Amazon EMR Migration Guide How to Move Apache Spark and Apache Hadoop from On-Premises to AWS
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Java Linksammlung
JAVA LINKSAMMLUNG LerneProgrammieren.de - 2020 Java einfach lernen (klicke hier) JAVA LINKSAMMLUNG INHALTSVERZEICHNIS Build ........................................................................................................................................................... 4 Caching ....................................................................................................................................................... 4 CLI ............................................................................................................................................................... 4 Cluster-Verwaltung .................................................................................................................................... 5 Code-Analyse ............................................................................................................................................. 5 Code-Generators ........................................................................................................................................ 5 Compiler ..................................................................................................................................................... 6 Konfiguration ............................................................................................................................................. 6 CSV ............................................................................................................................................................. 6 Daten-Strukturen -

Oracle Metadata Management V12.2.1.3.0 New Features Overview
An Oracle White Paper October 12 th , 2018 Oracle Metadata Management v12.2.1.3.0 New Features Overview Oracle Metadata Management version 12.2.1.3.0 – October 12 th , 2018 New Features Overview Disclaimer This document is for informational purposes. It is not a commitment to deliver any material, code, or functionality, and should not be relied upon in making purchasing decisions. The development, release, and timing of any features or functionality described in this document remains at the sole discretion of Oracle. This document in any form, software or printed matter, contains proprietary information that is the exclusive property of Oracle. This document and information contained herein may not be disclosed, copied, reproduced, or distributed to anyone outside Oracle without prior written consent of Oracle. This document is not part of your license agreement nor can it be incorporated into any contractual agreement with Oracle or its subsidiaries or affiliates. 1 Oracle Metadata Management version 12.2.1.3.0 – October 12 th , 2018 New Features Overview Table of Contents Executive Overview ............................................................................ 3 Oracle Metadata Management 12.2.1.3.0 .......................................... 4 METADATA MANAGER VS METADATA EXPLORER UI .............. 4 METADATA HOME PAGES ........................................................... 5 METADATA QUICK ACCESS ........................................................ 6 METADATA REPORTING ............................................................. -

Wandisco Fusion® Microsoft Azure Data Box
WANDISCO FUSION® MICROSOFT AZURE DATA BOX Use WANdisco Fusion with Data Box for bulk transfer of changing data WANdisco Fusion is the only solution that enables Microsoft customers to use the bulk transfer capabilities of the Azure Data Box to transfer static and changing Guaranteed data consistency information from Big Data applications to Azure Cloud with guaranteed data consistency. Users can continue to Take advantage of the storage on Azure Data Box for write to their local cluster while the Azure Data Box is in bulk data transfer while continuing to write to a local transit so when the Azure Data Box is subsequently being cluster and replicate those changes while the Azure uploaded, any changes are replicated to the Azure Cloud Data Box is uploaded to the Azure Cloud. with guaranteed consistency. Easy and intuitive step-by-step operation • Applications write to Azure Data Box using the same API that they use to interact with the Azure Cloud. No downtime and • WANdisco Fusion for Azure Data Box requires no change to applications which can continue to use the no business disruption API as they would normally. Write data to a local HDFS-compatible endpoint • Replication is continuous and recovers from on-premises and replicate to a storage location in intermittent network or system failures automatically. Microsoft Azure with no modification or disruption to applications on-premises. AZURE 2 STORAGE Cost saving MICROSOFT 1 3 AZURE DATA BOX Avoid the high network costs common to large scale data transfers and benefit from a range of FUSION applications available in Azure Cloud. -

The Dzone Guide to Volume Ii
THE D ZONE GUIDE TO MODERN JAVA VOLUME II BROUGHT TO YOU IN PARTNERSHIP WITH DZONE.COM/GUIDES DZONE’S 2016 GUIDE TO MODERN JAVA Dear Reader, TABLE OF CONTENTS 3 EXECUTIVE SUMMARY Why isn’t Java dead after more than two decades? A few guesses: Java is (still) uniquely portable, readable to 4 KEY RESEARCH FINDINGS fresh eyes, constantly improving its automatic memory management, provides good full-stack support for high- 10 THE JAVA 8 API DESIGN PRINCIPLES load web services, and enjoys a diverse and enthusiastic BY PER MINBORG community, mature toolchain, and vigorous dependency 13 PROJECT JIGSAW IS COMING ecosystem. BY NICOLAI PARLOG Java is growing with us, and we’re growing with Java. Java 18 REACTIVE MICROSERVICES: DRIVING APPLICATION 8 just expanded our programming paradigm horizons (add MODERNIZATION EFFORTS Church and Curry to Kay and Gosling) and we’re still learning BY MARKUS EISELE how to mix functional and object-oriented code. Early next 21 CHECKLIST: 7 HABITS OF SUPER PRODUCTIVE JAVA DEVELOPERS year Java 9 will add a wealth of bigger-picture upgrades. 22 THE ELEMENTS OF MODERN JAVA STYLE But Java remains vibrant for many more reasons than the BY MICHAEL TOFINETTI robustness of the language and the comprehensiveness of the platform. JVM languages keep multiplying (Kotlin went 28 12 FACTORS AND BEYOND IN JAVA GA this year!), Android keeps increasing market share, and BY PIETER HUMPHREY AND MARK HECKLER demand for Java developers (measuring by both new job 31 DIVING DEEPER INTO JAVA DEVELOPMENT posting frequency and average salary) remains high. The key to the modernization of Java is not a laundry-list of JSRs, but 34 INFOGRAPHIC: JAVA'S IMPACT ON THE MODERN WORLD rather the energy of the Java developer community at large. -
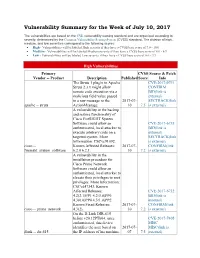
Vulnerability Summary for the Week of July 10, 2017
Vulnerability Summary for the Week of July 10, 2017 The vulnerabilities are based on the CVE vulnerability naming standard and are organized according to severity, determined by the Common Vulnerability Scoring System (CVSS) standard. The division of high, medium, and low severities correspond to the following scores: High - Vulnerabilities will be labeled High severity if they have a CVSS base score of 7.0 - 10.0 Medium - Vulnerabilities will be labeled Medium severity if they have a CVSS base score of 4.0 - 6.9 Low - Vulnerabilities will be labeled Low severity if they have a CVSS base score of 0.0 - 3.9 High Vulnerabilities Primary CVSS Source & Patch Vendor -- Product Description Published Score Info The Struts 1 plugin in Apache CVE-2017-9791 Struts 2.3.x might allow CONFIRM remote code execution via a BID(link is malicious field value passed external) in a raw message to the 2017-07- SECTRACK(link apache -- struts ActionMessage. 10 7.5 is external) A vulnerability in the backup and restore functionality of Cisco FireSIGHT System Software could allow an CVE-2017-6735 authenticated, local attacker to BID(link is execute arbitrary code on a external) targeted system. More SECTRACK(link Information: CSCvc91092. is external) cisco -- Known Affected Releases: 2017-07- CONFIRM(link firesight_system_software 6.2.0 6.2.1. 10 7.2 is external) A vulnerability in the installation procedure for Cisco Prime Network Software could allow an authenticated, local attacker to elevate their privileges to root privileges. More Information: CSCvd47343. Known Affected Releases: CVE-2017-6732 4.2(2.1)PP1 4.2(3.0)PP6 BID(link is 4.3(0.0)PP4 4.3(1.0)PP2. -

Chainsys-Platform-Technical Architecture-Bots
Technical Architecture Objectives ChainSys’ Smart Data Platform enables the business to achieve these critical needs. 1. Empower the organization to be data-driven 2. All your data management problems solved 3. World class innovation at an accessible price Subash Chandar Elango Chief Product Officer ChainSys Corporation Subash's expertise in the data management sphere is unparalleled. As the creative & technical brain behind ChainSys' products, no problem is too big for Subash, and he has been part of hundreds of data projects worldwide. Introduction This document describes the Technical Architecture of the Chainsys Platform Purpose The purpose of this Technical Architecture is to define the technologies, products, and techniques necessary to develop and support the system and to ensure that the system components are compatible and comply with the enterprise-wide standards and direction defined by the Agency. Scope The document's scope is to identify and explain the advantages and risks inherent in this Technical Architecture. This document is not intended to address the installation and configuration details of the actual implementation. Installation and configuration details are provided in technology guides produced during the project. Audience The intended audience for this document is Project Stakeholders, technical architects, and deployment architects The system's overall architecture goals are to provide a highly available, scalable, & flexible data management platform Architecture Goals A key Architectural goal is to leverage industry best practices to design and develop a scalable, enterprise-wide J2EE application and follow the industry-standard development guidelines. All aspects of Security must be developed and built within the application and be based on Best Practices. -

Return of Organization Exempt from Income
OMB No. 1545-0047 Return of Organization Exempt From Income Tax Form 990 Under section 501(c), 527, or 4947(a)(1) of the Internal Revenue Code (except black lung benefit trust or private foundation) Open to Public Department of the Treasury Internal Revenue Service The organization may have to use a copy of this return to satisfy state reporting requirements. Inspection A For the 2011 calendar year, or tax year beginning 5/1/2011 , and ending 4/30/2012 B Check if applicable: C Name of organization The Apache Software Foundation D Employer identification number Address change Doing Business As 47-0825376 Name change Number and street (or P.O. box if mail is not delivered to street address) Room/suite E Telephone number Initial return 1901 Munsey Drive (909) 374-9776 Terminated City or town, state or country, and ZIP + 4 Amended return Forest Hill MD 21050-2747 G Gross receipts $ 554,439 Application pending F Name and address of principal officer: H(a) Is this a group return for affiliates? Yes X No Jim Jagielski 1901 Munsey Drive, Forest Hill, MD 21050-2747 H(b) Are all affiliates included? Yes No I Tax-exempt status: X 501(c)(3) 501(c) ( ) (insert no.) 4947(a)(1) or 527 If "No," attach a list. (see instructions) J Website: http://www.apache.org/ H(c) Group exemption number K Form of organization: X Corporation Trust Association Other L Year of formation: 1999 M State of legal domicile: MD Part I Summary 1 Briefly describe the organization's mission or most significant activities: to provide open source software to the public that we sponsor free of charge 2 Check this box if the organization discontinued its operations or disposed of more than 25% of its net assets. -

Oracle Big Data SQL Release 4.1
ORACLE DATA SHEET Oracle Big Data SQL Release 4.1 The unprecedented explosion in data that can be made useful to enterprises – from the Internet of Things, to the social streams of global customer bases – has created a tremendous opportunity for businesses. However, with the enormous possibilities of Big Data, there can also be enormous complexity. Integrating Big Data systems to leverage these vast new data resources with existing information estates can be challenging. Valuable data may be stored in a system separate from where the majority of business-critical operations take place. Moreover, accessing this data may require significant investment in re-developing code for analysis and reporting - delaying access to data as well as reducing the ultimate value of the data to the business. Oracle Big Data SQL enables organizations to immediately analyze data across Apache Hadoop, Apache Kafka, NoSQL, object stores and Oracle Database leveraging their existing SQL skills, security policies and applications with extreme performance. From simplifying data science efforts to unlocking data lakes, Big Data SQL makes the benefits of Big Data available to the largest group of end users possible. KEY FEATURES Rich SQL Processing on All Data • Seamlessly query data across Oracle Oracle Big Data SQL is a data virtualization innovation from Oracle. It is a new Database, Hadoop, object stores, architecture and solution for SQL and other data APIs (such as REST and Node.js) on Kafka and NoSQL sources disparate data sets, seamlessly integrating data in Apache Hadoop, Apache Kafka, • Runs all Oracle SQL queries without modification – preserving application object stores and a number of NoSQL databases with data stored in Oracle Database. -

Hybrid Transactional/Analytical Processing: a Survey
Hybrid Transactional/Analytical Processing: A Survey Fatma Özcan Yuanyuan Tian Pınar Tözün IBM Resarch - Almaden IBM Research - Almaden IBM Research - Almaden [email protected] [email protected] [email protected] ABSTRACT To understand HTAP, we first need to look into OLTP The popularity of large-scale real-time analytics applications and OLAP systems and how they progressed over the years. (real-time inventory/pricing, recommendations from mobile Relational databases have been used for both transaction apps, fraud detection, risk analysis, IoT, etc.) keeps ris- processing as well as analytics. However, OLTP and OLAP ing. These applications require distributed data manage- systems have very different characteristics. OLTP systems ment systems that can handle fast concurrent transactions are identified by their individual record insert/delete/up- (OLTP) and analytics on the recent data. Some of them date statements, as well as point queries that benefit from even need running analytical queries (OLAP) as part of indexes. One cannot think about OLTP systems without transactions. Efficient processing of individual transactional indexing support. OLAP systems, on the other hand, are and analytical requests, however, leads to different optimiza- updated in batches and usually require scans of the tables. tions and architectural decisions while building a data man- Batch insertion into OLAP systems are an artifact of ETL agement system. (extract transform load) systems that consolidate and trans- For the kind of data processing that requires both ana- form transactional data from OLTP systems into an OLAP lytics and transactions, Gartner recently coined the term environment for analysis. Hybrid Transactional/Analytical Processing (HTAP). -

4.3.0 Third Party License Files
Third Party Terms Third Party License(s) of Terracotta Version 4.3 THE FOLLOWING THIRD PARTY COMPONENTS MAY BE UTILIZED, EMBEDDED, BUNDLED OR OTHERWISE INCLUDED IN SOME OF THE PRODUCTS ("Product") YOU HAVE LICENSED FROM TERRACOTTA, INC..THESE THIRD PARTY COMPONENTS MAY BE SUBJECT TO ADDITIONAL OR DIFFERENT LICENSE RIGHTS, TERMS AND CONDITIONS AND / OR REQUIRE CERTAIN NOTICES BY THEIR THIRD PARTY LICENSORS. SOFTWARE AG IS OBLIGED TO PASS ANY CURRENT AND FUTURE TERMS OF SUCH LICENSES THROUGH TO ITS LICENSEES. TP Product Name TP Product Version apache-commons-io 2.4 apache-commons-lang 2.5 apache-commons-logging 1.0.3 apache-jakarta-commons-beanutils 1.8.3 apache-jakarta-commons-cli 1.1 apache-jakarta-commons-collections 3.2.1 apache-jakarta-commons-logging 1.1.1 apache-log4j 1.2.17 apache-shiro 1.2.3 apache-xmlbeans 2.4.0 beanshell-project 2.0b4 commons-lang 2.6 fasterxml-jackson-annotations 2.3 gf.aopalliance-repackaged.jar 2.2.0 gf.hk2.api.jar 2.2.0 gf.hk2.locator.jar 2.2.0 Copyright (c) 2015 Software AG, Darmstadt, Germany Third Party License(s) of Terracotta Version 4.3 TP Product Name TP Product Version gf.hk2-utils.jar 2.2.0 gf.javax.annotation-api.jar 1.20 gf.javax.annotation.jar 1.1 gf.javax.inject.jar 2.2.0 gf.javax.jms.jar 1.1 gf.javax.mail.jar 1.4.4 (API 1.4) gf.javax.security.auth.message.jar 1.0 gf.javax.servlet-api.jar 3.0.1 gf.javax.transaction.jar 1.1 gf.javax.ws.rs-api.jar 2.00 gf.jersey-client.jar 2.6.0 gf.jersey-common.jar 2.6.0 gf.jersey-container-servlet-core.jar 2.6.0 gf.jersey-container-servlet.jar 2.6 gf.jersey-guava.jar -

Sphinx: Empowering Impala for Efficient Execution of SQL Queries
Sphinx: Empowering Impala for Efficient Execution of SQL Queries on Big Spatial Data Ahmed Eldawy1, Ibrahim Sabek2, Mostafa Elganainy3, Ammar Bakeer3, Ahmed Abdelmotaleb3, and Mohamed F. Mokbel2 1 University of California, Riverside [email protected] 2 University of Minnesota, Twin Cities {sabek,mokbel}@cs.umn.edu 3 KACST GIS Technology Innovation Center, Saudi Arabia {melganainy,abakeer,aothman}@gistic.org Abstract. This paper presents Sphinx, a full-fledged open-source sys- tem for big spatial data which overcomes the limitations of existing sys- tems by adopting a standard SQL interface, and by providing a high efficient core built inside the core of the Apache Impala system. Sphinx is composed of four main layers, namely, query parser, indexer, query planner, and query executor. The query parser injects spatial data types and functions in the SQL interface of Sphinx. The indexer creates spa- tial indexes in Sphinx by adopting a two-layered index design. The query planner utilizes these indexes to construct efficient query plans for range query and spatial join operations. Finally, the query executor carries out these plans on big spatial datasets in a distributed cluster. A system prototype of Sphinx running on real datasets shows up-to three orders of magnitude performance improvement over plain-vanilla Impala, Spa- tialHadoop, and PostGIS. 1 Introduction There has been a recent marked increase in the amount of spatial data produced by several devices including smart phones, space telescopes, medical devices, among others. For example, space telescopes generate up to 150 GB weekly spatial data, medical devices produce spatial images (X-rays) at 50 PB per year, NASA satellite data has more than 1 PB, while there are 10 Million geo- tagged tweets issued from Twitter every day as 2% of the whole Twitter firehose. -

Participating Organisations | June 2021 Aon Rewards Solutions Proprietary and Confidential
Aon Rewards Solutions Proprietary and Confidential Participating organisations | June 2021 Aon Rewards Solutions Proprietary and Confidential Participating organisations 1. .au Domain Administration 44. Alexion Pharmaceuticals Limited Australasia Pty Ltd 2. [24]7.ai 45. Alfa Financial Software 3. 10X Genomics* Limited 4. 4 Pines Brewing Company 46. Alibaba Group Inc 5. 8X8 47. Alida* 6. A.F. Gason Pty Ltd* 48. Align Technology Inc. 7. A10 Networks 49. Alkane Resources Limited 8. Abacus DX 50. Allianz Australia Ltd 9. AbbVie Pty Ltd 51. Allscripts 10. Ability Options Ltd 52. Alteryx 11. Abiomed* 53. Altium Ltd 12. AC3 54. Amazon.com 55. AMEC Foster Wheeler 13. ACCELA* Australia Pty Ltd 14. Accenture Australia Ltd 56. Amgen Australia Pty Ltd 15. AccorHotels 57. AMP Services Limited 16. Acer Computer Australia Pty Ltd* 58. AMSC 17. Achieve Australia Limited* 59. Analog Devices 18. Achmea Australia 60. Anaplan 19. ACI Worldwide 61. Ancestry.com 62. Anglo American Metallurgical 20. Acquia Coal Pty Ltd 21. Actian Corporation 63. AngloGold Ashanti Australia 22. Activision Blizzard Limited* 23. Adaman Resources 64. ANZ Banking Group Ltd 24. Adcolony 65. Aon Corporation Australia 25. A-dec Australia 66. APA Group 26. ADG Engineers* 67. Apollo Endosurgery Inc. 27. Adherium Limited 68. APPEN LTD 28. Administrative Services 69. Appian* 29. Adobe Systems Inc 70. Apple and Pear Australia Ltd* 30. ADP 71. Apple Pty Ltd 31. Adtran 72. Apptio 32. Advanced Micro Devices 73. APRA AMCOS 33. Advanced Sterlization 74. Aptean Products* 75. Aptos* 34. AECOM* 76. Apttus 35. AEMO 77. Aquila Resources 36. Aeris Resources Limited 78. Arcadis 37.