Annotated Table of Contents Links
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Changing Shape of the Computing World
Outside the Box — The Changing Shape of the Computing World Steve Cunningham Computer Science California State University Stanislaus Turlock, CA 95382 [email protected] http://www.cs.csustan.edu/~rsc Something happened to computing while many of us were busy practicing or teaching our craft, and computing is not quite the same thing we learned. We can ignore this change and others will take our place and teach about it, but they will not have the context and the skill to understand the technology behind it and to carry it forward to the success it should have. And if others carry that torch, computer science will be stunted because we didn't recognize and respond to the opportunity. What happened? Simply this—that Xerox and Apple and, yes, Microsoft opened up the box labeled “CAUTION: Computer Inside” and let the user into the computing picture. Users responded hesitantly but increasingly eagerly and now expect the computer to work for them instead of their working for the computer. Every application now in wide use, and any system that supports a general market, has evolved to meet that expectation. Any computing education that does not pay attention to the user’s role in computing is missing the most vibrant and exciting part of computing today. As it says at the top of this page, you are reading an editorial, not an academic paper. As an editorial, this note represents my personal passion and commitment to the user communication part of computing that the “official” computing establishment has long discounted, and I appreciate John Impagliazzo’s offer of this forum to make my case that computer science is missing the boat in not understanding the need to reshape computer science education to fill this void. -

SIGCHI Conferences Report for Members May 2018
SIGCHI Conferences Report " ! " ! " May 22, 2018 SIGCHI (Special Interest Group on Computer-Human Interaction) is led by the SIGCHI Executive committee and one of the appointed roles on this committee is the ACM SIGCHI Vice President for Conferences. This person is responsible for overseeing all aspects of SIGCHI-sponsored conferences and SIGCHI currently sponsors 24 conferences. www.si In addition to the annual CHI conference, the Specialised Conferences program of ACM SIGCHI has gradually evolved and has now become a significant part of the conference program that is offered to the HCI community at large. Across our conferences we have over 9,000 delegates attend our 24 conferences, with around 3000 of these attending CHI. This program includes all conferences involving ACM SIGCHI other than the annual CHI conferences. Throughout this report there are references to Specialised Conferences (e.g. Group to VRST) and CHI. Each conference has a steering committee and the chair of each steering committee serves on the ACM SIGCHI Council of Steering Committee Chairs. In addition we have an Adjunct Chair for CHI on the SIGCHI EC along with a SIGCHI Conference Board which works with the ACM SIGCHI VP for Conferences. The CHI Steering Committee oversees the activities of all CHI conference committee chairs from CHI 2018 onwards. It ensures that the objectives of the conference as established by the Steering Committee and EC are met. The CHI Steering Committee was created by SIGCHI Executive Committee in 2016. From CHI 2018 onwards, this committee serves as a focal point for communications between the conference committee, CHI attendees, CHI committees, CHI vendors, CHI liaison, SIGCHI and the SIGCHI Services Staff. -

Dronepaint: Swarm Light Painting with DNN-Based Gesture Recognition
DronePaint: Swarm Light Painting with DNN-based Gesture Recognition Valerii Serpiva Ekaterina Karmanova Aleksey Fedoseev Skolkovo Institute of Science and Skolkovo Institute of Science and Skolkovo Institute of Science and Technology Technology Technology Moscow, Russia Moscow, Russia Moscow, Russia [email protected] [email protected] [email protected] Stepan Perminov Dzmitry Tsetserukou Skolkovo Institute of Science and Skolkovo Institute of Science and Technology Technology Moscow, Russia Moscow, Russia [email protected] [email protected] Figure 1: a) View of user screen. Drawing trajectory by hand and gesture recognition. b) Long exposure light painting of “Siggraph" logo by drone. c) Single swarm agent with the LED circle. ABSTRACT trajectory patterns. The proposed system can be potentially applied We propose a novel human-swarm interaction system, allowing the in complex environment exploration, spray painting using drones, user to directly control a swarm of drones in a complex environment and interactive drone shows, allowing users to create their own art through trajectory drawing with a hand gesture interface based on objects by drone swarms. the DNN-based gesture recognition. The developed CV-based system allows the user to control the CCS CONCEPTS swarm behavior without additional devices through human ges- • Human-centered computing ! Human-computer interac- tures and motions in real-time, providing convenient tools to change tion (HCI). the swarm’s shape and formation. -

Elizabeth Baron Candidate for Director a As an ACM SIGGRAPH
Elizabeth Baron Candidate for Director A As an ACM SIGGRAPH Pioneer, implementing computer graphics and interactive techniques, I relied on SIGGRAPH for inspiration on how to apply CG & IT in novel ways. I was taught how to bring art, engineering and science to life through expressive, realistic and accurate experiences. Believing it is important to give back to an organization that has given so much, I am honored to be considered to serve as a Director-at-Large. Over the past two years I have avidly participated in the ACM SIGGRAPH Executive Committee Strategy Team sessions. The team has made impressive, significant changes to increase our relevancy. I believe that to grow both the conference and the organization, we must bridge the gap between research and industry practitioners. ACM SIGGRAPH can influence the practical and innovative application of CG & IT methods, products, services and systems for industry. We can be involved in industry. As SFX become physics-based, the importance and accuracy of many types of simulations are as appropriate and useful for media and entertainment as well as for industry. We can learn from each other. ACM SIGGRAPH has inspired the CG & IT industry and practitioners around the world. I want to be a part of growing the outstanding legacy SIGGRAPH has created to enable everyone to tell their stories. BIOGRAPHY Elizabeth Baron is Vice President of Immersive Solutions for Silverdraft Supercomputing. She has been the driving force in the development and deployment of global, collaborative immersive paradigms for industrial design and engineering. Formerly, Elizabeth was a Technical Specialist in Immersive Realities at Ford Motor Company. -
Surveymonkey Analyze
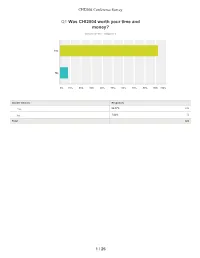
CHI2004 Conference Survey Q1 Was CHI2004 worth your time and money? Answered: 920 Skipped: 3 Yes No 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% Answer Choices Responses Yes 92.17% 848 No 7.83% 72 Total 920 1 / 25 CHI2004 Conference Survey Opening Plenary CHI Fringe Demonstrations Design Expo Development Consortium Doctoral Consortium Exhibits HCI Overviews Informal SIGs Other Special Sessions Panel Sessions Paper Sessions Posters Short Talks SIGs Student Competition Tutorials Workshops Closing Plenary 0 1 2 3 4 5 6 7 8 9 10 2 / 25 CHI2004 Conference Survey Poor Fair Neutral Good Excellent Didn't attend Total Weighted Average Opening Plenary 2.50% 6.74% 10.33% 39.89% 19.89% 20.65% 23 62 95 367 183 190 920 3.86 CHI Fringe 0.76% 2.07% 6.09% 14.78% 9.02% 67.28% 7 19 56 136 83 619 920 3.89 Demonstrations 0.43% 4.02% 12.72% 32.93% 7.50% 42.39% 4 37 117 303 69 390 920 3.75 Design Expo 0.76% 2.50% 8.37% 19.78% 7.83% 60.76% 7 23 77 182 72 559 920 3.80 Development Consortium 0.11% 0.22% 2.61% 3.48% 0.65% 92.93% 1 2 24 32 6 855 920 3.62 Doctoral Consortium 0.11% 0.11% 2.72% 1.63% 2.28% 93.15% 1 1 25 15 21 857 920 3.86 Exhibits 1.52% 6.20% 22.17% 39.78% 5.33% 25.00% 14 57 204 366 49 230 920 3.55 HCI Overviews 0.65% 3.26% 8.37% 20.22% 4.46% 63.04% 6 30 77 186 41 580 920 3.66 Informal SIGs 0.33% 2.07% 5.33% 10.76% 3.91% 77.61% 3 19 49 99 36 714 920 3.71 Other Special Sessions 0.54% 1.20% 5.00% 14.78% 6.52% 71.96% 5 11 46 136 60 662 920 3.91 Panel Sessions 3.04% 5.22% 12.83% 26.85% 8.70% 43.37% 28 48 118 247 80 399 920 3.58 Paper Sessions 1.63% 4.78% -

SIGCHI Executive Committee Meeting Notes 2014/10
SIGCHI EC agenda Honolulu, Hawaii, USA October 911, 2014 October 9 Gerrit van der Veer, Allison Druin, Philippe Palanque, Rob Jacob, Fred Sampson, Gary Olson, Scooter Morris, Patrick Kelley, Zhengjie Liu, Ashley Cozzi, John Thomas, Jonathan Lazar, Dan Olsen Apologies: Elizabeth Churchill, Jenny Preece, John Karat, Jofish Kaye, Kia Hook, Tuomo Kujala Various Issues: ● Sig Governing Board retiree task force (and JohnT’s suggestion) ○ Draft from Jonathan Grudin, Ron Baecker, John Thomas: Seniors for CHI, CHI for Seniors Ron Baecker, Jonathan Grudin, John Thomas Gerrit to send email to ECDONE Gerrit needs some feedback to bring to SIG Governing Board ● One of the SIGs have been developing “Playing cards of notable women in computing” This will be a kickstarter project, launching very soon (at Grace Hopper?) Details: http://www.cs.duke.edu/csed/wikipedia/cards.html Big: http://www.cs.duke.edu/csed/wikipedia/notableWomenWebPoster.jpg ● Publishing the minutes from the *May* Toronto meeting ○ Allison to work with Fred on redoing Students and Leaders: ● Scholarships ○ Gary Marsden Honoring: ■ Work with/collaborate with University and check with Family ■ Gary Olson to lead this effort & will involve others (Matt Jones, Susan Dray) ○ NEED Conference Scholarships for all SIGCHI sponsored Conferences ■ Scooter to take it to the CMC ● Mentoring ○ John T to chair: Create a lightweight policy for mentoring proposal Allison & Scooter to helpDONE ● Awards ○ Actually looking for nominations (CHI Academy + others) – Nov 15th ○ Patrick to share this info with the rest of the SIGCHI community through social media ○ Rob & Dan to find out awards status from Loren ■ Two Turing awards continuing forward ■ Several ACM Fellows continuing forward ■ This is starting to operate organically within the community. -

Abstr Acts Exemplified by These Papers
by Zeltzer, as his simulated human skeleton can (or will) central to the motion understanding problem than might navigate terrain, respond to obstacles, and yet walk with a cer- previously have been imagined. It is certainly important to tain "style" dictated by embedded (but communicating) understand the workings of the human visual system and the motion control programs. Simmons and Davis demonstrate structure of effective computer vision systems for processing the potential of high level representations by showing that moving objects, but the representations that are chosen to "why" questions are answerable with a high-level representa- elucidate some mechanism cannot be viewed in isolation. tion: demonstrating a representation's knowledge structure Rather, their semantics should be implementable and trans- not only of how to move (or change), but why. The Fortin, formable into a more readily visualized form amenable to Lamy, and Thalmann paper falls into an intermediate level either visual inspection or analytical verification. Design and where temporal relationships can be handled with graphical implementation of motion semantics is an exciting and relationships and motions themselves may be of any sort sup- challenging research field stimulating our representation struc- ported by the remainder of the animation system. turing skills while serving scientific and artistic applications. Since a principal function of a motion representation is verification that that representation is indeed adequate for a task, we must ask: 3) How is the motion information within the representa- tion visualized? The obvious answer is, of course, with computer-gener- ated graphics. The less obvious methods are with "natural language" descriptions, physical (robot) control, and question-answering. -

SIGGRAPH 2007 Computer Animation Festival Final Report 3/26/2008
SIGGRAPH 2007 Computer Animation Festival Final Report 3/26/2008 SIGGRAPH 2007 Computer Animation Festival Final Report Paul Debevec USC Institute for Creative Technologies SIGGRAPH 2007 Computer Animation Festival Chair [email protected] Last Update: March 26, 2008 This document presents the final report for the SIGGRAPH 2007 Computer Animation Festival. It provides relevant information about decisions made and work executed for the various aspects of putting on the show, and suggestions for improvements for future years. If you have any questions about this report – especially if you are in the process of organizing a SIGGRAPH Computer Animation Festival or similar event yourself – please feel free to contact me at [email protected]. Paul Debevec, USC ICT Page 1 SIGGRAPH 2007 Computer Animation Festival Final Report 3/26/2008 Contents Chairing a successful SIGGRAPH Computer Animation Festival was enormously rewarding but a huge amount of work. It required recruiting a skilled and dedicated CAF committee and anticipating, planning, and executing hundreds of tasks efficiently and effectively. This document describes the most significant tasks with an eye toward helping future CAF chairs learn from both the successes and lessons learned from putting on the SIGGRAPH 2007 Computer Animation Festival. The organization is as follows: Writing the Call for Participation ....................................................................................... 4 Setting the submission deadline..................................................................................... -

Dinesh Manocha Distinguished Professor Computer Science University of North Carolina at Chapel Hill
Dinesh Manocha Distinguished Professor Computer Science University of North Carolina at Chapel Hill Awards and honors and year received (list--no more than *five* items): • 2011: Distinguished Alumni Award, Indian Institute of Technology, Delhi • 2011: Fellow of Institute of Electrical and Electronics Engineers (IEEE) • 2011: Fellow of American Association for the Advancement of Science (AAAS) • 2009: Fellow of Association for Computing Machinery (ACM) • 1997: Office of Naval Research Young Investigator Award Have you previously been involved in any CRA activities? If so, describe. Manocha has been actively involved with organization and participation in CCC workshops that were related to robotics, spatial computing and human-computer interaction. List any other relevant experience and year(s) it occurred (list--no more than *five* items). • SIGGRAPH Executive Committee, Director-At-Large, 2011 – 2014 • General Chair/Co-Chair of 8 conferences and workshops; (1995- onwards) • Member of Editorial board and Guest editor of 20 journals in computer graphics, robotics, geometric computing, and parallel computing. (1995 onwards) • 34 Keynote and Distinguished Lectures between 2011-2015 • Program Chair/Co-Chair of 5 conferences and workshops; 100+ program committees in computer graphics, virtual reality, robotics, gaming, acoustics, and geometric computing Research interests: (list only) • Computer graphics • Virtual reality • Robotics • Geometric computing • Parallel computing Personal Statement Given the dynamic nature of our field, CRA is playing an ever-increasing role in terms of research and education. Over the last 25 years, my research has spanned a variety of different fields, including geometric/symbolic computing, computer graphics, robotics, virtual-reality and parallel computing. I have worked closely with researchers/developers in engineering, medical, and social sciences and also interacted with leading industrial organizations, federal laboratories, and startups. -

View the Revised S2018 Advance Program
PLAN YOUR EXPERIENCE ADVANCE PROGRAM The 45th International Conference & Exhibition on Computer Graphics and Interactive Techniques TABLE OF CONTENTS SCHEDULE AT A GLANCE ................................................... 3 CURATED CONTENT REASONS TO ATTEND ......................................................... 6 SIGGRAPH 2018 offers several events and sessions that are individually chosen by program chairs to CONFERENCE OVERVIEW ...................................................7 address specific topics in computer graphics and interactive techniques. CONFERENCE SCHEDULE ................................................ 10 Curated content is not selected through the regular APPY HOUR ..........................................................................19 channels of a comprehensive jury. ART GALLERY ......................................................................20 ART PAPERS........................................................................23 INTEREST AREAS SIGGRAPH brings together a wide variety of BUSINESS SYMPOSIUM ...................................................25 professionals who approach computer graphics and COMPUTER ANIMATION FESTIVAL: interactive techniques from different perspectives. ELECTONIC THEATER ........................................................26 Our programs and events align with five broad interest areas (listed below). Use these interest areas to help COMPUTER ANIMATION FESTIVAL: VR THEATER ........ 27 guide you through the content at SIGGRAPH 2018. COURSES .............................................................................28 -

2006 Annual Report
ACM SIGDOC FY’06 Annual Report Submitted by Brad Mehlenbacher, SIGDOC Chair _SIGDOC Purpose The Association for Computing Machinery (ACM) Special Interest Group (SIG) on the Design of Communication (DOC) — ACM SIGDOC — emphasizes the design of communication for computer-mediated information products and systems. SIGDOC fosters the study and publication of processes, methods, and technologies for communicating and designing communication artifacts such as printed and online information, documentation designs and applications, multimedia and Web-based environments. _SIGDOC Mission Statement Until 2003, SIGDOC focused on documentation for hardware and software. With the shift in focus from documentation to the “design of communication,” SIGDOC better positioned itself to emphasize the potentials, the practices, and the problems of multiple kinds of communication technologies, such as Web applications, user interfaces, and online and print documentation. SIGDOC focuses on the design of communication as it is taught, practiced, researched, and theorized in various fields, including technical communication, software engineering, information architecture, and usability. The mission of SIGDOC includes • Promoting the professional development of its members • Encouraging interdisciplinary problem solving related to online and print documentation and communication technologies • Providing avenues for publication and the exchange of professional information • Supporting research that focuses on the needs and goals of humans in technological contexts, -

Conference Program
THE PREMIER CONFERENCE FOR ELECTRONIC DESIGN TECHNOLOGY CONFERENCE PROGRAM November 2-6, 2014 Hilton San Jose, San Jose, California Sponsored by: In cooperation with: special interest group on design automation www.ICCAD.com 2014 The Premier Conference Devoted to Technical Innovations in Electronic Design Automation Yao-Wen Chang General Chair National Taiwan Univ., Dept. of Electrical Engineering Welcome to the 33rd ICCAD! Welcome to San Jose, California for the 33rd ICCAD, held Since 2012, ICCAD has become a crucial platform for holding annual from November 2nd to 6th, 2014. Like its 32 predecessors, highly competitive EDA contests, co-hosted by IEEE CEDA and Taiwan ICCAD 2014 provides a premier forum to explore emerging Ministry of Education, on modern topics to foster research advancements. challenges, present cutting-edge R&D solutions, record This year three contest problems on logic synthesis, timing-driven theoretical and empirical advances, and identify future placement, and DFM flow attracted 93 participating teams worldwide, roadmaps for design automation. Furthermore, ICCAD 2014 is co-located with achieving a greater success for this tradition. The contest results are the Phil Kaufman Award ceremony, IEEE CEDA CAD Contests, ACM CADathlon announced in the Tuesday contest session, along with the release of Contest and Student Research Competition, the Sunday full-day workshop on contest benchmarks. TCAD simulation, and five Thursday full-day workshops on design automation for analog and mixed-signal circuits, EDA research in the dark silicon era, It is our greatest honor to invite three distinguished keynote speakers: The variability modeling and characterization, process design kit automation, and Monday keynote is by Dr.