Introduction to Big Data(Hadoop) Eco-System the Modern Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Netapp Solutions for Hadoop Reference Architecture: Cloudera Faiz Abidi (Netapp) and Udai Potluri (Cloudera) June 2018 | WP-7217
White Paper NetApp Solutions for Hadoop Reference Architecture: Cloudera Faiz Abidi (NetApp) and Udai Potluri (Cloudera) June 2018 | WP-7217 In partnership with Abstract There has been an exponential growth in data over the past decade and analyzing huge amounts of data in a reasonable time can be a challenge. Apache Hadoop is an open- source tool that can help your organization quickly mine big data and extract meaningful patterns from it. However, enterprises face several technical challenges when deploying Hadoop, specifically in the areas of cluster availability, operations, and scaling. NetApp® has developed a reference architecture with Cloudera to deliver a solution that overcomes some of these challenges so that businesses can ingest, store, and manage big data with greater reliability and scalability and with less time spent on operations and maintenance. This white paper discusses a flexible, validated, enterprise-class Hadoop architecture that is based on NetApp E-Series storage using Cloudera’s Hadoop distribution. TABLE OF CONTENTS 1 Introduction ........................................................................................................................................... 4 1.1 Big Data ..........................................................................................................................................................4 1.2 Hadoop Overview ...........................................................................................................................................4 2 NetApp E-Series -

Introduction to Hbase Schema Design
Introduction to HBase Schema Design AmANDeeP KHURANA Amandeep Khurana is The number of applications that are being developed to work with large amounts a Solutions Architect at of data has been growing rapidly in the recent past . To support this new breed of Cloudera and works on applications, as well as scaling up old applications, several new data management building solutions using the systems have been developed . Some call this the big data revolution . A lot of these Hadoop stack. He is also a co-author of HBase new systems that are being developed are open source and community driven, in Action. Prior to Cloudera, Amandeep worked deployed at several large companies . Apache HBase [2] is one such system . It is at Amazon Web Services, where he was part an open source distributed database, modeled around Google Bigtable [5] and is of the Elastic MapReduce team and built the becoming an increasingly popular database choice for applications that need fast initial versions of their hosted HBase product. random access to large amounts of data . It is built atop Apache Hadoop [1] and is [email protected] tightly integrated with it . HBase is very different from traditional relational databases like MySQL, Post- greSQL, Oracle, etc . in how it’s architected and the features that it provides to the applications using it . HBase trades off some of these features for scalability and a flexible schema . This also translates into HBase having a very different data model . Designing HBase tables is a different ballgame as compared to relational database systems . I will introduce you to the basics of HBase table design by explaining the data model and build on that by going into the various concepts at play in designing HBase tables through an example . -

E6895 Advanced Big Data Analytics Lecture 4: Data Store
E6895 Advanced Big Data Analytics Lecture 4: Data Store Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science Chief Scientist, Graph Computing, IBM Watson Research Center E6895 Advanced Big Data Analytics — Lecture 4 © CY Lin, 2016 Columbia University Reference 2 E6895 Advanced Big Data Analytics – Lecture 4: Data Store © 2015 CY Lin, Columbia University Spark SQL 3 E6895 Advanced Big Data Analytics – Lecture 4: Data Store © 2015 CY Lin, Columbia University Spark SQL 4 E6895 Advanced Big Data Analytics – Lecture 4: Data Store © 2015 CY Lin, Columbia University Apache Hive 5 E6895 Advanced Big Data Analytics – Lecture 4: Data Store © 2015 CY Lin, Columbia University Using Hive to Create a Table 6 E6895 Advanced Big Data Analytics – Lecture 4: Data Store © 2015 CY Lin, Columbia University Creating, Dropping, and Altering DBs in Apache Hive 7 E6895 Advanced Big Data Analytics – Lecture 4: Data Store © 2015 CY Lin, Columbia University Another Hive Example 8 E6895 Advanced Big Data Analytics – Lecture 4: Data Store © 2015 CY Lin, Columbia University Hive’s operation modes 9 E6895 Advanced Big Data Analytics – Lecture 4: Data Store © 2015 CY Lin, Columbia University Using HiveQL for Spark SQL 10 E6895 Advanced Big Data Analytics – Lecture 4: Data Store © 2015 CY Lin, Columbia University Hive Language Manual 11 E6895 Advanced Big Data Analytics – Lecture 4: Data Store © 2015 CY Lin, Columbia University Using Spark SQL — Steps and Example 12 E6895 Advanced Big Data Analytics – Lecture 4: Data Store © 2015 CY Lin, Columbia University Query testtweet.json Get it from Learning Spark Github ==> https://github.com/databricks/learning-spark/tree/master/files 13 E6895 Advanced Big Data Analytics – Lecture 4: Data Store © 2015 CY Lin, Columbia University SchemaRDD 14 E6895 Advanced Big Data Analytics – Lecture 4: Data Store © 2015 CY Lin, Columbia University Row Objects Row objects represent records inside SchemaRDDs, and are simply fixed-length arrays of fields. -

Apache Sentry
Apache Sentry Prasad Mujumdar [email protected] [email protected] Agenda ● Various aspects of data security ● Apache Sentry for authorization ● Key concepts of Apache Sentry ● Sentry features ● Sentry architecture ● Integration with Hadoop ecosystem ● Sentry administration ● Future plans ● Demo ● Questions Who am I • Software engineer at Cloudera • Committer and PPMC member of Apache Sentry • also for Apache Hive and Apache Flume • Part of the the original team that started Sentry work Aspects of security Perimeter Access Visibility Data Authentication Authorization Audit, Lineage Encryption, what user can do data origin, usage Kerberos, LDAP/AD Masking with data Data access Access ● Provide user access to data Authorization ● Manage access policies what user can do ● Provide role based access with data Agenda ● Various aspects of data security ● Apache Sentry for authorization ● Key concepts of Apache Sentry ● Sentry features ● Sentry architecture ● Integration with Hadoop ecosystem ● Sentry administration ● Future plans ● Demo ● Questions Apache Sentry (Incubating) Unified Authorization module for Hadoop Unlocks Key RBAC Requirements Secure, fine-grained, role-based authorization Multi-tenant administration Enforce a common set of policies across multiple data access path in Hadoop. Key Capabilities of Sentry Fine-Grained Authorization Permissions on object hierarchie. Eg, Database, Table, Columns Role-Based Authorization Support for role templetes to manage authorization for a large set of users and data objects Multi Tanent Administration -

Orchestrating Big Data Analysis Workflows in the Cloud: Research Challenges, Survey, and Future Directions
00 Orchestrating Big Data Analysis Workflows in the Cloud: Research Challenges, Survey, and Future Directions MUTAZ BARIKA, University of Tasmania SAURABH GARG, University of Tasmania ALBERT Y. ZOMAYA, University of Sydney LIZHE WANG, China University of Geoscience (Wuhan) AAD VAN MOORSEL, Newcastle University RAJIV RANJAN, Chinese University of Geoscienes and Newcastle University Interest in processing big data has increased rapidly to gain insights that can transform businesses, government policies and research outcomes. This has led to advancement in communication, programming and processing technologies, including Cloud computing services and technologies such as Hadoop, Spark and Storm. This trend also affects the needs of analytical applications, which are no longer monolithic but composed of several individual analytical steps running in the form of a workflow. These Big Data Workflows are vastly different in nature from traditional workflows. Researchers arecurrently facing the challenge of how to orchestrate and manage the execution of such workflows. In this paper, we discuss in detail orchestration requirements of these workflows as well as the challenges in achieving these requirements. We alsosurvey current trends and research that supports orchestration of big data workflows and identify open research challenges to guide future developments in this area. CCS Concepts: • General and reference → Surveys and overviews; • Information systems → Data analytics; • Computer systems organization → Cloud computing; Additional Key Words and Phrases: Big Data, Cloud Computing, Workflow Orchestration, Requirements, Approaches ACM Reference format: Mutaz Barika, Saurabh Garg, Albert Y. Zomaya, Lizhe Wang, Aad van Moorsel, and Rajiv Ranjan. 2018. Orchestrating Big Data Analysis Workflows in the Cloud: Research Challenges, Survey, and Future Directions. -

Building a Modern, Scalable Cyber Intelligence Platform with Apache Kafka
White Paper Information Security | Machine Learning October 2020 IT@Intel: Building a Modern, Scalable Cyber Intelligence Platform with Apache Kafka Our Apache Kafka data pipeline based on Confluent Platform ingests tens of terabytes per day, providing in-stream processing for faster security threat detection and response Intel IT Authors Executive Summary Ryan Clark Advanced cyber threats continue to increase in frequency and sophistication, Information Security Engineer threatening computing environments and impacting businesses’ ability to grow. Jen Edmondson More than ever, large enterprises must invest in effective information security, Product Owner using technologies that improve detection and response times. At Intel, we Dennis Kwong are transforming from our legacy cybersecurity systems to a modern, scalable Information Security Engineer Cyber Intelligence Platform (CIP) based on Kafka and Splunk. In our 2019 paper, Transforming Intel’s Security Posture with Innovations in Data Intelligence, we Jac Noel discussed the data lake, monitoring, and security capabilities of Splunk. This Security Solutions Architect paper describes the essential role Apache Kafka plays in our CIP and its key Elaine Rainbolt benefits, as shown here: Industry Engagement Manager ECONOMIES OPERATE ON DATA REDUCE TECHNICAL GENERATES OF SCALE IN STREAM DEBT AND CONTEXTUALLY RICH Paul Salessi DOWNSTREAM COSTS DATA Information Security Engineer Intel IT Contributors Victor Colvard Information Security Engineer GLOBAL ALWAYS MODERN KAFKA LEADERSHIP SCALE AND REACH ON ARCHITECTURE WITH THROUGH CONFLUENT Juan Fernandez THRIVING COMMUNITY EXPERTISE Technical Solutions Specialist Frank Ober SSD Principal Engineer Apache Kafka is the foundation of our CIP architecture. We achieve economies of Table of Contents scale as we acquire data once and consume it many times. -

Building Machine Learning Inference Pipelines at Scale
Building Machine Learning inference pipelines at scale Julien Simon Global Evangelist, AI & Machine Learning @julsimon © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. Problem statement • Real-life Machine Learning applications require more than a single model. • Data may need pre-processing: normalization, feature engineering, dimensionality reduction, etc. • Predictions may need post-processing: filtering, sorting, combining, etc. Our goal: build scalable ML pipelines with open source (Spark, Scikit-learn, XGBoost) and managed services (Amazon EMR, AWS Glue, Amazon SageMaker) © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. Apache Spark https://spark.apache.org/ • Open-source, distributed processing system • In-memory caching and optimized execution for fast performance (typically 100x faster than Hadoop) • Batch processing, streaming analytics, machine learning, graph databases and ad hoc queries • API for Java, Scala, Python, R, and SQL • Available in Amazon EMR and AWS Glue © 2019, Amazon Web Services, Inc. or its affiliates. All rights reserved. MLlib – Machine learning library https://spark.apache.org/docs/latest/ml-guide.html • Algorithms: classification, regression, clustering, collaborative filtering. • Featurization: feature extraction, transformation, dimensionality reduction. • Tools for constructing, evaluating and tuning pipelines • Transformer – a transform function that maps a DataFrame into a new -

Cómo Citar El Artículo Número Completo Más Información Del
DYNA ISSN: 0012-7353 Universidad Nacional de Colombia Iván-Herrera-Herrera, Nelson; Luján-Mora, Sergio; Gómez-Torres, Estevan Ricardo Integración de herramientas para la toma de decisiones en la congestión vehicular DYNA, vol. 85, núm. 205, 2018, Abril-Junio, pp. 363-370 Universidad Nacional de Colombia DOI: https://doi.org/10.15446/dyna.v85n205.67745 Disponible en: https://www.redalyc.org/articulo.oa?id=49657889045 Cómo citar el artículo Número completo Sistema de Información Científica Redalyc Más información del artículo Red de Revistas Científicas de América Latina y el Caribe, España y Portugal Página de la revista en redalyc.org Proyecto académico sin fines de lucro, desarrollado bajo la iniciativa de acceso abierto Integration of tools for decision making in vehicular congestion• Nelson Iván-Herrera-Herreraa, Sergio Luján-Morab & Estevan Ricardo Gómez-Torres a a Facultad de Ciencias de la Ingeniería e Industrias, Universidad Tecnológica Equinoccial, Quito, Ecuador. [email protected], [email protected] b Departamento de Lenguajes y Sistemas Informáticos, Universidad de Alicante, Alicante, España. [email protected] Received: September 15th, 2017. Received in revised form: March 15th, 2018. Accepted: March 21th, 2018. Abstract The purpose of this study is to present an analysis of the use and integration of technological tools that help decision making in situations of vehicular congestion. The city of Quito-Ecuador is considered as a case study for the done work. The research is presented according to the development of an application, using Big Data tools (Apache Flume, Apache Hadoop, Apache Pig), favoring the processing of a lot of information that is required to collect, store and process. -

Evaluation of SPARQL Queries on Apache Flink
applied sciences Article SPARQL2Flink: Evaluation of SPARQL Queries on Apache Flink Oscar Ceballos 1 , Carlos Alberto Ramírez Restrepo 2 , María Constanza Pabón 2 , Andres M. Castillo 1,* and Oscar Corcho 3 1 Escuela de Ingeniería de Sistemas y Computación, Universidad del Valle, Ciudad Universitaria Meléndez Calle 13 No. 100-00, Cali 760032, Colombia; [email protected] 2 Departamento de Electrónica y Ciencias de la Computación, Pontificia Universidad Javeriana Cali, Calle 18 No. 118-250, Cali 760031, Colombia; [email protected] (C.A.R.R.); [email protected] (M.C.P.) 3 Ontology Engineering Group, Universidad Politécnica de Madrid, Campus de Montegancedo, Boadilla del Monte, 28660 Madrid, Spain; ocorcho@fi.upm.es * Correspondence: [email protected] Abstract: Existing SPARQL query engines and triple stores are continuously improved to handle more massive datasets. Several approaches have been developed in this context proposing the storage and querying of RDF data in a distributed fashion, mainly using the MapReduce Programming Model and Hadoop-based ecosystems. New trends in Big Data technologies have also emerged (e.g., Apache Spark, Apache Flink); they use distributed in-memory processing and promise to deliver higher data processing performance. In this paper, we present a formal interpretation of some PACT transformations implemented in the Apache Flink DataSet API. We use this formalization to provide a mapping to translate a SPARQL query to a Flink program. The mapping was implemented in a prototype used to determine the correctness and performance of the solution. The source code of the Citation: Ceballos, O.; Ramírez project is available in Github under the MIT license. -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -
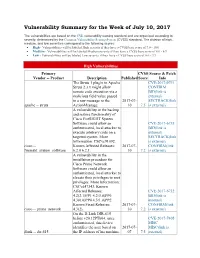
Vulnerability Summary for the Week of July 10, 2017
Vulnerability Summary for the Week of July 10, 2017 The vulnerabilities are based on the CVE vulnerability naming standard and are organized according to severity, determined by the Common Vulnerability Scoring System (CVSS) standard. The division of high, medium, and low severities correspond to the following scores: High - Vulnerabilities will be labeled High severity if they have a CVSS base score of 7.0 - 10.0 Medium - Vulnerabilities will be labeled Medium severity if they have a CVSS base score of 4.0 - 6.9 Low - Vulnerabilities will be labeled Low severity if they have a CVSS base score of 0.0 - 3.9 High Vulnerabilities Primary CVSS Source & Patch Vendor -- Product Description Published Score Info The Struts 1 plugin in Apache CVE-2017-9791 Struts 2.3.x might allow CONFIRM remote code execution via a BID(link is malicious field value passed external) in a raw message to the 2017-07- SECTRACK(link apache -- struts ActionMessage. 10 7.5 is external) A vulnerability in the backup and restore functionality of Cisco FireSIGHT System Software could allow an CVE-2017-6735 authenticated, local attacker to BID(link is execute arbitrary code on a external) targeted system. More SECTRACK(link Information: CSCvc91092. is external) cisco -- Known Affected Releases: 2017-07- CONFIRM(link firesight_system_software 6.2.0 6.2.1. 10 7.2 is external) A vulnerability in the installation procedure for Cisco Prime Network Software could allow an authenticated, local attacker to elevate their privileges to root privileges. More Information: CSCvd47343. Known Affected Releases: CVE-2017-6732 4.2(2.1)PP1 4.2(3.0)PP6 BID(link is 4.3(0.0)PP4 4.3(1.0)PP2. -

Chainsys-Platform-Technical Architecture-Bots
Technical Architecture Objectives ChainSys’ Smart Data Platform enables the business to achieve these critical needs. 1. Empower the organization to be data-driven 2. All your data management problems solved 3. World class innovation at an accessible price Subash Chandar Elango Chief Product Officer ChainSys Corporation Subash's expertise in the data management sphere is unparalleled. As the creative & technical brain behind ChainSys' products, no problem is too big for Subash, and he has been part of hundreds of data projects worldwide. Introduction This document describes the Technical Architecture of the Chainsys Platform Purpose The purpose of this Technical Architecture is to define the technologies, products, and techniques necessary to develop and support the system and to ensure that the system components are compatible and comply with the enterprise-wide standards and direction defined by the Agency. Scope The document's scope is to identify and explain the advantages and risks inherent in this Technical Architecture. This document is not intended to address the installation and configuration details of the actual implementation. Installation and configuration details are provided in technology guides produced during the project. Audience The intended audience for this document is Project Stakeholders, technical architects, and deployment architects The system's overall architecture goals are to provide a highly available, scalable, & flexible data management platform Architecture Goals A key Architectural goal is to leverage industry best practices to design and develop a scalable, enterprise-wide J2EE application and follow the industry-standard development guidelines. All aspects of Security must be developed and built within the application and be based on Best Practices.