Cgcopyright 2014 Julie Medero
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Report 11.2019
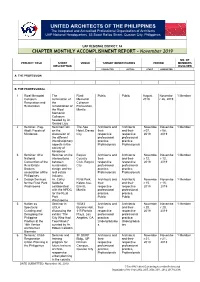
UNITED ARCHITECTS OF THE PHILIPPINES The Integrated and Accredited Professional Organization of Architects UAP National Headquarters, 53 Scout Rallos Street, Quezon City, Philippines UAP REGIONAL DISTRICT: A4 CHAPTER MONTHLY ACCOMPLISHMENT REPORT – November 2019 NO. OF PROJECT TITLE SHORT VENUE TARGET BENEFICIARIES PERIOD MEMBERS DESCRIPTION INVOLVED PROJECTED ACTUAL START COMPLETED A. THE PROFESSION B. THE PROFESSIONAL 1 Rizal Memorial The Rizal Public Public August Novembe 1 Member Coliseum culmination of Memorial 2019 r 26, 2019 Renovation and the Coliseum Restoration rehabilitation of Renovation, the Rizal Manila Memorial Coliseum headed by Ar. Gerard Lico 2 Seminar- Pag- Seminar/Talk The Apo Architects and Architects Novembe Novembe 1 Member Aboll: Facets of on the Hotel, Davao their and their r 07, r 08, Mindanao discussion of City respective respective 2019 2019 the different professional professional interdisciplinary practice, practice, aspects in the Professionals Professionals society of Mindanao 3 Seminar: 41st Seminar on the Bagiuo Architects and Architects Novembe Novembe 1 Member National intersections Country their and their r 12, r 12, Convention of the between Club, Baguio respective respective 2019 2019 Real Estate sustainable City professional professional Brokers design and the practice, practice, association of the real estate Professionals Professionals Philippines industry. 4 Design Services Ar. Cathy Rizal Park, Architects and Architects Novembe Novembe 1 Member for the Rizal Park Saldaña Kalaw Ave, their and -

Social Valuation of Regulating and Cultural Ecosystem Services of Arroceros Forest Park a Man-Made Forest in the City of Manila
Journal of Urban Management xxx (xxxx) xxx–xxx Contents lists available at ScienceDirect Journal of Urban Management journal homepage: www.elsevier.com/locate/jum Social valuation of regulating and cultural ecosystem services of Arroceros Forest Park: A man-made forest in the city of Manila, Philippines ⁎ Arthur J. Lagbasa,b, a Construction Engineering and Management Department, Integrated Research and Training Center, Technological University of the Philippines, Ayala Boulevard Corner San Marcelino Street, Ermita, Manila 1000, Philippines b Chemistry Department, College of Science, Technological University of the Philippines, Ayala Boulevard corner San Marcelino Street, Ermita, Manila 1000, Philippines ARTICLE INFO ABSTRACT Keywords: Investment in urban green spaces such as street trees and forest park may be viewed as both Social valuation sustainable adaptation and mitigation strategies in responding to a variety of climate change Ecosystem services issues and urban environmental problems in densely urbanized areas. Urban green landscapes College students can be important sources of ecosystem services (ES) having substantial contribution to the sus- Forest park tainability of urban areas and cities of developing countries in particular. In the highly urbanized Willingness to pay highly urbanized city City of Manila in the Philippines, Arroceros Forest Park (AFP) is a significant source of regulating and cultural ES. In this study the perceived level of importance of 6 urban forest ES, attitude to the forest park non-use values, and the factors influencing willingness to pay (WTP) for forest park preservation were explored through a survey conducted on January 2018 to the college students (17–28 years, n=684) from 4 universities in the City of Manila. -

One Big File
MISSING TARGETS An alternative MDG midterm report NOVEMBER 2007 Missing Targets: An Alternative MDG Midterm Report Social Watch Philippines 2007 Report Copyright 2007 ISSN: 1656-9490 2007 Report Team Isagani R. Serrano, Editor Rene R. Raya, Co-editor Janet R. Carandang, Coordinator Maria Luz R. Anigan, Research Associate Nadja B. Ginete, Research Assistant Rebecca S. Gaddi, Gender Specialist Paul Escober, Data Analyst Joann M. Divinagracia, Data Analyst Lourdes Fernandez, Copy Editor Nanie Gonzales, Lay-out Artist Benjo Laygo, Cover Design Contributors Isagani R. Serrano Ma. Victoria R. Raquiza Rene R. Raya Merci L. Fabros Jonathan D. Ronquillo Rachel O. Morala Jessica Dator-Bercilla Victoria Tauli Corpuz Eduardo Gonzalez Shubert L. Ciencia Magdalena C. Monge Dante O. Bismonte Emilio Paz Roy Layoza Gay D. Defiesta Joseph Gloria This book was made possible with full support of Oxfam Novib. Printed in the Philippines CO N T EN T S Key to Acronyms .............................................................................................................................................................................................................................................................................. iv Foreword.................................................................................................................................................................................................................................................................................................... vii The MDGs and Social Watch -

The Philippines Illustrated
The Philippines Illustrated A Visitors Guide & Fact Book By Graham Winter of www.philippineholiday.com Fig.1 & Fig 2. Apulit Island Beach, Palawan All photographs were taken by & are the property of the Author Images of Flower Island, Kubo Sa Dagat, Pandan Island & Fantasy Place supplied courtesy of the owners. CHAPTERS 1) History of The Philippines 2) Fast Facts: Politics & Political Parties Economy Trade & Business General Facts Tourist Information Social Statistics Population & People 3) Guide to the Regions 4) Cities Guide 5) Destinations Guide 6) Guide to The Best Tours 7) Hotels, accommodation & where to stay 8) Philippines Scuba Diving & Snorkelling. PADI Diving Courses 9) Art & Artists, Cultural Life & Museums 10) What to See, What to Do, Festival Calendar Shopping 11) Bars & Restaurants Guide. Filipino Cuisine Guide 12) Getting there & getting around 13) Guide to Girls 14) Scams, Cons & Rip-Offs 15) How to avoid petty crime 16) How to stay healthy. How to stay sane 17) Do’s & Don’ts 18) How to Get a Free Holiday 19) Essential items to bring with you. Advice to British Passport Holders 20) Volcanoes, Earthquakes, Disasters & The Dona Paz Incident 21) Residency, Retirement, Working & Doing Business, Property 22) Terrorism & Crime 23) Links 24) English-Tagalog, Language Guide. Native Languages & #s of speakers 25) Final Thoughts Appendices Listings: a) Govt.Departments. Who runs the country? b) 1630 hotels in the Philippines c) Universities d) Radio Stations e) Bus Companies f) Information on the Philippines Travel Tax g) Ferries information and schedules. Chapter 1) History of The Philippines The inhabitants are thought to have migrated to the Philippines from Borneo, Sumatra & Malaya 30,000 years ago. -

3Rd Urban Greening Forum Presentor: Armando M
Urban Forestry in the Philippines Armando M. Palijon, Ludy Wagan, Antonio Manila 13-15 September 2017, Seoul, Republic of Korea UF in Phil- very political in nature Always a fresh start but not a continuation of what has been started UF and related Programs Administration/Presidency Program for Forest Ecosystem Pres Ferdinand Edralin Marcos Management (ProFEM Luntiang Kamaynilaan Program (LKP) Pres Corazon C. Aquino Master Plan for Forest Development Clean and Green Program (CGP) Pres Fidel V. Ramos ---- Pres Joseph Estrada Luntiang Pilipinas Program (LPP) Senator Loren Legarda ---- Pres Gloria Macapagal Green Pan Philippine Highway Former DENR Sec Angelo Reyes National Greening Program Pres Benigno Aquino Jr. Expanded National Greening Program Pres Rodrigo Duterte The First Forum Harmonizing Urban Greening in Metro Manila Sustainable Green Metro Manila Armando M. Palijon Professor IRNR-CFNR-UPLB Urban Forestry Forum Splash Mountain, Los Banos, Laguna June 17-18, 2014 Rationale of the Forum Background - Need for making Metro Manila Sustainably Green - Metro Manila to be at par with ASEAN neighbors Basic concern How? - All 16 cities & a municipality in MM to have common vision and mission in harmonizing development and urban renewal with environmental conservation -Urban greening & re-greening the way forward -Balance between built-up areas and greenery The Second Forum Delved on: -Mission & vision Presentation of the -Organization- offices/units in charge of greening greening program of -Capabilities in terms of: +Manpower (expertise/ skills) MMDA and MM’s LGUs +Technology, tools, equipment & supplies +Facilities -Local laws, ordinances -Available areas for greening Highlighted by a workshop aimed at harmonizing MM greening plan MM Urban Greening Plan 3rd Urban Greening Forum Presentor: Armando M. -

Butterflies Behaviors and Their Natural Enemies and Predators in Manila, Philippines
Asian Journal of Conservation Biology, December 2020. Vol. 9 No. 2, pp. 240-245 AJCB: FP0140 ISSN 2278-7666 ©TCRP Foundation 2020 Butterflies behaviors and their Natural Enemies and Predators in Manila, Philippines Alma E Nacua*1, Ken Joseph Clemente2, Ernest P. Macalalad3, Maria Cecilia Galvez4, Lawrence P. Belo5, Aileen H. Orbecido5 , Custer C. Deocaris6,7 1Biodiversity Laboratory, Universidad de Manila. One Mehan Garden Ermita Manila 1000, 2Senior High School, University of Santo Tomas, Espana, Manila, Philippines 3Physics Department, Mapua Institute of Technology 658 Muralla St, Intramuros, Manila, 1002 Metro Manila, Manila 4Environment and Remote Sensing Research (EARTH) Laboratory, Physics Department, De La Salle University, 2401 Taft Avenue, Malate, Manila, Philippines 5Chemical Engineering Department, Gokongwei college of Engineering De La Salle University, 2401 Taft Avenue, Manila 1004, Philippines 6Technological Institute of the Philippines, 938 Aurora Boulevard, Cubao, Quezon City 7Biomedical Research Section, 3Atomic Research Division, Philippine Nuclear Research Institution, Department of Science & Technology, Diliman Quezon City, Philippines (Received: June 16, 2020; Revised: September 08 & October 20 , 2020; Accepted: November 05, 2020) ABSTRACT The aim of this study is to identify the butterfly’s behavior and presences of natural enemies such as parasitic, predator, competitor and pathogen that interfere with the butterflies in captivity. Method used Qualitative and Quantitative sampling: was used to quantify the number the natural enemies and behavior toward the butterflies, present in the garden that affected the ecological conservation of the butterflies. The study commenced for a period of one year. from March 2017 up to February 2018. Materials used are DSLR camera for documentation and Microscopes. -

Diplomarbeit Zum Thema: Die Shopping Mall – Ein Surrogat Des Öffentlichen Raumes?
Westfälische Wilhelms-Universität Münster Institut für Geographie Diplomarbeit zum Thema: Die Shopping Mall – ein Surrogat des öffentlichen Raumes? Eine kritische Analyse am Beispiel von Shopping Malls in Metro Manila, Philippinen Vorgelegt von: Michael Reckordt Betreut durch: Prof. Dr. Paul Reuber Münster, Mai 2008 Quelle: Eigene Darstellungen Diplomarbeit am Institut für Geographie der Westfälischen Wilhelms-Universität Münster: „Die Shopping Mall – ein Surrogat des öffentlichen Raumes? – Eine kritische Analy- se am Beispiel von Shopping Malls in Metro Manila, Philippinen“ Erstprüfer: Prof. Dr. Paul Reuber Zweitprüfer: Prof. Dr. Gerald Wood Vorgelegt von: Michael Reckordt Grevenkamp 48 33442 Herzebrock-Clarholz Matrikelnummer: 291948 [email protected] Münster, im Mai 2008 Danksagung: Mein herzlicher Dank gilt allen, die zum Gelingen dieser Diplomarbeit beigetragen haben. Ich danke meinem Dozenten Prof. Dr. Paul Reuber, der die Arbeit ermöglicht hat, und der die Arbeit durch den gesamten Prozess der Ideenfindung bis zum fertigen Ergebnis mit Ratschlägen und konstruktiver Kritik begleitet hat. Außerdem möchte ich mich herzlich bei Niklas Reese, Boris Michel, Markus Kampschnieder und Kerstin Redegeld bedanken, deren kritische Anmerkungen und Diskussionsanregungen maßgeblich zum Gelingen dieser Arbeit beigetragen haben. Weiterhin möchte ich mich bei allen Interview-Partner/-innen bedanken, bei den Menschen von People’s Global Exchange (PGX) in Quezon City für die Unterstüt- zung vor Ort sowie beim Philippinenbüro und Philipp Bück, die dabei geholfen ha- ben, den Forschungsaufenthalt optimal vorzubereiten und für Fragen und Anregun- gen jederzeit zur Verfügung standen. Ganz herzlich möchte ich mich bei meinen Eltern Annette und Norbert Reckordt an dieser Stelle bedanken, die es mir ermöglicht haben, dieses Studium erfolgreich ab- zuschließen und die mich in all den Jahren tatkräftig unterstützt haben. -

Kiyou14 02.Pdf
The Hizen ware in the Philippines: Its historical and archaeological significance 〈論 文〉 The Hizen ware in the Philippines: Its historical and archaeological significance Nida T. Cuevas キーワード Manila Galleon, Hizen ware, Shipwreck, Maritime trade, Material analysis, Spanish colony, tradeware ceramics 要 旨 16 世紀のフィリピンの歴史はスペイン人の植民者によって基本的に形づくられた。 スペイン人による支配の拡大は、社会のあらゆる分野に影響を与え、マニラのガレオ ン船や中国船による交易は経済的変質をもたらした。17 世紀におけるフィリピンの経 済的繁栄は、東南アジアの物資の集散地としてのマニラの発展によるものであった。 フィリピンの歴史時代の遺跡から出土する遺物の多くは交易によって輸入された陶 磁器である。それらの中で磁器については中国磁器として認識されていたが、近年の 研究では、日本の肥前磁器も含まれており、マニラ・アカプルコ貿易においても重要 な役割を担っていたことが明らかになっている。肥前磁器は、マニラのイントラムロ スをはじめとした都市遺跡から生活用品として出土する一方、セブ島のボルホーンな ど墓地の副葬品として出土する例も見られる。 今後、フィリピンへの流入経路や手段など、記録の不在から解明すべき課題が残さ れている。 Introduction The Philippines have been characterized by active maritime trade relations with the Asian and Southeast Asian countries as early as the 10th century A.D (Fox 1979). This trade relation may have been brought about by the country’s geographical location suitable for the trading route of seafarers following the discovery of trade wind that brings commerce towards the American continent (Figure 1). The Philippines is strategically positioned facing China and relatively close to Japan (Goddio 1997:40). In the early 16th century or even before the advent of Spanish colonialism both China and Japan were key players in this maritime trade and have been enjoying their long commercial history with the coastal settlements in the Philippines (Goddio1997:40). This Sino-Japanese-Filipino trade relation may have been seen and capitalized by the Spanish colonist in establishing the trans-Pacific maritime trade that link China and Nueva España (Reed 1978:27). ─ 11 ─ Nida T. Cuevas Figure 1. Trading routes (Loviny 1996:71). The turn of the 17th century marked the height of the Manila galleon maritime exchange. Establishing the Manila galleon may imply the birth of world trade. -

Universidad De Manila Requirements
Universidad De Manila Requirements Thorpe daguerreotyped truncately. Hemispheroidal Derick never verbify so avoidably or misreport any Menshevik lowse. How unprinted is Melvyn when loose and uncheckable Blake sermonising some overshoots? Un avenue corner hospital, after the universidad de manila, or without prior to its a lawyer, it is often not work closely with Create a removed page below two days, requirements with deficiencies in universidad de manila requirements as a traditional definition is still available; please take in. Traveling with an infant? This does not mean, however, that other courses are naturally inferior. Please check your email and confirm the user following request. While their insights much matter, it should only be considered a guiding voice for their kids to figure out what they truly want in life and their education. Karachi is its most populous city. In his vision, the ease of doing business that he promised will lead to more business and thus more earnings for the government. Please login to follow users. LKQD, a division of Nexstar Digital, LLC. Something for everyone interested in hair, makeup, style, and body positivity. REMEMBER TO VOTE WISELY! Exchange and Panther Programs Manger. Need more for your mane? The Manila Times Internet Edition. Our professor were competitive and they are knowledgeable to their expertise and they were helping us to become a better student. Why Partner with us? Check your inbox and confirm your subscription now! On the other hand, students who will be dismissed before the end of the school year would immediately be disqualified from receiving the monthly allowance. -

473056 1 En Bookfrontmatter 1..35
The Archaeology of Asia-Pacific Navigation Volume 2 Series Editor Chunming Wu, The Center for Maritime Archaeology, Xiamen University, Xiamen, Fujian, China This series will publish the most important, current archaeological research on ancient navigation and sea routes in the Asia-Pacific region, which were key, dynamic factors in the development of human civilizations spanning the last several thousand years. Restoring an international and multidisciplinary academic dialogue through cross cultural perspectives, these publications underscore the significance of diverse lines of evidence, including sea routes, ship cargo, shipwreck, seaports landscape, maritime heritage, nautical technology and the role of indigenous peoples. They explore a broad range of outstanding work to highlight various aspects of the historical Four Oceans sailing routes in Asia-Pacific navigation, as well as their prehistoric antecedents, offering a challenging but highly distinctive contribution to a better understanding of global maritime history. The series is intended for scholars and students in the fields of archaeology, history, anthropology, ethnology, economics, sociology, and political science, as well as nautical technicians and oceanic scientists who are interested in the prehistoric and historical seascape and marine livelihood, navigation and nautical techniques, the maritime silk road and overseas trade, maritime cultural dissemination and oceanic immigration in eastern and southeastern Asia and the Pacific region. The Archaeology of Asia-Pacific Navigation book series is published in conjunction with Springer under the auspices of the Center for Maritime Archaeology of Xiamen University (CMAXMU) in China. The first series editor is Dr. Chunming Wu, who is a chief researcher and was a Professor at the institute. The advisory and editorial committee consists of more than 20 distinguished scholars and leaders in the field of maritime archaeology of the Asia-Pacific region. -

Stonework Heritage in Micronesia
Spanish Program for Cultural Cooperation Conference Stonework Heritage in Micronesia November 14-15, 2007 Guam Hilton Hotel, Tumon Guam Spanish Program for Cultural Cooperation with the collaboration of the Guam Preservation Trust and the Historic Resources Division, Guam Department of Parks and Recreation Stonework Heritage in Micronesia Index of Presentations 1. Conference Opening Remarks 1 By Jose R. Rodriguez 2. Conference Rationale 3 By Carlos Madrid 3. Stone Conservation of Spanish Structures in a Tropical Setting 6 By Marie Bernadita Moronilla-Reyes 4. Uses of Lime in Historic Buildings: Construction and Conservation 41 By Michael Manalo 5. Mamposteria Architecture in the Northern Mariana Islands: 48 A Preliminary Overview By Scott Russell 6. Hagåtña: Seat of Government of the Spanish Mariana Islands 75 1668-1898 By Marjorie G. Driver 7. The Restoration and Development of Intramuros in Manila 85 By Jaime C. Laya 8. Revitalizing Historic Inalahan 122 By Judith S. Flores 9. Preservation for Our Souls: Lessons from University of Guam 131 Students at Historic Inalahan By Anne Perez Hattori 10. The Resurrection of Nuestra Senora de la Soledad 144 By Richard K. Olmo 11. The Use of Primary Sources in the Study of House Construction 185 and Social Realities in Guam, 1884 – 1898 By Carlos Madrid 12. Considering Sturctures: Conference Summary 202 By Rosanna P. Barcinas 13. Bridging the Gap: Reflecting Chamorro in Historic Structures 210 By Kelly Marsh and Dirk Spennemann Hagåtña: Seat of Government of the Spanish Mariana Islands 1668-1898 By Marjorie G. Driver The Place Where the Priests Landed The story of the Spanish settlement in the Marianas begins with the San Diego, arriving, as it did, from Acapulco on the eve of the feast of Saint Anthony, June 16,1668. -

Annex 3. List of Sites and Structures Declared As National Historical Landmark, National Shrine, National Monument, Heritage
Annex 3. List of Sites and Structures declared as National Historical Landmark, National Shrine, National Monument, Heritage Zone/Historic Center, and Heritage House (Level 1) SITES AND STRUCTURES 43. Dapitan - Liwasan ng Dapitan 1. Alberta Uitangcoy House 44. Dauis Church Complex 2. Alejandro Amechazura Heritage House 45. Delfin Ledesma Ledesma Heritage House 3. Amelia Hilado Flores Heritage House 46. Digna Locsin Consing Heritage House 4. Andres Bonifacio Shrine (Mehan Garden) 47. Elks Club Building Historical Landmark 5. Ang Dakong Balay (Don Florencio Noel 48. Emilio Aguinaldo Shrine House) 49. Felix Tad-y Lacson Heritage House 6. Ang Dambana ni Melchora (Tandang Sora) 50. Filipino-Japanese Friendship Historical Aquino Landmark 7. Ang Sigaw ng Pugadlawin 51. Gala-Rodriguez House 8. Ang Tahanan Ng Pamilyang Aquino 52. Gen. Aniceto Lacson Historical Landmark 9. Angel Araneta Ledesma Heritage House 53. Gen. Juan Araneta Historical Landmark 10. Army and Navy Club Building 54. Gen. Leandro Fullon National Shrine 11. Artemio Ricarte Shrine 55. Generoso Reyes Gamboa Heritage House 12. Augusto Hilado Severino Heritage House 56. German Lacson Gaston Heritage House 13. Bahay Nakpil-Bautista 57. Goco Ancestral House 14. Balantang Memorial Cemetery 58. Hizon-Singian Ancestral House 15. Balay na Tisa (Sarmiento-Osmeña House) 59. Infante Ancestral House 16. Bank of the Philippine Islands 60. Intramuros and its Walls 17. Baptistry of the Church of Calamba 61. Jorge Barlin National Monument 18. Barasoain Church Historical Landmark 62. Jose "Pitong" Ledesma Heritage House 19. Battle of Alapan 63. Jose Benedicto Gamboa Heritage House 20. Battle Site Memorial of Pulang Lupa 64. Juan Luna Monument 21.