Mysql Reference Manual
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Securecrt 7.3.6 Crack for Mac >>>
Securecrt 7.3.6 Crack For Mac >>> http://shurll.com/77o35 1 / 5 2 / 5 hash,,47850D6A1C717CEC4534B14525ED9BF2292DD905,,... VanDyke,,SecureCRT,,and,,SecureFX,,7 .3.6,,[Mac,,Os,,X],,[MAC599],,DOWNLOAD,,TORRENTSecureCRT,,for,,Mac,,OS,,X,,7.1... VanDyke,,Secu reCRT,,and,,SecureFX,,7.3.6,,[Mac,,Os,,X].torrent,,내부,,파일,,..Turn,,,your,,,computer,,,into,,,a,,,terminal,, ,server,,,using,,,Serial,,,to,,,Ethernet,,,Converter,,,with,,,its,,,amazing,,,capability,,,to,,,share,,,serial,,, devices,,,in,,,... Free,,,Download,,,SecureCRT,,,for,,,Mac,,,8.1.3,,,Build,,,1382,,,-,,,A,,,fully-featured,,,te rminal,,,emulator,,,as,,,well,,,as,,,a,,,SSH,,,and,,,Telnet,,,client,,,with,,,advanced,,,session,,,mana... Do wnload,,,VanDyke,,,SecureCRT,,,and,,,SecureFX,,,7.3.6,,,[Mac,,,Os,,,X],,,[MAC599],,,torrent,,,or,,,any,, ,other,,,torrent,,,from,,,Mac,,,category. SecureCRT®,,,7.3.6.963,,,for,,,MAC,,,|,,,40.7MbUsers,,,with,,,PCs,,,installed,,,with,,,Windows,,,8. Secu reCRT,,,provides,,,rock-solid,,,terminal,,,emulation,,,for,,,computing,,,professionals,,,,raising,,,product ivity,,,with,,,advanced,,,session,,,management,,,and,,,a,,,host,,,of,,,ways,,,to,,,save SecureCRT,,,for,,, Mac,,,,free,,,and,,,safe,,,downloadSecureCRT,,,supports,,,SSH2,,,,SSH1,,,,Telnet,,,,Telnet/SSL,,,,Serial, ,,,and,,,other,,,protocols..It,,,has,,,been,,,designed,,,to,,,be,,,used,,,during,,,the,,,high,,,stress,,,produc tion,,,... Torrentz,,,-,,,Fast,,,and,,,convenient,,,Torrents,,,Search,,,EngineApowersoft,,Screen,,Capture, ,Pro,,1.3.1,,InclTurn,,your,,computer,,into,,a,,terminal,,server,,using,,Serial,,to,,Ethernet,,Converter,, -
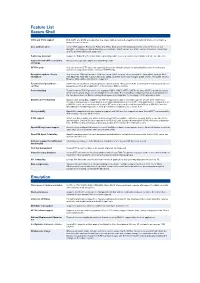
Feature List Secure Shell
Feature List Secure Shell SSH1 and SSH2 support Both SSH1 and SSH2 are supported in a single client, providing the maximum in flexibility when connecting to a range of remote servers. User authentication SecureCRT supports Password, Public Key (RSA, DSA, and X.509 including Smart Cards), Kerberos v5 (via GSSAPI), and Keyboard Interactive when connecting to SSH2 servers. For SSH1 servers, Password, Public Key, and TIS authentications are supported. Public Key Assistant Support for Public Key Assistant makes uploading public keys to an SSH2 server simple and safe for end users. Support for GSSAPI secured key Mechanisms supported depend on GSSAPI provider. exchange SFTP in a tab You can open an SFTP tab to the same SSH2 session without having to re-authenticate to perform file transfer operations using an interactive, text-based SFTP utility. Encryption ciphers: Strong The maximum 2048 bits length of DSA keys under SSH2 provides strong encryption. SecureCRT supports AES- encryption 128, AES-192, AES-256, Twofish, Blowfish, 3DES, and RC4 when connecting to SSH2 servers. For SSH1 servers, Blowfish, DES, 3DES, and RC4 are supported. Password and passphrase SSH2 session passwords and passphrases can be cached, letting SecureCRT and SecureFX share passwords and caching passphrases while either application or the Activator utility is running. Port forwarding Tunnel common TCP/IP protocols (for example, POP3, IMAP4, HTTP, SMTP) via SecureCRT to a remote Secure Shell server using a single, secure, multiplexed connection. Port forwarding configuration has been integrated into the tree-based Session Options dialog allowing easier configuration for securing TCP/IP application data. Dynamic port forwarding Dynamic port forwarding simplifies how TCP/IP application data is routed through the Secure Shell connection. -

Secure Configuration and Management of Linux Systems
Secure Configuration and Management of Linux Systems using a Network Service Orchestrator Vijay Satti A Thesis in The Department of Concordia Institute for Information Systems Engineering Presented in Partial Fulfillment of the Requirements for the Degree of Master of Applied Science at Concordia University Montréal, Québec, Canada May 2019 c Vijay Satti, 2019 CONCORDIA UNIVERSITY School of Graduate Studies This is to certify that the thesis prepared By: Vijay Satti Entitled: Secure Configuration and Management of Linux Systems using a Network Service Orchestrator and submitted in partial fulfillment of the requirements for the degree of Master of Applied Science complies with the regulations of this University and meets the accepted standards with respect to originality and quality. Signed by the Final Examining Committee: Chair Dr. Walter Lucia Examiner Dr. Anjali Agarwal Examiner Dr. Amr Youssef Supervisor Dr. J. William Atwood Approved by Dr. Chadi Assi, Graduate Program Director Department of Concordia Institute for Information Systems Engineering 2019 Dr. Amir Asif, Dean Faculty of Engineering and Computer Science Abstract Secure Configuration and Management of Linux Systems using a Network Service Orchestrator Vijay Satti Manual management of the configuration of network devices and computing devices (hosts) is an error-prone task. Centralized automation of these tasks can lower the costs of management, but can also introduce unknown or unanticipated security risks. Miscon- figuration (deliberate (by outsiders) or inadvertent (by insiders)) can expose a system to significant risks. Centralized network management has seen significant progress in recent years, result- ing in model-driven approaches that are clearly superior to previous "craft" methods. Host management has seen less development. -

Tunneling with Secure Shell (SSH) Secure Shell Tunneling with Secure Shell
White Paper Tunneling with Secure Shell (SSH) 4848 tramway ridge dr. ne suite 101 albuquerque, nm 87111 505 - 332 -5700 www.vandyke.com Tunneling with Secure Shell Remote access to network resources is increasingly a business requirement, but external network threats must be neutralized. A Secure Shell (SSH) capability called port forwarding allows nonsecure TCP/IP data to be tunneled across public and private networks through a secure, encrypted connection. The benefits of port forwarding are illustrated by a series of concrete examples. VanDyke Software's clients and servers provide an end-to-end tunneling solution to secure client/server applications, which may serve as a lightweight alternative to a Virtual Private Network (VPN). With today’s increasingly mobile and distributed workforce, providing remote access to travelers and teleworkers is no longer a “nice to have” option. In many corporations, remote access to business applications has become mission critical. At the same time, Internet access is now cheap, fast, and readily available. Leveraging the Internet to extend the local area network (LAN), provide real-time communications, and immediate file transfer and sharing is a scalable, cost-effective soluti on for corporate network remote access. However, Internet-based remote access also adds significant risk. Sensitive data can be intercepted, modified, or replayed anywhere between remote workers and the corporate firewall. Broadcast access technologies like cable and wireless are especially vulnerable. Whenever a computer is connected to the Internet, it becomes a potential target for intruders. "Always on" broadband greatly increases this exposure by giving intruders a fixed target to attack repeatedly over time. -

Inside: Special Focus Issue: Security
THE MAGAZINE OF USENIX & SAGE November 2001 • Volume 26 • Number 7 Special Focus Issue: Security Guest Editor: Rik Farrow inside: BEST PRACTICES No Plaintext Passwords by Abe Singer & The Advanced Computing Systems Association & The System Administrators Guild no plaintext passwords Introduction by Abe Singer Compromise of a user password is one of the most difficult intrusions to Abe Singer is a com- ORENSICS detect. Historically it has been difficult or impossible to avoid transmission puter security man- | F ager at the San Diego of passwords in the clear. But the technology now exists to make this possi- Supercomputer Cen- ble, albeit not trivially. The San Diego Supercomputer Center (SDSC) has ter, and occasional consultant and expert ETECTION managed to eliminate plaintext password transmission, while continuing to witness. His current D work is in security deliver services to a widely distributed user base. While it took some techni- measurement and security “for the life cal effort, overcoming the human hurdles proved to be more challenging. NTRUSION of the Republic.” |I This article discusses what solutions we provided and how we managed to do it without annoying too many people. We have actually added value to [email protected] RACTICES the environment, instead of reducing it. P EST At SDSC, we have to deal with some interesting issues of scale. We have thousands of B users and very few support staff. We have a wide variety of operating systems, high- speed networks and high-performance storage systems. Our users expect to be able to move large amounts of data (terabytes) around, in a reasonable amount of time. -

An Overview of the Secure Shell (SSH) Secure Shell Secure Shell Overview
White Paper An Overview of the Secure Shell (SSH) 4848 tramway ridge dr. ne suite 101 albuquerque, nm 87111 505 - 332 -5700 www.vandyke.com Secure Shell Overview Overview of Secure Shell ................................................................................................... 2 Introduction to Secure Shell............................................................................................ 2 History of Secure Shell ................................................................................................... 2 Functionality of Secure Shell.......................................................................................... 3 Secure Command Shell............................................................................................... 3 Port forwarding ........................................................................................................... 3 Secure File Transfer.................................................................................................... 4 Protocol Basics of Secure Shell ...................................................................................... 5 User Authentication .................................................................................................... 5 Host Authentication .................................................................................................... 7 Data Encryption .......................................................................................................... 8 Data Integrity ............................................................................................................. -

Safezone Browser Download Cent Safezone Browser Download Cent
safezone browser download cent Safezone browser download cent. NOT REGISTERED YET? RETRIEVE YOUR PERNUM FOR BETA TESTERS--> PLEASE ENTER YOUR REGISTERED EMAIL. Your PERNUM will be sent to your registered email account. REQUEST PASSWORD FOR BETA TESTERS--> PLEASE ENTER YOUR PERNUM. Your temporary password will be sent to your registered email account. RESET YOUR MASTER PIN FOR BETA TESTERS--> PLEASE ENTER YOUR REGISTERED EMAIL AND SAFEZONE PASSWORD. RESET YOUR MASTER PIN FOR BETA TESTERS--> YOUR REQUEST HAS BEEN RECEIVED. An email has been sent to our Support Team and they will contact you at your registered email for assistance. Please allow up to 48 hours for a response, emails are processed in the order they are received. SET UP YOUR MASTER PIN FOR BETA TESTERS--> PLEASE ENTER YOUR REGISTERED EMAIL AND SAFEZONE PASSWORD. SET UP YOUR MASTER PIN FOR BETA TESTERS--> Your SafeZone Pass is protected by two-step authentication. For every login process, or if you need to change your profile data, you need a one- time pin which has been randomly generated from your 6-digit Master Pin. SET UP YOUR MASTER PIN FOR BETA TESTERS--> Oops! There is already a Master PIN set up for this account. Please either login using your existing Master PIN or you may reset your Master PIN. SET UP YOUR MASTER PIN FOR BETA TESTERS--> Your Master Pin has been set up successfully! Let us test your first One-Time Pin, which is randomly generated from your Master Pin. Please enter the matching digits of your Master Pin: SafeZone APK. SafeZone app is only available at organizations using the SafeZone solution . -

Assurance Activity Report (MDFPP31/WLANCEP10) for Google Pixel Phones on Android 11.0
www.GossamerSec.com Assurance Activity Report (MDFPP31/WLANCEP10) for Google Pixel Phones on Android 11.0 Version 0.4 02/04/2021 Prepared by: Gossamer Security Solutions Accredited Security Testing Laboratory – Common Criteria Testing Catonsville, MD 21228 Prepared for: National Information Assurance Partnership Common Criteria Evaluation and Validation Scheme Document: AAR-VID11124 © 2020 Gossamer Security Solutions, Inc. All rights reserved. Version 0.4, 02/04/2021 REVISION HISTORY Revision Date Authors Summary Version 0.1 12/11/20 Tammy Compton Initial draft Austin Kimbrell Version 0.2 01/21/21 Austin Kimbrell Address comments Version 0.3 01/29/21 Austin Kimbrell Address comments Version 0.4 02/04/21 Austin Kimbrell Address comments The TOE Evaluation was Sponsored by: Google LLC 1600 Amphitheatre Parkway Mountain View, CA 94043 Evaluation Personnel: Justin Bettencourt Tammy Compton Austin Kimbrell John Messiha Raymond Smoley Gossamer Security Solutions, Inc. Catonsville, MD Common Criteria Versions: Common Criteria for Information Technology Security Evaluation Part 1: Introduction, Version 3.1, Revision 5, April 2017 Common Criteria for Information Technology Security Evaluation Part 2: Security functional components, Version 3.1, Revision 5, April 2017 Common Criteria for Information Technology Security Evaluation Part 3: Security assurance components, Version 3.1, Revision 5, April 2017 Common Evaluation Methodology Versions: Common Methodology for Information Technology Security Evaluation, Evaluation Methodology, Version 3.1, Revision 5, April 2017 GSS CCT Assurance Activity Report Page 2 of 182 © 2020 Gossamer Security Solutions, Inc. Document: AAR-VID11124 All rights reserved. Version 0.4, 02/04/2021 TABLE OF CONTENTS 1. Introduction ........................................................................................................................................................... 7 1.1 Device Equivalence ..................................................................................................................................... -

A Guide to Using Vbscript in Securecrt
User's Guide Scripting Essentials: A Guide to Using VBScript in SecureCRT 4848 tramway ridge dr. ne suite 101 albuquerque, nm 87111 505 - 332 - 5700 www.vandyke.com A Guide to Using VBScript in SecureCRT Introduction 1 How This Document is Organized 1 Conventions Used in This Document 1 SecureCRT’s Scripting Objects/API Reference 2 Chapter 1: Creating Scripts 4 1.1 Starting from Scratch with a New Script 4 1.2 Recording a Script 5 1.3 Modifying an Existing Example Script 9 Chapter 2: Launching Scripts 11 2.1 Manual Script Execution 11 2.2 Automated Script Execution 20 Chapter 3: Connecting to Remote Machines 24 3.1 Connecting with a Pre-configured Session 24 3.2 Connecting in an “Ad Hoc” Fashion 25 3.3 Connecting in Tabs 26 Solution: Open a Group of Sessions in Tabs 28 3.4 Disconnecting Active Connections 29 Solution: Automatically Close an Inactive Connection (Auto Disconnect) 30 3.5 Connecting to a List of Remote Machines Within a Loop 31 3.6 Handling Connection Failures Within a Script 31 Chapter 4: Reading Data from Remote Machines 35 4.1 Accessing Selected Text on the Screen 35 Solution: Performing a Web Search with Selected Text 35 4.2 Waiting for Specific Data to Arrive 36 Solution: Receive Notification when “Error-Indicating” Text Appears 38 4.3 Capturing Data from a Remote Machine 46 Chapter 5: Sending Data to Remote Machines 54 5.1 Sending Plain Text 54 Solution: Repeat a Command with Variable Input from User 54 5.2 Sending Control Codes 56 5.3 Simulating Keyboard Events 57 Solution: Add "no" to Each Selected Line and Send to Remote 59 Chapter 6: Getting Information from the End User 62 6.1 Prompting for Simple Responses: Yes, No, OK, Cancel, etc. -

Today's Leftovers Today's Leftovers
Published on Tux Machines (http://www.tuxmachines.org) Home > content > today's leftovers today's leftovers By Roy Schestowitz Created 19/02/2021 - 7:58pm Submitted by Roy Schestowitz on Friday 19th of February 2021 07:58:27 PM Filed under Misc [1] Moving to Zstandard images by default on mkinitcpio [2] As linux-lts moved to the 5.10 version, all official kernels of Arch Linux now support zstd compressed initramfs images, so mkinitcpio is switching to zstd compressed images by default with version 30, which is currently on [testing]. Technically Speaking (S1E01): Edge computing covered and diced - YouTube[3] What is edge computing, and what does it mean for data workloads, latency, and our precious, precious bandwidth? Red Hat CTO Chris Wright reboots Technically Speaking in this first episode where we explore edge computing. Virtualization?s role in next-generation infrastructure [4] Enterprises have always used multiple generations of technology simultaneously. Enterprise applications need to be deployed into both VMs and containers, and enterprises need a converged platform to support both. So the question IT people have to answer is, "How can we manage existing applications running on virtual machines and new applications running on containers together in an unified platform?" That is the mission of the open source project, KubeVirt. Downstream of that, Red Hat introduced OpenShift Virtualization (a.k.a. Container Native Virtualization) within the Red Hat OpenShift Container Platform, a Kubernetes based platform. NeoPixel fireflies jar with Raspberry Pi | HackSpace 39 [5] Security updates for Friday [6] Security updates have been issued by Debian (bind9, libbsd, openssl1.0, php-horde-text-filter, qemu, and unrar-free), Fedora (kiwix-desktop and libntlm), Mageia (coturn, mediawiki, privoxy, and veracrypt), openSUSE (buildah, libcontainers-common, podman), Oracle (kernel, nss, and perl), Red Hat (xterm), SUSE (java-1_7_1-ibm, php74, python-urllib3, and qemu), and Ubuntu (libjackson-json-java and shiro). -

Transferring Files Safely with Secure Shell
White Paper Secure File Transfer with SSH 4848 tramway ridge dr. ne suite 101 albuquerque, nm 87111 505 - 332 -5700 www.vandyke.com Data delivery over the Internet can be simple, convenient, and cost- effective - but it must also be secure. Traditional file transfer methods do not provide adequate security, transmitting account information like user names, passwords, and data in the clear where they can be easily intercepted. The current version of Secure Shell (SSH2) provides a secure alternative. This paper explains the Secure Shell File Transfer Protocol (SFTP) and presents specific applications for system administration, finance, health care, and business-to-business. VanDyke Software clients and servers provide secure file transfer capabilities for Windows and are interoperable with SSH software on other platforms. Transferring Files Safely with Secure Shell Schools, hospitals, government agencies, and enterprises – today, all of these organizations are tapping the power of the Internet to access and distribute mission- critical information. Readily-available, low-cost connectivity makes it possible to deliver files to customers, business partners, and employees, inexpensively and immediately. Why rush that report over to FedEx when you could post it on a file server right now? Why courier patient medical records from diagnostic lab to hospital when they could be transferred immediately to the doctor who needs them? Leveraging the Internet for data delivery is simple, convenient, and cost-effective – as long as file access, confidentiality, and integrity can be protected. Fortunately, cryptographic techniques like encryption, public-key authentication, and hashed-message authentication codes can prevent unauthorized disclosure or modification of private data. -

News About Nformation Systems Throughout M I T
News about nformation systems throughout M I T V o l u m e 1 8 • N u mI b e r 4 MS a r c h / A p r i l 2 0 0 3 . New MIT Home Page Innovates Further, as the home page images . on a Very Good Thing change, the border containing the MIT . logo remains consistent to show the . • Susan Curran . integration of MIT the institution and . MIT the community. Coming Soon: Tap into Tuition . eci n’est pas un hack,” As before, members of the com- . Assistance via the Web . 2 . “C proclaimed the debut of munity and the public are invited to . the new MIT home page on April 1. submit images or designs. This spirit of Software Spotlight . “This is not a hack.” collaboration celebrates the diversity TSM Backups Can Save the . Very true. The redesigned home of MIT and its freewheeling spirit, and Day, So Schedule Them Now . 3 . page reflects a great deal of thoughtful . reinforces the idea that we’re all here . work, based on data gathering through to learn from one another. Network Notes . surveys and focus groups, work with a SecureFX and SecureCRT: More . Fostering Community 4 . professional design firm, and usability Options for Good Connections . Through its changing graphic . testing. The redesign team, led by IS Bits and Bytes . Web Communications Services (WCS), and spotlight, the MIT home page . has fostered a very organic kind of Advice about End User License . worked to achieve a sense of dynamism . community. The spotlight provides Agreements and Readme Files .