A Benchmarking Study on Virtual Ligand Screening Against Homology Models of Human Gpcrs
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

309 Molecular Role of Dopamine in Anhedonia Linked to Reward
[Frontiers In Bioscience, Scholar, 10, 309-325, March 1, 2018] Molecular role of dopamine in anhedonia linked to reward deficiency syndrome (RDS) and anti- reward systems Mark S. Gold8, Kenneth Blum,1-7,10 Marcelo Febo1, David Baron,2 Edward J Modestino9, Igor Elman10, Rajendra D. Badgaiyan10 1Department of Psychiatry, McKnight Brain Institute, University of Florida, College of Medicine, Gainesville, FL, USA, 2Department of Psychiatry and Behavioral Sciences, Keck School of Medicine, University of South- ern California, Los Angeles, CA, USA, 3Global Integrated Services Unit University of Vermont Center for Clinical and Translational Science, College of Medicine, Burlington, VT, USA, 4Department of Addiction Research, Dominion Diagnostics, LLC, North Kingstown, RI, USA, 5Center for Genomics and Applied Gene Technology, Institute of Integrative Omics and Applied Biotechnology (IIOAB), Nonakuri, Purbe Medinpur, West Bengal, India, 6Division of Neuroscience Research and Therapy, The Shores Treatment and Recovery Center, Port St. Lucie, Fl., USA, 7Division of Nutrigenomics, Sanus Biotech, Austin TX, USA, 8Department of Psychiatry, Washington University School of Medicine, St. Louis, Mo, USA, 9Depart- ment of Psychology, Curry College, Milton, MA USA,, 10Department of Psychiatry, Wright State University, Boonshoft School of Medicine, Dayton, OH ,USA. TABLE OF CONTENTS 1. Abstract 2. Introduction 3. Anhedonia and food addiction 4. Anhedonia in RDS Behaviors 5. Anhedonia hypothesis and DA as a “Pleasure” molecule 6. Reward genes and anhedonia: potential therapeutic targets 7. Anti-reward system 8. State of At of Anhedonia 9. Conclusion 10. Acknowledgement 11. References 1. ABSTRACT Anhedonia is a condition that leads to the loss like “anti-reward” phenomena. These processes of feelings pleasure in response to natural reinforcers may have additive, synergistic or antagonistic like food, sex, exercise, and social activities. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Intramolecular Allosteric Communication in Dopamine D2 Receptor Revealed by Evolutionary Amino Acid Covariation
Intramolecular allosteric communication in dopamine D2 receptor revealed by evolutionary amino acid covariation Yun-Min Sunga, Angela D. Wilkinsb, Gustavo J. Rodrigueza, Theodore G. Wensela,1, and Olivier Lichtargea,b,1 aVerna and Marrs Mclean Department of Biochemistry and Molecular Biology, Baylor College of Medicine, Houston, TX 77030; and bDepartment of Molecular and Human Genetics, Baylor College of Medicine, Houston, TX 77030 Edited by Brian K. Kobilka, Stanford University School of Medicine, Stanford, CA, and approved February 16, 2016 (received for review August 19, 2015) The structural basis of allosteric signaling in G protein-coupled led us to ask whether ET could also uncover couplings among receptors (GPCRs) is important in guiding design of therapeutics protein sequence positions not in direct contact. and understanding phenotypic consequences of genetic variation. ET estimates the relative functional sensitivity of a protein to The Evolutionary Trace (ET) algorithm previously proved effective in variations at each residue position using phylogenetic distances to redesigning receptors to mimic the ligand specificities of functionally account for the functional divergence among sequence homologs distinct homologs. We now expand ET to consider mutual informa- (25, 26). Similar ideas can be applied to pairs of sequence positions tion, with validation in GPCR structure and dopamine D2 receptor to recompute ET as the average importance of the couplings be- (D2R) function. The new algorithm, called ET-MIp, identifies evolu- tween a residue and its direct structural neighbors (27). To measure tionarily relevant patterns of amino acid covariations. The improved the evolutionary coupling information between residue pairs, we predictions of structural proximity and D2R mutagenesis demon- present a new algorithm, ET-MIp, that integrates the mutual in- strate that ET-MIp predicts functional interactions between residue formation metric (MIp) (5) to the ET framework. -
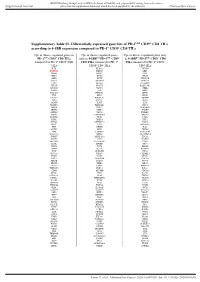
Supplementary Table S5. Differentially Expressed Gene Lists of PD-1High CD39+ CD8 Tils According to 4-1BB Expression Compared to PD-1+ CD39- CD8 Tils
BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) J Immunother Cancer Supplementary Table S5. Differentially expressed gene lists of PD-1high CD39+ CD8 TILs according to 4-1BB expression compared to PD-1+ CD39- CD8 TILs Up- or down- regulated genes in Up- or down- regulated genes Up- or down- regulated genes only PD-1high CD39+ CD8 TILs only in 4-1BBneg PD-1high CD39+ in 4-1BBpos PD-1high CD39+ CD8 compared to PD-1+ CD39- CD8 CD8 TILs compared to PD-1+ TILs compared to PD-1+ CD39- TILs CD39- CD8 TILs CD8 TILs IL7R KLRG1 TNFSF4 ENTPD1 DHRS3 LEF1 ITGA5 MKI67 PZP KLF3 RYR2 SIK1B ANK3 LYST PPP1R3B ETV1 ADAM28 H2AC13 CCR7 GFOD1 RASGRP2 ITGAX MAST4 RAD51AP1 MYO1E CLCF1 NEBL S1PR5 VCL MPP7 MS4A6A PHLDB1 GFPT2 TNF RPL3 SPRY4 VCAM1 B4GALT5 TIPARP TNS3 PDCD1 POLQ AKAP5 IL6ST LY9 PLXND1 PLEKHA1 NEU1 DGKH SPRY2 PLEKHG3 IKZF4 MTX3 PARK7 ATP8B4 SYT11 PTGER4 SORL1 RAB11FIP5 BRCA1 MAP4K3 NCR1 CCR4 S1PR1 PDE8A IFIT2 EPHA4 ARHGEF12 PAICS PELI2 LAT2 GPRASP1 TTN RPLP0 IL4I1 AUTS2 RPS3 CDCA3 NHS LONRF2 CDC42EP3 SLCO3A1 RRM2 ADAMTSL4 INPP5F ARHGAP31 ESCO2 ADRB2 CSF1 WDHD1 GOLIM4 CDK5RAP1 CD69 GLUL HJURP SHC4 GNLY TTC9 HELLS DPP4 IL23A PITPNC1 TOX ARHGEF9 EXO1 SLC4A4 CKAP4 CARMIL3 NHSL2 DZIP3 GINS1 FUT8 UBASH3B CDCA5 PDE7B SOGA1 CDC45 NR3C2 TRIB1 KIF14 TRAF5 LIMS1 PPP1R2C TNFRSF9 KLRC2 POLA1 CD80 ATP10D CDCA8 SETD7 IER2 PATL2 CCDC141 CD84 HSPA6 CYB561 MPHOSPH9 CLSPN KLRC1 PTMS SCML4 ZBTB10 CCL3 CA5B PIP5K1B WNT9A CCNH GEM IL18RAP GGH SARDH B3GNT7 C13orf46 SBF2 IKZF3 ZMAT1 TCF7 NECTIN1 H3C7 FOS PAG1 HECA SLC4A10 SLC35G2 PER1 P2RY1 NFKBIA WDR76 PLAUR KDM1A H1-5 TSHZ2 FAM102B HMMR GPR132 CCRL2 PARP8 A2M ST8SIA1 NUF2 IL5RA RBPMS UBE2T USP53 EEF1A1 PLAC8 LGR6 TMEM123 NEK2 SNAP47 PTGIS SH2B3 P2RY8 S100PBP PLEKHA7 CLNK CRIM1 MGAT5 YBX3 TP53INP1 DTL CFH FEZ1 MYB FRMD4B TSPAN5 STIL ITGA2 GOLGA6L10 MYBL2 AHI1 CAND2 GZMB RBPJ PELI1 HSPA1B KCNK5 GOLGA6L9 TICRR TPRG1 UBE2C AURKA Leem G, et al. -

(12) Patent Application Publication (10) Pub. No.: US 2006/0052435 A1 Van Der Graaf Et Al
US 20060052435A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2006/0052435 A1 Van der Graaf et al. (43) Pub. Date: Mar. 9, 2006 (54) SELECTIVE DOPAMIN D3 RECEPTOR (86) PCT No.: PCT/GB02/05595 AGONSTS FOR THE TREATMENT OF SEXUAL DYSFUNCTION (30) Foreign Application Priority Data (76) Inventors: Pieter Hadewijn Van der Graaf, Dec. 18, 2001 (GB) - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - O1302199 County of Kent (GB); Christopher Peter Wayman, County of Kent (GB); Publication Classification Andrew Douglas Baxter, Bury St. Edmunds (GB); Andrew Simon Cook, (51) Int. Cl. County of Kent (GB); Stephen A6IK 31/405 (2006.01) Kwok-Fung Wong, Guilford, CT (US) (52) U.S. Cl. .............................................................. 514/419 Correspondence Address: (57) ABSTRACT PFIZER INC. PATENT DEPARTMENT, MS8260-1611 The use of a composition comprising a Selective dopamine EASTERN POINT ROAD D3 receptor agonist, wherein Said dopamine D3 receptor GROTON, CT 06340 (US) agonist is at least about 15-times more functionally Selective for a dopamine D3 receptor as compared with a dopamine (21) Appl. No.: 10/499,210 D2 receptor when measured using the same functional assay, in the preparation of a medicament for the treatment and/or (22) PCT Filed: Dec. 10, 2002 prevention of Sexual dysfunction. Patent Application Publication Mar. 9, 2006 Sheet 1 of 2 US 2006/0052435 A1 Figure 1 A Selective D3 agonist provides a significant therapeutic window between prosexual and dose-limitind side effects Apomorphine EHV VE - vomiterection D27.2nMD33.9nM E HV H - hypotension O3 0.56nM Log Free plasma O. 1.0 O 1OO 1OOO conc (nM) D3D24973M agonist E noH noV D2 adOnist D2 ag Conclusion D3 No effect D2 & D3 mediates erection D2 mediates vomiting/hypotension Patent Application Publication Mar. -

Neuronal Dopamine D3 Receptors: Translational Implications for Preclinical Research and CNS Disorders
biomolecules Review Neuronal Dopamine D3 Receptors: Translational Implications for Preclinical Research and CNS Disorders Béla Kiss 1, István Laszlovszky 2, Balázs Krámos 3, András Visegrády 1, Amrita Bobok 1, György Lévay 1, Balázs Lendvai 1 and Viktor Román 1,* 1 Pharmacological and Drug Safety Research, Gedeon Richter Plc., 1103 Budapest, Hungary; [email protected] (B.K.); [email protected] (A.V.); [email protected] (A.B.); [email protected] (G.L.); [email protected] (B.L.) 2 Medical Division, Gedeon Richter Plc., 1103 Budapest, Hungary; [email protected] 3 Spectroscopic Research Department, Gedeon Richter Plc., 1103 Budapest, Hungary; [email protected] * Correspondence: [email protected]; Tel.: +36-1-432-6131; Fax: +36-1-889-8400 Abstract: Dopamine (DA), as one of the major neurotransmitters in the central nervous system (CNS) and periphery, exerts its actions through five types of receptors which belong to two major subfamilies such as D1-like (i.e., D1 and D5 receptors) and D2-like (i.e., D2, D3 and D4) receptors. Dopamine D3 receptor (D3R) was cloned 30 years ago, and its distribution in the CNS and in the periphery, molecular structure, cellular signaling mechanisms have been largely explored. Involvement of D3Rs has been recognized in several CNS functions such as movement control, cognition, learning, reward, emotional regulation and social behavior. D3Rs have become a promising target of drug research and great efforts have been made to obtain high affinity ligands (selective agonists, partial agonists and antagonists) in order to elucidate D3R functions. There has been a strong drive behind the efforts to find drug-like compounds with high affinity and selectivity and various functionality for D3Rs in the hope that they would have potential treatment options in CNS diseases such as schizophrenia, drug abuse, Parkinson’s disease, depression, and restless leg syndrome. -

Cancer Stem Cells—Key Players in Tumor Relapse
cancers Review Cancer Stem Cells—Key Players in Tumor Relapse Monica Marzagalli *, Fabrizio Fontana, Michela Raimondi and Patrizia Limonta Department of Pharmacological and Biomolecular Sciences, University of Milan, via Balzaretti 9, 20133 Milano, Italy; [email protected] (F.F.); [email protected] (M.R.); [email protected] (P.L.) * Correspondence: [email protected]; Tel.: +39-02-503-18427 Simple Summary: Cancer is one of the hardest pathologies to fight, being one of the main causes of death worldwide despite the constant development of novel therapeutic strategies. Therapeutic failure, followed by tumor relapse, might be explained by the existence of a subpopulation of cancer cells called cancer stem cells (CSCs). The survival advantage of CSCs relies on their ability to shape their phenotype against harmful conditions. This Review will summarize the molecular mechanisms exploited by CSCs in order to escape from different kind of therapies, shedding light on the potential novel CSC-specific targets for the development of innovative therapeutic approaches. Abstract: Tumor relapse and treatment failure are unfortunately common events for cancer patients, thus often rendering cancer an uncurable disease. Cancer stem cells (CSCs) are a subset of cancer cells endowed with tumor-initiating and self-renewal capacity, as well as with high adaptive abilities. Altogether, these features contribute to CSC survival after one or multiple therapeutic approaches, thus leading to treatment failure and tumor progression/relapse. Thus, elucidating the molecular mechanisms associated with stemness-driven resistance is crucial for the development of more effective drugs and durable responses. This review will highlight the mechanisms exploited by CSCs to overcome different therapeutic strategies, from chemo- and radiotherapies to targeted therapies Citation: Marzagalli, M.; Fontana, F.; and immunotherapies, shedding light on their plasticity as an insidious trait responsible for their Raimondi, M.; Limonta, P. -

Unveiling Role of Sphingosine-1-Phosphate Receptor 2 As a Brake of Epithelial Stem Cell Proliferation and a Tumor Suppressor in Colorectal Cancer
Unveiling role of Sphingosine-1-phosphate receptor 2 as a brake of epithelial stem cell proliferation and a tumor suppressor in colorectal cancer Luciana Petti Humanitas Clinical and Research Center-IRCCS Giulia Rizzo Humanitas University Federica Rubbino Humanitas University Sudharshan Elangovan Humanitas University Piergiuseppe Colombo Humanitas Clinical and Research Center-IRRCS Restelli Silvia Humanitas University Andrea Piontini Humanitas University Vincenzo Arena Policlinico Universitario Agostino Gemelli Michele Carvello Humanitas Clinical and Research Center-IRCCS Barbara Romano Universita degli Studi di Napoli Federico II Dipartimento di Medicina Clinica e Chirurgia Tommaso Cavalleri Humanitas Clinical and Research Center-IRCCS Achille Anselmo Humanitas Clinical and Research Center-IRCCS Federica Ungaro Humanitas University Silvia D’Alessio Humanitas University Antonino Spinelli Humanitas University Sanja Stifter Page 1/28 University of Rijeka Fabio Grizzi Humanitas Clinical and Research Center-IRCCS Alessandro Sgambato Istituto di Ricovero e Cura a Carattere Scientico Centro di Riferimento Oncologico della Basilicata Silvio Danese Humanitas University Luigi Laghi Universita degli Studi di Parma Alberto Malesci Humanitas University STEFANIA VETRANO ( [email protected] ) Humanitas University Research Keywords: colorectal cancer, Lgr5, S1PR2, PTEN, epithelial proliferation Posted Date: October 13th, 2020 DOI: https://doi.org/10.21203/rs.3.rs-56319/v2 License: This work is licensed under a Creative Commons Attribution 4.0 International License. Read Full License Version of Record: A version of this preprint was published on November 23rd, 2020. See the published version at https://doi.org/10.1186/s13046-020-01740-6. Page 2/28 Abstract Background. Sphingosine-1-phosphate receptor 2 (S1PR2) mediates pleiotropic functions encompassing cell proliferation, survival, and migration, which become collectively de-regulated in cancer. -

Inflammatory Modulation of Hematopoietic Stem Cells by Magnetic Resonance Imaging
Electronic Supplementary Material (ESI) for RSC Advances. This journal is © The Royal Society of Chemistry 2014 Inflammatory modulation of hematopoietic stem cells by Magnetic Resonance Imaging (MRI)-detectable nanoparticles Sezin Aday1,2*, Jose Paiva1,2*, Susana Sousa2, Renata S.M. Gomes3, Susana Pedreiro4, Po-Wah So5, Carolyn Ann Carr6, Lowri Cochlin7, Ana Catarina Gomes2, Artur Paiva4, Lino Ferreira1,2 1CNC-Center for Neurosciences and Cell Biology, University of Coimbra, Coimbra, Portugal, 2Biocant, Biotechnology Innovation Center, Cantanhede, Portugal, 3King’s BHF Centre of Excellence, Cardiovascular Proteomics, King’s College London, London, UK, 4Centro de Histocompatibilidade do Centro, Coimbra, Portugal, 5Department of Neuroimaging, Institute of Psychiatry, King's College London, London, UK, 6Cardiac Metabolism Research Group, Department of Physiology, Anatomy & Genetics, University of Oxford, UK, 7PulseTeq Limited, Chobham, Surrey, UK. *These authors contributed equally to this work. #Correspondence to Lino Ferreira ([email protected]). Experimental Section Preparation and characterization of NP210-PFCE. PLGA (Resomers 502 H; 50:50 lactic acid: glycolic acid) (Boehringer Ingelheim) was covalently conjugated to fluoresceinamine (Sigma- Aldrich) according to a protocol reported elsewhere1. NPs were prepared by dissolving PLGA (100 mg) in a solution of propylene carbonate (5 mL, Sigma). PLGA solution was mixed with perfluoro- 15-crown-5-ether (PFCE) (178 mg) (Fluorochem, UK) dissolved in trifluoroethanol (1 mL, Sigma). This solution was then added to a PVA solution (10 mL, 1% w/v in water) dropwise and stirred for 3 h. The NPs were then transferred to a dialysis membrane and dialysed (MWCO of 50 kDa, Spectrum Labs) against distilled water before freeze-drying. Then, NPs were coated with protamine sulfate (PS). -

G Protein‐Coupled Receptors
S.P.H. Alexander et al. The Concise Guide to PHARMACOLOGY 2019/20: G protein-coupled receptors. British Journal of Pharmacology (2019) 176, S21–S141 THE CONCISE GUIDE TO PHARMACOLOGY 2019/20: G protein-coupled receptors Stephen PH Alexander1 , Arthur Christopoulos2 , Anthony P Davenport3 , Eamonn Kelly4, Alistair Mathie5 , John A Peters6 , Emma L Veale5 ,JaneFArmstrong7 , Elena Faccenda7 ,SimonDHarding7 ,AdamJPawson7 , Joanna L Sharman7 , Christopher Southan7 , Jamie A Davies7 and CGTP Collaborators 1School of Life Sciences, University of Nottingham Medical School, Nottingham, NG7 2UH, UK 2Monash Institute of Pharmaceutical Sciences and Department of Pharmacology, Monash University, Parkville, Victoria 3052, Australia 3Clinical Pharmacology Unit, University of Cambridge, Cambridge, CB2 0QQ, UK 4School of Physiology, Pharmacology and Neuroscience, University of Bristol, Bristol, BS8 1TD, UK 5Medway School of Pharmacy, The Universities of Greenwich and Kent at Medway, Anson Building, Central Avenue, Chatham Maritime, Chatham, Kent, ME4 4TB, UK 6Neuroscience Division, Medical Education Institute, Ninewells Hospital and Medical School, University of Dundee, Dundee, DD1 9SY, UK 7Centre for Discovery Brain Sciences, University of Edinburgh, Edinburgh, EH8 9XD, UK Abstract The Concise Guide to PHARMACOLOGY 2019/20 is the fourth in this series of biennial publications. The Concise Guide provides concise overviews of the key properties of nearly 1800 human drug targets with an emphasis on selective pharmacology (where available), plus links to the open access knowledgebase source of drug targets and their ligands (www.guidetopharmacology.org), which provides more detailed views of target and ligand properties. Although the Concise Guide represents approximately 400 pages, the material presented is substantially reduced compared to information and links presented on the website. -

SZDB: a Database for Schizophrenia Genetic Research
Schizophrenia Bulletin vol. 43 no. 2 pp. 459–471, 2017 doi:10.1093/schbul/sbw102 Advance Access publication July 22, 2016 SZDB: A Database for Schizophrenia Genetic Research Yong Wu1,2, Yong-Gang Yao1–4, and Xiong-Jian Luo*,1,2,4 1Key Laboratory of Animal Models and Human Disease Mechanisms of the Chinese Academy of Sciences and Yunnan Province, Kunming Institute of Zoology, Kunming, China; 2Kunming College of Life Science, University of Chinese Academy of Sciences, Kunming, China; 3CAS Center for Excellence in Brain Science and Intelligence Technology, Chinese Academy of Sciences, Shanghai, China 4YGY and XJL are co-corresponding authors who jointly directed this work. *To whom correspondence should be addressed; Kunming Institute of Zoology, Chinese Academy of Sciences, Kunming, Yunnan 650223, China; tel: +86-871-68125413, fax: +86-871-68125413, e-mail: [email protected] Schizophrenia (SZ) is a debilitating brain disorder with a Introduction complex genetic architecture. Genetic studies, especially Schizophrenia (SZ) is a severe mental disorder charac- recent genome-wide association studies (GWAS), have terized by abnormal perceptions, incoherent or illogi- identified multiple variants (loci) conferring risk to SZ. cal thoughts, and disorganized speech and behavior. It However, how to efficiently extract meaningful biological affects approximately 0.5%–1% of the world populations1 information from bulk genetic findings of SZ remains a and is one of the leading causes of disability worldwide.2–4 major challenge. There is a pressing -

Supplementary Table 2
Supplementary Table 2. Differentially Expressed Genes following Sham treatment relative to Untreated Controls Fold Change Accession Name Symbol 3 h 12 h NM_013121 CD28 antigen Cd28 12.82 BG665360 FMS-like tyrosine kinase 1 Flt1 9.63 NM_012701 Adrenergic receptor, beta 1 Adrb1 8.24 0.46 U20796 Nuclear receptor subfamily 1, group D, member 2 Nr1d2 7.22 NM_017116 Calpain 2 Capn2 6.41 BE097282 Guanine nucleotide binding protein, alpha 12 Gna12 6.21 NM_053328 Basic helix-loop-helix domain containing, class B2 Bhlhb2 5.79 NM_053831 Guanylate cyclase 2f Gucy2f 5.71 AW251703 Tumor necrosis factor receptor superfamily, member 12a Tnfrsf12a 5.57 NM_021691 Twist homolog 2 (Drosophila) Twist2 5.42 NM_133550 Fc receptor, IgE, low affinity II, alpha polypeptide Fcer2a 4.93 NM_031120 Signal sequence receptor, gamma Ssr3 4.84 NM_053544 Secreted frizzled-related protein 4 Sfrp4 4.73 NM_053910 Pleckstrin homology, Sec7 and coiled/coil domains 1 Pscd1 4.69 BE113233 Suppressor of cytokine signaling 2 Socs2 4.68 NM_053949 Potassium voltage-gated channel, subfamily H (eag- Kcnh2 4.60 related), member 2 NM_017305 Glutamate cysteine ligase, modifier subunit Gclm 4.59 NM_017309 Protein phospatase 3, regulatory subunit B, alpha Ppp3r1 4.54 isoform,type 1 NM_012765 5-hydroxytryptamine (serotonin) receptor 2C Htr2c 4.46 NM_017218 V-erb-b2 erythroblastic leukemia viral oncogene homolog Erbb3 4.42 3 (avian) AW918369 Zinc finger protein 191 Zfp191 4.38 NM_031034 Guanine nucleotide binding protein, alpha 12 Gna12 4.38 NM_017020 Interleukin 6 receptor Il6r 4.37 AJ002942