Veritas Ediscovery Platform™
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Uila Supported Apps
Uila Supported Applications and Protocols updated Oct 2020 Application/Protocol Name Full Description 01net.com 01net website, a French high-tech news site. 050 plus is a Japanese embedded smartphone application dedicated to 050 plus audio-conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also 10086.cn classifies the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese web portal operated by YLMF Computer Technology Co. Chinese cloud storing system of the 115 website. It is operated by YLMF 115.com Computer Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr Korean shopping website 11st. It is operated by SK Planet Co. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt Lithuanian news portal Chinese web portal 163. It is operated by NetEase, a company which 163.com pioneered the development of Internet in China. 17173.com Website distributing Chinese games. 17u.com Chinese online travel booking website. 20 minutes is a free, daily newspaper available in France, Spain and 20minutes Switzerland. This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Shared 2shared is an online space for sharing and storage. -

The Application Usage and Risk Report an Analysis of End User Application Trends in the Enterprise
The Application Usage and Risk Report An Analysis of End User Application Trends in the Enterprise 8th Edition, December 2011 Palo Alto Networks 3300 Olcott Street Santa Clara, CA 94089 www.paloaltonetworks.com Table of Contents Executive Summary ........................................................................................................ 3 Demographics ............................................................................................................................................. 4 Social Networking Use Becomes More Active ................................................................ 5 Facebook Applications Bandwidth Consumption Triples .......................................................................... 5 Twitter Bandwidth Consumption Increases 7-Fold ................................................................................... 6 Some Perspective On Bandwidth Consumption .................................................................................... 7 Managing the Risks .................................................................................................................................... 7 Browser-based Filesharing: Work vs. Entertainment .................................................... 8 Infrastructure- or Productivity-Oriented Browser-based Filesharing ..................................................... 9 Entertainment Oriented Browser-based Filesharing .............................................................................. 10 Comparing Frequency and Volume of Use -

Dictionary of Health Information Technology and Security
DICTIONARY OF HEALTH INFORMATION TECHNOLOGY AND SECURITY Dr. David Edward Marcinko, MBA , CFP© Certifi ed Medical Planner© Editor-in-Chief Hope Rachel Hetico, RN, MSHA, CPHQ Certifi ed Medical Planner© Managing Editor NEW YORK 33021009_FM1.indd021009_FM1.indd i 003/17/20073/17/2007 116:48:506:48:50 Copyright © 2007 Springer Publishing Company, LLC All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmit- ted in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior permission of Springer Publishing Company, LLC. Springer Publishing Company, LLC 11 West 42nd Street New York, NY 10036 www.springerpub.com Acquisitions Editor: Sheri W. Sussman Production Editor: Carol Cain Cover design: Mimi Flow Composition: Apex Publishing, LLC 07 08 09 10/ 5 4 3 2 1 Library of Congress Cataloging-in-Publication Data Dictionary of health information technology and security / David Edward Marcinko, editor-in-chief, Hope Rachel Hetico, managing editor. p. ; cm. Includes bibliographical references. ISBN-13: 978-0-8261-4995-4 (alk. paper) ISBN-10: 0-8261-4995-2 (alk. paper) 1. Medical informatics—Dictionaries. 2. Medicine—Information technology—Dictionaries. 3. Medical informatics—Security measures— Dictionaries. I. Marcinko, David E. (David Edward) II. Hetico, Hope R. [DNLM: 1. Informatics—Dictionary—English. 2. Medical Informatics— Dictionary—English. 3. Computer Communication Networks—Dictionary— English. 4. Computer Security—Dictionary—English. W 13 D557165 2007] R858.D53 2007 610.3—dc22 2007005879 Printed in the United States of America by RR Donnelley. 33021009_FM1.indd021009_FM1.indd iiii 003/17/20073/17/2007 116:48:516:48:51 Th e Dictionary of Health Information Technology and Security is dedicated to Edward Anthony Marcinko Sr., and Edward Anthony Marcinko Jr., of Fell’s Point, Maryland. -

Ifolder Professional Edition
Quick Start July 16, 200263 To begin a Quick Start (English): Click in the box under the word Novell. Insert Quick Start and Title elements. 2. Type the product name. 3. Insert the HeadQS element, type the title of your card. 4. (Optional) Put product version on the card: Click View > Master Pages. Click in the small text box at the far left of the decorative lines. Click Tools > Variable > select the variable named Version > Edit Definition > enter the version number > click Done > Insert. It will appear as background text. Click View > Body Pages to return. For a single (stand-alone) card: Keep this master page, named “QS-Single.“ It shows the part number on the bottom right, since single cards don’t have front matter. For a card that’s part of a booklet: Use Print Preparation > Format > Page Layout > Master Page Usage to change to using “First” master page on the first page of the card. It doesn’t show the part number, since part number will be noted in the front of the booklet. Novell iFolder Professional Edition 2.0 www.novell.com QUICK START iFolder Quick Start Welcome to the Novell® iFolderTM Professional Edition Quick Start. This guide covers the following topics: ! “Overview” on page 1 ! “Installing the iFolder Client” on page 2 ! “Accessing iFolder through a Web Browser” on page 4 ! “Using iFolder” on page 5 ! “Tips and tricks for Synchronizing” on page 6 ! “Frequently Asked Questions” on page 8 OVERVIEW Novell iFolder lets you access your files from anywhere, at any time. It no longer matters where you are; iFolder lets you open and use any local files that you’ve placed in your iFolder directory. -

The Teacher and American Literature. Papers Presented at the 1964 Convention of the National Council of Teachers of English
DOCUMENT RESUME ED 042 741 TB 001 605 AUTHOR Leary, Lewis, Fd. TITLE The Teacher and American Literature. Papers Presented at the 1964 Convention of the National Council of Teachers of English. INSTITUTION National Council of Teachers of English, Champaign, Ill. PUB DATE 65 NOTE 194p. EDITS PRICE EDRS Price MF-$0.75 HC-$9.80 DESCRIPTORS American Culture, *American Literature, Authors, Biographies, Childrens Books, Elementary School Curriculum, Literary Analysis, *Literary Criticism, *Literature Programs, Novels, Poetry, Short Stories ABSTRACT Eighteen papers on recent scholarship and its implications for school programs treat American ideas, novels, short stories, poetry, Emerson and Thoreau, Hawthorne and Melville, Whitman and Dickinson, Twain and Henry James, and Faulkner and Hemingway. Authors are Edwin H. Cady, Edward J. Gordon, William Peden, Paul H. Krueger, Bernard Duffey, John A. Myers, Jr., Theodore Hornberger, J. N. Hook, Walter Harding, Betty Harrelson Porter, Arlin Turner, Robert E. Shafer, Edmund Reiss, Sister M. Judine, Howard W.Webb, Jr., Frank H. Townsend, Richard P. Adams, and John N. Terrey. In five additional papers, Willard Thorp and Alfred H. Grommon discuss the relationship of the teacher and curriculum to new.a7proaches in American literature, while Dora V. Smith, Ruth A. French, and Charlemae Rollins deal with the implications of American literature for elementary school programs and for children's reading. (MF) U.S. DEPAIIMENT Of NE11114. EDUCATION A WOK Off ICE Of EDUCATION r--1 THIS DOCUMENT HAS KM ITEPtODUCIO EXACTLY AS IHCEIVID 1110D1 THE 11115011 01 014111I1.1101 01,611111116 IL POINTS Of TIM PI OPINIONS 4" SIAM 00 NOT IKESSAIllY INPINSENT OFFICIAL OW Of IDS/CATION N. -

Casual Resource Sharing with Shared Virtual Folders
MASTER THESIS IN COMPUTER SCIENCE Casual Resource Sharing with Shared Virtual Folders Siri Birgitte Uldal June 15th, 2007 FACULTY OF SCIENCE Department of Computer Science University of Tromsø, N-9037 Tromsø Casual Resource Sharing with Shared Virtual Folders Siri Birgitte Uldal June 15th, 2007 ___________________ University of Tromsø 2007 Abstract Proliferation of wireless networks has been a major trigger behind increased mobility of computing devices. Along with increased mobility come requests for ad-hoc exchange of resources between computing devices as an extension of humans interacting. We termed it casual resource sharing where resources in this thesis have been narrowed down to files only. We have named our casual resource sharing model for shared virtual folders (SVF). SVFs can be looked upon as a common repository much in the same way as the tuplespace model. The SVF members perceive the repository similarly to a common file directory on a server, while in reality all participating devices stores their own contribution of files. All types of files could be added to the repository and shared. To become a SVF member one needs to be invited by another member or initiate a SVF oneself. All members are free to withdraw their SVF membership whenever they wish. They are also free to log on to the SVF and log out as they please. The SVF cease to exist when the last member has drawn his membership. The SVF implements a simple versioning detection system to alert members when a file has been modified by another member. Feasibility of the model is demonstrated in a prototype implementation based on Java and the JXTA middleware, a peer-to-peer (P2P) infrastructure middleware supporting the Internet protocol. -

Novell Ifolder 1.0
QuickStart Rev 99a37 June 14, 2001 To begin a QuickStart (English): 1. Click in the black bar next to the curly-cue. Insert QuickStart and Title elements. 2. In Title, put in the Product Name by clicking Special > Variable > click Product Name in the list > Edit Definition > type in your product name > Done > Insert. If Variable is grayed out, make sure cursor is inside Title element. (This will put the product name at the top of all the pages. To see text in the black bar, use Ctrl+L to refresh.) For a single (stand-alone) card: Put in your product version (Special > Variable > click Version, etc.). It will appear as background text replacing Version X.X. For a card that’s part of a booklet: Use Special > Master Page Usage to assign ”First” master page instead of “QS-Single.” (Version and Novell logo will disappear—they will be shown on the booklet cover instead.) NOVELL IFOLDER 1.0 Welcome to Novell iFolder iFolderTM lets you access your personal iFolder files from anywhere and at any time. You now have the flexibility of working on your files regardless of whether or not you’re connected to the network. If you make any changes to your iFolder files, you need only an Internet connection to upload the changes to your personal folder on the iFolder server. The changes are then downloaded to each of the computers where you have the iFolder client installed so that regardless of what computer you are using, you will always have the latest copy of your files—whether it’s at home, at work, or on your laptop. -

DVD: Suse Linux 10.0
LINUX MAGA On this DVD: Suse Linux 10.0 Linux kernel 2.6.13 ZINE X.org 6.8.2 KDE 3.4.2 Gnome 2.12 OpenOffice 2.0 pre-release KOffice 1.4 GIMP 2.2.8 ISSUE Inkscape 0.42 Evolution 2.4 Firefox 1.0.6 Xen 3 preview 62 GCC 4.0 RealPlayer 10.0.1 SUSE LINUX Banshee 0.9.7 Kaffeine 0.7.1 MySQL 4.1.9 In August 2005, Novell announced a dramatic new direction for Suse Linux. Suse, they said, was now a community project, with volunteer developers participating in reviewing, testing, and development. They announced that the fi rst release of this new 10.0 community-based Suse would be Suse Linux 10.0. Now Suse Linux has fi nally arrived, and we are proud to include it as this month's Linux DVD is Linux Kernel 2.6.11, along with for the desktop user. Included is a pre- Magazine DVD. Suse Linux 10.0 combines KDE 3.4.2 and GNOME 2.12. Updated release version of the OpenOffi ce.org Suse's long Linux tradition with the technical components include GCC 4.0, glibc 2.0 productivity suite. muscle of Novell and the agility of the 2.3.5, and the Xen 3 technical preview. The Kontact personal information mana- community framework. On this DVD, you'll ger, and the alternative Evolution suite, fi nd the great tools that have made Suse Some of the new tools in Suse 10.0 in- contain tools for managing your email, Linux one of the world's great Linux clude the AppArmor intrusion detection calendar, and address book. -

Exinda Applications List
Application List Exinda ExOS Version 6.4 © 2014 Exinda Networks, Inc. 2 Copyright © 2014 Exinda Networks, Inc. All rights reserved. No parts of this work may be reproduced in any form or by any means - graphic, electronic, or mechanical, including photocopying, recording, taping, or information storage and retrieval systems - without the written permission of the publisher. Products that are referred to in this document may be either trademarks and/or registered trademarks of the respective owners. The publisher and the author make no claim to these trademarks. While every precaution has been taken in the preparation of this document, the publisher and the author assume no responsibility for errors or omissions, or for damages resulting from the use of information contained in this document or from the use of programs and source code that may accompany it. In no event shall the publisher and the author be liable for any loss of profit or any other commercial damage caused or alleged to have been caused directly or indirectly by this document. Document Built on Tuesday, October 14, 2014 at 5:10 PM Documentation conventions n bold - Interface element such as buttons or menus. For example: Select the Enable checkbox. n italics - Reference to other documents. For example: Refer to the Exinda Application List. n > - Separates navigation elements. For example: Select File > Save. n monospace text - Command line text. n <variable> - Command line arguments. n [x] - An optional CLI keyword or argument. n {x} - A required CLI element. n | - Separates choices within an optional or required element. © 2014 Exinda Networks, Inc. -
3000 Applications
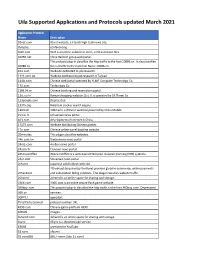
Uila Supported Applications and Protocols updated March 2021 Application Protocol Name Description 01net.com 05001net plus website, is a Japanese a French embedded high-tech smartphonenews site. application dedicated to audio- 050 plus conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also classifies 10086.cn the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese cloudweb portal storing operated system byof theYLMF 115 Computer website. TechnologyIt is operated Co. by YLMF Computer 115.com Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr ThisKorean protocol shopping plug-in website classifies 11st. the It ishttp operated traffic toby the SK hostPlanet 123people.com. Co. 123people.com Deprecated. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt ChineseLithuanian web news portal portal 163. It is operated by NetEase, a company which pioneered the 163.com development of Internet in China. 17173.com Website distributing Chinese games. 17u.com 20Chinese minutes online is a travelfree, daily booking newspaper website. available in France, Spain and Switzerland. 20minutes This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Checkout (acquired by Verifone) provides global e-commerce, online payments 2Checkout and subscription billing solutions. -

What Did You Do in School Today Junior? an Analysis of Application Usage on K-12 School Networks
What Did You Do In School Today Junior? An Analysis of Application Usage on K-12 School Networks March 2012 Palo Alto Networks 3300 Olcott Street Santa Clara, CA 95054 www.paloaltonetworks.com Table of Contents Key Findings ....................................................................................................................................................... 3 Introduction ....................................................................................................................................................... 4 Tools That Enable Circumvention ....................................................................................................................... 5 Encrypted Tunnels: Protection or Evasion? ................................................................................................................ 5 Remote Desktop Applications: What is the Use Case? .............................................................................................. 6 External Proxies: K‐12 Usage is Double Enteprise Usage ........................................................................................... 7 P2P FileSharing: Solution Of Choice For Moving Large Files ................................................................................. 8 Browser‐based Filesharing: Education or Entertainment? ................................................................................... 9 Browser‐based Filesharing use Case: Productivity .................................................................................................. -

Hacking the Web 2.0 User Agency and the Role of Hackers As Computational Mediators
Hacking the Web 2.0 User agency and the role of hackers as computational mediators andrea rota Thesis submitted to the Department of Sociology of the London School of Economics and Political Science for the degree of Doctor of Philosophy. London, January 2016 With amendments (April 2016) I certify that the thesis I have presented for examination for the PhD degree of the London School of Economics and Political Science is solely my own work other than where I have clearly indicated that it is the work of others (in which case the extent of any work carried out jointly by me and any other person is clearly identified in it). The copyright of this thesis rests with the author. Quotation from it is permitted, provided that full acknowledgement is made. This thesis may not be reproduced without my prior written consent. I warrant that this authorisation does not, to the best of my belief, infringe the rights of any third party. Additionally to the above copyright notice as required by the School, I declare that I release this dissertation under a Creative Commons Attribution-ShareAlike 4.0 International license. 1 Abstract This thesis studies the contested reconfigurations of computational agency within the do- main of practices and affordances involved in the use of the Internet in everyday life (here labelled lifeworld Internet), through the transition of the Internet to a much deeper reliance on computation than at any previous stage. Computational agency is here considered not only in terms of capacity to act enabled (or restrained) by the computational layer but also as the recursive capacity to reconfigure the computational layer itself, therefore in turn affecting one’s own and others’ computational agency.