGATCCAGC 179 GPC‑AS2 TCTCAACTCCCCTCCTTCGAG TTACATTTCCCGGCCCATCTC 151 XLOC_110310 AGTGGTAGGGCAAGTCCTCT CGTGGTGGGATTCAAAGGGA 187 COL1A1, collagen type I alpha 1; COL6A1, collagen type VI, alpha 1; COL2A1, collagen type II alpha 1; DCT, dopachrome tautomerase; PDE4D, phosphodiesterase 4D cAMP‑specific. Table SII. The differentially expressed mRNAs in the ParoAF_Control group. Gene ID logFC P‑Value Symbol Description ENSG00000165480 ‑6.4838 8.32E‑12 SKA3 Spindle and kinetochore associated complex subunit 3 ENSG00000165424 ‑6.43924 0.002056 ZCCHC24 Zinc finger, CCHC domain containing 24 ENSG00000182836 ‑6.20215 0.000817 PLCXD3 Phosphatidylinositol‑specific phospholipase C, X domain containing 3 ENSG00000174358 ‑5.79775 0.029093 SLC6A19 Solute carrier family 6 (neutral amino acid transporter), member 19 ENSG00000168916 ‑5.761 0.004046 ZNF608 Zinc finger protein 608 ENSG00000134343 ‑5.56371 0.01356 ANO3 Anoctamin 3 ENSG00000110400 ‑5.48194 0.004123 PVRL1 Poliovirus receptor‑related 1 (herpesvirus entry mediator C) ENSG00000124882 ‑5.45849 0.022164 EREG Epiregulin ENSG00000113448 ‑5.41752 0.000577 PDE4D Phosphodiesterase -
HCC and Cancer Mutated Genes Summarized in the Literature Gene Symbol Gene Name References*
HCC and cancer mutated genes summarized in the literature Gene symbol Gene name References* A2M Alpha-2-macroglobulin (4) ABL1 c-abl oncogene 1, receptor tyrosine kinase (4,5,22) ACBD7 Acyl-Coenzyme A binding domain containing 7 (23) ACTL6A Actin-like 6A (4,5) ACTL6B Actin-like 6B (4) ACVR1B Activin A receptor, type IB (21,22) ACVR2A Activin A receptor, type IIA (4,21) ADAM10 ADAM metallopeptidase domain 10 (5) ADAMTS9 ADAM metallopeptidase with thrombospondin type 1 motif, 9 (4) ADCY2 Adenylate cyclase 2 (brain) (26) AJUBA Ajuba LIM protein (21) AKAP9 A kinase (PRKA) anchor protein (yotiao) 9 (4) Akt AKT serine/threonine kinase (28) AKT1 v-akt murine thymoma viral oncogene homolog 1 (5,21,22) AKT2 v-akt murine thymoma viral oncogene homolog 2 (4) ALB Albumin (4) ALK Anaplastic lymphoma receptor tyrosine kinase (22) AMPH Amphiphysin (24) ANK3 Ankyrin 3, node of Ranvier (ankyrin G) (4) ANKRD12 Ankyrin repeat domain 12 (4) ANO1 Anoctamin 1, calcium activated chloride channel (4) APC Adenomatous polyposis coli (4,5,21,22,25,28) APOB Apolipoprotein B [including Ag(x) antigen] (4) AR Androgen receptor (5,21-23) ARAP1 ArfGAP with RhoGAP domain, ankyrin repeat and PH domain 1 (4) ARHGAP35 Rho GTPase activating protein 35 (21) ARID1A AT rich interactive domain 1A (SWI-like) (4,5,21,22,24,25,27,28) ARID1B AT rich interactive domain 1B (SWI1-like) (4,5,22) ARID2 AT rich interactive domain 2 (ARID, RFX-like) (4,5,22,24,25,27,28) ARID4A AT rich interactive domain 4A (RBP1-like) (28) ARID5B AT rich interactive domain 5B (MRF1-like) (21) ASPM Asp (abnormal -

A Chemical Proteomic Approach to Investigate Rab Prenylation in Living Systems
A chemical proteomic approach to investigate Rab prenylation in living systems By Alexandra Fay Helen Berry A thesis submitted to Imperial College London in candidature for the degree of Doctor of Philosophy of Imperial College. Department of Chemistry Imperial College London Exhibition Road London SW7 2AZ August 2012 Declaration of Originality I, Alexandra Fay Helen Berry, hereby declare that this thesis, and all the work presented in it, is my own and that it has been generated by me as the result of my own original research, unless otherwise stated. 2 Abstract Protein prenylation is an important post-translational modification that occurs in all eukaryotes; defects in the prenylation machinery can lead to toxicity or pathogenesis. Prenylation is the modification of a protein with a farnesyl or geranylgeranyl isoprenoid, and it facilitates protein- membrane and protein-protein interactions. Proteins of the Ras superfamily of small GTPases are almost all prenylated and of these the Rab family of proteins forms the largest group. Rab proteins are geranylgeranylated with up to two geranylgeranyl groups by the enzyme Rab geranylgeranyltransferase (RGGT). Prenylation of Rabs allows them to locate to the correct intracellular membranes and carry out their roles in vesicle trafficking. Traditional methods for probing prenylation involve the use of tritiated geranylgeranyl pyrophosphate which is hazardous, has lengthy detection times, and is insufficiently sensitive. The work described in this thesis developed systems for labelling Rabs and other geranylgeranylated proteins using a technique known as tagging-by-substrate, enabling rapid analysis of defective Rab prenylation in cells and tissues. An azide analogue of the geranylgeranyl pyrophosphate substrate of RGGT (AzGGpp) was applied for in vitro prenylation of Rabs by recombinant enzyme. -
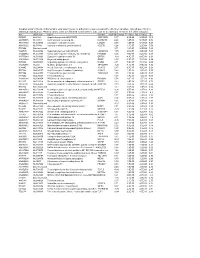
Supplementary File 2A Revised
Supplementary file 2A. Differentially expressed genes in aldosteronomas compared to all other samples, ranked according to statistical significance. Missing values were not allowed in aldosteronomas, but to a maximum of five in the other samples. Acc UGCluster Name Symbol log Fold Change P - Value Adj. P-Value B R99527 Hs.8162 Hypothetical protein MGC39372 MGC39372 2,17 6,3E-09 5,1E-05 10,2 AA398335 Hs.10414 Kelch domain containing 8A KLHDC8A 2,26 1,2E-08 5,1E-05 9,56 AA441933 Hs.519075 Leiomodin 1 (smooth muscle) LMOD1 2,33 1,3E-08 5,1E-05 9,54 AA630120 Hs.78781 Vascular endothelial growth factor B VEGFB 1,24 1,1E-07 2,9E-04 7,59 R07846 Data not found 3,71 1,2E-07 2,9E-04 7,49 W92795 Hs.434386 Hypothetical protein LOC201229 LOC201229 1,55 2,0E-07 4,0E-04 7,03 AA454564 Hs.323396 Family with sequence similarity 54, member B FAM54B 1,25 3,0E-07 5,2E-04 6,65 AA775249 Hs.513633 G protein-coupled receptor 56 GPR56 -1,63 4,3E-07 6,4E-04 6,33 AA012822 Hs.713814 Oxysterol bining protein OSBP 1,35 5,3E-07 7,1E-04 6,14 R45592 Hs.655271 Regulating synaptic membrane exocytosis 2 RIMS2 2,51 5,9E-07 7,1E-04 6,04 AA282936 Hs.240 M-phase phosphoprotein 1 MPHOSPH -1,40 8,1E-07 8,9E-04 5,74 N34945 Hs.234898 Acetyl-Coenzyme A carboxylase beta ACACB 0,87 9,7E-07 9,8E-04 5,58 R07322 Hs.464137 Acyl-Coenzyme A oxidase 1, palmitoyl ACOX1 0,82 1,3E-06 1,2E-03 5,35 R77144 Hs.488835 Transmembrane protein 120A TMEM120A 1,55 1,7E-06 1,4E-03 5,07 H68542 Hs.420009 Transcribed locus 1,07 1,7E-06 1,4E-03 5,06 AA410184 Hs.696454 PBX/knotted 1 homeobox 2 PKNOX2 1,78 2,0E-06 -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -

Production of 4-Ene-3-Ketosteroids in Corynebacterium Glutamicum
catalysts Article Production of 4-Ene-3-ketosteroids in Corynebacterium glutamicum Julia García-Fernández 1, Beatriz Galán 1, Carmen Felpeto-Santero 1, José L. Barredo 2 and José L. García 1,* 1 Department of Environmental Biotechnology, Centro de Investigaciones Biológicas (CSIC), Ramiro de Maeztu 9, 28040 Madrid, Spain; [email protected] (J.G.-F.); [email protected] (B.G.); [email protected] (C.F.-S.) 2 Department of Biotechnology, Crystal Pharma, A Division of Albany Molecular Research Inc. (AMRI), 47151 Boecillo Valladolid, Spain; [email protected] * Correspondence: [email protected]; Tel.: +34-918-373-112 Received: 29 September 2017; Accepted: 20 October 2017; Published: 27 October 2017 Abstract: Corynebacterium glutamicum has been widely used for the industrial production of amino acids and many value-added chemicals; however, it has not been exploited for the production of steroids. Using C. glutamicum as a cellular biocatalyst we have expressed the 3β-hydroxysteroid dehydrogenase/isomerase MSMEG_5228 from Mycobacterium smegmatis to demonstrate that the resulting recombinant strain is able to oxidize in vivo C19 and C21 3-OH-steroids to their corresponding keto-derivatives. This new approach constitutes a proof of concept of a biotechnological process for producing value-added intermediates such as 4-pregnen-16α,17α-epoxy-16β-methyl-3,20-dione. Keywords: 3-OH-steroids; biotransformation; dehydrogenase; Rhodococcus and Corynebacterium expression systems 1. Introduction Corynebacterium glutamicum has been widely used for the industrial production of amino acids, but the publication of its complete genome [1,2] has provided the basis for an enormous progress in the use of this microorganism for other biotechnological applications placing it as an ideal chassis within the top ranking of cell factories [3]. -

Literature Mining Sustains and Enhances Knowledge Discovery from Omic Studies
LITERATURE MINING SUSTAINS AND ENHANCES KNOWLEDGE DISCOVERY FROM OMIC STUDIES by Rick Matthew Jordan B.S. Biology, University of Pittsburgh, 1996 M.S. Molecular Biology/Biotechnology, East Carolina University, 2001 M.S. Biomedical Informatics, University of Pittsburgh, 2005 Submitted to the Graduate Faculty of School of Medicine in partial fulfillment of the requirements for the degree of Doctor of Philosophy University of Pittsburgh 2016 UNIVERSITY OF PITTSBURGH SCHOOL OF MEDICINE This dissertation was presented by Rick Matthew Jordan It was defended on December 2, 2015 and approved by Shyam Visweswaran, M.D., Ph.D., Associate Professor Rebecca Jacobson, M.D., M.S., Professor Songjian Lu, Ph.D., Assistant Professor Dissertation Advisor: Vanathi Gopalakrishnan, Ph.D., Associate Professor ii Copyright © by Rick Matthew Jordan 2016 iii LITERATURE MINING SUSTAINS AND ENHANCES KNOWLEDGE DISCOVERY FROM OMIC STUDIES Rick Matthew Jordan, M.S. University of Pittsburgh, 2016 Genomic, proteomic and other experimentally generated data from studies of biological systems aiming to discover disease biomarkers are currently analyzed without sufficient supporting evidence from the literature due to complexities associated with automated processing. Extracting prior knowledge about markers associated with biological sample types and disease states from the literature is tedious, and little research has been performed to understand how to use this knowledge to inform the generation of classification models from ‘omic’ data. Using pathway analysis methods to better understand the underlying biology of complex diseases such as breast and lung cancers is state-of-the-art. However, the problem of how to combine literature- mining evidence with pathway analysis evidence is an open problem in biomedical informatics research. -

Insight V-CHEM General Health Profile
【Product Name】 General Health Profile 【Packing Specification】 1 Disc / Sample 【Instrument】 See the InSight V-CHEM chemistry analyser Operator’s Manual for complete information on use of the analyser. 【Intended Use】 The General Health Profile used with the InSight V-CHEM chemistry analyser is intended to be used for the in vitro quantitative determination of total Protein (TP), albumin (ALB), total bilirubin (TBIL), alanine aminotransferase (ALT), blood urea (BUN), creatinine (CRE), amylase (AMY), creatinekinase (CK), calcium (Ca2+), phosphorus (P), alkaline Phosphatase (ALP), glucose (GLU), and total cholesterol (CHOL)in heparinised whole blood, heparinised plasma, or serum in a clinical laboratory setting or point of care location. The General Health Profile and the InSight V-CHEM chemistry analyser comprise an in vitro diagnostic system that aids the physician in the following disorders: liver and gall bladder diseases, urinary system diseases, carbohydrate metabolism disorders, lipid metabolism disorders, cardiovascular disease and pancreatic diseases. 【Test Principles】 This product, which is based on spectrophotometry, is used to quantitatively determine the concentration or activity of the 13 biochemical indicators in the sample. The test principles are as follows: (1) Total Protein (TP) The total protein method is a Biuret reaction, the protein solution is treated with cupric [Cu(II)] ions in a strong alkaline medium. The Cu(II) ions react with peptide bonds between the carbonyl oxygen and amide nitrogen atoms to form a coloured Cu-protein complex. The amount of total protein present in the sample is directly proportional to the absorbance of the Cu-protein complex. The total protein test is an endpoint reaction and the absorbance is measured as the difference in absorbance between 550 nm and 800 nm.