Parallel Architecture Hardware and General Purpose Operating System
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Memory Protection at Option
Memory Protection at Option Application-Tailored Memory Safety in Safety-Critical Embedded Systems – Speicherschutz nach Wahl Auf die Anwendung zugeschnittene Speichersicherheit in sicherheitskritischen eingebetteten Systemen Der Technischen Fakultät der Universität Erlangen-Nürnberg zur Erlangung des Grades Doktor-Ingenieur vorgelegt von Michael Stilkerich Erlangen — 2012 Als Dissertation genehmigt von der Technischen Fakultät Universität Erlangen-Nürnberg Tag der Einreichung: 09.07.2012 Tag der Promotion: 30.11.2012 Dekan: Prof. Dr.-Ing. Marion Merklein Berichterstatter: Prof. Dr.-Ing. Wolfgang Schröder-Preikschat Prof. Dr. Michael Philippsen Abstract With the increasing capabilities and resources available on microcontrollers, there is a trend in the embedded industry to integrate multiple software functions on a single system to save cost, size, weight, and power. The integration raises new requirements, thereunder the need for spatial isolation, which is commonly established by using a memory protection unit (MPU) that can constrain access to the physical address space to a fixed set of address regions. MPU-based protection is limited in terms of available hardware, flexibility, granularity and ease of use. Software-based memory protection can provide an alternative or complement MPU-based protection, but has found little attention in the embedded domain. In this thesis, I evaluate qualitative and quantitative advantages and limitations of MPU-based memory protection and software-based protection based on a multi-JVM. I developed a framework composed of the AUTOSAR OS-like operating system CiAO and KESO, a Java implementation for deeply embedded systems. The framework allows choosing from no memory protection, MPU-based protection, software-based protection, and a combination of the two. -

Uva-DARE (Digital Academic Repository)
UvA-DARE (Digital Academic Repository) On the construction of operating systems for the Microgrid many-core architecture van Tol, M.W. Publication date 2013 Link to publication Citation for published version (APA): van Tol, M. W. (2013). On the construction of operating systems for the Microgrid many-core architecture. General rights It is not permitted to download or to forward/distribute the text or part of it without the consent of the author(s) and/or copyright holder(s), other than for strictly personal, individual use, unless the work is under an open content license (like Creative Commons). Disclaimer/Complaints regulations If you believe that digital publication of certain material infringes any of your rights or (privacy) interests, please let the Library know, stating your reasons. In case of a legitimate complaint, the Library will make the material inaccessible and/or remove it from the website. Please Ask the Library: https://uba.uva.nl/en/contact, or a letter to: Library of the University of Amsterdam, Secretariat, Singel 425, 1012 WP Amsterdam, The Netherlands. You will be contacted as soon as possible. UvA-DARE is a service provided by the library of the University of Amsterdam (https://dare.uva.nl) Download date:27 Sep 2021 General Bibliography [1] J. Aas. Understanding the linux 2.6.8.1 cpu scheduler. Technical report, Silicon Graphics Inc. (SGI), Eagan, MN, USA, February 2005. [2] D. Abts, S. Scott, and D. J. Lilja. So many states, so little time: Verifying memory coherence in the Cray X1. In Proceedings of the 17th International Symposium on Parallel and Distributed Processing, IPDPS '03, page 10 pp., Washington, DC, USA, April 2003. -

Early Stored Program Computers
Stored Program Computers Thomas J. Bergin Computing History Museum American University 7/9/2012 1 Early Thoughts about Stored Programming • January 1944 Moore School team thinks of better ways to do things; leverages delay line memories from War research • September 1944 John von Neumann visits project – Goldstine’s meeting at Aberdeen Train Station • October 1944 Army extends the ENIAC contract research on EDVAC stored-program concept • Spring 1945 ENIAC working well • June 1945 First Draft of a Report on the EDVAC 7/9/2012 2 First Draft Report (June 1945) • John von Neumann prepares (?) a report on the EDVAC which identifies how the machine could be programmed (unfinished very rough draft) – academic: publish for the good of science – engineers: patents, patents, patents • von Neumann never repudiates the myth that he wrote it; most members of the ENIAC team contribute ideas; Goldstine note about “bashing” summer7/9/2012 letters together 3 • 1.0 Definitions – The considerations which follow deal with the structure of a very high speed automatic digital computing system, and in particular with its logical control…. – The instructions which govern this operation must be given to the device in absolutely exhaustive detail. They include all numerical information which is required to solve the problem…. – Once these instructions are given to the device, it must be be able to carry them out completely and without any need for further intelligent human intervention…. • 2.0 Main Subdivision of the System – First: since the device is a computor, it will have to perform the elementary operations of arithmetics…. – Second: the logical control of the device is the proper sequencing of its operations (by…a control organ. -

Microprocessor Architecture
EECE416 Microcomputer Fundamentals Microprocessor Architecture Dr. Charles Kim Howard University 1 Computer Architecture Computer System CPU (with PC, Register, SR) + Memory 2 Computer Architecture •ALU (Arithmetic Logic Unit) •Binary Full Adder 3 Microprocessor Bus 4 Architecture by CPU+MEM organization Princeton (or von Neumann) Architecture MEM contains both Instruction and Data Harvard Architecture Data MEM and Instruction MEM Higher Performance Better for DSP Higher MEM Bandwidth 5 Princeton Architecture 1.Step (A): The address for the instruction to be next executed is applied (Step (B): The controller "decodes" the instruction 3.Step (C): Following completion of the instruction, the controller provides the address, to the memory unit, at which the data result generated by the operation will be stored. 6 Harvard Architecture 7 Internal Memory (“register”) External memory access is Very slow For quicker retrieval and storage Internal registers 8 Architecture by Instructions and their Executions CISC (Complex Instruction Set Computer) Variety of instructions for complex tasks Instructions of varying length RISC (Reduced Instruction Set Computer) Fewer and simpler instructions High performance microprocessors Pipelined instruction execution (several instructions are executed in parallel) 9 CISC Architecture of prior to mid-1980’s IBM390, Motorola 680x0, Intel80x86 Basic Fetch-Execute sequence to support a large number of complex instructions Complex decoding procedures Complex control unit One instruction achieves a complex task 10 -

What Do We Mean by Architecture?
Embedded programming: Comparing the performance and development workflows for architectures Embedded programming week FABLAB BRIGHTON 2018 What do we mean by architecture? The architecture of microprocessors and microcontrollers are classified based on the way memory is allocated (memory architecture). There are two main ways of doing this: Von Neumann architecture (also known as Princeton) Von Neumann uses a single unified cache (i.e. the same memory) for both the code (instructions) and the data itself, Under pure von Neumann architecture the CPU can be either reading an instruction or reading/writing data from/to the memory. Both cannot occur at the same time since the instructions and data use the same bus system. Harvard architecture Harvard architecture uses different memory allocations for the code (instructions) and the data, allowing it to be able to read instructions and perform data memory access simultaneously. The best performance is achieved when both instructions and data are supplied by their own caches, with no need to access external memory at all. How does this relate to microcontrollers/microprocessors? We found this page to be a good introduction to the topic of microcontrollers and microprocessors, the architectures they use and the difference between some of the common types. First though, it’s worth looking at the difference between a microprocessor and a microcontroller. Microprocessors (e.g. ARM) generally consist of just the Central Processing Unit (CPU), which performs all the instructions in a computer program, including arithmetic, logic, control and input/output operations. Microcontrollers (e.g. AVR, PIC or 8051) contain one or more CPUs with RAM, ROM and programmable input/output peripherals. -

Simulating Physics with Computers
International Journal of Theoretical Physics, VoL 21, Nos. 6/7, 1982 Simulating Physics with Computers Richard P. Feynman Department of Physics, California Institute of Technology, Pasadena, California 91107 Received May 7, 1981 1. INTRODUCTION On the program it says this is a keynote speech--and I don't know what a keynote speech is. I do not intend in any way to suggest what should be in this meeting as a keynote of the subjects or anything like that. I have my own things to say and to talk about and there's no implication that anybody needs to talk about the same thing or anything like it. So what I want to talk about is what Mike Dertouzos suggested that nobody would talk about. I want to talk about the problem of simulating physics with computers and I mean that in a specific way which I am going to explain. The reason for doing this is something that I learned about from Ed Fredkin, and my entire interest in the subject has been inspired by him. It has to do with learning something about the possibilities of computers, and also something about possibilities in physics. If we suppose that we know all the physical laws perfectly, of course we don't have to pay any attention to computers. It's interesting anyway to entertain oneself with the idea that we've got something to learn about physical laws; and if I take a relaxed view here (after all I'm here and not at home) I'll admit that we don't understand everything. -

High Performance Computing Systems
High Performance Computing Systems Multikernels Doug Shook Multikernels Two predominant approaches to OS: – Full weight kernel – Lightweight kernel Why not both? – How does implementation affect usage and performance? Gerolfi, et. al. “A Multi-Kernel Survey for High- Performance Computing,” 2016 2 FusedOS Assumes heterogeneous architecture – Linux on full cores – LWK requests resources from linux to run programs Uses CNK as its LWK 3 IHK/McKernel Uses an Interface for Heterogeneous Kernels – Resource allocation – Communication McKernel is the LWK – Only operable with IHK Uses proxy processes 4 mOS Embeds LWK into the Linux kernel – LWK is visible to Linux just like any other process Resource allocation is performed by sysadmin/user 5 FFMK Uses the L4 microkernel – What is a microkernel? Also uses a para-virtualized Linux instance – What is paravirtualization? 6 Hobbes Pisces Node Manager Kitten LWK Palacios Virtual Machine Monitor 7 Sysadmin Criteria Is the LWK standalone? Which kernel is booted by the BIOS? How and when are nodes partitioned? 8 Application Criteria What is the level of POSIX support in the LWK? What is the pseudo file system support? How does an application access Linux functionality? What is the system call overhead? Can LWK and Linux share memory? Can a single process span Linux and the LWK? Does the LWK support NUMA? 9 Linux Criteria Are LWK processes visible to standard tools like ps and top? Are modifications to the Linux kernel necessary? Do Linux kernel changes propagate to the LWK? -
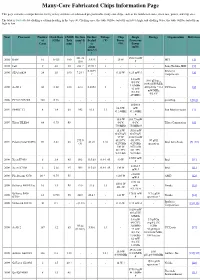
Many-Core Fabricated Chips Information Page
Many-Core Fabricated Chips Information Page This page contains a comprehensive listing of key attributes of fabricated programmable many-core chips, such as the number of cores, clock rate, power, and chip area. The table is Sortable by clicking a column heading in the top row. Clicking once, the table will be sorted from low to high, and clicking twice, the table will be sorted from high to low. Year Processor Number Clock Rate CMOS Die Size Die Size Voltage Chip Single Energy Organization Reference of (GHz) Tech (mm^2) Scaled (V) Power Processor Cores (nm) * to (W) Power 22nm (mW) (mm^2) † 331.24 1562.5 mW 2002 RAW 16 0.425 180 3.975 - 25 W - MIT [1] (16) # 2005 Cell 9 4.0 90 221 ? 17.76 ? 1 - - - Sony,Toshiba,IBM [2] 0.0875 Intelesys 2006 SEAforth24 24 1.0 180 7.29 ? - 0.15 W 6.25 mW # - [3] ? Corporation 2.4 mW 93.0 pJ/Op = @0.9V, 0.093 mW/MHz 116MHz 2006 AsAP 1 36 0.60 180 32.1 0.3852 2 - 300 pJ/Op = 0.3 UC Davis [4] 32 mW mW/MHz @1.8V, @1.8V 475MHz 2006 PC202/203/205 248 0.16 - - - - - - - picoChip [5] [6] 10500.0 84.0 W mW 2007 SPARC T2 8 1.4 65 342 51.3 1.1 - Sun Microsystems [7] @1.4GHz @1.4GHz # 10.8 W 168.75 mW 2007 Tilera TILE64 64 0.75 90 - - - @1V, @1V, - Tilera Corporation [8] 750MHz 750MHz # 15.6 W 195.0 mW @670mV @670mV 97 W 1212.5 mW 275.0 @1.07V, @1.07V, 97 pJ/fl 2007 Polaris(TeraFLOPS) 80 5.67 65 41.25 1.35 Intel Tera-Scale [9] [10] (3) 4.27GHz 4.27GHz operation 230 W 2875 mW @1.35V, @1.35V, 5.67GHz 5.67GHz 15000 mW 2008 Xeon E7450 6 2.4 45 503 115.69 0.9-1.45 90 W - Intel [11] # 21666.7 2008 Xeon X7460 6 2.66 45 503 -

Endian: from the Ground up a Coordinated Approach
WHITEPAPER Endian: From the Ground Up A Coordinated Approach By Kevin Johnston Senior Staff Engineer, Verilab July 2008 © 2008 Verilab, Inc. 7320 N MOPAC Expressway | Suite 203 | Austin, TX 78731-2309 | 512.372.8367 | www.verilab.com WHITEPAPER INTRODUCTION WHat DOES ENDIAN MEAN? Data in Imagine XYZ Corp finally receives first silicon for the main Endian relates the significance order of symbols to the computers chip for its new camera phone. All initial testing proceeds position order of symbols in any representation of any flawlessly until they try an image capture. The display is kind of data, if significance is position-dependent in that regularly completely garbled. representation. undergoes Of course there are many possible causes, and the debug Let’s take a specific type of data, and a specific form of dozens if not team analyzes code traces, packet traces, memory dumps. representation that possesses position-dependent signifi- There is no problem with the code. There is no problem cance: A digit sequence representing a numeric value, like hundreds of with data transport. The problem is eventually tracked “5896”. Each digit position has significance relative to all down to the data format. other digit positions. transformations The development team ran many, many pre-silicon simula- I’m using the word “digit” in the generalized sense of an between tions of the system to check datapath integrity, bandwidth, arbitrary radix, not necessarily decimal. Decimal and a few producer and error correction. The verification effort checked that all other specific radixes happen to be particularly useful for the data submitted at the camera port eventually emerged illustration simply due to their familiarity, but all of the consumer. -

Using an MPU to Enforce Spatial Separation
HighIntegritySystems Using an MPU to Enforce Spatial Separation Issue 1.3 - November 26, 2020 Copyright WITTENSTEIN aerospace & simulation ltd date as document, all rights reserved. WITTENSTEIN high integrity systems v Americas: +1 408 625 4712 ROTW: +44 1275 395 600 Email: [email protected] Web: www.highintegritysystems.com HighIntegritySystems Contents Contents..........................................................................................................................................2 List Of Figures.................................................................................................................................3 List Of Notation...............................................................................................................................3 CHAPTER 1 Introduction.....................................................................................................4 1.1 Introduction..............................................................................................................................4 1.2 Use Case - An Embedded System...........................................................................................5 CHAPTER 2 System Architecture and its Effect on Spatial Separation......................6 2.1 Spatial Separation with a Multi-Processor System....................................................................6 2.2 Spatial Separation with a Multi-Core System............................................................................6 2.3 Spatial Separation -

Think in G Machines Corporation Connection
THINK ING MACHINES CORPORATION CONNECTION MACHINE TECHNICAL SUMMARY The Connection Machine System Connection Machine Model CM-2 Technical Summary ................................................................. Version 6.0 November 1990 Thinking Machines Corporation Cambridge, Massachusetts First printing, November 1990 The information in this document is subject to change without notice and should not be construed as a commitment by Thinking Machines Corporation. Thinking Machines Corporation reserves the right to make changes to any products described herein to improve functioning or design. Although the information in this document has been reviewed and is believed to be reliable, Thinking Machines Corporation does not assume responsibility or liability for any errors that may appear in this document. Thinking Machines Corporation does not assume any liability arising from the application or use of any information or product described herein. Connection Machine® is a registered trademark of Thinking Machines Corporation. CM-1, CM-2, CM-2a, CM, and DataVault are trademarks of Thinking Machines Corporation. C*®is a registered trademark of Thinking Machines Corporation. Paris, *Lisp, and CM Fortran are trademarks of Thinking Machines Corporation. C/Paris, Lisp/Paris, and Fortran/Paris are trademarks of Thinking Machines Corporation. VAX, ULTRIX, and VAXBI are trademarks of Digital Equipment Corporation. Symbolics, Symbolics 3600, and Genera are trademarks of Symbolics, Inc. Sun, Sun-4, SunOS, and Sun Workstation are registered trademarks of Sun Microsystems, Inc. UNIX is a registered trademark of AT&T Bell Laboratories. The X Window System is a trademark of the Massachusetts Institute of Technology. StorageTek is a registered trademark of Storage Technology Corporation. Trinitron is a registered trademark of Sony Corporation. -

Strict Memory Protection for Microcontrollers
Master Thesis Spring 2019 Strict Memory Protection for Microcontrollers Erlend Sveen Supervisor: Jingyue Li Co-supervisor: Magnus Själander Sunday 17th February, 2019 Abstract Modern desktop systems protect processes from each other with memory protection. Microcontroller systems, which lack support for memory virtualization, typically only uses memory protection for areas that the programmer deems necessary and does not separate processes completely. As a result the application still appears monolithic and only a handful of errors may be detected. This thesis presents a set of solutions for complete separation of processes, unleash- ing the full potential of the memory protection unit embedded in modern ARM-based microcontrollers. The operating system loads multiple programs from disk into indepen- dently protected portions of memory. These programs may then be started, stopped, modified, crashed etc. without affecting other running programs. When loading pro- grams, a new allocation algorithm is used that automatically aligns the memories for use with the protection hardware. A pager is written to satisfy additional run-time demands of applications, and communication primitives for inter-process communication is made available. Since every running process is unable to get access to other running processes, not only reliability but also security is improved. An application may be split so that unsafe or error-prone code is separated from mission-critical code, allowing it to be independently restarted when an error occurs. With executable and writeable memory access rights being mutually exclusive, code injection is made harder to perform. The solution is all transparent to the programmer. All that is required is to split an application into sub-programs that operates largely independently.