Power and Performance Optimization for Network-On-Chip Based Many-Core Processors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

1 in the United States District Court
Case 6:20-cv-00779 Document 1 Filed 08/25/20 Page 1 of 33 IN THE UNITED STATES DISTRICT COURT WESTERN DISTRICT OF TEXAS AUSTIN DIVISION AURIGA INNOVATIONS, INC. C.A. No. 6:20-cv-779 Plaintiff, v. JURY TRIAL DEMANDED INTEL CORPORATION, HP INC., and HEWLETT PACKARD ENTERPRISE COMPANY, Defendants COMPLAINT Plaintiff Auriga Innovations, Inc. (“Auriga” or “Plaintiff”) files this complaint for patent infringeMent against Defendants Intel Corporation (“Intel”), HP Inc. (“HPI”), and Hewlett Packard Enterprise Company (“HPE”) (collectively, “Defendants”) under 35 U.S.C. § 217 et seq. as a result of Defendants’ unauthorized use of Auriga’s patents and alleges as follows: THE PARTIES 1. Auriga is a corporation organized and existing under the laws of the state of Delaware with its principal place of business at 1891 Robertson Road, Suite 100, Ottawa, ON K2H 5B7 Canada. 2. On information and belief, Intel is a Delaware corporation with a place of business at 2200 Mission College Boulevard, Santa Clara, California 95054. 3. On information and belief, since April 1989, Intel has been registered to do business in the State of Texas under Texas Taxpayer Number 19416727436 and has places of business at 1 Case 6:20-cv-00779 Document 1 Filed 08/25/20 Page 2 of 33 1300 S Mopac Expressway, Austin, Texas 78746; 6500 River Place Blvd, Bldg 7, Austin, Texas 78730; and 5113 Southwest Parkway, Austin, Texas 78735 (collectively, “Intel Austin Offices”). https://www.intel.com/content/www/us/en/location/usa.htMl. 4. On information and belief, HPI is a Delaware corporation with a principal place of business at 1501 Page Mill Road, Palo Alto, CA 94304. -

China's Progress in Semiconductor Manufacturing Equipment
MARCH 2021 China’s Progress in Semiconductor Manufacturing Equipment Accelerants and Policy Implications CSET Policy Brief AUTHORS Will Hunt Saif M. Khan Dahlia Peterson Executive Summary China has a chip problem. It depends entirely on the United States and U.S. allies for access to advanced commercial semiconductors, which underpin all modern technologies, from smartphones to fighter jets to artificial intelligence. China’s current chip dependence allows the United States and its allies to control the export of advanced chips to Chinese state and private actors whose activities threaten human rights and international security. Chip dependence is also expensive: China currently depends on imports for most of the chips it consumes. China has therefore prioritized indigenizing advanced semiconductor manufacturing equipment (SME), which chip factories require to make leading-edge chips. But indigenizing advanced SME will be hard since Chinese firms have serious weaknesses in almost all SME sub-sectors, especially photolithography, metrology, and inspection. Meanwhile, the top global SME firms—based in the United States, Japan, and the Netherlands—enjoy wide moats of intellectual property and world- class teams of engineers, making it exceptionally difficult for newcomers to the SME industry to catch up to the leading edge. But for a country with China’s resources and political will, catching up in SME is not impossible. Whether China manages to close this gap will depend on its access to five technological accelerants: 1. Equipment components. Building advanced SME often requires access to a range of complex components, which SME firms often buy from third party suppliers and then assemble into finished SME. -

Microcode Revision Guidance August 31, 2019 MCU Recommendations
microcode revision guidance August 31, 2019 MCU Recommendations Section 1 – Planned microcode updates • Provides details on Intel microcode updates currently planned or available and corresponding to Intel-SA-00233 published June 18, 2019. • Changes from prior revision(s) will be highlighted in yellow. Section 2 – No planned microcode updates • Products for which Intel does not plan to release microcode updates. This includes products previously identified as such. LEGEND: Production Status: • Planned – Intel is planning on releasing a MCU at a future date. • Beta – Intel has released this production signed MCU under NDA for all customers to validate. • Production – Intel has completed all validation and is authorizing customers to use this MCU in a production environment. -

Single Board Computer
Single Board Computer SBC with the Intel® 8th generation Core™/Xeon® (formerly Coffee Lake H) SBC-C66 and 9th generation Core™ / Xeon® / Pentium® / Celeron® (formerly Coffee Lake Refresh) CPUs High-performing, flexible solution for intelligence at the edge HIGHLIGHTS CONNECTIVITY CPU 2x USB 3.1; 4x USB 2.0; NVMe SSD Slot; PCI-e x8 Intel® 8th gen. Core™ / Xeon® and 9th gen. Core™ / port (PCI-e x16 mechanical slot); VPU High Speed Xeon® / Pentium® / Celeron® CPUs Connector with 4xUSB3.1 + 2x PCI-ex4 GRAPHICS MEMORY Intel® UHD Graphics 630/P630 architecture, up to 128GB DDR4 memory on 4x SO-DIMM Slots supports up to 3 independent displays (ECC supported) Available in Industrial Temperature Range MAIN FIELDS OF APPLICATION Biomedical/ Gaming Industrial Industrial Surveillance Medical devices Automation and Internet of Control Things FEATURES ® ™ ® Intel 8th generation Core /Xeon (formerly Coffee Lake H) CPUs: Max Cores 6 • Intel® Core™ i7-8850H, Six Core @ 2.6GHz (4.3GHz Max 1 Core Turbo), 9MB Cache, 45W TDP (35W cTDP), with Max Thread 12 HyperThreading • Intel® Core™ i5-8400H, Quad Core @ 2.5GHz (4.2GHz Intel® QM370, HM370 or CM246 Platform Controller Hub Chipset Max 1 Core Turbo), 8MB Cache, 45W TDP (35W cTDP), (PCH) with HyperThreading • Intel® Core™ i3-8100H, Quad Core @ 3.0GHz, 6MB 2x DDR4-2666 or 4x DDR4-2444 ECC SODIMM Slots, up to 128GB total (only with 4 SODIMM modules). Cache, 45W TDP (35W cTDP) Memory ® ™ ® ® ECC DDR4 memory modules supported only with Xeon Core Information subject to change. Please visit www.seco.com to find the latest version of this datasheet Information subject to change. -

Technology Roadmap for 22Nm CMOS and Beyond
Technology Roadmap for 22nm CMOS and beyond June 1, 2009 IEDST 2009@IIT-Bombay Hiroshi Iwai Tokyo Institute of Technology 1 Outline 1. Scaling 2. ITRS Roadmap 3. Voltage Scaling/ Low Power and Leakage 4. SRAM Cell Scaling 5.Roadmap for further future as a personal view 2 1. Scaling 3 Scaling Method: by R. Dennard in 1974 1 Wdep: Space Charge Region (or Depletion Region) Width 1 1 SDWdep has to be suppressed 1 Otherwise, large leakage Wdep between S and D I Leakage current Potential in space charge region is high, and thus, electrons in source are 0 attracted to the space charge region. 0 V 1 K=0.7 X , Y, Z :K, V :K, Na : 1/K for By the scaling, Wdep is suppressed in proportion, example and thus, leakage can be suppressed. K Good scaled I-V characteristics K K Wdep V/Na K Wdep I I : K : K 0 0K V 4 Downscaling merit: Beautiful! Geometry & L , W g g K Scaling K : K=0.7 for example Supply voltage Tox, Vdd Id = vsatWgCo (Vg‐Vth) Co: gate C per unit area Drive current I d K –1 ‐1 ‐1 in saturation Wg (tox )(Vg‐Vth)= Wgtox (Vg‐Vth)= KK K=K Id per unit Wg Id/µm 1 Id per unit Wg = Id / Wg= 1 Gate capacitance Cg K Cg = εoεoxLgWg/tox KK/K = K Switching speed τ K τ= CgVdd/Id KK/K= K Clock frequency f 1/K f = 1/τ = 1/K Chip area Achip α α: Scaling factor In the past, α>1 for most cases Integration (# of Tr) N α/K2 N α/K2 = 1/K2 , when α=1 Power per chip P α fNCV2/2 K‐1(αK‐2)K (K1 )2= α = 1, when α=1 5 k= 0.7 and α =1 k= 0.72 =0.5 and α =1 Single MOFET Vdd 0.7 Vdd 0.5 Lg 0.7 Lg 0.5 Id 0.7 Id 0.5 Cg 0.7 Cg 0.5 P (Power)/Clock P (Power)/Clock 0.73 = 0.34 0.53 = 0.125 τ (Switching time) 0.7 τ (Switching time) 0.5 Chip N (# of Tr) 1/0.72 = 2 N (# of Tr) 1/0.52 = 4 f (Clock) 1/0.7 = 1.4 f (Clock) 1/0.5 = 2 P (Power) 1 P (Power) 1 6 - The concerns for limits of down-scaling have been announced for every generation. -
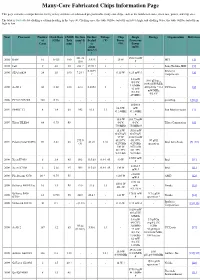
Many-Core Fabricated Chips Information Page
Many-Core Fabricated Chips Information Page This page contains a comprehensive listing of key attributes of fabricated programmable many-core chips, such as the number of cores, clock rate, power, and chip area. The table is Sortable by clicking a column heading in the top row. Clicking once, the table will be sorted from low to high, and clicking twice, the table will be sorted from high to low. Year Processor Number Clock Rate CMOS Die Size Die Size Voltage Chip Single Energy Organization Reference of (GHz) Tech (mm^2) Scaled (V) Power Processor Cores (nm) * to (W) Power 22nm (mW) (mm^2) † 331.24 1562.5 mW 2002 RAW 16 0.425 180 3.975 - 25 W - MIT [1] (16) # 2005 Cell 9 4.0 90 221 ? 17.76 ? 1 - - - Sony,Toshiba,IBM [2] 0.0875 Intelesys 2006 SEAforth24 24 1.0 180 7.29 ? - 0.15 W 6.25 mW # - [3] ? Corporation 2.4 mW 93.0 pJ/Op = @0.9V, 0.093 mW/MHz 116MHz 2006 AsAP 1 36 0.60 180 32.1 0.3852 2 - 300 pJ/Op = 0.3 UC Davis [4] 32 mW mW/MHz @1.8V, @1.8V 475MHz 2006 PC202/203/205 248 0.16 - - - - - - - picoChip [5] [6] 10500.0 84.0 W mW 2007 SPARC T2 8 1.4 65 342 51.3 1.1 - Sun Microsystems [7] @1.4GHz @1.4GHz # 10.8 W 168.75 mW 2007 Tilera TILE64 64 0.75 90 - - - @1V, @1V, - Tilera Corporation [8] 750MHz 750MHz # 15.6 W 195.0 mW @670mV @670mV 97 W 1212.5 mW 275.0 @1.07V, @1.07V, 97 pJ/fl 2007 Polaris(TeraFLOPS) 80 5.67 65 41.25 1.35 Intel Tera-Scale [9] [10] (3) 4.27GHz 4.27GHz operation 230 W 2875 mW @1.35V, @1.35V, 5.67GHz 5.67GHz 15000 mW 2008 Xeon E7450 6 2.4 45 503 115.69 0.9-1.45 90 W - Intel [11] # 21666.7 2008 Xeon X7460 6 2.66 45 503 -

Attacking X86 Processor Integrity from Software
V0LTpwn: Attacking x86 Processor Integrity from Software Zijo Kenjar and Tommaso Frassetto, Technische Universität Darmstadt; David Gens and Michael Franz, University of California, Irvine; Ahmad-Reza Sadeghi, Technische Universität Darmstadt https://www.usenix.org/conference/usenixsecurity20/presentation/kenjar This paper is included in the Proceedings of the 29th USENIX Security Symposium. August 12–14, 2020 978-1-939133-17-5 Open access to the Proceedings of the 29th USENIX Security Symposium is sponsored by USENIX. V0LTpwn: Attacking x86 Processor Integrity from Software Zijo Kenjar1, Tommaso Frassetto1, David Gens2, Michael Franz2, and Ahmad-Reza Sadeghi1 1Technical University of Darmstadt, Germany {zijo.kenjar,tommaso.frassetto,ahmad.sadeghi}@trust.tu-darmstadt.de 2University of California, Irvine {dgens,franz}@uci.edu Abstract complex, and far from flawless. In the recent past, we Fault-injection attacks have been proven in the past to have seen how seemingly minor implementation bugs at be a reliable way of bypassing hardware-based security the hardware level can have a severe impact on secu- measures, such as cryptographic hashes, privilege and rity [14]. Attacks such as Meltdown [36], Spectre [33], access permission enforcement, and trusted execution Foreshadow [58], and RIDL [62] demonstrate that at- environments. However, traditional fault-injection at- tackers can exploit these bugs from software to bypass tacks require physical presence, and hence, were often access permissions and extract secret data. considered out of scope in many real-world adversary Furthermore, we have seen that the adverse effects settings. of hardware vulnerabilities are not limited to confiden- In this paper we show this assumption may no longer tiality, but can also compromise integrity in principle: be justified on x86. -

2.2 Adaptive Routing Algorithms and Router Design 20
https://theses.gla.ac.uk/ Theses Digitisation: https://www.gla.ac.uk/myglasgow/research/enlighten/theses/digitisation/ This is a digitised version of the original print thesis. Copyright and moral rights for this work are retained by the author A copy can be downloaded for personal non-commercial research or study, without prior permission or charge This work cannot be reproduced or quoted extensively from without first obtaining permission in writing from the author The content must not be changed in any way or sold commercially in any format or medium without the formal permission of the author When referring to this work, full bibliographic details including the author, title, awarding institution and date of the thesis must be given Enlighten: Theses https://theses.gla.ac.uk/ [email protected] Performance Evaluation of Distributed Crossbar Switch Hypermesh Sarnia Loucif Dissertation Submitted for the Degree of Doctor of Philosophy to the Faculty of Science, Glasgow University. ©Sarnia Loucif, May 1999. ProQuest Number: 10391444 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a com plete manuscript and there are missing pages, these will be noted. Also, if material had to be removed, a note will indicate the deletion. uest ProQuest 10391444 Published by ProQuest LLO (2017). Copyright of the Dissertation is held by the Author. All rights reserved. This work is protected against unauthorized copying under Title 17, United States C ode Microform Edition © ProQuest LLO. ProQuest LLO. -

Adaptive Parallelism for Coupled, Multithreaded Message-Passing Programs Samuel K
University of New Mexico UNM Digital Repository Computer Science ETDs Engineering ETDs Fall 12-1-2018 Adaptive Parallelism for Coupled, Multithreaded Message-Passing Programs Samuel K. Gutiérrez Follow this and additional works at: https://digitalrepository.unm.edu/cs_etds Part of the Numerical Analysis and Scientific omputC ing Commons, OS and Networks Commons, Software Engineering Commons, and the Systems Architecture Commons Recommended Citation Gutiérrez, Samuel K.. "Adaptive Parallelism for Coupled, Multithreaded Message-Passing Programs." (2018). https://digitalrepository.unm.edu/cs_etds/95 This Dissertation is brought to you for free and open access by the Engineering ETDs at UNM Digital Repository. It has been accepted for inclusion in Computer Science ETDs by an authorized administrator of UNM Digital Repository. For more information, please contact [email protected]. Samuel Keith Guti´errez Candidate Computer Science Department This dissertation is approved, and it is acceptable in quality and form for publication: Approved by the Dissertation Committee: Professor Dorian C. Arnold, Chair Professor Patrick G. Bridges Professor Darko Stefanovic Professor Alexander S. Aiken Patrick S. McCormick Adaptive Parallelism for Coupled, Multithreaded Message-Passing Programs by Samuel Keith Guti´errez B.S., Computer Science, New Mexico Highlands University, 2006 M.S., Computer Science, University of New Mexico, 2009 DISSERTATION Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy Computer Science The University of New Mexico Albuquerque, New Mexico December 2018 ii ©2018, Samuel Keith Guti´errez iii Dedication To my beloved family iv \A Dios rogando y con el martillo dando." Unknown v Acknowledgments Words cannot adequately express my feelings of gratitude for the people that made this possible. -

Detecting False Sharing Efficiently and Effectively
W&M ScholarWorks Arts & Sciences Articles Arts and Sciences 2016 Cheetah: Detecting False Sharing Efficiently andff E ectively Tongping Liu Univ Texas San Antonio, Dept Comp Sci, San Antonio, TX 78249 USA; Xu Liu Coll William & Mary, Dept Comp Sci, Williamsburg, VA 23185 USA Follow this and additional works at: https://scholarworks.wm.edu/aspubs Recommended Citation Liu, T., & Liu, X. (2016, March). Cheetah: Detecting false sharing efficiently and effectively. In 2016 IEEE/ ACM International Symposium on Code Generation and Optimization (CGO) (pp. 1-11). IEEE. This Article is brought to you for free and open access by the Arts and Sciences at W&M ScholarWorks. It has been accepted for inclusion in Arts & Sciences Articles by an authorized administrator of W&M ScholarWorks. For more information, please contact [email protected]. Cheetah: Detecting False Sharing Efficiently and Effectively Tongping Liu ∗ Xu Liu ∗ Department of Computer Science Department of Computer Science University of Texas at San Antonio College of William and Mary San Antonio, TX 78249 USA Williamsburg, VA 23185 USA [email protected] [email protected] Abstract 1. Introduction False sharing is a notorious performance problem that may Multicore processors are ubiquitous in the computing spec- occur in multithreaded programs when they are running on trum: from smart phones, personal desktops, to high-end ubiquitous multicore hardware. It can dramatically degrade servers. Multithreading is the de-facto programming model the performance by up to an order of magnitude, significantly to exploit the massive parallelism of modern multicore archi- hurting the scalability. Identifying false sharing in complex tectures. -

Moore's Law: the Future of Si Microelectronics
Moore’s law: the future of Si microelectronics Soon after Bardeen, Brattain, and Shockley invented a solid-state device in 19471 to replace electron vacuum tubes, the microelectronics industry and a revolution started. Since its birth, the industry has experienced four decades of unprecedented explosive growth driven by two factors: Noyce and Kilby inventing the planar integrated circuit2,3 and the advantageous characteristics that result from scaling (shrinking) solid-state devices. Scott E. Thompson and Srivatsan Parthasarathy SWAMP Center, Department of Electrical and Computer Engineering, University of Florida, Gainsville, FL 32611-6130 USA E-mail:[email protected], [email protected] Scaling solid-state devices has the peculiar property of improving approaches under investigation are: (1) nonclassical CMOS, which cost, performance, and power, which has historically given any consists of new channel materials and/or multigate fully depleted company with the latest technology a large competitive device structures; and (2) alternatives to CMOS, such as spintronics, advantage in the market. As a result, the microelectronics single electron devices, and molecular computing8,9. While some of industry has driven transistor feature size scaling from 10 µm to these non-Si research areas are important and will be successful in ~30 nm4-6 during the past 40 years. During most of this time, new applications and markets10, it seems unlikely any of the non-Si scaling simply consisted of reducing the feature size. However, options can replace the Si transistor for the $300 billion during certain periods, there were major changes as with the microelectronics industry in the foreseeable future (perhaps as long industry move from Si bipolar to p-channel metal-oxide- as 30 years). -

Multiprocessing Contents
Multiprocessing Contents 1 Multiprocessing 1 1.1 Pre-history .............................................. 1 1.2 Key topics ............................................... 1 1.2.1 Processor symmetry ...................................... 1 1.2.2 Instruction and data streams ................................. 1 1.2.3 Processor coupling ...................................... 2 1.2.4 Multiprocessor Communication Architecture ......................... 2 1.3 Flynn’s taxonomy ........................................... 2 1.3.1 SISD multiprocessing ..................................... 2 1.3.2 SIMD multiprocessing .................................... 2 1.3.3 MISD multiprocessing .................................... 3 1.3.4 MIMD multiprocessing .................................... 3 1.4 See also ................................................ 3 1.5 References ............................................... 3 2 Computer multitasking 5 2.1 Multiprogramming .......................................... 5 2.2 Cooperative multitasking ....................................... 6 2.3 Preemptive multitasking ....................................... 6 2.4 Real time ............................................... 7 2.5 Multithreading ............................................ 7 2.6 Memory protection .......................................... 7 2.7 Memory swapping .......................................... 7 2.8 Programming ............................................. 7 2.9 See also ................................................ 8 2.10 References .............................................