Chip Shop Map of the UK
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Jinjuu Updated Menu.Pdf
SOHO STARTERS SNACKS RAW PLATES MANDOO / DUMPLINGS JINJUU’S ANJU SHARING BOARD 24 3 PER SERVING (extra maybe ordered by piece) YOOK-HWE STEAK TARTAR 14 FOR 2 VEGETABLE CHIPS & DIPS (v, vg on request) 6 Diced grass fed English beef fillet marinated in soy, ginger, Kong bowl, sae woo prawn lollipops, signature Korean fried chicken, BEEF & PORK MANDOO 7.5 Crispy vegetable chips, served with kimchi soy guacamole. Juicy steamed beef & pork dumplings. Seasoned delicately garlic & sesame. Garnished with Korean pear, toasted steamed beef & pork mandoo, mushroom & true mandoo. pinenuts & topped with raw quail egg. with Korean spices. Soy dipping sauce. KONG BOWL (v) (vg, gf on request) 5 small / large JINJUU’S YA-CHAE SHARING BOARD (v) 20 PHILLY CHEESESTEAK MANDOO 7.5 Steamed soybeans (edamame) topped with our Jinjuu chili SEARED TUNA TATAKI (gf on request) 12 / 18 FOR 2 Crispy fried dumplings stued with bulgogi beef short ribs, panko mix. Seared Atlantic tuna steak in panko crust, topped with kizami Kong bowl, tofu lollipops, signature Korean fried cauliflower, cheddar, mushrooms, spring onion & pickled jalapeno. Spicy wasabi & cucumber salsa, served on a bed of julienne daikon. steamed mushroom & true mandoo. dipping sauce. TACOS SALMON SASHIMI (gf on request) 12 WILD MUSHROOM & TRUFFLE MANDOO (v) 7.5 2 PER SERVING (extra maybe ordered by piece) Raw Scottish salmon sashimi style, avocado, soy & yuja, Steamed dumplings stued with wild mushrooms & black seaweed & wasabi tobiko. K-TOWN MINI SLIDERS trues. True soy dipping sauce. 12 2 PER SERVING (extra maybe ordered by piece) BULGOGI BEEF TACO TUNA TARTAR (gf on request) 12 TRIO MANDOO TASTING PLATE 7.5 Bulgogi UK grass fed beef fillet, avocado, Asian slaw, kimchi, Diced raw Atlantic tuna, dressed with sesame oil, soy, One of each dumpling listed above. -

Great Food, Great Stories from Korea
GREAT FOOD, GREAT STORIE FOOD, GREAT GREAT A Tableau of a Diamond Wedding Anniversary GOVERNMENT PUBLICATIONS This is a picture of an older couple from the 18th century repeating their wedding ceremony in celebration of their 60th anniversary. REGISTRATION NUMBER This painting vividly depicts a tableau in which their children offer up 11-1541000-001295-01 a cup of drink, wishing them health and longevity. The authorship of the painting is unknown, and the painting is currently housed in the National Museum of Korea. Designed to help foreigners understand Korean cuisine more easily and with greater accuracy, our <Korean Menu Guide> contains information on 154 Korean dishes in 10 languages. S <Korean Restaurant Guide 2011-Tokyo> introduces 34 excellent F Korean restaurants in the Greater Tokyo Area. ROM KOREA GREAT FOOD, GREAT STORIES FROM KOREA The Korean Food Foundation is a specialized GREAT FOOD, GREAT STORIES private organization that searches for new This book tells the many stories of Korean food, the rich flavors that have evolved generation dishes and conducts research on Korean cuisine after generation, meal after meal, for over several millennia on the Korean peninsula. in order to introduce Korean food and culinary A single dish usually leads to the creation of another through the expansion of time and space, FROM KOREA culture to the world, and support related making it impossible to count the exact number of dishes in the Korean cuisine. So, for this content development and marketing. <Korean Restaurant Guide 2011-Western Europe> (5 volumes in total) book, we have only included a selection of a hundred or so of the most representative. -

The North East's Favourite!
Welcome to The Ashvale Over 30 years of award winning fish and chips Delicious and nutritious Produced by Compass Print Group Ltd, Aberdeen. 01224 875987 The North East’s Favourite! Tasty Choice Meal Deals MEAL DEAL 1 MEAL DEAL 2 Consists of Consists of Standard Jumbo Haddock Supper £9. 90 Haddock Supper £11. 20 served with Mushy Peas or Curry Sauce served with Mushy Peas or Curry Sauce PLUS 500ml Bottle of Soft Drink PLUS 500ml Bottle of Soft Drink Lunchtime Take-Away Meal Deals Available 11.45 a.m. to 2.00 p.m. Fish & Chips + a Can Mince Pie & Chips + a Can Meal Jumbo Sausage & Chips + a Can +330ml Can Smoked Sausage & Chips + a Can King Rib & Chips + a Can ic Beef/Cheeseburger & Chips + a Can £5. 50 ! tast ow Fan Veggie Burger & Chips + a Can W e! Add a side ONLY £1 - Curry Sauce • Gravy • Beans • Mushy Peas Valu Produced by Compass Print Group Ltd, Aberdeen. 01224 875987 The North East’s Favourite! Produced by Compass Print Holdings Ltd, Aberdeen. 01224 875987 Fish, Scampi, Senior & Kids Meals Fish Exclusive to the Ashvale (Freshest Haddock you will eat!) Scampi Single Supper Single Supper Jumbo Haddock (8oz) £6.80 £9.60 Breaded Scampi £5.40 £8.20 Standard Haddock (5/6oz) £5.50 £8.30 Battered Scampi £6.20 £9.00 Small Haddock (4oz) £4.80 £7.60 Jumbo Fish Cake (Breaded) £4.50 £7.30 Kids Meal Boxes Haddock, Sausage, Scampi, Senior Citizen Special Chicken Nuggets, Hot Dog, ALL WITH CHIPS Fish Cake, Burger, Cheeseburger Small Haddock £6.65 or Pizza £5.00 Chicken Fillets £6.65 Served with Chips, Peas or Beans PLUS Soft Drink 330ml Breaded Scampi £6.65 Produced by Compass Print Group Ltd, Aberdeen. -

African / Caribbean African Products Asian Asian
2010 Washington Blvd. Baltimore, MD 21230 Ph: 301.322.4503 | Fax: 301.322.4504 [email protected] | www.emdsalesinc.com AFRICAN / CARIBBEAN CANDLES DRY PASTA - SOUPS FLOUR AFRICAN PRODUCTS CANDY / DESSERT CANNED FISH AND MEATS FRUITS AND VEGETABLES ASIAN CARIBBEAN - WEST INDIAN HALAL - KOSHER ASIAN GROCERY CENTRAL AMERICAN HISPANIC SODAS BANANA LEAVES CHEESES HOLIDAY PRODUCTS BEANS CHIPS AND SNACKS HOT SAUCES BREAKFAST CLEANSERS HOUSE BEAUTY CENTER COCONUT PRODUCTS HOUSEWARES CONDIMENTS JUICES - NECTARS COOKIES AND CRACKERS LAUNDRY CREAMS MALTA MEXICAN MISCELLANEOUS OILS AND LARDS OTHERS PERUVIAN PERUVIAN PRODUCTS REF TORTILLA RICE SPICES - BOULLIONS TORTILLAS YOGURTS AFRICAN / CARIBBEAN G. KRUST SPICY BEEF PATTIES 15 OZ G. KRUST VEGETABLE PATTIES 15 OZ Item Pack: 12 Item Pack: 12 Item Size: 15 OZ Item Size: 15 OZ UPC: 72113470003 UPC: 72113470008 G. KRUST MILD BEEF PATTIES 15 OZ G. KRUST MICROWAVE S. BEEF PATTIES 10 OZ Item Pack: 12 Item Pack: 12 Item Size: 15 OZ Item Size: 10 OZ UPC: 72113470004 UPC: 72113470024 G. KRUST MICROWAVE M. BEEF PATTIES 10 OZ G. KRUST MICROWAVE CHICKEN PATTIES 10 OZ Item Pack: 12 Item Pack: 12 Item Size: 10 OZ Item Size: 10 OZ UPC: 72113470025 UPC: 72113470027 G. KRUST CHICKEN PATTIES 15 OZ T. ICE GREEN TEA ICE BAR 4 CT Item Pack: 12 Item Pack 6 Item Size: 15 OZ Item Size 4/2.5 Z UPC: 72113470006 UPC 08373731428 YISSINE DUMPLING WRAPPER 14 OZ ASSI PORK DUMPLINGS 1.25 LBS Item Pack 24 Item Pack 20 Item Size 14 OZ Item Size 1.25 LB UPC 01865220538 UPC 08165220571 #Na me? ASIAN OTASTY BBQ PORK BUNS BAO 24 OZ T. -

12382 Siaway Chippy Takeaway Leaflet Gatefold.Indd
BREAKFAST BOX 6 of the best... SIDES Full Scottish Breakfast Box with Baked Beans Siaway Coleslaw or Tartare Sauce £1.50 ME £5.95 GE Our fried products are lightly Salad Box £2.50 Veggie Scottish Breakfast Box with Baked Beans battered with Highland Spring Curry Sauce or Gravy £1.50 G £5.95 GE Onion Rings £2.50 G water and cooked traditionally in FISH - Single/Supper beef dripping. Mushy Peas or Beans £1.50 BREAKFAST ROLLS Pickled Egg or Onion 60p E GFE (Extra filling 80p / Extra Egg 50p / Haddock Single £7.30/£8.30 Vegetarian, vegan and gluten free Tattie Scone 40p) Panko Breaded Haddock Single £7.95/£8.95 GFE options also available. KIDS (with chips) G Wholetail Breaded Scampi with lemon wedge Haddock £4.60 GF Bacon £2.40 £7.95/£8.95 GH Scampi £4.60 GD Egg £2.40 GE Homemade Panko Breaded Fishcake Smoked Sausage £3.60 B Black Pudding £2.40 G £5.50/£6.50 GF TASTE OF THE HIGHLANDS Regular Sausage £3.60 Haggis £2.40 G Calamari with lemon wedge £4.95/£5.95 GA - Single/Supper G Tempura Battered King Prawns with Chicken Nuggets £3.60 Sausage (Lorne or Link) £2.40 G Speyside Haggis or Veggie Haggis £5.25/£6.25 G Sweet Chilli Sauce £7.95/£8.95 GD Cheesy Chips £2.45 M Tattie Scone £1 G Speyside Puddings: Black, White or Red £5.25/£6.25 G Chips: Small cone or large cone £1.95/£2.95 Panko Breaded Scallops £8.50/£9.50 GA SLUSH PUPPIES FILLED MORNING ROLLS Cheesy Chips £3.95 M Regular £1.50 Scottish Salmon Single £8.50/£9.50 MF Chip Butty £2.60 G Large £2 Salad Rolls: Isle of Skye Creel Pot (Squats, Mussels or Langoustines Green Salad £1 GM GM If -

Soho Alc 2017 Front Website
SOHO ANJU / SMALL PLATES VEGETABLE CHIPS & DIPS 6.5 K-TOWN MINI SLIDERS TWO PER SERVING MANDOO / DUMPLINGS FOUR PER SERVING TACOS TWO PER SERVING Crispy vegetable crisps, served with tomato soy salsa EXTRA SLIDER(S) MAY BE ORDERED BY PIECE EXTRA DUMPLING(S) MAY BE ORDRED BY PIECE EXTRA TACO(S) MAY BE ORDERED BY PIECE & kimchi guacamole. KOREAN FRIED CHICKEN SLIDERS 8 MANDOO (Beef & Pork) 8 SHORT RIB BEEF TACOS 9 KONG BOWL (v) 5 Golden fried chicken thighs, our signature sauces, mayo, Juicy steamed beef & pork dumplings. Seasoned delicately with Korean spices. Chipotle short rib tacos, avocado, gem lettuce, red onion, kimchi, Steamed soybeans (edamame) topped with our Jinjuu chili panko mix. crispy iceberg lettuce, tossed in a brioche bun. Soy dipping sauce. sour cream & topped with coriander. PORK & KIMCHI SOUP 6.5 BULGOGI SLIDERS 8 PHILLY CHEESESTEAK 8 PORK BELLY TACOS 9 Artisan English pork stewed with homemade kimchi, tofu & spring onions. House ground beef burger jazzed up with Korean spices. Thinly sliced English artisanal pork belly marinated in Korean spices, Cooked pink & topped with homemade pickle, cheddar & bacon. shitake, spring onion & pickled jalapeno. Spicy dipping sauce. apple, kimchi & Asian slaw. 9 JINJUU’S SIGNATURE KOREAN FRIED CHICKEN (v) 7 (v) 8 Chicken thighs (boneless) crispy fried in our famous batter. KOREAN FRIED TOFU SLIDERS YA-CHAE MANDOO (Vegetable) (v) 7.5 MUSHROOM TACOS Pickled white radish on the side & paired with our signature sauces: Golden fried crispy tofu, our signature sauces, mayo & crispy Miso sauteed portobello mushroom, kale & black beans, feta cheese, Gochujang Red & Jinjuu Black Soy. -

Thank You for Your Custom
Jin Go Gae Korean Restaurant Thank you for your custom There will be 10% service charge added to your final bill. Any customers with food allergies please ask staff for assiistance. Ban-chan Pickles P1. 김치 Kimchi .................................... 2.9 Famous spicy Korean preserved cabbage P2. 깍두기 Kkagdugi .............................. 2.9 Preserved spicy raddish kimchi made from P1. 김치 white daikon Kim-chi P3. 숙주나물 Sugju Namul .......................... 2.9 Mung bean sprouts seasoned with sesame oil P4. 시금치나물 Sigeumchi Namul ................. 2.9 P4. 시금치나물 Seasoned spinach with sesame oil Sigumchi Namul P5. 채나물 Chae Namul ........................... 2.9 Pickled sweet & sour white radish P6. 모듬나물 Mixed seasonal pickles ............. 5.9 P6. 모듬나물 Mixed seasonal pickles P7. 파절이 PaJeori (per person)....................... 2.9 Thinly sliced spring onions salad drizzled in chilli powder, sesame seed and oil P8. 상추 Sangchu ...................................2.5 Fresh seasonal assorted green lettuce P9. 무쌈 Moo- Sam ................................. 2.5 P9. 무쌈 Thinly sliced sweet organic beetroot mooli Moo -Sam P10. 치킨무 Korean Pickle Radish............................2.9 Cubes of sweet fermented white Mu radish Please be aware all our food may contain sasame seeds and soya, please ask for assistance An-Joo Starter 1. 파전 Par-Jeon (Highly recommended)............... 9.5 Korean squid pancake with spring onions and crab sticks 2. 김치전 Kim-Chi Jeon............................ 9.5 Kimchi pancake 1. 파전 Par-Jeon 3. 잡채 Jap-Chae (Highly recommended).............. 10 Thin glass vermicelli pan fried with mixed vegetables with beef 4. 군만두 Mandu (6 Pieces).......................... 8.5 Home handmade meat or vegetable fried dumplings 5. 진고개 쌀순대 Sundae (black pudding) ..... 16.9 Home made steamed, rice stuffed black 3. -
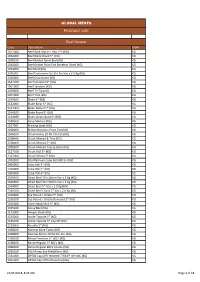
GLOBAL MEATS PRODUCT LIST Beef Generic
GLOBAL MEATS PRODUCT LIST Beef Generic Code Description UOM 1071000 Beef Back Ribs 6-7 Ribs LPF (KG) KG 1034000 Beef Blade Diced 5* (KG) KG 1028100 Beef Brisket Navel End (KG) KG 1040200 Beef Brisket Point End Boneless Diced (KG) KG 1074000 Beef Butt (KG) KG 1026001 Beef Cantonese Cut Stir Fry Vac x 2.5 Kg (KG) KG 1545000 Beef Osso Bucco (KG) KG 1547100 Beef Schnitzel 5* (KG) KG 1061000 Beef Tendons (KG) KG 1059000 Beef Tri-Tip (KG) KG 1057000 Beef Trim (KG) KG 1534200 Blade 5* (KG) KG 1532000 Blade Bolar 5* (KG) KG 1534000 Blade Netted 5* (KG) KG 1534100 Blade Roast 5* (KG) KG 1534099 Blade Steak Sliced 5* (KG) KG 1048300 Bone Marrow (KG) KG 1027001 Braising Steak (KG) KG 1028000 Brisket Boneless Point End (KG) KG 1048100 Chuck Bones 20 KG Ctn Fzn (KG) KG 1038400 Chuck Minced & Trim (KG) KG 1538000 Chuck Minced 5* (KG) KG 1038300 Chuck Minced Coarse 8mm (KG) KG 1527100 Chuck Roll 5* (KG) KG 1527000 Chuck Whole 5* (KG) KG 1000300 City Platinum Cube Roll MB 2+ (KG) KG 1400000 Cube Roll 4* (KG) KG 1500000 Cube Roll 5* (KG) KG 1600000 Cube Roll 6* (KG) KG 1040400 Diced Beef 10 x 10mm Vac x 2 Kg (KG) KG 1040500 Diced Beef 20 x 20mm Vac x 2 Kg (KG) KG 1540000 Diced Beef 5* Vac x 2.0 Kg (KG) KG 1540100 Diced Beef Chuck 5* Vac x 2.0 Kg (KG) KG 1526000 Eye Round / Girello 5* (KG) KG 1526100 Eye Round / Girello Denuded 5* (KG) KG 1636000 Flank Steak/Skirt 6* (KG) KG 1045100 Gravy Beef (KG) KG 1143000 Hanger Steak (KG) KG 1535000 Inside Topside 5* (KG) KG 1535100 Inside Topside 5* Cap Off (KG) KG 1529000 Knuckle 5* (KG) KG 1048200 Marrow Bone Tubes -

Polombos-Takeaway-Menu.Pdf
Single +Chips Single +Chips Single +Chips +Chips Fish (Battered) £2.90 £4.90 Vegetable Spring Roll £1.90 £3.90 Regular Chips £2.20 Homemade Coleslaw £1.70 Chicken Burger £2.70 £4.70 Lasagne £5.40 £7.40 Garlic Bread (3) £2.50 Homemade Lentil Soup £1.70 Fish (Breaded) £3.20 £5.20 1/2 Fried Pizza £1.80 £3.80 + Cheese £3.80 Curry Sauce £0.90 Vegetable Burger £2.50 £4.50 Chilli £4.80 £6.80 with Cheese £4.10 Fish (Gluten Free) £3.20 £5.20 1/2 Pizza Crunch £1.90 £3.90 + Curry £3.10 Gravy £0.90 1/4lb Beef Burger £2.30 £4.30 Baked Potatoes £2.40 Macaroni £4.80 £6.80 with Tomatoes £2.90 Fish Cake £2.20 £4.20 Large Chips £3.30 Mushy Peas £1.20 1/2lb Beef Burger £4.20 £6.20 + Cheese £4.00 with Ham £3.50 Calamari Rings (3) £2.90 £4.90 + Cheese £5.70 Baked Beans £1.20 1/4lb Cheese Burger £2.70 £4.70 + Chicken Mayo £3.90 Onion Rings £2.50 Scampi (4) £2.90 £4.90 + Curry £4.50 1/2lb Cheese Burger £4.90 £6.90 + Tuna Mayo £4.20 Battered Mushrooms £3.40 Chicken Nuggets (4) £2.00 £4.00 Potato Fritter £0.60 1/4lb Chilli Burger £4.60 £5.60 + Beans £3.90 (10) with Garlic Mayo Dip Sausage £1.50 £3.50 Pickled Onions £0.30 1/2lb Chilli Burger £6.50 £8.50 +Chilli £5.40 Breaded Mushrooms £4.40 Vegtable Pakora (4) £1.90 £3.90 Pickled Eggs £0.90 1/4lb Chilli Cheese £4.80 £6.80 +Coleslaw £3.70 (10) with Garlic Mayo Dip Pickled Gherkins £0.90 1/2lb Chilli Cheese £7.10 £9.10 Bread Roll £0.50 1/4lb Cheese & Bacon £3.80 £5.80 Chippy Small Meals Buttered Roll £0.60 Chippy Choice 1/2lb Cheese & Bacon £6.00 £8.00 Burger bar gourmet & baked Single +Chips Single +Chips Single -
Catering Menu 2021 7 17.Pub
A summer favorite. Orecchiette pasta tossed with Toasted almond slivers, lemon zest, Extra Virgin Olive Oil, and Parmigiano Reggiano Cheese. A light refresh- ing pasta salad that will leave you wanting more. Serves 8 1 WELCOME TO OUR MENU For 4 Generations we’ve been serving our customers with the same excellence that everyone has come to expect when they shop at Cafasso’s. Chef Michael Cafasso coordi- nates the enormous kitchen operations with the same attention and love as you would find in your kitchen at home. Great pride is taken in preparing all of the food for your party . It’s prepared exclusively for you with the same attention, freshness and quality that goes into everything we do. This menu offers a variety of favorite specialties which go well at parties where the food is to be served in Chafer style warming dishes. Our staff aims to please , special requests are a specialty of ours. We also can refer Servers for your party to assist in setup, serving and cleanup. You will notice reference on the cover to Our Cafasso’s “A Casa” Service. This is our in your home catering service. We plan, coordinate and create a complete party in your home or at a venue of your choice. This service has size limitations and minimums you Must call us for this service WHAT YOU NEED TO KNOW TO ORDER For our customers who feel more comfortable talking to us , Our Catering Phones are open from 10 am—5pm Monday through Friday You Can order Online at www.Cafasso’s.com You Can view Photos at Instagram, Facebook or #cfmktfood We take Orders for Pickup everyday of the week including Sundays We deliver everyday of the week . -

Desserts PASTA & WOKS PIZZA WHITE WINE Tap Wine BREAKFAST
All kids main meals come with a “Busy Nipper SPARKLING WINE WHITE WINE PASTA & WOKS KIDS Activity Bag” or a soft drink. BREAKFAST Available until 5pm 150ml 250ml Bottle Spaghetti Bolognaise Nuggets and Chips _________________________________ 9.90 Cereal Yellowglen Yellow Brut Cuvée 150ml 250ml Bottle the traditional favourite Cornflakes, Nutri-Grain, Just Right, topped with parmesan _____________________________ 19.90 Spaghetti Bolognaise topped with parmesan _______ 9.90 Rice Bubbles, Special K _______________________________ 5.00 200ml (S.E. Australia) 9.00 Wynns Coonawarra Estate Riesling (Coonawarra, S.A.) 9.00 14.00 34.90 Chicken Schnitzel, Chips and Gravy ______________13.90 Toast (GF) Yellowglen Yellow Brut Cuvée Chilli Chicken Spaghetti toasted Irrewarra sourdough served with Toasted Cheese Sandwich and Chips (GF) _________ 7.90 (S.E. Australia) 19.90 Seppelt Drumborg Riesling pan seared chicken, bacon and onion in chilli a selection of jams ___________________________________ 6.00 ghee with baby spinach and grana padano ___________ 22.90 (Henty, Vic) 49.90 Calamari and Chips _______________________________ 9.90 Café Style Raisin Toast _____________________________ 6.00 Yellowglen Pink Soft Rosé (S.E. Australia) 19.90 Blackwood Park Riesling Garlic Prawn Penne Grilled Fish and Salad (GF) ________________________ 9.90 Apple, Cranberry & Muesli Bread __________________ 8.90 (Goulburn River, Central Vic) 35.00 pan seared tiger prawns in a garlic cream sauce Fried Fish and Chips ______________________________ 9.90 Banana Bread Stony Peak Brut tossed with penne and baby spinach pan fried banana bread served with (S.E. Australia) 6.00 21.90 Penfolds Bin 51 Riesling and topped with parmesan __________________________25.90 Ham and Pineapple Pizza (GF)_____________________ 9.90 natural yoghurt and honey ___________________________ 8.90 (Eden Valley, S.A.) 10.00 16.00 43.90 Fried Rice (GF) ____________________________________ 9.90 Strawberry Yoghurt 200g (GF) _____________________ 3.00 Yellowglen Perle Vintage Chicken Risotto (GF) (S.E. -

ALC JAN 20 Korean Backdrop
SNACKS RAW PLATES SHARING PLATTER JINJUU’S ANJU SHARING BOARD 24 VEGETABLE CHIPS & DIPS (v, vg on request) 6 YOOK-HWE STEAK TARTAR 14 FOR 2 Crispy vegetable chips, served with kimchi soy guacamole. Diced grass fed English beef fillet marinated in soy, ginger, Kong bowl, sae woo prawn lollipops, signature Korean fried chicken, garlic & sesame. Garnished with Korean pear, toasted beef & pork mandoo, steamed ya-chae mandoo. pinenuts & topped with raw quail egg. (v) (vg, gf on request) 5 20 KONG BOWL JINJUU’S YA-CHAE SHARING BOARD (v) Steamed soybeans (edamame) topped with our Jinjuu chili FOR 2 panko mix. TUNA SASHIMI (gf) 16 Kong bowl, tofu lollipops, signature Korean fried cauliflower, Thinly sliced Pacific tuna with shredded daikon steamed ya-chae mandoo. SKEWERS & carrots. Kimchi yuja dressing & perilla oil. 4 PER SERVING (extra maybe ordered by piece) SALMON SASHIMI (gf on request) 12 SAE-WOO POPS 8 Raw Scottish salmon sashimi style, avocado, soy & yuja, MANDOO Crispy fried round prawn cakes served on sticks. seaweed & wasabi tobiko. 3 PER SERVING (extra could be ordered by piece) Gochujang mayo on the side. TUNA TARTAR (gf on request) 16 BEEF & PORK 7.5 TOFU LOLLIPOPS (vg) 6 Diced raw Atlantic tuna, dressed with sesame oil, soy, Pan fried dumplings with beef & pork marinated Crispy gochujang marinated tofu served on sticks. gochujang. Garnished with wasabi mayo. in chilli & soy. Special kalbi sauce. Signature sauce on the side. YA-CHAE (vg) 7.5 K- TACOS K-TOWN MINI SLIDERS Juicy steamed dumplings with sautéed courgettes, 2 PER SERVING (extra could be ordered by piece) 2 PER SERVING (extra maybe ordered by piece) Chinese garlic chives, cabbage & green peas.