Once More on the Language of the Documents from Niya (East Turkestan) and Its Genetic Position
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Grammatical Gender in Hindukush Languages
Grammatical gender in Hindukush languages An areal-typological study Julia Lautin Department of Linguistics Independent Project for the Degree of Bachelor 15 HEC General linguistics Bachelor's programme in Linguistics Spring term 2016 Supervisor: Henrik Liljegren Examinator: Bernhard Wälchli Expert reviewer: Emil Perder Project affiliation: “Language contact and relatedness in the Hindukush Region,” a research project supported by the Swedish Research Council (421-2014-631) Grammatical gender in Hindukush languages An areal-typological study Julia Lautin Abstract In the mountainous area of the Greater Hindukush in northern Pakistan, north-western Afghanistan and Kashmir, some fifty languages from six different genera are spoken. The languages are at the same time innovative and archaic, and are of great interest for areal-typological research. This study investigates grammatical gender in a 12-language sample in the area from an areal-typological perspective. The results show some intriguing features, including unexpected loss of gender, languages that have developed a gender system based on the semantic category of animacy, and languages where this animacy distinction is present parallel to the inherited gender system based on a masculine/feminine distinction found in many Indo-Aryan languages. Keywords Grammatical gender, areal-typology, Hindukush, animacy, nominal categories Grammatiskt genus i Hindukush-språk En areal-typologisk studie Julia Lautin Sammanfattning I den här studien undersöks grammatiskt genus i ett antal språk som talas i ett bergsområde beläget i norra Pakistan, nordvästra Afghanistan och Kashmir. I området, här kallat Greater Hindukush, talas omkring 50 olika språk från sex olika språkfamiljer. Det stora antalet språk tillsammans med den otillgängliga terrängen har gjort att språken är arkaiska i vissa hänseenden och innovativa i andra, vilket gör det till ett intressant område för arealtypologisk forskning. -

(And Potential) Language and Linguistic Resources on South Asian Languages
CoRSAL Symposium, University of North Texas, November 17, 2017 Existing (and Potential) Language and Linguistic Resources on South Asian Languages Elena Bashir, The University of Chicago Resources or published lists outside of South Asia Digital Dictionaries of South Asia in Digital South Asia Library (dsal), at the University of Chicago. http://dsal.uchicago.edu/dictionaries/ . Some, mostly older, not under copyright dictionaries. No corpora. Digital Media Archive at University of Chicago https://dma.uchicago.edu/about/about-digital-media-archive Hock & Bashir (eds.) 2016 appendix. Lists 9 electronic corpora, 6 of which are on Sanskrit. The 3 non-Sanskrit entries are: (1) the EMILLE corpus, (2) the Nepali national corpus, and (3) the LDC-IL — Linguistic Data Consortium for Indian Languages Focus on Pakistan Urdu Most work has been done on Urdu, prioritized at government institutions like the Center for Language Engineering at the University of Engineering and Technology in Lahore (CLE). Text corpora: http://cle.org.pk/clestore/index.htm (largest is a 1 million word Urdu corpus from the Urdu Digest. Work on Essential Urdu Linguistic Resources: http://www.cle.org.pk/eulr/ Tagset for Urdu corpus: http://cle.org.pk/Publication/papers/2014/The%20CLE%20Urdu%20POS%20Tagset.pdf Urdu OCR: http://cle.org.pk/clestore/urduocr.htm Sindhi Sindhi is the medium of education in some schools in Sindh Has more institutional backing and consequent research than other languages, especially Panjabi. Sindhi-English dictionary developed jointly by Jennifer Cole at the University of Illinois Urbana- Champaign and Sarmad Hussain at CLE (http://182.180.102.251:8081/sed1/homepage.aspx). -

Linguistics Development Team
Development Team Principal Investigator: Prof. Pramod Pandey Centre for Linguistics / SLL&CS Jawaharlal Nehru University, New Delhi Email: [email protected] Paper Coordinator: Prof. K. S. Nagaraja Department of Linguistics, Deccan College Post-Graduate Research Institute, Pune- 411006, [email protected] Content Writer: Prof. K. S. Nagaraja Prof H. S. Ananthanarayana Content Reviewer: Retd Prof, Department of Linguistics Osmania University, Hyderabad 500007 Paper : Historical and Comparative Linguistics Linguistics Module : Indo-Aryan Language Family Description of Module Subject Name Linguistics Paper Name Historical and Comparative Linguistics Module Title Indo-Aryan Language Family Module ID Lings_P7_M1 Quadrant 1 E-Text Paper : Historical and Comparative Linguistics Linguistics Module : Indo-Aryan Language Family INDO-ARYAN LANGUAGE FAMILY The Indo-Aryan migration theory proposes that the Indo-Aryans migrated from the Central Asian steppes into South Asia during the early part of the 2nd millennium BCE, bringing with them the Indo-Aryan languages. Migration by an Indo-European people was first hypothesized in the late 18th century, following the discovery of the Indo-European language family, when similarities between Western and Indian languages had been noted. Given these similarities, a single source or origin was proposed, which was diffused by migrations from some original homeland. This linguistic argument is supported by archaeological and anthropological research. Genetic research reveals that those migrations form part of a complex genetical puzzle on the origin and spread of the various components of the Indian population. Literary research reveals similarities between various, geographically distinct, Indo-Aryan historical cultures. The Indo-Aryan migrations started in approximately 1800 BCE, after the invention of the war chariot, and also brought Indo-Aryan languages into the Levant and possibly Inner Asia. -

Languages of Kohistan. Sociolinguistic Survey of Northern
SOCIOLINGUISTIC SURVEY OF NORTHERN PAKISTAN VOLUME 1 LANGUAGES OF KOHISTAN Sociolinguistic Survey of Northern Pakistan Volume 1 Languages of Kohistan Volume 2 Languages of Northern Areas Volume 3 Hindko and Gujari Volume 4 Pashto, Waneci, Ormuri Volume 5 Languages of Chitral Series Editor Clare F. O’Leary, Ph.D. Sociolinguistic Survey of Northern Pakistan Volume 1 Languages of Kohistan Calvin R. Rensch Sandra J. Decker Daniel G. Hallberg National Institute of Summer Institute Pakistani Studies of Quaid-i-Azam University Linguistics Copyright © 1992 NIPS and SIL Published by National Institute of Pakistan Studies, Quaid-i-Azam University, Islamabad, Pakistan and Summer Institute of Linguistics, West Eurasia Office Horsleys Green, High Wycombe, BUCKS HP14 3XL United Kingdom First published 1992 Reprinted 2002 ISBN 969-8023-11-9 Price, this volume: Rs.300/- Price, 5-volume set: Rs.1500/- To obtain copies of these volumes within Pakistan, contact: National Institute of Pakistan Studies Quaid-i-Azam University, Islamabad, Pakistan Phone: 92-51-2230791 Fax: 92-51-2230960 To obtain copies of these volumes outside of Pakistan, contact: International Academic Bookstore 7500 West Camp Wisdom Road Dallas, TX 75236, USA Phone: 1-972-708-7404 Fax: 1-972-708-7433 Internet: http://www.sil.org Email: [email protected] REFORMATTING FOR REPRINT BY R. CANDLIN. CONTENTS Preface............................................................................................................viii Maps................................................................................................................. -

Language Documentation and Description
Language Documentation and Description ISSN 1740-6234 ___________________________________________ This article appears in: Language Documentation and Description, vol 17. Editor: Peter K. Austin Countering the challenges of globalization faced by endangered languages of North Pakistan ZUBAIR TORWALI Cite this article: Torwali, Zubair. 2020. Countering the challenges of globalization faced by endangered languages of North Pakistan. In Peter K. Austin (ed.) Language Documentation and Description 17, 44- 65. London: EL Publishing. Link to this article: http://www.elpublishing.org/PID/181 This electronic version first published: July 2020 __________________________________________________ This article is published under a Creative Commons License CC-BY-NC (Attribution-NonCommercial). The licence permits users to use, reproduce, disseminate or display the article provided that the author is attributed as the original creator and that the reuse is restricted to non-commercial purposes i.e. research or educational use. See http://creativecommons.org/licenses/by-nc/4.0/ ______________________________________________________ EL Publishing For more EL Publishing articles and services: Website: http://www.elpublishing.org Submissions: http://www.elpublishing.org/submissions Countering the challenges of globalization faced by endangered languages of North Pakistan Zubair Torwali Independent Researcher Summary Indigenous communities living in the mountainous terrain and valleys of the region of Gilgit-Baltistan and upper Khyber Pakhtunkhwa, northern -

Proposal for Generation Panel for Sinhala Script Label
Proposal for the Generation Panel for the Sinhala Script Label Generation Ruleset for the Root Zone 1 General information Sinhala belongs to the Indo-European language family with its roots deeply associated with Indo-Aryan sub family to which the languages such as Persian and Hindi belong. Although it is not very clear whether people in Sri Lanka spoke a dialect of Prakrit at the time of arrival of Buddhism in the island, there is enough evidence that Sinhala evolved from mixing of Sanskrit, Magadi (the language which was spoken in Magada Province of India where Lord Buddha was born) and local language which was spoken by people of Sri Lanka prior to the arrival of Vijaya, the founder of Sinhala Kingdom. It is also surmised that Sinhala had evolved from an ancient variant of Apabramsa (middle Indic) which is known as ‘Elu’. When tracing history of Elu, it was preceded by Hela or Pali Sihala. Sinhala though has close relationships with Indo Aryan languages which are spoken primarily in the north, north eastern and central India, was very much influenced by Tamil which belongs to the Dravidian family of languages. Though Sinhala is related closely to Indic languages, it also has its own unique characteristics: Sinhala has symbols for two vowels which are not found in any other Indic languages in India: ‘æ’ (ඇ) and ‘æ:’ (ඈ). Sinhala script had evolved from Southern Brahmi script from which almost all the Southern Indic Scripts such as Telugu and Oriya had evolved. Later Sinhala was influenced by Pallava Grantha writing of Southern India. -

A Grammatical Description of Dameli
Emil Perder A Grammatical Description of Dameli Emil Perder A Grammatical Description of Dameli A Grammatical ISBN 978-91-7447-770-2 Department of Linguistics Doctoral Thesis in Linguistics at Stockholm University, Sweden 2013 A Grammatical Description of Dameli Emil Perder A Grammatical Description of Dameli Emil Perder ©Emil Perder, Stockholm 2013 ISBN 978-91-7447-770-2 Printed in Sweden by Universitetsservice AB, Stockholm 2013 Distributor: Department of Linguistics, Stockholm University ماں َتارف تہ ِاک توحفہ، دامیاں A gift from me, Dameli people Abstract This dissertation aims to provide a grammatical description of Dameli (ISO-639-3: dml), an Indo-Aryan language spoken by approximately 5 000 people in the Domel Valley in Chitral in the Khyber Pakhtunkhwa Province in the North-West of Pakistan. Dameli is a left-branching SOV language with considerable morphological complexity, particularly in the verb, and a complicated system of argument marking. The phonology is relatively rich, with 31 consonant and 16 vowel phonemes. This is the first extensive study of this language. The analysis presented here is based on original data collected primarily between 2003-2008 in cooperation with speakers of the language in Peshawar and Chitral, including the Domel Valley. The core of the data consists of recorded texts and word lists, but questionnaires and paradigms of word forms have also been used. The main emphasis is on describing the features of the language as they appear in texts and other material, rather than on conforming them to any theory, but the analysis is informed by functional analysis and linguistic typology, hypotheses on diachronical developments and comparisons with neighbouring and related languages. -

Andrew Ollett, Language of the Snakes. Prakrit, Sanskrit, and the Language Order of Premodern India
Cracow Indological Studies Vol. XIX, No. 2 (2017) https://doi.org/10.12797/CIS.19.2017.02.06 Andrew Ollett, Language of the Snakes. Prakrit, Sanskrit, and the Language Order of Premodern India . pp. 290. Oakland: University of California Press. October 2017.—Reviewed by Lidia Wojtczak (SOAS, University of London). $QGUHZ2OOHWW¶VERRNSXEOLVKHGLQ2FWREHUFRQVWLWXWHVDUHYLVHG YHUVLRQ RI KLV 'RFWRUDO 7KHVLV RI 7KH ³ELRJUDSK\ RI 3UDNULW IURPWKHSHUVSHFWLYHRIFXOWXUDOKLVWRU\´ S LVDEROGVWDWHPHQWRI WKHDXWKRU¶VGHGLFDWLRQWRDFORVHDQGVHQVLWLYHUHDGLQJRIWKHOLWHUDWXUH RI SUHPRGHUQ 6RXWK$VLD7KH ERRN LV GLYLGHG LQWR VHYHQ FKDSWHUV HDFK D IDUUHDFKLQJ DQG LQGHSWK DQDO\VLV RI 3UDNULW¶V LPSDFW RQ and interactions with, the literary culture of early India. The volume LV VXSSOHPHQWHG E\ WKUHH YDOXDEOH DQG LOOXPLQDWLQJ DSSHQGLFHV DQG E\ FRSLRXV QRWHV ZKLFK EULQJ RXW WKH DXWKRU¶V HUXGLWH DSSURDFK WRWKHVXEMHFWPDWWHU 2OOHWW SRVLWV WKDW 3UDNULW LV WKH ³NH\ WR XQGHUVWDQGLQJ KRZ literary languages worked in premodern India as a whole and it pro- YLGHV DQ DOWHUQDWLYH ZD\ RI WKLQNLQJ DERXW ODQJXDJH´ S $V KHH[SODLQV3UDNULW¶VSODFHLQWKHLQWHUDFWLYHOLQJXLVWLFIUDPHZRUNRI ,QGLDDWWKHEHJLQQLQJRIWKH&RPPRQ(UD2OOHWWGLVWDQFHVKLPVHOI IURP PRGHUQ GLVFXVVLRQV RQ ZKDW VWDQGV EHKLQG WKH WHUP µ3UDNULW¶ DV RSSRVHG WR µ0LGGOH ,QGLF¶ DQG LQVWHDG ORRNV IRU KLV GH¿QLWLRQ LQSUHPRGHUQVRXUFHV3UDNULWKHWHOOVXV³LVZKDW3UDNULWWH[WVWHOOXV they are written in”, and most generally, it is “the language of literary WH[WVFRPSRVHGLQWKH¿UVWKDOIRIWKH¿UVWPLOOHQQLXP&(´ S 118 Cracow Indological Studies ,W ZDV D ³FODVVLFDO´ ODQJXDJH LQ PDQ\ VHQVHV RI WKH ZRUG²3UDNULW WH[WVZHUHMXGJHGFODVVLFDOE\WKHSHRSOHUHDGLQJWKHPIURPWKHEHJLQ - ning of the Common Era and the language was cultivated as a mark- HU RI ³LQWHOOHFWXDO FXOWXUH´ QRW RQO\ LQ ,QGLD EXW DFURVV 6RXWK DQG South-East Asia (p. 9). Literature was foundational to the formation of the “Sanskrit Cosmopolis”—the supra-regional, socio-political, and cultural order WKDW 6KHOGRQ 3ROORFN KDV LGHQWL¿HG DV H[LVWLQJ LQ WKH ¿UVW PLOOHQ nium CE. -
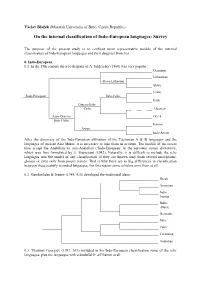
Internal Classification of Indo-European Languages: Survey
Václav Blažek (Masaryk University of Brno, Czech Republic) On the internal classification of Indo-European languages: Survey The purpose of the present study is to confront most representative models of the internal classification of Indo-European languages and their daughter branches. 0. Indo-European 0.1. In the 19th century the tree-diagram of A. Schleicher (1860) was very popular: Germanic Lithuanian Slavo-Lithuaian Slavic Celtic Indo-European Italo-Celtic Italic Graeco-Italo- -Celtic Albanian Aryo-Graeco- Greek Italo-Celtic Iranian Aryan Indo-Aryan After the discovery of the Indo-European affiliation of the Tocharian A & B languages and the languages of ancient Asia Minor, it is necessary to take them in account. The models of the recent time accept the Anatolian vs. non-Anatolian (‘Indo-European’ in the narrower sense) dichotomy, which was first formulated by E. Sturtevant (1942). Naturally, it is difficult to include the relic languages into the model of any classification, if they are known only from several inscriptions, glosses or even only from proper names. That is why there are so big differences in classification between these scantily recorded languages. For this reason some scholars omit them at all. 0.2. Gamkrelidze & Ivanov (1984, 415) developed the traditional ideas: Greek Armenian Indo- Iranian Balto- -Slavic Germanic Italic Celtic Tocharian Anatolian 0.3. Vladimir Georgiev (1981, 363) included in his Indo-European classification some of the relic languages, plus the languages with a doubtful IE affiliation at all: Tocharian Northern Balto-Slavic Germanic Celtic Ligurian Italic & Venetic Western Illyrian Messapic Siculian Greek & Macedonian Indo-European Central Phrygian Armenian Daco-Mysian & Albanian Eastern Indo-Iranian Thracian Southern = Aegean Pelasgian Palaic Southeast = Hittite; Lydian; Etruscan-Rhaetic; Elymian = Anatolian Luwian; Lycian; Carian; Eteocretan 0.4. -

RJSSER ISSN 2707-9015 (ISSN-L) Research Journal of Social DOI: Sciences & Economics Review ______
Research Journal of Social Sciences & Economics Review Vol. 1, Issue 4, 2020 (October – December) ISSN 2707-9023 (online), ISSN 2707-9015 (Print) RJSSER ISSN 2707-9015 (ISSN-L) Research Journal of Social DOI: https://doi.org/10.36902/rjsser-vol1-iss4-2020(411-417) Sciences & Economics Review ____________________________________________________________________________________ Interplay between Socio-Economic Factors and Language Shift: A Study of Saraiki Language in D.G. Khan * Ghulam Mujtaba Yasir, PhD Scholar (Corresponding Author) ** Prof. Dr. Mamuna Ghani, Ex-Dean __________________________________________________________________________________ Abstract Pakistan is among those very few multicultural and multilingual countries which are celebrated for their ethnic as well as linguistic diversity. From the coastal areas of Karachi to the mountainous terrain of Gilgit Baltistan six major and more than 70 minor languages are spoken in various parts of Pakistan. Urdu relishes the position of National Language whereas the official language of the country is English and is mostly used by the power-wielding strata of the country namely the government functionaries, corporate sector, and education sector. The purpose of the study was to find out the interplay between socioeconomic factors and the phenomenon of language shift. The present research is descriptive in which 300 Urdu speaking children of Saraiki families of D.G. Khan District were selected for data collection. A multiple-choice questionnaire was devised and administered to collect the required data. The results insinuated a strong interplay between socio- economic factors and the language shift. Keywords: Linguistic Diversity, Multilingualism, Socio-Economic Factors, Language Shift, Saraiki Language Introduction Language shift, also termed as language transfer, language replacement, and language assimilation, is such a situation where the members of one speech community functionally abandon one language and shift to another socially prestigious language, not necessarily by conscious choice (Garret 2006). -

THE PHONOLOGY of the VERBAL PHRASE in HINDKO Submitted By
THE PHONOLOGY OF THE VERBAL PHRASE IN HINDKO submitted by ELAHI BAKHSH AKHTAR AWAN FOR THE AWARD OF A DEGREE OF Ph.D. at the UNIVERSITY OF LONDON 1974 ProQuest Number: 10672820 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a com plete manuscript and there are missing pages, these will be noted. Also, if material had to be removed, a note will indicate the deletion. uest ProQuest 10672820 Published by ProQuest LLC(2017). Copyright of the Dissertation is held by the Author. All rights reserved. This work is protected against unauthorized copying under Title 17, United States C ode Microform Edition © ProQuest LLC. ProQuest LLC. 789 East Eisenhower Parkway P.O. Box 1346 Ann Arbor, Ml 48106- 1346 acknowledgment I wish to express my profound sense of gratitude and indebtedness to my supervisor Dr. R.K. Sprigg. But for his advice, suggestions, constructive criticism and above all unfailing kind ness at all times this thesis could not have been completed. In addition, I must thank my wife Riaz Begum for her help and encouragement during the many months of preparation. CONTENTS Introduction i Chapter I Value of symbols used in this thesis 1 1 .00 Introductory 1 1.10 I.P.A. Symbols 1 1.11 Other symbols 2 Chapter II The Verbal Phrase and the Verbal Word 6 2.00 Introductory 6 2.01 The Sentence 6 2.02 The Phrase 6 2.10 The Verbal Phra.se 7 2.11 Delimiting the Verbal Phrase 7 2.12 Place of the Verbal Phrase 7 2.121 -

On Corresponding Sanskrit Words for the Prakrit Term Posaha: with Special Reference to Śrāvakācāra Texts
International Journal of Jaina Studies (Online) Vol. 13, No. 2 (2017) 1-17 ON CORRESPONDING SANSKRIT WORDS FOR THE PRAKRIT TERM POSAHA: WITH SPECIAL REFERENCE TO ŚRĀVAKĀCĀRA TEXTS Kazuyoshi Hotta 1. Introduction In Brahmanism, the upavasathá purification rite has been practiced on the day prior to the performance of a Vedic ritual. We can find descriptions of this purification rite in Brahmanical texts, such as ŚBr 1.1.1.7, which states as follows. For assuredly, (he argued,) the gods see through the mind of man; they know that, when he enters on this vow, he means to sacrifice to them the next morning. Therefore all the gods betake themselves to his house, and abide by (him or the fires, upa-vas) in his house; whence this (day) is called upa-vasatha (Tr. Eggeling 1882: 4f.).1 This rite was then incorporated into Jainism and Buddhism in different ways, where it is known under names such as posaha or uposatha in Prakrit and Pāli. Buddhism adopted and developed the rite mainly as a ritual for mendicants. Many descriptions of this rite can be found in Buddhist vinaya texts. Furthermore, this rite is practiced until today throughout Buddhist Asia. On the other hand, Jainism has employed the rite mainly as a practice for the laity. Therefore, descriptions of Jain posaha are found in the group of texts called Śrāvakācāra, which contain the code of conduct for the laity. There are many forms of Śrāvakācāra texts. Some are independent texts, while others form part of larger works. Many of them consist mainly of the twelve vrata (restraints) and eleven pratimā (stages of renunciation) that should be observed by * This paper is an expanded version of Hotta 2014 and the contents of a paper delivered at the 19th Jaina Studies Workshop, “Jainism and Buddhism” (18 March 2017, SOAS).