High-Performance Optimizations on Tiled Many-Core Embedded Systems: a Matrix Multiplication Case Study
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
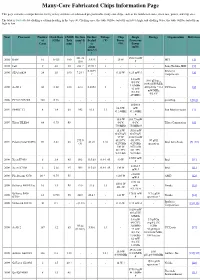
Many-Core Fabricated Chips Information Page
Many-Core Fabricated Chips Information Page This page contains a comprehensive listing of key attributes of fabricated programmable many-core chips, such as the number of cores, clock rate, power, and chip area. The table is Sortable by clicking a column heading in the top row. Clicking once, the table will be sorted from low to high, and clicking twice, the table will be sorted from high to low. Year Processor Number Clock Rate CMOS Die Size Die Size Voltage Chip Single Energy Organization Reference of (GHz) Tech (mm^2) Scaled (V) Power Processor Cores (nm) * to (W) Power 22nm (mW) (mm^2) † 331.24 1562.5 mW 2002 RAW 16 0.425 180 3.975 - 25 W - MIT [1] (16) # 2005 Cell 9 4.0 90 221 ? 17.76 ? 1 - - - Sony,Toshiba,IBM [2] 0.0875 Intelesys 2006 SEAforth24 24 1.0 180 7.29 ? - 0.15 W 6.25 mW # - [3] ? Corporation 2.4 mW 93.0 pJ/Op = @0.9V, 0.093 mW/MHz 116MHz 2006 AsAP 1 36 0.60 180 32.1 0.3852 2 - 300 pJ/Op = 0.3 UC Davis [4] 32 mW mW/MHz @1.8V, @1.8V 475MHz 2006 PC202/203/205 248 0.16 - - - - - - - picoChip [5] [6] 10500.0 84.0 W mW 2007 SPARC T2 8 1.4 65 342 51.3 1.1 - Sun Microsystems [7] @1.4GHz @1.4GHz # 10.8 W 168.75 mW 2007 Tilera TILE64 64 0.75 90 - - - @1V, @1V, - Tilera Corporation [8] 750MHz 750MHz # 15.6 W 195.0 mW @670mV @670mV 97 W 1212.5 mW 275.0 @1.07V, @1.07V, 97 pJ/fl 2007 Polaris(TeraFLOPS) 80 5.67 65 41.25 1.35 Intel Tera-Scale [9] [10] (3) 4.27GHz 4.27GHz operation 230 W 2875 mW @1.35V, @1.35V, 5.67GHz 5.67GHz 15000 mW 2008 Xeon E7450 6 2.4 45 503 115.69 0.9-1.45 90 W - Intel [11] # 21666.7 2008 Xeon X7460 6 2.66 45 503 -

Tousimojarad, Ashkan (2016) GPRM: a High Performance Programming Framework for Manycore Processors. Phd Thesis
Tousimojarad, Ashkan (2016) GPRM: a high performance programming framework for manycore processors. PhD thesis. http://theses.gla.ac.uk/7312/ Copyright and moral rights for this thesis are retained by the author A copy can be downloaded for personal non-commercial research or study This thesis cannot be reproduced or quoted extensively from without first obtaining permission in writing from the Author The content must not be changed in any way or sold commercially in any format or medium without the formal permission of the Author When referring to this work, full bibliographic details including the author, title, awarding institution and date of the thesis must be given Glasgow Theses Service http://theses.gla.ac.uk/ [email protected] GPRM: A HIGH PERFORMANCE PROGRAMMING FRAMEWORK FOR MANYCORE PROCESSORS ASHKAN TOUSIMOJARAD SUBMITTED IN FULFILMENT OF THE REQUIREMENTS FOR THE DEGREE OF Doctor of Philosophy SCHOOL OF COMPUTING SCIENCE COLLEGE OF SCIENCE AND ENGINEERING UNIVERSITY OF GLASGOW NOVEMBER 2015 c ASHKAN TOUSIMOJARAD Abstract Processors with large numbers of cores are becoming commonplace. In order to utilise the available resources in such systems, the programming paradigm has to move towards in- creased parallelism. However, increased parallelism does not necessarily lead to better per- formance. Parallel programming models have to provide not only flexible ways of defining parallel tasks, but also efficient methods to manage the created tasks. Moreover, in a general- purpose system, applications residing in the system compete for the shared resources. Thread and task scheduling in such a multiprogrammed multithreaded environment is a significant challenge. In this thesis, we introduce a new task-based parallel reduction model, called the Glasgow Parallel Reduction Machine (GPRM). -

Multi-Core Processors and Systems: State-Of-The-Art and Study of Performance Increase
Multi-Core Processors and Systems: State-of-the-Art and Study of Performance Increase Abhilash Goyal Computer Science Department San Jose State University San Jose, CA 95192 408-924-1000 [email protected] ABSTRACT speedup. Some tasks are easily divided into parts that can be To achieve the large processing power, we are moving towards processed in parallel. In those scenarios, speed up will most likely Parallel Processing. In the simple words, parallel processing can follow “common trajectory” as shown in Figure 2. If an be defined as using two or more processors (cores, computers) in application has little or no inherent parallelism, then little or no combination to solve a single problem. To achieve the good speedup will be achieved and because of overhead, speed up may results by parallel processing, in the industry many multi-core follow as show by “occasional trajectory” in Figure 2. processors has been designed and fabricated. In this class-project paper, the overview of the state-of-the-art of the multi-core processors designed by several companies including Intel, AMD, IBM and Sun (Oracle) is presented. In addition to the overview, the main advantage of using multi-core will demonstrated by the experimental results. The focus of the experiment is to study speed-up in the execution of the ‘program’ as the number of the processors (core) increases. For this experiment, open source parallel program to count the primes numbers is considered and simulation are performed on 3 nodes Raspberry cluster . Obtained results show that execution time of the parallel program decreases as number of core increases. -

Bit MIPS Processor for Multi-Core
IETE 46th Mid Term Symposium “Impact of Technology on Skill Development” MTS - 2015 Special Issue of International Journal of Electronics, Communication & Soft Computing Science and Engineering, ISSN: 2277 -9477 Design of 16-bit MIPS Processor for Multi -Core SoC Ms. Jinal K.Tapar Ms. Shrushti K. Tapar Prof. Ashish E. Bhande Abstract — This being the era of fast, high performance multiple instructions like add, move, branch etc. computing, there is the need of having efficient optimizations in simultaneously, leading to fast execution speeds. TheThe the processor architecture and at the same time in memory simultaneous working of these different cores on a chip hierarchy too. Each and every day, the advancement of applications in communication and multimedia systems are achieves the goal of “ parallel computing”. Computer compelling to increase number of cores in the main processor viz., architecture courses in university and technical schoolsschools aaroundround dual-core, quad-core, octa-core and so on. Thus, a MPSoC with 8- the world often study the MIPS architecture due to its various cores supporting both message-passing and shared -memory inter- basic and easy-to-understand design characteristics. core communication mechanisms is to be implemented . It is well known that p rocessor is a heart of any computing device. Thus, a The MIPS instruction set archi tecture (ISA) is a RISC 16-bit RISC type processor supporting the MIPS III instruction (Reduced instruction set computer) based microprocessormicroprocessor set architecture (ISA) with special support for detecting the data architecture that was developed by MIPS Computer SystemsSystems dependency cases like RAW is synthesized and sim ulated using Inc. -

Exascale Computing Study: Technology Challenges in Achieving Exascale Systems
ExaScale Computing Study: Technology Challenges in Achieving Exascale Systems Peter Kogge, Editor & Study Lead Keren Bergman Shekhar Borkar Dan Campbell William Carlson William Dally Monty Denneau Paul Franzon William Harrod Kerry Hill Jon Hiller Sherman Karp Stephen Keckler Dean Klein Robert Lucas Mark Richards Al Scarpelli Steven Scott Allan Snavely Thomas Sterling R. Stanley Williams Katherine Yelick September 28, 2008 This work was sponsored by DARPA IPTO in the ExaScale Computing Study with Dr. William Harrod as Program Manager; AFRL contract number FA8650-07-C-7724. This report is published in the interest of scientific and technical information exchange and its publication does not constitute the Government’s approval or disapproval of its ideas or findings NOTICE Using Government drawings, specifications, or other data included in this document for any purpose other than Government procurement does not in any way obligate the U.S. Government. The fact that the Government formulated or supplied the drawings, specifications, or other data does not license the holder or any other person or corporation; or convey any rights or permission to manufacture, use, or sell any patented invention that may relate to them. APPROVED FOR PUBLIC RELEASE, DISTRIBUTION UNLIMITED. This page intentionally left blank. DISCLAIMER The following disclaimer was signed by all members of the Exascale Study Group (listed below): I agree that the material in this document reects the collective views, ideas, opinions and ¯ndings of the study participants only, and not those of any of the universities, corporations, or other institutions with which they are a±liated. Furthermore, the material in this document does not reect the o±cial views, ideas, opinions and/or ¯ndings of DARPA, the Department of Defense, or of the United States government. -

Research Challenges for On-Chip Interconnection Networks
......................................................................................................................................................................................................................................................... RESEARCH CHALLENGES FOR ON-CHIP INTERCONNECTION NETWORKS ......................................................................................................................................................................................................................................................... ON-CHIP INTERCONNECTION NETWORKS ARE RAPIDLY BECOMING A KEY ENABLING John D. Owens TECHNOLOGY FOR COMMODITY MULTICORE PROCESSORS AND SOCS COMMON IN University of California, CONSUMER EMBEDDED SYSTEMS.LAST YEAR, THE NATIONAL SCIENCE FOUNDATION Davis INITIATED A WORKSHOP THAT ADDRESSED UPCOMING RESEARCH ISSUES IN OCIN William J. Dally TECHNOLOGY, DESIGN, AND IMPLEMENTATION AND SET A DIRECTION FOR RESEARCHERS Stanford University IN THE FIELD. ...... VLSI technology’s increased capa- (NoC), whose philosophy has been sum- Ron Ho bility is yielding a more powerful, more marized as ‘‘route packets, not wires.’’2 capable, and more flexible computing Connecting components through an on- Sun Microsystems system on single processor die. The micro- chip network has several advantages over processor industry is moving from single- dedicated wiring, potentially delivering core to multicore and eventually to many- high-bandwidth, low-latency, low-power D.N. (Jay) core architectures, containing tens to hun- -

Unstructured Computations on Emerging Architectures
Unstructured Computations on Emerging Architectures Dissertation by Mohammed A. Al Farhan In Partial Fulfillment of the Requirements For the Degree of Doctor of Philosophy King Abdullah University of Science and Technology Thuwal, Kingdom of Saudi Arabia May 2019 2 EXAMINATION COMMITTEE PAGE The dissertation of M. A. Al Farhan is approved by the examination committee Dissertation Committee: David E. Keyes, Chair Professor, King Abdullah University of Science and Technology Edmond Chow Associate Professor, Georgia Institute of Technology Mikhail Moshkov Professor, King Abdullah University of Science and Technology Markus Hadwiger Associate Professor, King Abdullah University of Science and Technology Hakan Bagci Associate Professor, King Abdullah University of Science and Technology 3 ©May 2019 Mohammed A. Al Farhan All Rights Reserved 4 ABSTRACT Unstructured Computations on Emerging Architectures Mohammed A. Al Farhan his dissertation describes detailed performance engineering and optimization Tof an unstructured computational aerodynamics software system with irregu- lar memory accesses on various multi- and many-core emerging high performance computing scalable architectures, which are expected to be the building blocks of energy-austere exascale systems, and on which algorithmic- and architecture-oriented optimizations are essential for achieving worthy performance. We investigate several state-of-the-practice shared-memory optimization techniques applied to key kernels for the important problem class of unstructured meshes. We illustrate -

Parallel Architecture Hardware and General Purpose Operating System
Parallel Architecture Hardware and General Purpose Operating System Co-design Oskar Schirmer G¨ottingen, 2018-07-10 Abstract Because most optimisations to achieve higher computational performance eventually are limited, parallelism that scales is required. Parallelised hard- ware alone is not sufficient, but software that matches the architecture is required to gain best performance. For decades now, hardware design has been guided by the basic design of existing software, to avoid the higher cost to redesign the latter. In doing so, however, quite a variety of supe- rior concepts is excluded a priori. Consequently, co-design of both hardware and software is crucial where highest performance is the goal. For special purpose application, this co-design is common practice. For general purpose application, however, a precondition for usability of a computer system is an arXiv:1807.03546v1 [cs.DC] 10 Jul 2018 operating system which is both comprehensive and dynamic. As no such op- erating system has ever been designed, a sketch for a comprehensive dynamic operating system is presented, based on a straightforward hardware architec- ture to demonstrate how design decisions regarding software and hardware do coexist and harmonise. 1 Contents 1 Origin 4 1.1 Performance............................ 4 1.2 Limits ............................... 5 1.3 TransparentStructuralOptimisation . 8 1.4 VectorProcessing......................... 9 1.5 Asymmetric Multiprocessing . 10 1.6 SymmetricMulticore ....................... 11 1.7 MultinodeComputer ....................... 12 2 Review 14 2.1 SharedMemory.......................... 14 2.2 Cache ............................... 15 2.3 Synchronisation .......................... 15 2.4 Time-Shared Multitasking . 15 2.5 Interrupts ............................. 16 2.6 Exceptions............................. 16 2.7 PrivilegedMode.......................... 17 2.8 PeripheralI/O ......................... -

High-Performance Optimizations on Tiled Many-Core Embedded Systems: a Matrix Multiplication Case Study
High-performance optimizations on tiled many-core embedded systems: a matrix multiplication case study Arslan Munir, Farinaz Koushanfar, Ann Gordon-Ross & Sanjay Ranka The Journal of Supercomputing An International Journal of High- Performance Computer Design, Analysis, and Use ISSN 0920-8542 J Supercomput DOI 10.1007/s11227-013-0916-9 1 23 Your article is protected by copyright and all rights are held exclusively by Springer Science +Business Media New York. This e-offprint is for personal use only and shall not be self- archived in electronic repositories. If you wish to self-archive your article, please use the accepted manuscript version for posting on your own website. You may further deposit the accepted manuscript version in any repository, provided it is only made publicly available 12 months after official publication or later and provided acknowledgement is given to the original source of publication and a link is inserted to the published article on Springer's website. The link must be accompanied by the following text: "The final publication is available at link.springer.com”. 1 23 Author's personal copy J Supercomput DOI 10.1007/s11227-013-0916-9 High-performance optimizations on tiled many-core embedded systems: a matrix multiplication case study Arslan Munir · Farinaz Koushanfar · Ann Gordon-Ross · Sanjay Ranka © Springer Science+Business Media New York 2013 Abstract Technological advancements in the silicon industry, as predicted by Moore’s law, have resulted in an increasing number of processor cores on a single chip, giving rise to multicore, and subsequently many-core architectures. This work focuses on identifying key architecture and software optimizations to attain high per- formance from tiled many-core architectures (TMAs)—an architectural innovation in the multicore technology. -

Many-Core Key-Value Store
Many-Core Key-Value Store Mateusz Berezecki Eitan Frachtenberg Mike Paleczny Kenneth Steele Facebook Facebook Facebook Tilera [email protected] [email protected] [email protected] [email protected] Abstract—Scaling data centers to handle task-parallel work- This sharing aspect is critical for large-scale web sites, loads requires balancing the cost of hardware, operations, where the sheer data size and number of queries on it far and power. Low-power, low-core-count servers reduce costs in exceed the capacity of any single server. Such large-data one of these dimensions, but may require additional nodes to provide the required quality of service or increase costs by workloads can be I/O intensive and have no obvious access under-utilizing memory and other resources. patterns that would foster prefetching. Caching and sharing We show that the throughput, response time, and power the data among many front-end servers allows system ar- consumption of a high-core-count processor operating at a low chitects to plan for simple, linear scaling, adding more KV clock rate and very low power consumption can perform well stores to the cluster as the data grows. At Facebook, we when compared to a platform using faster but fewer commodity have used this property grow larger and larger clusters, and cores. Specific measurements are made for a key-value store, 3 Memcached, using a variety of systems based on three different scaled Memcached accordingly . processors: the 4-core Intel Xeon L5520, 8-core AMD Opteron But as these clusters grow larger, their associated oper- 6128 HE, and 64-core Tilera TILEPro64. -

Power and Performance Optimization for Network-On-Chip Based Many-Core Processors
Power and Performance Optimization for Network-on-Chip based Many-Core Processors YUAN YAO Doctoral Thesis in Information and Communication Technology (INFKOMTE) School of Electrical Engineering and Computer Science KTH Royal Institute of Technology Stockholm, Sweden 2019 KTH School of Electrical Engineering and Computer Science TRITA-EECS-AVL-2019:44 Electrum 229, SE-164 40 Stockholm ISBN 978-91-7873-182-4 SWEDEN Akademisk avhandling som med tillstånd av Kungl Tekniska högskolan framlägges till offentlig granskning för avläggande av teknologie doktorsexamen i Informations- och Kommunikationsteknik fredag den 23 Augusti 2019 klockan 9.00 i Sal B, Elect- rum, Kungl Tekniska högskolan, Kistagången 16, Kista. © Yuan Yao, May 27, 2019 Tryck: Universitetsservice US AB iii Abstract Network-on-Chip (NoC) is emerging as a critical shared architecture for CMPs (Chip Multi-/Many-Core Processors) running parallel and concurrent applications. As the core count scales up and the transistor size shrinks, how to optimize power and performance for NoC open new research challenges. As it can potentially consume 20–40% of the entire chip power [20, 40, 81], NoC power efficiency has emerged as one of the main design constraints in today’s and future high performance CMPs. For NoC power management, we propose a novel on-chip DVFS technique that is able to adjust per-region NoC V/F according to voted V/F levels from communicating threads. A thread periodically votes for a preferred NoC V/F level that best suits its individual performance interests. The final DVFS decision of each region is adjusted by a region DVFS controller democratically based on the majority of votes it receives. -

When HPC Meets Big Data in the Cloud
When HPC meets Big Data in the Cloud Prof. Cho-Li Wang The University of Hong Kong Dec. 17, 2013 @Cloud-Asia Big Data: The “4Vs" Model • High Volume (amount of data) • High Velocity (speed of data in and out) • High Variety (range of data types and sources) • High Values : Most Important 2010: 800,000 petabytes (would fill a stack of DVDs 2.5 x 1018 reaching from the earth to the moon and back) By 2020, that pile of DVDs would stretch half way to Mars. Google Trend: (12/2012) Big Data vs. Data Analytics vs. Cloud Computing Cloud Computing Big Data 12/2012 • McKinsey Global Institute (MGI) : – Using big data, retailers could increase its operating margin by more than 60%. – The U.S. could reduce its healthcare expenditure by 8% – Government administrators in Europe could save more than €100 billion ($143 billion). Google Trend: 12/2013 Big Data vs. Data Analytics vs. Cloud Computing “Big Data” in 2013 Outline • Part I: Multi-granularity Computation Migration o "A Computation Migration Approach to Elasticity of Cloud Computing“ (previous work) • Part II: Big Data Computing on Future Maycore Chips o Crocodiles: Cloud Runtime with Object Coherence On Dynamic tILES for future 1000-core tiled processors” (ongoing) Big Data Too Big To Move Part I Multi-granularity Computation Migration Source: Cho-Li Wang, King Tin Lam and Ricky Ma, "A Computation Migration Approach to Elasticity of Cloud Computing", Network and Traffic Engineering in Emerging Distributed Computing Applications, IGI Global, pp. 145-178, July, 2012. Multi-granularity Computation