University of Huddersfield Repository
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Extraterrestrial Places in the Cthulhu Mythos
Extraterrestrial places in the Cthulhu Mythos 1.1 Abbith A planet that revolves around seven stars beyond Xoth. It is inhabited by metallic brains, wise with the ultimate se- crets of the universe. According to Friedrich von Junzt’s Unaussprechlichen Kulten, Nyarlathotep dwells or is im- prisoned on this world (though other legends differ in this regard). 1.2 Aldebaran Aldebaran is the star of the Great Old One Hastur. 1.3 Algol Double star mentioned by H.P. Lovecraft as sidereal The double star Algol. This infrared imagery comes from the place of a demonic shining entity made of light.[1] The CHARA array. same star is also described in other Mythos stories as a planetary system host (See Ymar). The following fictional celestial bodies figure promi- nently in the Cthulhu Mythos stories of H. P. Lovecraft and other writers. Many of these astronomical bodies 1.4 Arcturus have parallels in the real universe, but are often renamed in the mythos and given fictitious characteristics. In ad- Arcturus is the star from which came Zhar and his “twin” dition to the celestial places created by Lovecraft, the Lloigor. Also Nyogtha is related to this star. mythos draws from a number of other sources, includ- ing the works of August Derleth, Ramsey Campbell, Lin Carter, Brian Lumley, and Clark Ashton Smith. 2 B Overview: 2.1 Bel-Yarnak • Name. The name of the celestial body appears first. See Yarnak. • Description. A brief description follows. • References. Lastly, the stories in which the celes- 3 C tial body makes a significant appearance or other- wise receives important mention appear below the description. -

Errata for H. P. Lovecraft: the Fiction
Errata for H. P. Lovecraft: The Fiction The layout of the stories – specifically, the fact that the first line is printed in all capitals – has some drawbacks. In most cases, it doesn’t matter, but in “A Reminiscence of Dr. Samuel Johnson”, there is no way of telling that “Privilege” and “Reminiscence” are spelled with capitals. THE BEAST IN THE CAVE A REMINISCENCE OF DR. SAMUEL JOHNSON 2.39-3.1: advanced, and the animal] advanced, 28.10: THE PRIVILEGE OF REMINISCENCE, the animal HOWEVER] THE PRIVILEGE OF 5.12: wondered if the unnatural quality] REMINISCENCE, HOWEVER wondered if this unnatural quality 28.12: occurrences of History and the] occurrences of History, and the THE ALCHEMIST 28.20: whose famous personages I was] whose 6.5: Comtes de C——“), and] Comtes de C— famous Personages I was —”), and 28.22: of August 1690 (or] of August, 1690 (or 6.14: stronghold for he proud] stronghold for 28.32: appear in print.”), and] appear in the proud Print.”), and 6.24: stones of he walls,] stones of the walls, 28.34: Juvenal, intituled “London,” by] 7.1: died at birth,] died at my birth, Juvenal, intitul’d “London,” by 7.1-2: servitor, and old and trusted] servitor, an 29.29: Poems, Mr. Johnson said:] Poems, Mr. old and trusted Johnson said: 7.33: which he had said had for] which he said 30.24: speaking for Davy when others] had for speaking for Davy when others 8.28: the Comte, the pronounced in] the 30.25-26: no Doubt but that he] no Doubt that Comte, he pronounced in he 8.29: haunted the House of] haunted the house 30.35-36: to the Greater -

H. P. Lovecraft-A Bibliography.Pdf
X-'r Art Hi H. P. LOVECRAFT; A BIBLIOGRAPHY compiled by Joseph Payne/ Brennan Yale University Library BIBLIO PRESS 1104 Vermont Avenue, N. W. Washington 5, D. C. Revised edition, copyright 1952 Joseph Payne Brennan Original from Digitized by GOO UNIVERSITY OF CALIFORNIA L&11 vie 2. THE SHUNNED HOUSE. Athol, Mass., 1928. bds., labels, uncut. o. p. August Derleth: "Not a published book. Six or seven copies hand bound by R. H. Barlow in 1936 and sent to friends." Some stapled in paper covers. A certain number of uncut, unbound but folded sheets available. Following is an extract from the copyright notice pasted to the unbound sheets: "Though the sheets of this story were printed and marked for copyright in 1928, the story was neither bound nor cir- culated at that time. A few copies were bound, put under copyright, and circulated by R. H. Barlow in 1936, but the first wide publication of the story was in the magazine, WEIRD TALES, in the following year. The story was orig- inally set up and printed by the late W. Paul Cook, pub- lisher of THE RECLUSE." FURTHER CRITICISM OF POETRY. Press of Geo. G. Fetter Co., Louisville, 1952. 13 p. o. p. THE CATS OF ULTHAR. Dragonfly Press, Cassia, Florida, 1935. 10 p. o. p. Christmas, 1935. Forty copies printed. LOOKING BACKWARD. C. W. Smith, Haverhill, Mass., 1935. 36 p. o. p. THE SHADOW OVER INNSMOUTH. Visionary Press, Everett, Pa., 1936. 158 p. o. p. Illustrations by Frank Utpatel. The only work of the author's which was published in book form during his lifetime. -

Hidden Leaves from the Necronomicon XIX Their Hidden
Hidden Leaves From The Necronomicon XIX Their Hidden Place I have seen much unmeant for mortal eyes in my wanderings beneath that dark and forgotten city. It is not the splendours of Irem that haunt my dreams with this madness, but another place, a place shrouded in utter silence; long unknown to man and shunned even by ghoul and nightgaunt. A stillness likened to millions of vanished years pressed with great heaviness upon my soul as I trod those labyrinths in terror, ever fearing that my footfalls might awaken the dread architects of this nameless region where the hand of time is bound and the wind does not whisper. Great was my fear of this place, but greater was the strange sleep-like fascination that gripped my mind and guided my feet ever downwards through realms unknown. My lamp cast it's radiance upon basalt walls, revealing mighty pillars hewn surely by no human hand, where curiously stained obelisks engraved with frightful images and cryptic characters reared above me into the darkness. A passage sloped before me, I descended. For what seemed to be an eternity I descended rapt in contemplation of the grim icons that stretched endlessly on either hand, depicting the strange deeds of Those Great Ones born not of mortal womb. They had dwelt here and passed on, yet the walls of the edifice bore Their mark: vast likenesses of those terrible beings of yore carved beneath a firmament of unguessed asterisms. Endlessly the way led downwards, ever downwards. The passage oftime had fled from my mind, Hypnos and eternity held my soul. -

Eldritch Horror Components Except for the Components Itself, Charred Skin and Still-Hot Embers Flaking from the Limb
THE CHARRED MAN EXPANSION OVERVIEW Calvin Wright huddled in a corner of the empty barn. His tattered In the Masks of Nyarlathotep expansion, investigators must clothes were covered in dirt and bloodstains and reeked of death. It embark on an epic, world-spanning campaign to hinder the had been weeks since he had been able to change them. The ringing devious plots of multiple cults. Should they fail, Nyarlathotep, in his ears was growing louder. It is coming, Calvin thought to the Messenger of the Outer Gods, will succeed at opening the himself. Sure enough, tenebrous tendrils of inky-black smoke snaked Great Gate and bringing doom upon the Earth. This expansion their way toward him from cracks in the walls. includes two new Ancient Ones and new investigators, Calvin stared ahead, unblinking, unflinching, as the tendrils Monsters, and encounters. lashed violently past him, slicing his cheek, blood oozing from the This expansion also features new mechanics, including Personal fresh wound. He dug his fingernails into his forearm and clenched Stories, Unique Assets, Focus, and Resources. In addition, it his teeth as the dark shapes coalesced gradually into the vaguely introduces a new way to play: campaign mode. humanoid shape of a creature he had come to know all too well. Appearing to be burnt from head to toe, the creature’s skin was pitch black and gave off a faint orange glow, as if it burned from within. “What do you want, demon?” Calvin growled. USING THIS EXPANSION The entity responded with a voice that sounded to Calvin like the snapping of bones. -

Regeln Für Mystische-Ruinen- Brandblasen Werfen
DER VERBRANNTE ÜBERBLICK Calvin Wright kauerte in der Ecke einer leeren Scheune. Seine zerlumpte Die Erweiterung Masken des Nyarlathotep schickt die Ermittler auf Kleidung war mit Blut und Schmutz verkrustet und stank nach Verwesung; eine epische, weltumspannende Kampagne, bei der es darum geht, er hatte sie seit Wochen nicht gewechselt. Das Pfeifen in seinen Ohren die teuflischen Pläne mehrerer Kulte zu durchkreuzen. Sollten sie wurde zusehends lauter. ‚Er ist im Anmarsch‘, dachte Calvin bei sich. Bald scheitern, wird Nyarlathotep, der Bote der Äußeren Götter, das Große schon krochen schattenhafte Tentakel aus tintenschwarzem Rauch durch die Tor öffnen und damit das Schicksal der Erde besiegeln. Mit dabei sind Risse in den Wänden und schlängelten auf ihn zu. zwei neue Große Alte sowie zahlreiche neue Ermittler, Monster und Ohne zu blinzeln, ohne auch nur mit der Wimper zu zucken, starrte Begegnungen. Calvin geradeaus, während die Fangarme an ihm vorbeischossen und seine Außerdem bietet die Erweiterung brandneue Spielmechaniken in Wange aufschlitzten. Blut quoll aus der frischen Wunde. Er krallte sich Form von persönlichen Geschichten, besonderen Unterstützungen, mit den Fingernägeln in seine Unterarme und biss die Zähne zusammen, Fokusmarkern und Ressourcen. Darüber hinaus gibt es eine völlig während die dunklen Formen allmählich zu einer menschenähnlichen neue Spielvariante: den Kampagnenmodus. Gestalt verschmolzen, die ihm nur allzu gut bekannt war. Sie schien von Kopf bis Fuß verbrannt zu sein, hatte kohlrabenschwarze Haut und verströmte ein fahles rötliches Leuchten, als würde sie von innen heraus glühen. ERWENDUNG DER RWEITERUNG „Was willst du, Dämon?“, fauchte Calvin. V E Das Wesen antwortete mit einer Stimme, die Calvin an das Knacken von Um mit der Erweiterung Masken des Nyarlathotep zu spielen, Knochen erinnerte. -

The Numinous in Gothic and Post-Gothic Ghost Experience
University of Connecticut OpenCommons@UConn Honors Scholar Theses Honors Scholar Program Spring 5-6-2012 Evolution of Effect: The uminouN s in Gothic and Post-Gothic Ghost Experience Literature Ryan P. Kennedy University of Connecticut - Storrs, [email protected] Follow this and additional works at: https://opencommons.uconn.edu/srhonors_theses Part of the English Language and Literature Commons Recommended Citation Kennedy, Ryan P., "Evolution of Effect: The uminousN in Gothic and Post-Gothic Ghost Experience Literature" (2012). Honors Scholar Theses. 252. https://opencommons.uconn.edu/srhonors_theses/252 Kennedy 1 Evolution of Effect: The Numinous in Gothic and Post-Gothic Ghost Experience Literature by Ryan P. Kennedy A Thesis submitted to the Honors Department, University of Connecticut In Partial Fulfillment of the Requirements for The Honors B.A. Degree in English Storrs, Connecticut April 2012 Kennedy 2 The earliest instances of Gothic fiction can best be described as the guilty pleasures of a self-congratulatory period of Enlightenment. The empiricism of thinkers like John Locke had come to dominant acceptance, and the belief was that the reproducible evidence of the senses was the only thing that could be upheld as truth. In this sort of atmosphere, seemingly spectral appearances were written off; the belief was that, if a spirit would not kindly consent to the demands of scientific rigor, then there was no reason to entertain their existence. E.J. Clery, author of several books on the rise of the Gothic school and the development of supernatural fiction offers an explanation for the change in perspective in regards to ghostly subject matter: “It is as though the urban relocation of the supernatural has effected a change in the very nature of superstition. -

Original Copy the Tomb (1917) Dagon (1917)
Original Copy Pirated Copy The Tomb (1917) The Tomb (1917) Dagon (1917) Dagon (1917) Polaris (1918) Polaris (1918) Beyond the Wall of Sleep (1919) Beyond the Wall of Sleep (1919) Memory (1919) Memory (1919) Old Bugs (1919) Old Bugs (1919) The Transition of Juan Romero (1919) The Transition of Juan Romero (1919) The White Ship (1919) The White Ship (1919) The Doom That Came to Sarnath (1919) The Doom That Came to Sarnath (1919) The Statement of Randolph Carter (1919) The Statement of Randolph Carter (1919) The Terrible Old Man (1920) The Terrible Old Man (1920) The Tree (1920) The Tree (1920) The Cats of Ulthar (1920) The Cats of Ulthar (1920) The Temple (1920) The Temple (1920) Facts Concerning the Late Arthur Jermyn and Facts Concerning the Late Arthur Jermyn and His Family (1920) His Family (1920) The Street (1920) The Street (1920) Celephaïs (1920) Celephaïs (1920) From Beyond (1920) From Beyond (1920) Nyarlathotep (1920) Nyarlathotep (1920) The Picture in the House (1920) The Picture in the House (1920) Ex Oblivione (1921) Ex Oblivione (1921) The Nameless City (1921) The Nameless City (1921) The Quest of Iranon (1921) The Quest of Iranon (1921) The Moon-Bog (1921) The Moon-Bog (1921) Original Copy Pirated Copy The Outsider (1921) The Outsider (1921) The Other Gods (1921) The Other Gods (1921) The Music of Erich Zann (1921) The Music of Erich Zann (1921) Herbert West — Reanimator (1922) Herbert West — Reanimator (1922) Hypnos (1922) Hypnos (1922) What the Moon Brings (1922) What the Moon Brings (1922) Azathoth (1922) Azathoth (1922) -
Trail of Cthulhu.Pdf
TRAIL OF CTHULHU Credits Publisher: Simon Rogers Written by: Kenneth Hite GUMSHOE System: Robin D Laws Layout: Jérôme Huguenin Art: Jérôme Huguenin GUMSHOE Guru: Robin D Laws Editing and Additional Material: Simon Rogers Based on: Call of Cthulhu by Sandy Petersen and Lynn Willis Special thanks : Effie and Julia Huguenin, Léo and Pascal Quidault Playtesting: Adrian Price, Steve Dempsey, Wai Kien, Adrian Smith, Graham Walmsley, Alex Fradera, Dave, Polymancer Studios, Simon Rogers, Daniel Bayn, Danni Bayn, Chris Malone, Mark DiPasquale, Matthew Pook, Tim Barker, Louise Hayes, David Lai, Mike Shepard, Carla Jane Miller, Elizabeth Rees, Robert Mills, Donald F. Taylor III, Richard Hardy, Lynne Hardy, Frederic Moll, Fredrik Hansson, Jeff Campbel Jamie Michael, Joshua Ford, Marcus Ogawa, Lisa Marie Ogawa, Gil Trevizo, Henry de Veuve, Ronald Abitz, Steve Bartalamay, Alan Fountain, Peter Kessler, Wojciech “Alter” Kobza, Laurent Mollicone, Olivier Noël, Wayne O’Connor, Ghislain Morel, James Semple, Gabriella Semple, Dan Pusceddu, Olive Pusceddu, Axel Eble, Stefan Ohrmann, Martin Schrammm, Onno Tasler, Ralf Achenbach, William C Bargo Jr, Jacques Maurice Mallah, Donald F. Taylor III, Keith A Callison, Doug © 2007 Pelgrane Press Ltd. All Rights Reserved. Published by arrangement with Chaosium, Inc. Trail of Cthulhu is a trademark of Pelgrane Press Ltd. 3 TRAIL OF CTHULHU Contents CREDITS ...........................................................3 Cop Talk (Interpersonal) ...................32 Piggybacking ........................................... -

Something Involving Tentacles
SomethingSomething InvolvingInvolving TentaclesTentacles Exploring Lovecraft, Chaos Magic, And the Alignments of the Stars Io Cthulhu Ftaghn! • WTF am I thinking? • A Brief Intro to Chaos Magic • A Brief Intro to Lovecraft and Cthulhu • The Various Necronomicons • Piecing it all together • Staying Sane WTF am I Thinking? Don’t open that door. • These are fictional things, right? – Yes and no. • Fiction can be real • Reality makes good fiction • Just because it’s fiction, does that mean it isn’t “real”? Shit, flowers, and tentacles that don’t exist. • The thing to remember about fictional entities is that they’re as real as you make ‘em. • More importantly, they serve a good purpose, much like the bullshit that makes the flowers grow. Fiction doesn’t mean it’s fake • It isn’t the genre of literature something is in that makes it real or fake, it’s the results you get from it. • If you get results, it’s real • If you don’t, it’s fake. Yeah, but why Cthulhu? • Reason 1: It gets results. • Reason 2: There is more than one way to interpret an Elder God. • Reason 3: It’s a cool thing to tell your friends • Reason 4: A little madness now and then is relished by the wisest men. • Reason 5: Why not? There are worse things • I could have reported on Catholic Schoolgirls raising demons Important Tips • Avoid needless • Never invoke anything embarrassment. bigger than your head. Practice the correct • Avoid all cabalistic pronunciation of your jewelry over 10 pounds in weight, or you’re just god’s name in the asking for trouble. -

Assignment of Copyright from Weird Tales Magazine to August Derleth
, I; ; 'I . ~ .. ~ , " ," ~ •.J I I, ASSIGl& ENT OF GOPYRIGHT r I FOR VALUE RECEIVED, WE, \?EIRD TALES LlAGAZINE PU-rlLISrlED BY S!DRT I I STO RIES, I NC ., or 1.4 . ~e st 49th S'tr-eet , Nor: York 20 , Ne':'l' York, Her-eby assign I I i 1 to August Derleth and 1?'>nald ilandr ei, both of Sauk C~ty , \'ii sco nsin, t h1.s ninth ! day of October, 1947, all our interest (vli.th the exception of magazine &erla.l ,I right s according to previous agreement) as regis tered copyright propri.etors in l r and to the copyrights of the ,follom.ng s tories~ all by Ho..:ard Phi1lips Love- i craft: I DAGON 10/25 9/ 25/ 25 B,XXc- 567392 I ! THE PIGTURE IN TIlE EDU5E 1/24 12/15/25 B,XXe-605167 i r THE HOU1'D 2/24 1/15/ 24 B,XZc-007Z40 THE RATS I N TIlE WALLS 5/24 2/15/24 B,xxe-S09499 I 1 ' THE WHITE APE 4/25 5/15/24 n.xxe-eians 1 r HYPNOS 5,6, 7/24 5/22/24 B, XXe-620017 ! THE FESTIVAL 1/ 25 12/1/24 B,XXe-6 5020l I THE STATU,IENT OF RANDOLPH GARTER 2/25 , 1/1/25 B,xxc- 658584 : I THE MUSIC OF EllICH ZAl'.'N 5/25 4/1/ 25 B,xxc-666644 i THE UNNAllABLE " 7/25 ' 6/1/25 B,nc- 668996 i I THE TEMPLE 9/ 25 8/1/25 B,XXc-668998 1 I i T'dE T01.lB 1/ 26 12/1/25 B,XXC!696158 i I THE GATS OF ULmAR 2/26 1/1/26 B,XXe-7C0191 i II" T'dE OUTSIDER 4/ 26 5/1/26 B,)'J[c-7C0195 ~ TIlE UOON- BOG 6/26 ' 5/1/26 B,XXe-700l94 ,, ; TilE TERRIBLE OLD 1.l1lN 6/26 7/1/26 B,xxc-745166 !, ~ HE I, 9/ 26 6/1/26 B,XXc-745167 i ..'1 r, T'rlE WHITE SHIP 5/27 2/1/27 BJxxc-760506 " "~ THE HORROR AT RED .HOOK 1/ 27 12/ 1/26 B,lXe-760504 ~ :: PIGKl.: AN 'S J!ODlI. -
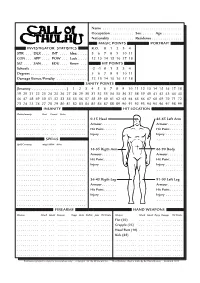
Call Character Sheetet
Name . Occupation . Sex. Age . R Nationality . Residence . MAGIC POINTS PORTRAIT INVESTIGATOR STATISTICS K.O. 0 1234 STR . DEX . INT . Idea . 567891011 CON . APP . POW . Luck . 12 13 14 15 16 17 18 SIZ . SAN . EDU. Know . HIT POINTS Schools . -2 -1 0 1 2 34 Degrees . 567891011 Damage Bonus/Penalty . 12 13 14 15 16 17 18 SANITY POINTS (Insanity . ) 123456789101112 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 INSANITY HIT LOCATION Phobia/Insanity Start Present Notes . 0-15 Head 46-65 Left Arm . Armour . Armour . Hit Point . Hit Point . Injury . Injury . SPELLS . Spell/Ceremony Magic/POW Notes . 16-35 Rigth Arm 66-90 Body . Armour . Armour . Hit Point . Hit Point . Injury . Injury . 36-45 Rigth Leg 91-00 Left Leg . Armour . Armour . Hit Point . Hit Point . Injury . Injury . FIREARMS HAND WEAPONS Weapon Attack Impale Damage Range Shots Bullets Jams Hit Points Weapon Attack Impale Parry Damage Hit Points . Fist (50) . Grapple (25) . Head Butt (10) . Kick (25) . Permission granted to copy for personal use only · copyright 1994 by Chaosium Inc. · This Character Sheet is made by Bo Hasle Nielsen · Denmark 1998 Players Name .