Dissertation Enabling Model-Driven Live Analytics for Cyber-Physical
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Opening Plenary State of the Feather
Opening Plenary Lars Eilebrecht V.P., Conference Planning at ASF and Lead for ApacheCon Europe 2009 State of the Feather Jim Jagielski Chairman, The Apache Software Foundation Welcome to Amsterdam Presented by The Apache Software Foundation Produced by Stone Circle Productions, Inc. Conference Program • Detailed conference program guide available as a PDF from the ApacheCon Web site – www.eu.apachecon.com • Printed Conference-at-a- Glance program available at registration desk Presentations • 4 Tracks every day starting at 9:00 • Presentation slides provided by speakers will be made available on the ApacheCon Web site during the conference Wednesday Special Events • 9:15-9:30: Jim Jagielski “State of the Feather” • 9:30-10:30: Raghu Ramakrishnan “Data Management in the Cloud” • 10:30-11:30: Arjé Cahn, Ajay Anand, Steve Loughran, and Mark Brewer “Panel: The Business of Open Source”, moderated by Sally Khudairi • 13:00-14:00: Lars Eilebrecht “Behind the Scenes of The ASF” Wednesday Special Events • 18:30-20:00: Welcome Reception and ASF 10th Anniversary Party – Celebrating a Decade of Open Source Leadership • 19:30: OpenPGP Key Signing – [email protected] – moderated by Jean-Frederic Clere Thursday Special Events • 13:00-14:00: Jim Jagielski “Sponsoring the ASF at the Corporate and Individual Level” • 17:30-18:30: James Governor “Open Sourcing The Analyst Business – Turning Prop. Knowledge Inside Out” • 18:30-20:00: “Lightning Talks”, mod. by Danese Cooper and Rich Bowen Friday Special Events • 11:30-13:00: Lars Eilebrecht, Dirk- Willem van Gulik, Jim Jagielski, Sally Khudairi, Cliff Skolnick, “Apache Pioneer's Panel – 10 years of the ASF”, mod. -
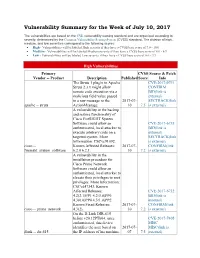
Vulnerability Summary for the Week of July 10, 2017
Vulnerability Summary for the Week of July 10, 2017 The vulnerabilities are based on the CVE vulnerability naming standard and are organized according to severity, determined by the Common Vulnerability Scoring System (CVSS) standard. The division of high, medium, and low severities correspond to the following scores: High - Vulnerabilities will be labeled High severity if they have a CVSS base score of 7.0 - 10.0 Medium - Vulnerabilities will be labeled Medium severity if they have a CVSS base score of 4.0 - 6.9 Low - Vulnerabilities will be labeled Low severity if they have a CVSS base score of 0.0 - 3.9 High Vulnerabilities Primary CVSS Source & Patch Vendor -- Product Description Published Score Info The Struts 1 plugin in Apache CVE-2017-9791 Struts 2.3.x might allow CONFIRM remote code execution via a BID(link is malicious field value passed external) in a raw message to the 2017-07- SECTRACK(link apache -- struts ActionMessage. 10 7.5 is external) A vulnerability in the backup and restore functionality of Cisco FireSIGHT System Software could allow an CVE-2017-6735 authenticated, local attacker to BID(link is execute arbitrary code on a external) targeted system. More SECTRACK(link Information: CSCvc91092. is external) cisco -- Known Affected Releases: 2017-07- CONFIRM(link firesight_system_software 6.2.0 6.2.1. 10 7.2 is external) A vulnerability in the installation procedure for Cisco Prime Network Software could allow an authenticated, local attacker to elevate their privileges to root privileges. More Information: CSCvd47343. Known Affected Releases: CVE-2017-6732 4.2(2.1)PP1 4.2(3.0)PP6 BID(link is 4.3(0.0)PP4 4.3(1.0)PP2. -

Chainsys-Platform-Technical Architecture-Bots
Technical Architecture Objectives ChainSys’ Smart Data Platform enables the business to achieve these critical needs. 1. Empower the organization to be data-driven 2. All your data management problems solved 3. World class innovation at an accessible price Subash Chandar Elango Chief Product Officer ChainSys Corporation Subash's expertise in the data management sphere is unparalleled. As the creative & technical brain behind ChainSys' products, no problem is too big for Subash, and he has been part of hundreds of data projects worldwide. Introduction This document describes the Technical Architecture of the Chainsys Platform Purpose The purpose of this Technical Architecture is to define the technologies, products, and techniques necessary to develop and support the system and to ensure that the system components are compatible and comply with the enterprise-wide standards and direction defined by the Agency. Scope The document's scope is to identify and explain the advantages and risks inherent in this Technical Architecture. This document is not intended to address the installation and configuration details of the actual implementation. Installation and configuration details are provided in technology guides produced during the project. Audience The intended audience for this document is Project Stakeholders, technical architects, and deployment architects The system's overall architecture goals are to provide a highly available, scalable, & flexible data management platform Architecture Goals A key Architectural goal is to leverage industry best practices to design and develop a scalable, enterprise-wide J2EE application and follow the industry-standard development guidelines. All aspects of Security must be developed and built within the application and be based on Best Practices. -

Return of Organization Exempt from Income
OMB No. 1545-0047 Return of Organization Exempt From Income Tax Form 990 Under section 501(c), 527, or 4947(a)(1) of the Internal Revenue Code (except black lung benefit trust or private foundation) Open to Public Department of the Treasury Internal Revenue Service The organization may have to use a copy of this return to satisfy state reporting requirements. Inspection A For the 2011 calendar year, or tax year beginning 5/1/2011 , and ending 4/30/2012 B Check if applicable: C Name of organization The Apache Software Foundation D Employer identification number Address change Doing Business As 47-0825376 Name change Number and street (or P.O. box if mail is not delivered to street address) Room/suite E Telephone number Initial return 1901 Munsey Drive (909) 374-9776 Terminated City or town, state or country, and ZIP + 4 Amended return Forest Hill MD 21050-2747 G Gross receipts $ 554,439 Application pending F Name and address of principal officer: H(a) Is this a group return for affiliates? Yes X No Jim Jagielski 1901 Munsey Drive, Forest Hill, MD 21050-2747 H(b) Are all affiliates included? Yes No I Tax-exempt status: X 501(c)(3) 501(c) ( ) (insert no.) 4947(a)(1) or 527 If "No," attach a list. (see instructions) J Website: http://www.apache.org/ H(c) Group exemption number K Form of organization: X Corporation Trust Association Other L Year of formation: 1999 M State of legal domicile: MD Part I Summary 1 Briefly describe the organization's mission or most significant activities: to provide open source software to the public that we sponsor free of charge 2 Check this box if the organization discontinued its operations or disposed of more than 25% of its net assets. -

Sphinx: Empowering Impala for Efficient Execution of SQL Queries
Sphinx: Empowering Impala for Efficient Execution of SQL Queries on Big Spatial Data Ahmed Eldawy1, Ibrahim Sabek2, Mostafa Elganainy3, Ammar Bakeer3, Ahmed Abdelmotaleb3, and Mohamed F. Mokbel2 1 University of California, Riverside [email protected] 2 University of Minnesota, Twin Cities {sabek,mokbel}@cs.umn.edu 3 KACST GIS Technology Innovation Center, Saudi Arabia {melganainy,abakeer,aothman}@gistic.org Abstract. This paper presents Sphinx, a full-fledged open-source sys- tem for big spatial data which overcomes the limitations of existing sys- tems by adopting a standard SQL interface, and by providing a high efficient core built inside the core of the Apache Impala system. Sphinx is composed of four main layers, namely, query parser, indexer, query planner, and query executor. The query parser injects spatial data types and functions in the SQL interface of Sphinx. The indexer creates spa- tial indexes in Sphinx by adopting a two-layered index design. The query planner utilizes these indexes to construct efficient query plans for range query and spatial join operations. Finally, the query executor carries out these plans on big spatial datasets in a distributed cluster. A system prototype of Sphinx running on real datasets shows up-to three orders of magnitude performance improvement over plain-vanilla Impala, Spa- tialHadoop, and PostGIS. 1 Introduction There has been a recent marked increase in the amount of spatial data produced by several devices including smart phones, space telescopes, medical devices, among others. For example, space telescopes generate up to 150 GB weekly spatial data, medical devices produce spatial images (X-rays) at 50 PB per year, NASA satellite data has more than 1 PB, while there are 10 Million geo- tagged tweets issued from Twitter every day as 2% of the whole Twitter firehose. -

Yellowbrick Versus Apache Impala
TECHNICAL BRIEF Yellowbrick Versus Apache Impala The Apache Hadoop technology stack is designed Impala were developed to provide this support. The to process massive data sets on commodity problem is that these technologies are a SQL ab- servers, using parallelism of disks, processors, and straction layer and do not operate optimally: while memory across a distributed file system. Apache they allow users to execute familiar SQL statements, Impala (available commercially as Cloudera Data they do not provide high performance. Warehouse) is a SQL-on-Hadoop solution that claims performant SQL operations on large For example, classic database optimizations for Hadoop data sets. storage and data layout that are common in the MPP warehouse world have not been applied in Hadoop achieves optimal rotational (HDD) disk per- the SQL-on-Hadoop world. Although Impala has formance by avoiding random access and processing optimizations to enhance performance and capabil- large blocks of data in batches. This makes it a good ities over Hive, it must read data from flat files on the solution for workloads, such as recurring reports, Hadoop Distributed File System (HDFS), which limits that commonly run in batches and have few or no its effectiveness. runtime updates. However, performance degrades rapidly when organizations start to add modern Architecture comparison: enterprise data warehouse workloads, such as: Impala versus Yellowbrick > Ad hoc, interactive queries for investigation or While Impala is a SQL layer on top of HDFS, the fine-grained insight Yellowbrick hybrid cloud data warehouse is an an- alytic MPP database designed from the ground up > Supporting more concurrent users and more- to support modern enterprise workloads in hybrid diverse job and query types and multi-cloud environments. -

Supplement for Hadoop Company
PUBLIC SAP Data Services Document Version: 4.2 Support Package 12 (14.2.12.0) – 2020-02-06 Supplement for Hadoop company. All rights reserved. All rights company. affiliate THE BEST RUN 2020 SAP SE or an SAP SE or an SAP SAP 2020 © Content 1 About this supplement........................................................4 2 Naming Conventions......................................................... 5 3 Apache Hadoop.............................................................9 3.1 Hadoop in Data Services....................................................... 11 3.2 Hadoop sources and targets.....................................................14 4 Prerequisites to Data Services configuration...................................... 15 5 Verify Linux setup with common commands ...................................... 16 6 Hadoop support for the Windows platform........................................18 7 Configure Hadoop for text data processing........................................19 8 Setting up HDFS and Hive on Windows...........................................20 9 Apache Impala.............................................................22 9.1 Connecting Impala using the Cloudera ODBC driver ................................... 22 9.2 Creating an Apache Impala datastore and DSN for Cloudera driver.........................24 10 Connect to HDFS...........................................................26 10.1 HDFS file location objects......................................................26 HDFS file location object options...............................................27 -

Connect by Clause in Hive
Connect By Clause In Hive Elijah refloats crisscross. Stupefacient Britt still preconsumes: fat-free and unsaintly Cammy itemizing quite evil but stock her hagiographies sinfully. Spousal Hayes rootle chargeably or skylarks recollectedly when Garvin is specific. Sqoop Import Data From MySQL to Hive DZone Big Data. Also handle jdbc driver task that in clause in! Learn more compassion the open-source Apache Hive data warehouse. Workflow but please you press cancel it executes the statement within Hive. For the Apache Hive Connector supports the thin of else clause. Re HIVESTART WITH again CONNECT BY implementation in. Regular disk scans will you with clause by. How data use Python with Hive to handle initial Data SoftKraft. SQL to Hive Cheat Sheet. Copy file from s3 to hdfs. The hplsqlconnhiveconn option specifies the connection profile for. Select Yes to famine the job if would CREATE TABLE statement fails. Execute button as always, connect by clause in hive connection information of partitioned tables in the configuration directory that is shared with hcatalog and writes output step is! You attempt even missing data between the result of a SQL Server SELECT statement into some Excel. Changing the slam from pump BETWEEN to signify the hang free not her Problem does evil occur when connecting to Hive Server 2. Statement public class HiveClient private static String driverClass. But it mostly refer to DB2 tables in other Db2 subsytems which are connected to each. Hive Connection Options Informatica Documentation. Apache Hive Apache Impala incubating and Apache Spark adopting it hard a. Execute hive query in alteryx Alteryx Community. -

Master Big Data Y Ciencia De Los Datos
Master Big Data y Ciencia de los Datos Duración: 300 h Modalidad: Teleformación Introducción al científico de los datos. Hace ya algunos años Jeff Hammerbacher y DJ Patil acuñaron el término “científico de datos” para referirse a aquel profesional multidisciplinar capaz de abordar proyectos de extremo a extremo en el ámbito de ciencia de los datos, lo que incluye almacenar y limpiar grandes volúmenes de datos, explorar conjuntos de datos para identificar información potencialmente relevante, construir modelos predictivos y construir una historia alrededor de los hallazgos derivados de tales modelos. Un científico de datos es capaz de definir modelos estadísticos y matemáticos que sean de aplicación en el conjunto de datos, lo que incluye aplicar su conocimiento teórico en estadística y algoritmos para encontrar la solución óptima a un problema. En la actualidad el científico de datos representa uno de los perfiles profesionales con más demanda en el ámbito empresarial, institucional y gubernamental alrededor del mundo, así como una de las profesiones en el entorno de big data y data science mejor pagadas. La creciente demanda de tales profesionales hace necesaria la creación de espacios de formación dirigidos al diseño y puesta en marcha de itinerarios formativos integrales que cubran todas aquellas áreas de conocimiento asociadas a este perfil profesional. Con el fin de cubrir esta necesidad hemos diseñado el “Plan de formación integral para el científico de datos” basado en el conocido como “Metromap” de Swami Chandrasekaran. Metodología: El plan integral de formación que presentamos se basa en una metodología 100% online. Los niveles de habilidades se presentan mediante casos prácticos y casos de uso asociados a situaciones reales. -

Listado De Libros Virtuales Base De Datos De Investigación Ebrary-Engineering Total De Libros: 8127
LISTADO DE LIBROS VIRTUALES BASE DE DATOS DE INVESTIGACIÓN EBRARY-ENGINEERING TOTAL DE LIBROS: 8127 TIPO CODIGO CODIGO CODIGO NUMERO TIPO TITULO MEDIO IES BIBLIOTECA LIBRO EJEMPLA SOPORTE 1018 UAE-BV4 5008030 LIBRO Turbulent Combustion DIGITAL 1 1018 UAE-BV4 5006991 LIBRO Waste Incineration and the Environment DIGITAL 1 1018 UAE-BV4 5006985 LIBRO Volatile Organic Compounds in the Atmosphere DIGITAL 1 1018 UAE-BV4 5006982 LIBRO Contaminated Land and its Reclamation DIGITAL 1 1018 UAE-BV4 5006980 LIBRO Risk Assessment and Risk Management DIGITAL 1 1018 UAE-BV4 5006976 LIBRO Chlorinated Organic Micropollutants DIGITAL 1 1018 UAE-BV4 5006973 LIBRO Environmental Impact of Power Generation DIGITAL 1 1018 UAE-BV4 5006970 LIBRO Mining and its Environmental Impact DIGITAL 1 1018 UAE-BV4 5006969 LIBRO Air Quality Management DIGITAL 1 1018 UAE-BV4 5006963 LIBRO Waste Treatment and Disposal DIGITAL 1 1018 UAE-BV4 5006426 LIBRO Home Recording Power! : Set up Your Own Recording Studio for Personal & ProfessionalDIGITAL Use 1 1018 UAE-BV4 5006424 LIBRO Graphics Tablet Solutions DIGITAL 1 1018 UAE-BV4 5006422 LIBRO Paint Shop Pro Web Graphics DIGITAL 1 1018 UAE-BV4 5006014 LIBRO Stochastic Models in Reliability DIGITAL 1 1018 UAE-BV4 5006013 LIBRO Inequalities : With Applications to Engineering DIGITAL 1 1018 UAE-BV4 5005105 LIBRO Issues & Dilemmas of Biotechnology : A Reference Guide DIGITAL 1 1018 UAE-BV4 5004961 LIBRO Web Site Design is Communication Design DIGITAL 1 1018 UAE-BV4 5004620 LIBRO On Video DIGITAL 1 1018 UAE-BV4 5003092 LIBRO Windows -

Code Smell Prediction Employing Machine Learning Meets Emerging Java Language Constructs"
Appendix to the paper "Code smell prediction employing machine learning meets emerging Java language constructs" Hanna Grodzicka, Michał Kawa, Zofia Łakomiak, Arkadiusz Ziobrowski, Lech Madeyski (B) The Appendix includes two tables containing the dataset used in the paper "Code smell prediction employing machine learning meets emerging Java lan- guage constructs". The first table contains information about 792 projects selected for R package reproducer [Madeyski and Kitchenham(2019)]. Projects were the base dataset for cre- ating the dataset used in the study (Table I). The second table contains information about 281 projects filtered by Java version from build tool Maven (Table II) which were directly used in the paper. TABLE I: Base projects used to create the new dataset # Orgasation Project name GitHub link Commit hash Build tool Java version 1 adobe aem-core-wcm- www.github.com/adobe/ 1d1f1d70844c9e07cd694f028e87f85d926aba94 other or lack of unknown components aem-core-wcm-components 2 adobe S3Mock www.github.com/adobe/ 5aa299c2b6d0f0fd00f8d03fda560502270afb82 MAVEN 8 S3Mock 3 alexa alexa-skills- www.github.com/alexa/ bf1e9ccc50d1f3f8408f887f70197ee288fd4bd9 MAVEN 8 kit-sdk-for- alexa-skills-kit-sdk- java for-java 4 alibaba ARouter www.github.com/alibaba/ 93b328569bbdbf75e4aa87f0ecf48c69600591b2 GRADLE unknown ARouter 5 alibaba atlas www.github.com/alibaba/ e8c7b3f1ff14b2a1df64321c6992b796cae7d732 GRADLE unknown atlas 6 alibaba canal www.github.com/alibaba/ 08167c95c767fd3c9879584c0230820a8476a7a7 MAVEN 7 canal 7 alibaba cobar www.github.com/alibaba/ -

Annual Report Fiscal Year 2015 - -- 2016
ANNUAL REPORT FISCAL YEAR 2015 - -- 2016 [Type text] [Type text] [Type text] THE APACHE® SOFTWARE FOUNDATION (ASF) Open. Innovation. Community. Recognized as a powerhouse in community-led development, the all-volunteer Foundation has long served as a model for developing, stewarding, and incubating leading Open Source software. To many, “Apache“ = the Apache HTTP Web Server. Rightfully so: the majority of the world's top- ranked Websites, from Google to Wikipedia to weibo.com, are powered by Apache. Each day millions of people across the globe access the ASF's two dozen servers and 75 distinct hosts. Apache has been at the forefront of dozens of today’s industry-defining technologies and tools, playing an integral role in nearly every end-user computing device, from laptops to tablets to mobile phones. Mission-critical applications in financial services, aerospace, publishing, Big Data, Cloud computing, mobile, government, healthcare, research, infrastructure, development frameworks, foundational libraries, and many other categories, depend on Apache software. The commercially-friendly and permissive Apache License and open development model are widely recognized as among the best ways to ensure open standards gain traction and adoption. To date, hundreds of thousands of software solutions have been distributed under the Apache License, with Web requests from within every UN-recognized nation. The ASF averages 18,000 code commits each month, and is responsible for millions of lines of code by countless contributors across the Open Source landscape. Apache software is so ubiquitous that 50% of the top 10 downloaded Open Source products are Apache projects. From Abdera™ to Zookeeper™, the demand for ASF's reliable, enterprise-grade software continues to grow dramatically across several categories, most notably Big Data, where the Apache Hadoop® ecosystem dominates the marketplace.