Is There a Schema Construct in Hbase
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Administration and Configuration Guide
Red Hat JBoss Data Virtualization 6.4 Administration and Configuration Guide This guide is for administrators. Last Updated: 2018-09-26 Red Hat JBoss Data Virtualization 6.4 Administration and Configuration Guide This guide is for administrators. Red Hat Customer Content Services Legal Notice Copyright © 2018 Red Hat, Inc. This document is licensed by Red Hat under the Creative Commons Attribution-ShareAlike 3.0 Unported License. If you distribute this document, or a modified version of it, you must provide attribution to Red Hat, Inc. and provide a link to the original. If the document is modified, all Red Hat trademarks must be removed. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent. Red Hat Software Collections is not formally related to or endorsed by the official Joyent Node.js open source or commercial project. -

Synthesis and Development of a Big Data Architecture for the Management of Radar Measurement Data
1 Faculty of Electrical Engineering, Mathematics & Computer Science Synthesis and Development of a Big Data architecture for the management of radar measurement data Alex Aalbertsberg Master of Science Thesis November 2018 Supervisors: dr. ir. Maurice van Keulen (University of Twente) prof. dr. ir. Mehmet Aks¸it (University of Twente) dr. Doina Bucur (University of Twente) ir. Ronny Harmanny (Thales) University of Twente P.O. Box 217 7500 AE Enschede The Netherlands Approval Internship report/Thesis of: …………………………………………………………………………………………………………Alexander P. Aalbertsberg Title: …………………………………………………………………………………………Synthesis and Development of a Big Data architecture for the management of radar measurement data Educational institution: ………………………………………………………………………………..University of Twente Internship/Graduation period:…………………………………………………………………………..2017-2018 Location/Department:.…………………………………………………………………………………435 Advanced Development, Delft Thales Supervisor:……………………………………………………………………………R. I. A. Harmanny This report (both the paper and electronic version) has been read and commented on by the supervisor of Thales Netherlands B.V. In doing so, the supervisor has reviewed the contents and considering their sensitivity, also information included therein such as floor plans, technical specifications, commercial confidential information and organizational charts that contain names. Based on this, the supervisor has decided the following: o This report is publicly available (Open). Any defence may take place publicly and the report may be included in public libraries and/or published in knowledge bases. • o This report and/or a summary thereof is publicly available to a limited extent (Thales Group Internal). tors . It will be read and reviewed exclusively by teachers and if necessary by members of the examination board or review ? committee. The content will be kept confidential and not disseminated through publication or inclusion in public libraries and/or knowledge bases. -
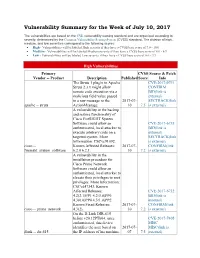
Vulnerability Summary for the Week of July 10, 2017
Vulnerability Summary for the Week of July 10, 2017 The vulnerabilities are based on the CVE vulnerability naming standard and are organized according to severity, determined by the Common Vulnerability Scoring System (CVSS) standard. The division of high, medium, and low severities correspond to the following scores: High - Vulnerabilities will be labeled High severity if they have a CVSS base score of 7.0 - 10.0 Medium - Vulnerabilities will be labeled Medium severity if they have a CVSS base score of 4.0 - 6.9 Low - Vulnerabilities will be labeled Low severity if they have a CVSS base score of 0.0 - 3.9 High Vulnerabilities Primary CVSS Source & Patch Vendor -- Product Description Published Score Info The Struts 1 plugin in Apache CVE-2017-9791 Struts 2.3.x might allow CONFIRM remote code execution via a BID(link is malicious field value passed external) in a raw message to the 2017-07- SECTRACK(link apache -- struts ActionMessage. 10 7.5 is external) A vulnerability in the backup and restore functionality of Cisco FireSIGHT System Software could allow an CVE-2017-6735 authenticated, local attacker to BID(link is execute arbitrary code on a external) targeted system. More SECTRACK(link Information: CSCvc91092. is external) cisco -- Known Affected Releases: 2017-07- CONFIRM(link firesight_system_software 6.2.0 6.2.1. 10 7.2 is external) A vulnerability in the installation procedure for Cisco Prime Network Software could allow an authenticated, local attacker to elevate their privileges to root privileges. More Information: CSCvd47343. Known Affected Releases: CVE-2017-6732 4.2(2.1)PP1 4.2(3.0)PP6 BID(link is 4.3(0.0)PP4 4.3(1.0)PP2. -

Chainsys-Platform-Technical Architecture-Bots
Technical Architecture Objectives ChainSys’ Smart Data Platform enables the business to achieve these critical needs. 1. Empower the organization to be data-driven 2. All your data management problems solved 3. World class innovation at an accessible price Subash Chandar Elango Chief Product Officer ChainSys Corporation Subash's expertise in the data management sphere is unparalleled. As the creative & technical brain behind ChainSys' products, no problem is too big for Subash, and he has been part of hundreds of data projects worldwide. Introduction This document describes the Technical Architecture of the Chainsys Platform Purpose The purpose of this Technical Architecture is to define the technologies, products, and techniques necessary to develop and support the system and to ensure that the system components are compatible and comply with the enterprise-wide standards and direction defined by the Agency. Scope The document's scope is to identify and explain the advantages and risks inherent in this Technical Architecture. This document is not intended to address the installation and configuration details of the actual implementation. Installation and configuration details are provided in technology guides produced during the project. Audience The intended audience for this document is Project Stakeholders, technical architects, and deployment architects The system's overall architecture goals are to provide a highly available, scalable, & flexible data management platform Architecture Goals A key Architectural goal is to leverage industry best practices to design and develop a scalable, enterprise-wide J2EE application and follow the industry-standard development guidelines. All aspects of Security must be developed and built within the application and be based on Best Practices. -

Sphinx: Empowering Impala for Efficient Execution of SQL Queries
Sphinx: Empowering Impala for Efficient Execution of SQL Queries on Big Spatial Data Ahmed Eldawy1, Ibrahim Sabek2, Mostafa Elganainy3, Ammar Bakeer3, Ahmed Abdelmotaleb3, and Mohamed F. Mokbel2 1 University of California, Riverside [email protected] 2 University of Minnesota, Twin Cities {sabek,mokbel}@cs.umn.edu 3 KACST GIS Technology Innovation Center, Saudi Arabia {melganainy,abakeer,aothman}@gistic.org Abstract. This paper presents Sphinx, a full-fledged open-source sys- tem for big spatial data which overcomes the limitations of existing sys- tems by adopting a standard SQL interface, and by providing a high efficient core built inside the core of the Apache Impala system. Sphinx is composed of four main layers, namely, query parser, indexer, query planner, and query executor. The query parser injects spatial data types and functions in the SQL interface of Sphinx. The indexer creates spa- tial indexes in Sphinx by adopting a two-layered index design. The query planner utilizes these indexes to construct efficient query plans for range query and spatial join operations. Finally, the query executor carries out these plans on big spatial datasets in a distributed cluster. A system prototype of Sphinx running on real datasets shows up-to three orders of magnitude performance improvement over plain-vanilla Impala, Spa- tialHadoop, and PostGIS. 1 Introduction There has been a recent marked increase in the amount of spatial data produced by several devices including smart phones, space telescopes, medical devices, among others. For example, space telescopes generate up to 150 GB weekly spatial data, medical devices produce spatial images (X-rays) at 50 PB per year, NASA satellite data has more than 1 PB, while there are 10 Million geo- tagged tweets issued from Twitter every day as 2% of the whole Twitter firehose. -

Using Apache Phoenix to Store and Access Data Date Published: 2020-02-29 Date Modified: 2020-07-28
Cloudera Runtime 7.2.1 Using Apache Phoenix to Store and Access Data Date published: 2020-02-29 Date modified: 2020-07-28 https://docs.cloudera.com/ Legal Notice © Cloudera Inc. 2021. All rights reserved. The documentation is and contains Cloudera proprietary information protected by copyright and other intellectual property rights. No license under copyright or any other intellectual property right is granted herein. Copyright information for Cloudera software may be found within the documentation accompanying each component in a particular release. Cloudera software includes software from various open source or other third party projects, and may be released under the Apache Software License 2.0 (“ASLv2”), the Affero General Public License version 3 (AGPLv3), or other license terms. Other software included may be released under the terms of alternative open source licenses. Please review the license and notice files accompanying the software for additional licensing information. Please visit the Cloudera software product page for more information on Cloudera software. For more information on Cloudera support services, please visit either the Support or Sales page. Feel free to contact us directly to discuss your specific needs. Cloudera reserves the right to change any products at any time, and without notice. Cloudera assumes no responsibility nor liability arising from the use of products, except as expressly agreed to in writing by Cloudera. Cloudera, Cloudera Altus, HUE, Impala, Cloudera Impala, and other Cloudera marks are registered or unregistered trademarks in the United States and other countries. All other trademarks are the property of their respective owners. Disclaimer: EXCEPT AS EXPRESSLY PROVIDED IN A WRITTEN AGREEMENT WITH CLOUDERA, CLOUDERA DOES NOT MAKE NOR GIVE ANY REPRESENTATION, WARRANTY, NOR COVENANT OF ANY KIND, WHETHER EXPRESS OR IMPLIED, IN CONNECTION WITH CLOUDERA TECHNOLOGY OR RELATED SUPPORT PROVIDED IN CONNECTION THEREWITH. -

HDP 3.1.4 Release Notes Date of Publish: 2019-08-26
Release Notes 3 HDP 3.1.4 Release Notes Date of Publish: 2019-08-26 https://docs.hortonworks.com Release Notes | Contents | ii Contents HDP 3.1.4 Release Notes..........................................................................................4 Component Versions.................................................................................................4 Descriptions of New Features..................................................................................5 Deprecation Notices.................................................................................................. 6 Terminology.......................................................................................................................................................... 6 Removed Components and Product Capabilities.................................................................................................6 Testing Unsupported Features................................................................................ 6 Descriptions of the Latest Technical Preview Features.......................................................................................7 Upgrading to HDP 3.1.4...........................................................................................7 Behavioral Changes.................................................................................................. 7 Apache Patch Information.....................................................................................11 Accumulo........................................................................................................................................................... -

Apache Hbase. | 1
apache hbase. | 1 how hbase works *this is a study guide that was created from lecture videos and is used to help you gain an understanding of how hbase works. HBase Foundations Yahoo released the Hadoop data storage system and Google added HDFS programming interface. HDFS stands for Hadoop Distributed File System and it spreads data across what are called nodes in it’s cluster. The data does not have a schema as it is just document/files. HDFS is schemaless, distributed and fault tolerant. MapReduce is focused on data processing and jobs to write to MapReduce are in Java. The operations of a MapReduce job is to find the data and list tasks that it needs to execute and then execute them. The action of executing is called reducers. A downside is that it is batch oriented, which means you would have to read the entire file of data even if you would like to read a small portion of data. Batch oriented is slow. Hadoop is semistructured data and unstructured data, there is no random access for Hadoop and no transaction support. HBase is also called the Hadoop database and unlike Hadoop or HDFS, it has a schema. There is an in-memory feature that gives you the ability to read information quickly. You can isolate the data you want to analyze. HBase is random access. HBase allows for CRUD, which is Creating a new document, Reading the information into an application or process, Update which will allow you to change the value and Delete where mind movement machine. -

Yellowbrick Versus Apache Impala
TECHNICAL BRIEF Yellowbrick Versus Apache Impala The Apache Hadoop technology stack is designed Impala were developed to provide this support. The to process massive data sets on commodity problem is that these technologies are a SQL ab- servers, using parallelism of disks, processors, and straction layer and do not operate optimally: while memory across a distributed file system. Apache they allow users to execute familiar SQL statements, Impala (available commercially as Cloudera Data they do not provide high performance. Warehouse) is a SQL-on-Hadoop solution that claims performant SQL operations on large For example, classic database optimizations for Hadoop data sets. storage and data layout that are common in the MPP warehouse world have not been applied in Hadoop achieves optimal rotational (HDD) disk per- the SQL-on-Hadoop world. Although Impala has formance by avoiding random access and processing optimizations to enhance performance and capabil- large blocks of data in batches. This makes it a good ities over Hive, it must read data from flat files on the solution for workloads, such as recurring reports, Hadoop Distributed File System (HDFS), which limits that commonly run in batches and have few or no its effectiveness. runtime updates. However, performance degrades rapidly when organizations start to add modern Architecture comparison: enterprise data warehouse workloads, such as: Impala versus Yellowbrick > Ad hoc, interactive queries for investigation or While Impala is a SQL layer on top of HDFS, the fine-grained insight Yellowbrick hybrid cloud data warehouse is an an- alytic MPP database designed from the ground up > Supporting more concurrent users and more- to support modern enterprise workloads in hybrid diverse job and query types and multi-cloud environments. -

Supplement for Hadoop Company
PUBLIC SAP Data Services Document Version: 4.2 Support Package 12 (14.2.12.0) – 2020-02-06 Supplement for Hadoop company. All rights reserved. All rights company. affiliate THE BEST RUN 2020 SAP SE or an SAP SE or an SAP SAP 2020 © Content 1 About this supplement........................................................4 2 Naming Conventions......................................................... 5 3 Apache Hadoop.............................................................9 3.1 Hadoop in Data Services....................................................... 11 3.2 Hadoop sources and targets.....................................................14 4 Prerequisites to Data Services configuration...................................... 15 5 Verify Linux setup with common commands ...................................... 16 6 Hadoop support for the Windows platform........................................18 7 Configure Hadoop for text data processing........................................19 8 Setting up HDFS and Hive on Windows...........................................20 9 Apache Impala.............................................................22 9.1 Connecting Impala using the Cloudera ODBC driver ................................... 22 9.2 Creating an Apache Impala datastore and DSN for Cloudera driver.........................24 10 Connect to HDFS...........................................................26 10.1 HDFS file location objects......................................................26 HDFS file location object options...............................................27 -

Hortonworks Data Platform for Enterprise Data Lakes Delivers Robust, Big Data Analytics That Accelerate Decision Making and Innovation
IBM United States Software Announcement 218-187, dated March 20, 2018 Hortonworks Data Platform for Enterprise Data Lakes delivers robust, big data analytics that accelerate decision making and innovation Table of contents 1 Overview 5 Publications 2 Key prerequisites 5 Technical information 2 Planned availability date 6 Ordering information 2 Description 7 Terms and conditions 5 Program number 9 Prices 10 Corrections Overview Hortonworks Data Platform is an enterprise ready open source Apache Hadoop distribution based on a centralized architecture supported by YARN. Hortonworks Data Platform is designed to address the needs of data at rest, power real-time customer applications, and deliver big data analytics that can help accelerate decision making and innovation. The official Apache versions for Hortonworks Data Platform V2.6.4 include: • Apache Accumulo 1.7.0 • Apache Atlas 0.8.0 • Apache Calcite 1.2.0 • Apache DataFu 1.3.0 • Apache Falcon 0.10.0 • Apache Flume 1.5.2 • Apache Hadoop 2.7.3 • Apache HBase 1.1.2 • Apache Hive 1.2.1 • Apache Hive 2.1.0 • Apache Kafka 0.10.1 • Apache Knox 0.12.0 • Apache Mahout 0.9.0 • Apache Oozie 4.2.0 • Apache Phoenix 4.7.0 • Apache Pig 0.16.0 • Apache Ranger 0.7.0 • Apache Slider 0.92.0 • Apache Spark 1.6.3 • Apache Spark 2.2.0 • Apache Sqoop 1.4.6 • Apache Storm 1.1.0 • Apache TEZ 0.7.0 • Apache Zeppelin 0.7.3 IBM United States Software Announcement 218-187 IBM is a registered trademark of International Business Machines Corporation 1 • Apache ZooKeeper 3.4.6 IBM(R) clients can download this new offering from Passport Advantage(R). -

Presto: the Definitive Guide
Presto The Definitive Guide SQL at Any Scale, on Any Storage, in Any Environment Compliments of Matt Fuller, Manfred Moser & Martin Traverso Virtual Book Tour Starburst presents Presto: The Definitive Guide Register Now! Starburst is hosting a virtual book tour series where attendees will: Meet the authors: • Meet the authors from the comfort of your own home Matt Fuller • Meet the Presto creators and participate in an Ask Me Anything (AMA) session with the book Manfred Moser authors + Presto creators • Meet special guest speakers from Martin your favorite podcasts who will Traverso moderate the AMA Register here to save your spot. Praise for Presto: The Definitive Guide This book provides a great introduction to Presto and teaches you everything you need to know to start your successful usage of Presto. —Dain Sundstrom and David Phillips, Creators of the Presto Projects and Founders of the Presto Software Foundation Presto plays a key role in enabling analysis at Pinterest. This book covers the Presto essentials, from use cases through how to run Presto at massive scale. —Ashish Kumar Singh, Tech Lead, Bigdata Query Processing Platform, Pinterest Presto has set the bar in both community-building and technical excellence for lightning- fast analytical processing on stored data in modern cloud architectures. This book is a must-read for companies looking to modernize their analytics stack. —Jay Kreps, Cocreator of Apache Kafka, Cofounder and CEO of Confluent Presto has saved us all—both in academia and industry—countless hours of work, allowing us all to avoid having to write code to manage distributed query processing.