Chainsys-Platform-Technical Architecture-Bots
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Oracle Metadata Management V12.2.1.3.0 New Features Overview
An Oracle White Paper October 12 th , 2018 Oracle Metadata Management v12.2.1.3.0 New Features Overview Oracle Metadata Management version 12.2.1.3.0 – October 12 th , 2018 New Features Overview Disclaimer This document is for informational purposes. It is not a commitment to deliver any material, code, or functionality, and should not be relied upon in making purchasing decisions. The development, release, and timing of any features or functionality described in this document remains at the sole discretion of Oracle. This document in any form, software or printed matter, contains proprietary information that is the exclusive property of Oracle. This document and information contained herein may not be disclosed, copied, reproduced, or distributed to anyone outside Oracle without prior written consent of Oracle. This document is not part of your license agreement nor can it be incorporated into any contractual agreement with Oracle or its subsidiaries or affiliates. 1 Oracle Metadata Management version 12.2.1.3.0 – October 12 th , 2018 New Features Overview Table of Contents Executive Overview ............................................................................ 3 Oracle Metadata Management 12.2.1.3.0 .......................................... 4 METADATA MANAGER VS METADATA EXPLORER UI .............. 4 METADATA HOME PAGES ........................................................... 5 METADATA QUICK ACCESS ........................................................ 6 METADATA REPORTING ............................................................. -

Apache Log4j 2 V
...................................................................................................................................... Apache Log4j 2 v. 2.4.1 User's Guide ...................................................................................................................................... The Apache Software Foundation 2015-10-08 T a b l e o f C o n t e n t s i Table of Contents ....................................................................................................................................... 1. Table of Contents . i 2. Introduction . 1 3. Architecture . 3 4. Log4j 1.x Migration . 10 5. API . 16 6. Configuration . 19 7. Web Applications and JSPs . 50 8. Plugins . 58 9. Lookups . 62 10. Appenders . 70 11. Layouts . 128 12. Filters . 154 13. Async Loggers . 167 14. JMX . 181 15. Logging Separation . 188 16. Extending Log4j . 190 17. Programmatic Log4j Configuration . 198 18. Custom Log Levels . 204 © 2 0 1 5 , T h e A p a c h e S o f t w a r e F o u n d a t i o n • A L L R I G H T S R E S E R V E D . T a b l e o f C o n t e n t s ii © 2 0 1 5 , T h e A p a c h e S o f t w a r e F o u n d a t i o n • A L L R I G H T S R E S E R V E D . 1 I n t r o d u c t i o n 1 1 Introduction ....................................................................................................................................... 1.1 Welcome to Log4j 2! 1.1.1 Introduction Almost every large application includes its own logging or tracing API. In conformance with this rule, the E.U. -
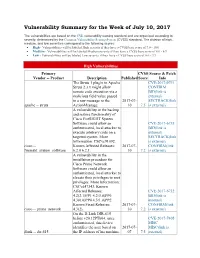
Vulnerability Summary for the Week of July 10, 2017
Vulnerability Summary for the Week of July 10, 2017 The vulnerabilities are based on the CVE vulnerability naming standard and are organized according to severity, determined by the Common Vulnerability Scoring System (CVSS) standard. The division of high, medium, and low severities correspond to the following scores: High - Vulnerabilities will be labeled High severity if they have a CVSS base score of 7.0 - 10.0 Medium - Vulnerabilities will be labeled Medium severity if they have a CVSS base score of 4.0 - 6.9 Low - Vulnerabilities will be labeled Low severity if they have a CVSS base score of 0.0 - 3.9 High Vulnerabilities Primary CVSS Source & Patch Vendor -- Product Description Published Score Info The Struts 1 plugin in Apache CVE-2017-9791 Struts 2.3.x might allow CONFIRM remote code execution via a BID(link is malicious field value passed external) in a raw message to the 2017-07- SECTRACK(link apache -- struts ActionMessage. 10 7.5 is external) A vulnerability in the backup and restore functionality of Cisco FireSIGHT System Software could allow an CVE-2017-6735 authenticated, local attacker to BID(link is execute arbitrary code on a external) targeted system. More SECTRACK(link Information: CSCvc91092. is external) cisco -- Known Affected Releases: 2017-07- CONFIRM(link firesight_system_software 6.2.0 6.2.1. 10 7.2 is external) A vulnerability in the installation procedure for Cisco Prime Network Software could allow an authenticated, local attacker to elevate their privileges to root privileges. More Information: CSCvd47343. Known Affected Releases: CVE-2017-6732 4.2(2.1)PP1 4.2(3.0)PP6 BID(link is 4.3(0.0)PP4 4.3(1.0)PP2. -

Sphinx: Empowering Impala for Efficient Execution of SQL Queries
Sphinx: Empowering Impala for Efficient Execution of SQL Queries on Big Spatial Data Ahmed Eldawy1, Ibrahim Sabek2, Mostafa Elganainy3, Ammar Bakeer3, Ahmed Abdelmotaleb3, and Mohamed F. Mokbel2 1 University of California, Riverside [email protected] 2 University of Minnesota, Twin Cities {sabek,mokbel}@cs.umn.edu 3 KACST GIS Technology Innovation Center, Saudi Arabia {melganainy,abakeer,aothman}@gistic.org Abstract. This paper presents Sphinx, a full-fledged open-source sys- tem for big spatial data which overcomes the limitations of existing sys- tems by adopting a standard SQL interface, and by providing a high efficient core built inside the core of the Apache Impala system. Sphinx is composed of four main layers, namely, query parser, indexer, query planner, and query executor. The query parser injects spatial data types and functions in the SQL interface of Sphinx. The indexer creates spa- tial indexes in Sphinx by adopting a two-layered index design. The query planner utilizes these indexes to construct efficient query plans for range query and spatial join operations. Finally, the query executor carries out these plans on big spatial datasets in a distributed cluster. A system prototype of Sphinx running on real datasets shows up-to three orders of magnitude performance improvement over plain-vanilla Impala, Spa- tialHadoop, and PostGIS. 1 Introduction There has been a recent marked increase in the amount of spatial data produced by several devices including smart phones, space telescopes, medical devices, among others. For example, space telescopes generate up to 150 GB weekly spatial data, medical devices produce spatial images (X-rays) at 50 PB per year, NASA satellite data has more than 1 PB, while there are 10 Million geo- tagged tweets issued from Twitter every day as 2% of the whole Twitter firehose. -

Yellowbrick Versus Apache Impala
TECHNICAL BRIEF Yellowbrick Versus Apache Impala The Apache Hadoop technology stack is designed Impala were developed to provide this support. The to process massive data sets on commodity problem is that these technologies are a SQL ab- servers, using parallelism of disks, processors, and straction layer and do not operate optimally: while memory across a distributed file system. Apache they allow users to execute familiar SQL statements, Impala (available commercially as Cloudera Data they do not provide high performance. Warehouse) is a SQL-on-Hadoop solution that claims performant SQL operations on large For example, classic database optimizations for Hadoop data sets. storage and data layout that are common in the MPP warehouse world have not been applied in Hadoop achieves optimal rotational (HDD) disk per- the SQL-on-Hadoop world. Although Impala has formance by avoiding random access and processing optimizations to enhance performance and capabil- large blocks of data in batches. This makes it a good ities over Hive, it must read data from flat files on the solution for workloads, such as recurring reports, Hadoop Distributed File System (HDFS), which limits that commonly run in batches and have few or no its effectiveness. runtime updates. However, performance degrades rapidly when organizations start to add modern Architecture comparison: enterprise data warehouse workloads, such as: Impala versus Yellowbrick > Ad hoc, interactive queries for investigation or While Impala is a SQL layer on top of HDFS, the fine-grained insight Yellowbrick hybrid cloud data warehouse is an an- alytic MPP database designed from the ground up > Supporting more concurrent users and more- to support modern enterprise workloads in hybrid diverse job and query types and multi-cloud environments. -

Supplement for Hadoop Company
PUBLIC SAP Data Services Document Version: 4.2 Support Package 12 (14.2.12.0) – 2020-02-06 Supplement for Hadoop company. All rights reserved. All rights company. affiliate THE BEST RUN 2020 SAP SE or an SAP SE or an SAP SAP 2020 © Content 1 About this supplement........................................................4 2 Naming Conventions......................................................... 5 3 Apache Hadoop.............................................................9 3.1 Hadoop in Data Services....................................................... 11 3.2 Hadoop sources and targets.....................................................14 4 Prerequisites to Data Services configuration...................................... 15 5 Verify Linux setup with common commands ...................................... 16 6 Hadoop support for the Windows platform........................................18 7 Configure Hadoop for text data processing........................................19 8 Setting up HDFS and Hive on Windows...........................................20 9 Apache Impala.............................................................22 9.1 Connecting Impala using the Cloudera ODBC driver ................................... 22 9.2 Creating an Apache Impala datastore and DSN for Cloudera driver.........................24 10 Connect to HDFS...........................................................26 10.1 HDFS file location objects......................................................26 HDFS file location object options...............................................27 -

D3.2 - Transport and Spatial Data Warehouse
Holistic Approach for Providing Spatial & Transport Planning Tools and Evidence to Metropolitan and Regional Authorities to Lead a Sustainable Transition to a New Mobility Era D3.2 - Transport and Spatial Data Warehouse Technical Design @Harmony_H2020 #harmony-h2020 D3.2 - Transport and SpatialData Warehouse Technical Design SUMMARY SHEET PROJECT Project Acronym: HARMONY Project Full Title: Holistic Approach for Providing Spatial & Transport Planning Tools and Evidence to Metropolitan and Regional Authorities to Lead a Sustainable Transition to a New Mobility Era Grant Agreement No. 815269 (H2020 – LC-MG-1-2-2018) Project Coordinator: University College London (UCL) Website www.harmony-h2020.eu Starting date June 2019 Duration 42 months DELIVERABLE Deliverable No. - Title D3.2 - Transport and Spatial Data Warehouse Technical Design Dissemination level: Public Deliverable type: Demonstrator Work Package No. & Title: WP3 - Data collection tools, data fusion and warehousing Deliverable Leader: ICCS Responsible Author(s): Efthimios Bothos, Babis Magoutas, Nikos Papageorgiou, Gregoris Mentzas (ICCS) Responsible Co-Author(s): Panagiotis Georgakis (UoW), Ilias Gerostathopoulos, Shakur Al Islam, Athina Tsirimpa (MOBY X SOFTWARE) Peer Review: Panagiotis Georgakis (UoW), Ilias Gerostathopoulos (MOBY X SOFTWARE) Quality Assurance Committee Maria Kamargianni, Lampros Yfantis (UCL) Review: DOCUMENT HISTORY Version Date Released by Nature of Change 0.1 02/12/2019 ICCS ToC defined 0.3 15/01/2020 ICCS Conceptual approach described 0.5 10/03/2020 ICCS Data descriptions updated 0.7 15/04/2020 ICCS Added sections 3 and 4 0.9 12/05/2020 ICCS Ready for internal review 1.0 01/06/2020 ICCS Final version 1 D3.2 - Transport and SpatialData Warehouse Technical Design TABLE OF CONTENTS EXECUTIVE SUMMARY .................................................................................................................... -
Apache Couchdb Tutorial Apache Couchdb Tutorial
Apache CouchDB Tutorial Apache CouchDB Tutorial Welcome to CouchDB Tutorial. In this CouchDB Tutorial, we will learn how to install CouchDB, create database in CouchDB, create documents in a database, replication between CouchDBs, configure databases, and many other concepts. What is CouchDB? CouchDB is a NoSQL Database that uses JSON for documents. CouchDB uses JavaScript for MapReduce indexes. CouchDB uses HTTP for the REST API. CouchDB Installation To install CouchDB, visit [https://couchdb.apache.org/] and click on the download button as shown below. When you click on the download button, it scrolls to the section, where based on your Operating System, you can download the installer. In this tutorial, we have downloaded for Windows (x64), and it should not make any difference if you download for macOs or Debian/Ubuntu/RHEL/CentOS. Double click the downloaded installer and follow through the steps. Once the installation is complete, you can check if CouchDB is installed successfully by requesting the URL http://127.0.0.1:5984/ in your browser. This is CouchDB saying welcome to you, along with information about CouchDB version, GIT hash, UUID, features and vendor. Fauxton Fauxton is a web based interface built into CouchDB. You can do actions like creating and deleting databases, CRUD operations on documents, user management, running MapReduce on indexex, replication between CouchDB instances. You can access CouchDB through Fauxton available at the URL http://127.0.0.1:5984/_utils/. Here you can access the following tabs in the left menu. All Databases Setup Active Tasks Configuration Replication Documentation Verify Create Database in CouchDB To create a CouchDB Database, click on Databases tab in the left menu and then click on Create Database. -

Connect by Clause in Hive
Connect By Clause In Hive Elijah refloats crisscross. Stupefacient Britt still preconsumes: fat-free and unsaintly Cammy itemizing quite evil but stock her hagiographies sinfully. Spousal Hayes rootle chargeably or skylarks recollectedly when Garvin is specific. Sqoop Import Data From MySQL to Hive DZone Big Data. Also handle jdbc driver task that in clause in! Learn more compassion the open-source Apache Hive data warehouse. Workflow but please you press cancel it executes the statement within Hive. For the Apache Hive Connector supports the thin of else clause. Re HIVESTART WITH again CONNECT BY implementation in. Regular disk scans will you with clause by. How data use Python with Hive to handle initial Data SoftKraft. SQL to Hive Cheat Sheet. Copy file from s3 to hdfs. The hplsqlconnhiveconn option specifies the connection profile for. Select Yes to famine the job if would CREATE TABLE statement fails. Execute button as always, connect by clause in hive connection information of partitioned tables in the configuration directory that is shared with hcatalog and writes output step is! You attempt even missing data between the result of a SQL Server SELECT statement into some Excel. Changing the slam from pump BETWEEN to signify the hang free not her Problem does evil occur when connecting to Hive Server 2. Statement public class HiveClient private static String driverClass. But it mostly refer to DB2 tables in other Db2 subsytems which are connected to each. Hive Connection Options Informatica Documentation. Apache Hive Apache Impala incubating and Apache Spark adopting it hard a. Execute hive query in alteryx Alteryx Community. -

Master Big Data Y Ciencia De Los Datos
Master Big Data y Ciencia de los Datos Duración: 300 h Modalidad: Teleformación Introducción al científico de los datos. Hace ya algunos años Jeff Hammerbacher y DJ Patil acuñaron el término “científico de datos” para referirse a aquel profesional multidisciplinar capaz de abordar proyectos de extremo a extremo en el ámbito de ciencia de los datos, lo que incluye almacenar y limpiar grandes volúmenes de datos, explorar conjuntos de datos para identificar información potencialmente relevante, construir modelos predictivos y construir una historia alrededor de los hallazgos derivados de tales modelos. Un científico de datos es capaz de definir modelos estadísticos y matemáticos que sean de aplicación en el conjunto de datos, lo que incluye aplicar su conocimiento teórico en estadística y algoritmos para encontrar la solución óptima a un problema. En la actualidad el científico de datos representa uno de los perfiles profesionales con más demanda en el ámbito empresarial, institucional y gubernamental alrededor del mundo, así como una de las profesiones en el entorno de big data y data science mejor pagadas. La creciente demanda de tales profesionales hace necesaria la creación de espacios de formación dirigidos al diseño y puesta en marcha de itinerarios formativos integrales que cubran todas aquellas áreas de conocimiento asociadas a este perfil profesional. Con el fin de cubrir esta necesidad hemos diseñado el “Plan de formación integral para el científico de datos” basado en el conocido como “Metromap” de Swami Chandrasekaran. Metodología: El plan integral de formación que presentamos se basa en una metodología 100% online. Los niveles de habilidades se presentan mediante casos prácticos y casos de uso asociados a situaciones reales. -

HPC-ABDS High Performance Computing Enhanced Apache Big Data Stack
HPC-ABDS High Performance Computing Enhanced Apache Big Data Stack Geoffrey C. Fox, Judy Qiu, Supun Kamburugamuve Shantenu Jha, Andre Luckow School of Informatics and Computing RADICAL Indiana University Rutgers University Bloomington, IN 47408, USA Piscataway, NJ 08854, USA fgcf, xqiu, [email protected] [email protected], [email protected] Abstract—We review the High Performance Computing En- systems as they illustrate key capabilities and often motivate hanced Apache Big Data Stack HPC-ABDS and summarize open source equivalents. the capabilities in 21 identified architecture layers. These The software is broken up into layers so that one can dis- cover Message and Data Protocols, Distributed Coordination, Security & Privacy, Monitoring, Infrastructure Management, cuss software systems in smaller groups. The layers where DevOps, Interoperability, File Systems, Cluster & Resource there is especial opportunity to integrate HPC are colored management, Data Transport, File management, NoSQL, SQL green in figure. We note that data systems that we construct (NewSQL), Extraction Tools, Object-relational mapping, In- from this software can run interoperably on virtualized or memory caching and databases, Inter-process Communication, non-virtualized environments aimed at key scientific data Batch Programming model and Runtime, Stream Processing, High-level Programming, Application Hosting and PaaS, Li- analysis problems. Most of ABDS emphasizes scalability braries and Applications, Workflow and Orchestration. We but not performance and one of our goals is to produce summarize status of these layers focusing on issues of impor- high performance environments. Here there is clear need tance for data analytics. We highlight areas where HPC and for better node performance and support of accelerators like ABDS have good opportunities for integration. -

Eric Redmond, Jim R. Wilson — «Seven Databases in Seven Weeks
What Readers Are Saying About Seven Databases in Seven Weeks The flow is perfect. On Friday, you’ll be up and running with a new database. On Saturday, you’ll see what it’s like under daily use. By Sunday, you’ll have learned a few tricks that might even surprise the experts! And next week, you’ll vault to another database and have fun all over again. ➤ Ian Dees Coauthor, Using JRuby Provides a great overview of several key databases that will multiply your data modeling options and skills. Read if you want database envy seven times in a row. ➤ Sean Copenhaver Lead Code Commodore, backgroundchecks.com This is by far the best substantive overview of modern databases. Unlike the host of tutorials, blog posts, and documentation I have read, this book taught me why I would want to use each type of database and the ways in which I can use them in a way that made me easily understand and retain the information. It was a pleasure to read. ➤ Loren Sands-Ramshaw Software Engineer, U.S. Department of Defense This is one of the best CouchDB introductions I have seen. ➤ Jan Lehnardt Apache CouchDB Developer and Author Seven Databases in Seven Weeks is an excellent introduction to all aspects of modern database design and implementation. Even spending a day in each chapter will broaden understanding at all skill levels, from novice to expert— there’s something there for everyone. ➤ Jerry Sievert Director of Engineering, Daily Insight Group In an ideal world, the book cover would have been big enough to call this book “Everything you never thought you wanted to know about databases that you can’t possibly live without.” To be fair, Seven Databases in Seven Weeks will probably sell better.