Arxiv:1811.01238V2 [Cs.CV] 21 Aug 2019
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Bass – Glaucomatous-Type Field Loss Not Due to Glaucoma
Glaucoma on the Brain! Glaucomatous-Type Yes, we see lots of glaucoma Field Loss Not Due to Not every field that looks like glaucoma is due to glaucoma! Glaucoma If you misdiagnose glaucoma, you could miss other sight-threatening and life-threatening Sherry J. Bass, OD, FAAO disorders SUNY College of Optometry New York, NY Types of Glaucomatous Visual Field Defects Paracentral Defects Nasal Step Defects Arcuate and Bjerrum Defects Altitudinal Defects Peripheral Field Constriction to Tunnel Fields 1 Visual Field Defects in Very Early Glaucoma Paracentral loss Early superior/inferior temporal RNFL and rim loss: short axons Arcuate defects above or below the papillomacular bundle Arcuate field loss in the nasal field close to fixation Superotemporal notch Visual Field Defects in Early Glaucoma Nasal step More widespread RNFL loss and rim loss in the inferior or superior temporal rim tissue : longer axons Loss stops abruptly at the horizontal raphae “Step” pattern 2 Visual Field Defects in Moderate Glaucoma Arcuate scotoma- Bjerrum scotoma Focal notches in the inferior and/or superior rim tissue that reach the edge of the disc Denser field defects Follow an arcuate pattern connected to the blind spot 3 Visual Field Defects in Advanced Glaucoma End-Stage Glaucoma Dense Altitudinal Loss Progressive loss of superior or inferior rim tissue Non-Glaucomatous Etiology of End-Stage Glaucoma Paracentral Field Loss Peripheral constriction Hereditary macular Loss of temporal rim tissue diseases Temporal “islands” Stargardt’s macular due -

Bilateral Acquired Progressive Retinal Nerve Fiber Layer Myelination
Bilateral Acquired Progressive Retinal Nerve Fiber Layer Myelination Abstract We present the multimodal imaging findings of an unusual case of bilateral acquired progressive myelination of the optic disc over a 10-year follow up period, in a hyperopic adolescent patient in the absence of an underlying ocular or systemic abnormality. Myelination of the left optic disc was noted at age 7 and of the right optic disc at age 13 but no other ocular or systemic abnormalities were identified. Cross sectional OCT and en face OCT angiography confirmed the presence of myelination of the retinal nerve fiber layer and excluded other etiologic possibilities including an astrocytic hamartoma. Keywords: Optic Nerve; Optic Fiber Myelination, Acquired, Hyperopia INTRODUCTION Myelination of the retinal nerve fiber layer occurs in 1% of the population and is most frequently congenital and non-progressive. (1) Congenital cases are typically isolated but may be rarely associated with the syndrome of ipsilateral high myopia, strabismus and amblyopia (2,3), although cases have been reported in hyperopic eyes. Reports of acquired and progressive myelination associated with congenital optic nerve disorders such as Arnold-Chiari malformation, hydrocephalus, optic disc drusen, and iatrogenic causes such as optic nerve sheath fenestration, are relatively rare.(4–8) PLEASE ADJUST THE REFERENCE CITATIONS While affected patients are typically asymptomatic, retinal nerve fiber layer myelination can be rarely associated with visual loss. Even more unusual are reports of acquired and progressive myelination of the nerve fiber layer. We present the multimodal imaging findings of such a case in a healthy young patient with a 10-year follow up. -

Central Serous Papillopathy by Optic Nerve Head Drusen
Clinical Ophthalmology Dovepress open access to scientific and medical research Open Access Full Text Article CASE REPORT Central serous papillopathy by optic nerve head drusen Ana Marina Suelves1 Abstract: We report a 38-year-old man with a complaint of blurred vision in his right eye for the Ester Francés-Muñoz1 previous 5 days. He had bilateral optic disc drusen. Fluorescein angiography revealed multiple Roberto Gallego-Pinazo1 hyperfluorescent foci within temporal optic discs and temporal inferior arcade in late phase. Diamar Pardo-Lopez1 Optical coherence tomography showed bilateral peripapillary serous detachment as well as right Jose Luis Mullor2 macular detachment. This is the first reported case of a concurrent peripapillary and macular Jose Fernando Arevalo3 detachment in a patient with central serous papillopathy by optic disc drusen. Central serous papillopathy is an atypical form of central serous chorioretinopathy that should be considered Manuel Díaz-Llopis1,4,5 as a potential cause of acute loss of vision in patients with optic nerve head drusen. 1 Department of Ophthalmology, La Fe Keywords: central serous papillopathy, peripapillary central serous chorioretinopathy, optic University Hospital, Valencia, Spain; For personal use only. 2Instituto de Investigación Sanitaria, nerve head drusen, peripapillary subretinal fluid Fundación para la investigación, La Fe Hospital, Valencia, Spain; 3Retina and vitreous service, Clínica Introduction Oftalmológica Centro Caracas, Optic nerve head drusen (ONHD) are hyaline material calcificated -

Neuroradiology for Ophthalmologists
Eye (2020) 34:1027–1038 https://doi.org/10.1038/s41433-019-0753-z REVIEW ARTICLE Neuroradiology for ophthalmologists 1 2 1 1,3,4,5,6,7 Bayan Al Othman ● Jared Raabe ● Ashwini Kini ● Andrew G. Lee Received: 3 June 2019 / Revised: 29 October 2019 / Accepted: 24 November 2019 / Published online: 2 January 2020 © The Author(s), under exclusive licence to The Royal College of Ophthalmologists 2020 Abstract This article will review the best approaches to neuroimaging for specific ophthalmologic conditions and discuss characteristic radiographic findings. A review of the current literature was performed to find recommendations for the best approaches and characteristic radiographic findings for various ophthalmologic conditions. Options for imaging continue to grow with modern advances in technology, and ophthalmologists should stay current on the various radiographic techniques available to them, focusing on their strengths and weaknesses for different clinical scenarios. Introduction Computed tomography (CT) 1234567890();,: 1234567890();,: Modern imaging technology continues to advance the CT imaging reconstructs a three-dimensional image made boundaries and increase the options available to physicians of many conventional x-ray images. The conventional x-ray with respect to neuroradiology. In ophthalmology, the most images are ordered in tomographic slices that have been common studies employed are computed tomography (CT) computerized so a viewer can scroll through the images, and magnetic resonance imaging (MRI). There are several analyzing sequential cross-sections [1]. Density is the pri- different types of protocols that provide unique advantages mary characteristic that determines image appearance on a and disadvantages depending on the clinical scenario. This CT scan. As with traditional x-rays, tissues appear on a grey article endeavours to review those options and discuss how scale ranging from white (i.e., hyperdense tissues such as they are best employed to evaluate a variety of specific bone) to black (i.e., hypodense materials such as air). -
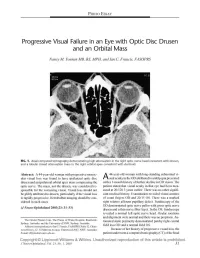
Progressive Visual Failure in an Eye with Optic Disc Drusen and an Orbital Mass
PHOTO ESSAY Progressive Visual Failure in an Eye with Optic Disc Drusen and an Orbital Mass Nancy M. Younan MB, BS, MPH, and Ian C. Francis, FASOPRS FIG. 1. Axial computed tomography demonstrating high attenuation in the right optic nerve head consistent with drusen, and a lobular mixed attenuation mass in the right orbital apex consistent with dermoid. Abstract: A 44-year-old woman with progressive monoc 44-year-old woman with long-standing subnormal vi ular visual loss was found to have ipsilateral optic disc A sual acuity in the OD attributed to amblyopia presented drusen and an ipsilateral orbital apex mass compressing the with a 1-month history of further decline in OD vision. The optic nerve. The mass, not the drusen, was considered re patient stated that visual acuity in that eye had been mea sponsible for the worsening vision. Visual loss should not sured at 20/120 3 years earlier. There was no other signifi be glibly attributed to drusen, particularly if the visual loss cant medical history. Examination revealed visual acuities is rapidly progressive. Retrobulbar imaging should be con of count fingers OD and 20/15 OS. There was a marked sidered in such cases. right relative afferent pupillary defect. Funduscopy of the OD demonstrated optic nerve pallor with gross optic nerve (JNeuro-Ophthalmol 2003;23: 31-33) drusen and a thin nerve fiber layer. In the OS, funduscopy revealed a normal left optic nerve head. Ocular rotations and alignment were normal and there was no proptosis. Au The Ocular Plastics Unit, The Prince of Wales Hospital, Randwick, tomated static perimetry demonstrated patchy right central Sydney, Australia, and the University of NSW, Sydney, Australia. -

Optic Disc Drusen, Glaucoma, Or Could It Be Both?
Title: Where are the defects coming from…Optic Disc Drusen, Glaucoma, or could it be both? Authors: Rachel Goretsky OD, Biana Gekht OD Abstract: Optic disc drusen and glaucoma cause similar retinal nerve fiber layer(RNFL) as well as visual field defects. This paper describes a patient who has both conditions and the management involved. I. Case History: 66 year old African-American male presents for dilation and imaging. Patient has a history of Glaucoma for several years; he is taking Brimonidine bid OU and Latanoprost qhs OU with reported good compliance. Medical & Ocular History: • Hypertension, gout, cholesterol and stents placed in leg and chest. Glaucoma OU. History of peripheral iridotomy OU one year ago. Medications:Amplodipine, clopidogrel, allopurinol II. Pertinent findings: • Maximum pressure history is 17 OD, 19 OS, current visit 16 OD, 19 OS • Anterior chamber : Grade 2 Van Herick Angles OU • Iris: Peripheral Iridotomy, patent at 12 o’clock OD,OS • Optic disc: 0.3r OD, OS small nerves, mild blurry margins indicative of disc drusen • Macula: diffuse epiretinal membrane OU • Pachymetry : 556 OD/ 566 OS • Gonioscopy: open to trabecular meshwork (TM) superiorly, otherwise no structures visible OD, open to TM inferiorly, otherwise no structures visible OS • Spectralis Optical Coherence Tomography(OCT): optic disc drusen with small cups and disc area OU • Visual field exhibited no defects OD, inferior nasal defects OS. III. Differential Diagnosis: • Papilledema, tilted discs, pseudotumor cerebri, myelinated nerve fiber layer IV. Diagnosis and Discussion Optic nerve head drusen are hyaline deposits made of calcium phosphate as well as amino acids, among other materials. -
Optic Nerve on Sheath:
3/16/2018 < Optic nerve axons of retinal ganglion cells 1.2 million nerve fibers . ON sheath: continuous with the meninges dura、arachnoid and pia mater 1 3/16/2018 optic nerve functions 1.Visual Acuity 2.Color Vision 3.Pupil 4.Contrast sensitivity Ancillary Tests 1.Visual Field 2.Neuro-imaging 3.OCT 4.VEP Etiology:Optic nerve diseases 1.inflammation:optic neuritis 2 . ischemic optic neuropathy 3-Compression 4-Granuloma & infiltration 5-Hereditary 6-Toxic 7-Irradiation 8- Trauma . 2 3/16/2018 Optic Neuritis 3-Neuroretinitis 1-Retrobulbar neuritis 2-Papillitis Papillitis optic disc is normal hyperemia and edema with macular star . in adults common in children. least common type with multiple sclerosis. viral infections Rapid unilateral loss of vision RAPD Loss of color vision Pain in moving the eye Swollen disc with or without peripapillary flame-shaped hemorrhages. 3 3/16/2018 Fig optic neuritis Centrocecal scotoma Bilateral optic neuritis Bilateral Central scotoma 4 3/16/2018 Bilateral hemianopsia MRI demyelinating lesions multiple sclerosis Neuromylitis Optica VF showed non- central scotoma altitudinal VF an ischemic mechanism play a role in ON in NMO patients 5 3/16/2018 Optic Neuritis Follow Up Diffuse and central loss in the affected eye at baseline Follow Up : nerve fiber bundle defects were the predominant localized abnormalities in both the affected and fellow eyes physicians evaluate the characteristics of optic neuritis and other optic neuropathies in the future Ischemic optic neuropathy ( ION) 6 3/16/2018 Anterior ischemic optic neuropathy ( AION ) Arteritic Non- Arteritic GCA - vasculitis hypoperfusion of ONH transient visual loss, temporal sudden painless loss of vision pain, jaw pain, fatigue, weight loss hyperemic disc Pale disc Sectorial, diffuse edema optic disc edema splinter hemorrhages of a chalky white color Subsequent optic atrophy Nonarteritic ischemic optic neuropathy visual field altitudinal field defect 7 3/16/2018 NAION sudden, painless visual loss OS shows AION . -

Mizuo-Nakamura Phenomenon in Oguchi Disease Due to A
Correspondence 1098 lattice-like degeneration,4 non-neovascular vitreous haemorrhage,5 and myopia.4 Occasionally elevated blood vessels have been demonstrated secondary to vitreous traction.6 We postulate that in this case separation of intact retinal vascular arcades from the retina occurred because of antero–posterior mechanical forces on already dragged retinal vessels under tension when PVD occurred. Kingham also advocated conservative management for such cases. Conflict of interest The authors declare no conflict of interest. References 1 Shaikh S, Trese MT. New Insights into progressive visual loss in adult retinopathy of prematurity. Arch Ophthalmol 2004; 122(3): 404–406. 2 Tasman W. Vitreoretinal changes in cicatrical retrolental fibroplasias. Trans Am Ophthalmol soc 1970; 68: 548–594. 3 Kingham JD. Acute retrolental fibroplasia. II. Treatment by cryosurgery. Arch Ophthalmol 1978; 96(11): 2049–2053. 4 Smith BT, Tasman WS, Young TL, Wilson ME, Raab EL, Paysse EA et al. Retinopathy of prematurity: late complications in the baby boomer generation (1946–1964). Trans Am Ophthalmol Soc 2005; 103: 225–234. 5 Quiram PA, Capone Jr A. Adult ROP: late complications of retinopathy of prematurity. Retinal Physician 2007; 4(5): 25–28. 6 Tasman W, Brown GC. Progressive visual loss in adults with retinopathy of prematurity (ROP). Trans Am Ophthalmol Soc 1988; 86: 367–379. S Tarafdar, EE Obi and JR Murdoch Tennent Institute of Ophthalmology, Gartnavel Figure 1 (a) A nasally dragged disc and retinal vessels. (b) Intact General Hospital, Glasgow, Scotland, UK avulsed retinal vessels floating freely in the vitreous cavity. E-mail: [email protected] avulsed retinal vessels floating freely in the vitreous Eye (2011) 25, 1097–1098; doi:10.1038/eye.2011.86; cavity was present (Figure 1b). -

Frcs Knights
Frcs knights FRCS Glasgow Experience 5 trials to success by Kareem Elsheikh I start with the name of Allah Al-Rahman Al-Rahim. 1st I want to thank Allah Al-Ali Al-Kadeer for my success. Then I will mention some advices before starting. - You must know that success is a gift from the God just you try hard, study & study, practice & practice if you succeed so you are winner & if failed do not be sad it is not a defect in you it is only The God's will . Stand up try again & again - Sources for study are different so find books that you feel comfort with it. For me: - Wong : was my 1ry source I studied it more than 15 times in my 5 trials I think it is the corner stone in 3rd part although it has some mistakes &defects that I corrected from other sources. - Dr Walled Bader Internal medicine notes: they are very helpful in viva - Wills eye manual: It was my source in 2nd Part & was a reference in 3rd part specially in some topics that is not fulfilled in wong e.g: conjunctiva, Lid & orbit - Cake Walk : also a great book but very defective you can not study it alone. I read it fast reading then I marked on the topics that is not in wong for being repeated & studied good ( specially 1st 70 pages that are very helpful) also I copied single information by hand write to my 1ry source (wong). - Kanski synopsis: A great friend -who studded this book in his FRCs & succeeded told me to try it. -

Anatomic and Visual Function Outcomes in Paediatric Idiopathic Intracranial Hypertension Sidney M Gospe III,1 M Tariq Bhatti,1,2 Mays a El-Dairi1
Downloaded from http://bjo.bmj.com/ on April 14, 2016 - Published by group.bmj.com Clinical science Anatomic and visual function outcomes in paediatric idiopathic intracranial hypertension Sidney M Gospe III,1 M Tariq Bhatti,1,2 Mays A El-Dairi1 1Department of ABSTRACT Monitoring of papilledema severity and early Ophthalmology, Duke Background There is a paucity of literature describing detection of optic atrophy in patients with IIH University Medical Center, Durham, North Carolina USA risk factors for vision loss in paediatric idiopathic have been greatly aided by advances in spectral 2Department of Neurology, intracranial hypertension (IIH). We investigate the final domain optical coherence tomography (SD-OCT). Duke University Medical visual function, spectral domain optical coherence This non-invasive imaging modality is now com- Center, Durham, North tomography (SD-OCT) and enhanced depth imaging monly used to measure the thickness of the peripa- Carolina, USA (EDI)-OCT findings in children with papilledema caused pillary RNFL in IIH, glaucoma and other optic 5–7 Correspondence to by IIH. neuropathies. Moreover, the high resolution of Dr Mays A El-Dairi, Methods Medical records of 31 patients with SD-OCT has allowed pathology of specific layers of Department of Ophthalmology, paediatric IIH (age ≤17 years) were retrospectively the retina to be analysed qualitatively and quantita- Duke Eye Center, Duke reviewed. Optic disc photographs on presentation and tively, and we have recently described examples of university, P.O. Box 3802, Durham, NC 27710, USA; automated perimetry, SD-OCT and EDI-OCT imaging on focal atrophy of retinal layers in the macula in [email protected] final follow-up visit were statistically analysed to identify adult patients with IIH that is distinct from the patient characteristics and anatomic findings associated already-well-described RGC and RNFL changes.8 Received 17 April 2015 with irreversible vision loss. -

The Diagnostic Dilemma of Pseudopapilledema
The Diagnostic Dilemma of Pseudopapilledema Tiffenie Harris, OD, FAAO Associate Professor Western University College of Optometry Author’s Bio Dr. Harris is a graduate of Indiana University School of Optometry. She practiced primary care optometry in the Detroit Metropolitan Area for 10 years prior to starting her academic career in 2004 at her Alma matter. She joined Western University College of Optometry in 2008. Dr. Harris is the Course Director for Principles and Practice of Anterior Segment and Posterior Segment courses. Diagnostic Dilemma Optic nerve head (ONH) elevation tends to be the most intimidating ocular finding especially when it presents bilaterally. The purpose of this article is to provide the clinician with clinical strategies that will enhance their assessment and management of bilateral disc elevations. In addition, this topic is important to review because effective management will reduce over-referrals for neurological evaluations, thus decreasing health care costs while avoiding needless and expensive neurological testing. The optometrist’s role includes detection of disease with a timely and appropriate referral to specialists as well as co-management and/or monitoring once under the care of a physician. A clinical case in which the optic nerves are severely swollen is easy to diagnose. Yet, a case in which the nerves appear to be mildly or moderately elevated or swollen makes the diagnosis more challenging, especially when the patient presents with symptoms of headaches. This type of quandary frequently can cause alarm for the clinician, which often eclipses the fact that the patient has no other signs or symptoms of increased intracranial pressure (ICP). -

Clinical Features of Optic Disc Drusen in an Ophthalmic Genetics Cohort
Hindawi Journal of Ophthalmology Volume 2020, Article ID 5082706, 8 pages https://doi.org/10.1155/2020/5082706 Research Article Clinical Features of Optic Disc Drusen in an Ophthalmic Genetics Cohort Jasmine Y. Serpen,1,2 Lev Prasov,1,3,4 Wadih M. Zein,1 Catherine A. Cukras,1 Denise Cunningham,1 Elizabeth C. Murphy,1 Amy Turriff,1,5 Brian P. Brooks,1 and Laryssa A. Huryn 1 1National Eye Institute, National Institutes of Health, Bethesda, MD 20892, USA 2Case Western Reserve University School of Medicine, Cleveland, OH 44106, USA 3Department of Ophthalmology and Visual Sciences, Kellogg Eye Center, University of Michigan, Ann Arbor, MI 48105, USA 4Department of Human Genetics, University of Michigan, Ann Arbor, MI 48109, USA 50e National Human Genome Research Institute, National Institutes of Health, Bethesda, MD 20892, USA Correspondence should be addressed to Laryssa A. Huryn; [email protected] Received 17 June 2020; Revised 19 August 2020; Accepted 19 September 2020; Published 6 October 2020 Academic Editor: Stefano Baiocchi Copyright © 2020 Jasmine Y. Serpen et al. )is is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Background/Aims. Optic disc drusen (ODD) are calcified deposits of proteinaceous material in the optic disc, and their burden in ocular conditions is unknown. As ODD can be associated with visual field defects further compromising already degenerating visual function in patients with retinal degenerations, it is important to further our knowledge of ODD in inherited eye disease.