Best Practices for Big Data : Visualizing Billions of Rows with Rapid Response Times “Big Data Analytics at the Speed of Thought”
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Java Linksammlung
JAVA LINKSAMMLUNG LerneProgrammieren.de - 2020 Java einfach lernen (klicke hier) JAVA LINKSAMMLUNG INHALTSVERZEICHNIS Build ........................................................................................................................................................... 4 Caching ....................................................................................................................................................... 4 CLI ............................................................................................................................................................... 4 Cluster-Verwaltung .................................................................................................................................... 5 Code-Analyse ............................................................................................................................................. 5 Code-Generators ........................................................................................................................................ 5 Compiler ..................................................................................................................................................... 6 Konfiguration ............................................................................................................................................. 6 CSV ............................................................................................................................................................. 6 Daten-Strukturen -

Declarative Languages for Big Streaming Data a Database Perspective
Tutorial Declarative Languages for Big Streaming Data A database Perspective Riccardo Tommasini Sherif Sakr University of Tartu Unversity of Tartu [email protected] [email protected] Emanuele Della Valle Hojjat Jafarpour Politecnico di Milano Confluent Inc. [email protected] [email protected] ABSTRACT sources and are pushed asynchronously to servers which are The Big Data movement proposes data streaming systems to responsible for processing them [13]. tame velocity and to enable reactive decision making. However, To facilitate the adoption, initially, most of the big stream approaching such systems is still too complex due to the paradigm processing systems provided their users with a set of API for shift they require, i.e., moving from scalable batch processing to implementing their applications. However, recently, the need for continuous data analysis and pattern detection. declarative stream processing languages has emerged to simplify Recently, declarative Languages are playing a crucial role in common coding tasks; making code more readable and main- fostering the adoption of Stream Processing solutions. In partic- tainable, and fostering the development of more complex appli- ular, several key players introduce SQL extensions for stream cations. Thus, Big Data frameworks (e.g., Flink [9], Spark [3], 1 processing. These new languages are currently playing a cen- Kafka Streams , and Storm [19]) are starting to develop their 2 3 4 tral role in fostering the stream processing paradigm shift. In own SQL-like approaches (e.g., Flink SQL , Beam SQL , KSQL ) this tutorial, we give an overview of the various languages for to declaratively tame data velocity. declarative querying interfaces big streaming data. -

Apache Apex: Next Gen Big Data Analytics
Apache Apex: Next Gen Big Data Analytics Thomas Weise <[email protected]> @thweise PMC Chair Apache Apex, Architect DataTorrent Apache Big Data Europe, Sevilla, Nov 14th 2016 Stream Data Processing Data Delivery Transform / Analytics Real-time visualization, … Declarative SQL API Data Beam Beam SAMOA Operator SAMOA DAG API Sources Library Events Logs Oper1 Oper2 Oper3 Sensor Data Social Databases CDC (roadmap) 2 Industries & Use Cases Financial Services Ad-Tech Telecom Manufacturing Energy IoT Real-time Call detail record customer facing (CDR) & Supply chain Fraud and risk Smart meter Data ingestion dashboards on extended data planning & monitoring analytics and processing key performance record (XDR) optimization indicators analysis Understanding Reduce outages Credit risk Click fraud customer Preventive & improve Predictive assessment detection behavior AND maintenance resource analytics context utilization Packaging and Improve turn around Asset & Billing selling Product quality & time of trade workforce Data governance optimization anonymous defect tracking settlement processes management customer data HORIZONTAL • Large scale ingest and distribution • Enforcing data quality and data governance requirements • Real-time ELTA (Extract Load Transform Analyze) • Real-time data enrichment with reference data • Dimensional computation & aggregation • Real-time machine learning model scoring 3 Apache Apex • In-memory, distributed stream processing • Application logic broken into components (operators) that execute distributed in a cluster • -
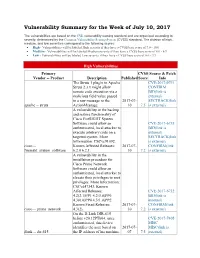
Vulnerability Summary for the Week of July 10, 2017
Vulnerability Summary for the Week of July 10, 2017 The vulnerabilities are based on the CVE vulnerability naming standard and are organized according to severity, determined by the Common Vulnerability Scoring System (CVSS) standard. The division of high, medium, and low severities correspond to the following scores: High - Vulnerabilities will be labeled High severity if they have a CVSS base score of 7.0 - 10.0 Medium - Vulnerabilities will be labeled Medium severity if they have a CVSS base score of 4.0 - 6.9 Low - Vulnerabilities will be labeled Low severity if they have a CVSS base score of 0.0 - 3.9 High Vulnerabilities Primary CVSS Source & Patch Vendor -- Product Description Published Score Info The Struts 1 plugin in Apache CVE-2017-9791 Struts 2.3.x might allow CONFIRM remote code execution via a BID(link is malicious field value passed external) in a raw message to the 2017-07- SECTRACK(link apache -- struts ActionMessage. 10 7.5 is external) A vulnerability in the backup and restore functionality of Cisco FireSIGHT System Software could allow an CVE-2017-6735 authenticated, local attacker to BID(link is execute arbitrary code on a external) targeted system. More SECTRACK(link Information: CSCvc91092. is external) cisco -- Known Affected Releases: 2017-07- CONFIRM(link firesight_system_software 6.2.0 6.2.1. 10 7.2 is external) A vulnerability in the installation procedure for Cisco Prime Network Software could allow an authenticated, local attacker to elevate their privileges to root privileges. More Information: CSCvd47343. Known Affected Releases: CVE-2017-6732 4.2(2.1)PP1 4.2(3.0)PP6 BID(link is 4.3(0.0)PP4 4.3(1.0)PP2. -

Chainsys-Platform-Technical Architecture-Bots
Technical Architecture Objectives ChainSys’ Smart Data Platform enables the business to achieve these critical needs. 1. Empower the organization to be data-driven 2. All your data management problems solved 3. World class innovation at an accessible price Subash Chandar Elango Chief Product Officer ChainSys Corporation Subash's expertise in the data management sphere is unparalleled. As the creative & technical brain behind ChainSys' products, no problem is too big for Subash, and he has been part of hundreds of data projects worldwide. Introduction This document describes the Technical Architecture of the Chainsys Platform Purpose The purpose of this Technical Architecture is to define the technologies, products, and techniques necessary to develop and support the system and to ensure that the system components are compatible and comply with the enterprise-wide standards and direction defined by the Agency. Scope The document's scope is to identify and explain the advantages and risks inherent in this Technical Architecture. This document is not intended to address the installation and configuration details of the actual implementation. Installation and configuration details are provided in technology guides produced during the project. Audience The intended audience for this document is Project Stakeholders, technical architects, and deployment architects The system's overall architecture goals are to provide a highly available, scalable, & flexible data management platform Architecture Goals A key Architectural goal is to leverage industry best practices to design and develop a scalable, enterprise-wide J2EE application and follow the industry-standard development guidelines. All aspects of Security must be developed and built within the application and be based on Best Practices. -

Informatica 10.2 Hotfix 2 Release Notes April 2019
Informatica 10.2 HotFix 2 Release Notes April 2019 © Copyright Informatica LLC 1998, 2020 Contents Installation and Upgrade......................................................................... 3 Informatica Upgrade Paths......................................................... 3 Upgrading from 9.6.1............................................................. 4 Upgrading from Version 10.0, 10.1, 10.1.1, and 10.1.1 HotFix 1.............................. 4 Upgrading from Version 10.1.1 HF2.................................................. 5 Upgrading from 10.2.............................................................. 6 Related Links ................................................................... 7 Verify the Hadoop Distribution Support................................................ 7 Hotfix Installation and Rollback..................................................... 8 10.2 HotFix 2 Fixed Limitations and Closed Enhancements........................................ 17 Analyst Tool Fixed Limitations and Closed Enhancements (10.2 HotFix 2).................... 17 Application Service Fixed Limitations and Closed Enhancements (10.2 HotFix 2)............... 17 Command Line Programs Fixed Limitations and Closed Enhancements (10.2 HotFix 2).......... 17 Developer Tool Fixed Limitations and Closed Enhancements (10.2 HotFix 2).................. 18 Informatica Connector Toolkit Fixed Limitations and Closed Enhancements (10.2 HotFix 2) ...... 18 Mappings and Workflows Fixed Limitations (10.2 HotFix 2)............................... 18 Metadata -

Sphinx: Empowering Impala for Efficient Execution of SQL Queries
Sphinx: Empowering Impala for Efficient Execution of SQL Queries on Big Spatial Data Ahmed Eldawy1, Ibrahim Sabek2, Mostafa Elganainy3, Ammar Bakeer3, Ahmed Abdelmotaleb3, and Mohamed F. Mokbel2 1 University of California, Riverside [email protected] 2 University of Minnesota, Twin Cities {sabek,mokbel}@cs.umn.edu 3 KACST GIS Technology Innovation Center, Saudi Arabia {melganainy,abakeer,aothman}@gistic.org Abstract. This paper presents Sphinx, a full-fledged open-source sys- tem for big spatial data which overcomes the limitations of existing sys- tems by adopting a standard SQL interface, and by providing a high efficient core built inside the core of the Apache Impala system. Sphinx is composed of four main layers, namely, query parser, indexer, query planner, and query executor. The query parser injects spatial data types and functions in the SQL interface of Sphinx. The indexer creates spa- tial indexes in Sphinx by adopting a two-layered index design. The query planner utilizes these indexes to construct efficient query plans for range query and spatial join operations. Finally, the query executor carries out these plans on big spatial datasets in a distributed cluster. A system prototype of Sphinx running on real datasets shows up-to three orders of magnitude performance improvement over plain-vanilla Impala, Spa- tialHadoop, and PostGIS. 1 Introduction There has been a recent marked increase in the amount of spatial data produced by several devices including smart phones, space telescopes, medical devices, among others. For example, space telescopes generate up to 150 GB weekly spatial data, medical devices produce spatial images (X-rays) at 50 PB per year, NASA satellite data has more than 1 PB, while there are 10 Million geo- tagged tweets issued from Twitter every day as 2% of the whole Twitter firehose. -

HDP 3.1.4 Release Notes Date of Publish: 2019-08-26
Release Notes 3 HDP 3.1.4 Release Notes Date of Publish: 2019-08-26 https://docs.hortonworks.com Release Notes | Contents | ii Contents HDP 3.1.4 Release Notes..........................................................................................4 Component Versions.................................................................................................4 Descriptions of New Features..................................................................................5 Deprecation Notices.................................................................................................. 6 Terminology.......................................................................................................................................................... 6 Removed Components and Product Capabilities.................................................................................................6 Testing Unsupported Features................................................................................ 6 Descriptions of the Latest Technical Preview Features.......................................................................................7 Upgrading to HDP 3.1.4...........................................................................................7 Behavioral Changes.................................................................................................. 7 Apache Patch Information.....................................................................................11 Accumulo........................................................................................................................................................... -

Apache Calcite: a Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources
Apache Calcite: A Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources Edmon Begoli Jesús Camacho-Rodríguez Julian Hyde Oak Ridge National Laboratory Hortonworks Inc. Hortonworks Inc. (ORNL) Santa Clara, California, USA Santa Clara, California, USA Oak Ridge, Tennessee, USA [email protected] [email protected] [email protected] Michael J. Mior Daniel Lemire David R. Cheriton School of University of Quebec (TELUQ) Computer Science Montreal, Quebec, Canada University of Waterloo [email protected] Waterloo, Ontario, Canada [email protected] ABSTRACT argued that specialized engines can offer more cost-effective per- Apache Calcite is a foundational software framework that provides formance and that they would bring the end of the “one size fits query processing, optimization, and query language support to all” paradigm. Their vision seems today more relevant than ever. many popular open-source data processing systems such as Apache Indeed, many specialized open-source data systems have since be- Hive, Apache Storm, Apache Flink, Druid, and MapD. Calcite’s ar- come popular such as Storm [50] and Flink [16] (stream processing), chitecture consists of a modular and extensible query optimizer Elasticsearch [15] (text search), Apache Spark [47], Druid [14], etc. with hundreds of built-in optimization rules, a query processor As organizations have invested in data processing systems tai- capable of processing a variety of query languages, an adapter ar- lored towards their specific needs, two overarching problems have chitecture designed for extensibility, and support for heterogeneous arisen: data models and stores (relational, semi-structured, streaming, and • The developers of such specialized systems have encoun- geospatial). This flexible, embeddable, and extensible architecture tered related problems, such as query optimization [4, 25] is what makes Calcite an attractive choice for adoption in big- or the need to support query languages such as SQL and data frameworks. -

Yellowbrick Versus Apache Impala
TECHNICAL BRIEF Yellowbrick Versus Apache Impala The Apache Hadoop technology stack is designed Impala were developed to provide this support. The to process massive data sets on commodity problem is that these technologies are a SQL ab- servers, using parallelism of disks, processors, and straction layer and do not operate optimally: while memory across a distributed file system. Apache they allow users to execute familiar SQL statements, Impala (available commercially as Cloudera Data they do not provide high performance. Warehouse) is a SQL-on-Hadoop solution that claims performant SQL operations on large For example, classic database optimizations for Hadoop data sets. storage and data layout that are common in the MPP warehouse world have not been applied in Hadoop achieves optimal rotational (HDD) disk per- the SQL-on-Hadoop world. Although Impala has formance by avoiding random access and processing optimizations to enhance performance and capabil- large blocks of data in batches. This makes it a good ities over Hive, it must read data from flat files on the solution for workloads, such as recurring reports, Hadoop Distributed File System (HDFS), which limits that commonly run in batches and have few or no its effectiveness. runtime updates. However, performance degrades rapidly when organizations start to add modern Architecture comparison: enterprise data warehouse workloads, such as: Impala versus Yellowbrick > Ad hoc, interactive queries for investigation or While Impala is a SQL layer on top of HDFS, the fine-grained insight Yellowbrick hybrid cloud data warehouse is an an- alytic MPP database designed from the ground up > Supporting more concurrent users and more- to support modern enterprise workloads in hybrid diverse job and query types and multi-cloud environments. -

Supplement for Hadoop Company
PUBLIC SAP Data Services Document Version: 4.2 Support Package 12 (14.2.12.0) – 2020-02-06 Supplement for Hadoop company. All rights reserved. All rights company. affiliate THE BEST RUN 2020 SAP SE or an SAP SE or an SAP SAP 2020 © Content 1 About this supplement........................................................4 2 Naming Conventions......................................................... 5 3 Apache Hadoop.............................................................9 3.1 Hadoop in Data Services....................................................... 11 3.2 Hadoop sources and targets.....................................................14 4 Prerequisites to Data Services configuration...................................... 15 5 Verify Linux setup with common commands ...................................... 16 6 Hadoop support for the Windows platform........................................18 7 Configure Hadoop for text data processing........................................19 8 Setting up HDFS and Hive on Windows...........................................20 9 Apache Impala.............................................................22 9.1 Connecting Impala using the Cloudera ODBC driver ................................... 22 9.2 Creating an Apache Impala datastore and DSN for Cloudera driver.........................24 10 Connect to HDFS...........................................................26 10.1 HDFS file location objects......................................................26 HDFS file location object options...............................................27 -

Hortonworks Data Platform for Enterprise Data Lakes Delivers Robust, Big Data Analytics That Accelerate Decision Making and Innovation
IBM Europe Software Announcement ZP18-0220, dated March 20, 2018 Hortonworks Data Platform for Enterprise Data Lakes delivers robust, big data analytics that accelerate decision making and innovation Table of contents 1 Overview 5 Technical information 2 Key prerequisites 6 Ordering information 2 Planned availability date 7 Terms and conditions 2 Description 9 Prices 5 Program number 10 Announcement countries 5 Publications 10 Corrections Overview Hortonworks Data Platform is an enterprise ready open source Apache Hadoop distribution based on a centralized architecture supported by YARN. Hortonworks Data Platform is designed to address the needs of data at rest, power real-time customer applications, and deliver big data analytics that can help accelerate decision making and innovation. The official Apache versions for Hortonworks Data Platform V2.6.4 include: • Apache Accumulo 1.7.0 • Apache Atlas 0.8.0 • Apache Calcite 1.2.0 • Apache DataFu 1.3.0 • Apache Falcon 0.10.0 • Apache Flume 1.5.2 • Apache Hadoop 2.7.3 • Apache HBase 1.1.2 • Apache Hive 1.2.1 • Apache Hive 2.1.0 • Apache Kafka 0.10.1 • Apache Knox 0.12.0 • Apache Mahout 0.9.0 • Apache Oozie 4.2.0 • Apache Phoenix 4.7.0 • Apache Pig 0.16.0 • Apache Ranger 0.7.0 • Apache Slider 0.92.0 • Apache Spark 1.6.3 • Apache Spark 2.2.0 • Apache Sqoop 1.4.6 • Apache Storm 1.1.0 • Apache TEZ 0.7.0 • Apache Zeppelin 0.7.3 IBM Europe Software Announcement ZP18-0220 IBM is a registered trademark of International Business Machines Corporation 1 • Apache ZooKeeper 3.4.6 IBM(R) clients can download this new offering from Passport Advantage(R).