Accessibility and Computing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

IPC Accessibility Guide
2 TABLE OF CONTENTS FIGURES AND TABLES ................................................................................................................. 8 Foreword ........................................................................................................................................... 10 Introduction ................................................................................................................................. 10 Evolving content ......................................................................................................................... 10 Disclosure ...................................................................................................................................... 11 Structure and content of the IPC Accessibility Guide ...................................................... 11 Content ........................................................................................................................................... 11 Executive summary ......................................................................................................................... 12 Aim and purpose of the Guide ................................................................................................ 12 Key objectives of the Guide ..................................................................................................... 12 Target audience of the Guide ................................................................................................. 12 1 General information -

ADA Day Draft
Americans With Disabilities Act ADA DAY 7.26.21 What is ADA Day? History The ADA (Americans with Disabilities Act) is a civil rights law for people with disabilities that was passed on July 26, 1990. The law prohibits discrimination against individuals with disabilities, assuring them of equality and equity of opportunity, full community participation, independent living, and economic self-sufficiency. In enacting the ADA, Congress recognized that physical and mental disabilities do not reduce a person’s right or ability to fully participate in all aspects of society, but that people with physical or mental disabilities are frequently excluded from doing so as a result of prejudice and inaccessibility. With the help of the ADA, 1 in 4 Americans with disabilities is able to participate in their communities and workplaces today. Every July 26th we celebrate the ADA, our fellow individuals with disabilities, and look ahead to the work that is still being done to make a more inclusive, accessible life for those with disabilities. Areas of assistance under the ADA Employment Transportation Public Accommodations President George Bush signing the ADA act on July 26, 1990 Communications and access to state and local government programs and services 01 Overview of Americans with Disabilities Act Title I of the Americans with Disabilities Act (ADA): Prohibits private and government employers, employment agencies, and worker’s unions from discriminating against qualified individuals with disabilities. This covered all termsof employment, including applications, hiring, firing, promotion, and job training. It is enforced by the U.S Equal Employment Opportunity Commission. Those who believe they have been discriminated against on the basis of their disability can file a charge to the department citing disability discrimination. -

2015 Roadmap to Web Accessibility in Higher Education 22
White Paper 201 ROADMAP TO WEB ACCESSIBILITY IN HIGHER5 EDUCATION 2015 Roadmap to Web Accessibility in Higher Education 2 Table of Contents TABLE OF CONTENTS ................................................................................................................................ 2 EXECUTIVE SUMMARY ............................................................................................................................. 4 WHO IS THIS WHITE PAPER FOR? ............................................................................................................. 4 WEB ACCESSIBILITY – A GROWING CONCERN FOR HIGHER EDUCATION .................................................. 5 WHAT IS WEB ACCESSIBILITY? ........................................................................................................................... 5 A SURGE IN THE DISABLED POPULATION .............................................................................................................. 5 IMPACT OF ACCESSIBILITY LAWS ON UNIVERSITIES .................................................................................................. 6 THE REHABILITATION ACT.................................................................................................................................. 6 THE AMERICANS WITH DISABILITIES ACT .............................................................................................................. 6 TYPES OF DISABILITIES ..................................................................................................................................... -

Gauging ADA Compliance in the 21St Century Business Internet: a Pilot Study
Communications of the IIMA Volume 16 Issue 4 Article 3 2018 Gauging ADA Compliance in the 21st Century Business Internet: A Pilot Study Daniel McDonald Georgia College & State University, [email protected] Tanya Goette Georgia College & State University, [email protected] Hannah Petoia Georgia College & State University Follow this and additional works at: https://scholarworks.lib.csusb.edu/ciima Part of the Management Information Systems Commons Recommended Citation McDonald, Daniel; Goette, Tanya; and Petoia, Hannah (2018) "Gauging ADA Compliance in the 21st Century Business Internet: A Pilot Study," Communications of the IIMA: Vol. 16 : Iss. 4 , Article 3. Available at: https://scholarworks.lib.csusb.edu/ciima/vol16/iss4/3 This Article is brought to you for free and open access by CSUSB ScholarWorks. It has been accepted for inclusion in Communications of the IIMA by an authorized editor of CSUSB ScholarWorks. For more information, please contact [email protected]. Gauging ADA Compliance in the 21st Century Business Internet: A Pilot Study ABSTRACT This paper explores issues of accessibility in Web design, including the applicability of various federal statutes such as the Americans with Disabilities Act of 1990 (ADA) and Section 508 of the Rehabilitation Act of 1973. A pilot study of six private sector websites is completed to gauge the effectiveness of current accessibility standards as interpreted from the ADA and Section 508. Evaluating these sites shows that even after 25 years, sites still have accessibility issues. Keywords: web accessibility, Americans with Disabilities Act, ADA, web design, accessibility standards, WCAG 2.0, HTML Section 508 checklist INTRODUCTION The Americans with Disabilities Act of 1990 (ADA) created a legal incentive for businesses to stop discriminating against people with disabilities. -

Accessibility in Web Development Courses: a Case Study
informatics Article Accessibility in Web Development Courses: A Case Study Mexhid Ferati 1,* and Bahtijar Vogel 2 1 Informatics Department, Linnaeus University, 392 31 Kalmar, Sweden 2 Department of Computer Science and Media Technology, Malmö University, 205 06 Malmö, Sweden; [email protected] * Correspondence: [email protected] Received: 11 February 2020; Accepted: 13 March 2020; Published: 17 March 2020 Abstract: Web accessibility is becoming a relevant topic with an increased number of people with disabilities and the elderly using the web. Numerous legislations are being passed that require the web to be universally accessible to all people, regardless of their abilities and age. Despite this trend, university curricula still teach traditional web development without addressing accessibility as a topic. To investigate this matter closely, we studied the syllabi of web development courses at one university to evaluate whether the topic of accessibility was taught there. Additionally, we conducted a survey with nineteen students who were enrolled in a web development course, and we interviewed three lecturers from the same university. Our findings suggest that the topic of accessibility is not covered in web development courses, although both students and lecturers think that it should. This generates lack of competence in accessibility. The findings also confirm the finding of previous studies that, among web developers, there is a low familiarity with accessibility guidelines and policies. An interesting finding we uncovered was that gender affects the motivation to learn about accessibility. Females were driven by personal reasons, which we attribute to females having an increased sense of empathy. Finally, our participants were divided in their opinions whether accessibility contributes to usability. -

Universal Design Principles Into Astronomy Education and Research
INCORPORATING UNIVERSAL DESIGN PRINCIPLES INTO ASTRONOMY EDUCATION AND RESEARCH Panelists: Alicia Aarnio (University of Colorado/AAS WGAD) Jackie Monkiewicz (Arizona State/AAS WGAD) Sharron Rush (Knowbility.org) Organized by: Sarah Tuttle (University of Washington/ AAS CWSA-WGAD liaison) CART captioning: Polly Fife (Texas Closed Captioning) Universal Access Note: • Please use this space as you need or prefer. • Sit in chairs or on the floor, pace, lie on the floor, rock, flap, spin, move around, knit, step in and out of the room. • Feel free to use your laptop or your electronic devices or your mechanical fidget devices if you brought them. Take notes or play video games. • Meeting tag #wiaiv; us: @AAS_WGAD, @AliciaAarnio, @jmonkiew, @knowbility • Please use headphones if you use audio. -adapted from Lydia Brown, @autistichoya Motivation 1 in 5 Americans is disabled (CDC, 2015) • ADA: Americans with Disabilities Act (1990) prohibits discrimination… • BUT Disability Offices and ADA compliance varies from institution to institution • Graph shows percentage of students with disabilities in STEM degrees: 10% undergraduate; 5% graduate level, 1% who complete PhD programs. Accessibility 101 • Intersectionality Reminder • Medical vs. Social Model of Disability • Visible vs. Invisible Disability, risks of disclosure • ADA Compliance (and its limits) • Common forms of Prejudice & Discrimination • Representation • Movement towards Self-Advocacy • ADA Compliant vs. Barrier-free vs. Universal Design Defining our terms: • Disability: Condition which -

The Changing Shape of the Computing World
Outside the Box — The Changing Shape of the Computing World Steve Cunningham Computer Science California State University Stanislaus Turlock, CA 95382 [email protected] http://www.cs.csustan.edu/~rsc Something happened to computing while many of us were busy practicing or teaching our craft, and computing is not quite the same thing we learned. We can ignore this change and others will take our place and teach about it, but they will not have the context and the skill to understand the technology behind it and to carry it forward to the success it should have. And if others carry that torch, computer science will be stunted because we didn't recognize and respond to the opportunity. What happened? Simply this—that Xerox and Apple and, yes, Microsoft opened up the box labeled “CAUTION: Computer Inside” and let the user into the computing picture. Users responded hesitantly but increasingly eagerly and now expect the computer to work for them instead of their working for the computer. Every application now in wide use, and any system that supports a general market, has evolved to meet that expectation. Any computing education that does not pay attention to the user’s role in computing is missing the most vibrant and exciting part of computing today. As it says at the top of this page, you are reading an editorial, not an academic paper. As an editorial, this note represents my personal passion and commitment to the user communication part of computing that the “official” computing establishment has long discounted, and I appreciate John Impagliazzo’s offer of this forum to make my case that computer science is missing the boat in not understanding the need to reshape computer science education to fill this void. -
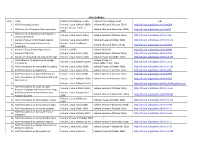
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1 (March 1969) Volume 49 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J204 Volume 24 Issue 1 (Feb. 1, 2. ACM Journal of Computer Documentation Volume 26 Issue 4 (November 2002) http://dl.acm.org/citation.cfm?id=J24 2000) ACM Journal on Emerging Technologies in 3. Volume 1 Issue 1 (April 2005) Volume 13 Issue 2 (October 2016) http://dl.acm.org/citation.cfm?id=J967 Computing Systems 4. Journal of Data and Information Quality Volume 1 Issue 1 (June 2009) Volume 8 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1191 Journal on Educational Resources in Volume 1 Issue 1es (March 5. Volume 16 Issue 2 (March 2016) http://dl.acm.org/citation.cfm?id=J814 Computing 2001) 6. Journal of Experimental Algorithmics Volume 1 (1996) Volume 21 (2016) http://dl.acm.org/citation.cfm?id=J430 7. Journal of the ACM Volume 1 Issue 1 (Jan. 1954) Volume 63 Issue 4 (October 2016) http://dl.acm.org/citation.cfm?id=J401 8. Journal on Computing and Cultural Heritage Volume 1 Issue 1 (June 2008) Volume 9 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J1157 ACM Letters on Programming Languages Volume 2 Issue 1-4 9. Volume 1 Issue 1 (March 1992) http://dl.acm.org/citation.cfm?id=J513 and Systems (March–Dec. 1993) 10. ACM Transactions on Accessible Computing Volume 1 Issue 1 (May 2008) Volume 9 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1156 11. -

Cv Shinohara.Pdf
Kristen Shinohara School of Information B. Thomas Golisano College of Computing and Information Sciences Rochester Institute of Technology 20 Lomb Memorial Drive, Rochester, NY 14623 [email protected] | www.kristenshinohara.com ACADEMIC POSITION Assistant Professor, School of Information, B. Thomas Golisano College of Computing and Information Sciences, Rochester Institute of Technology (2017 – present). EDUCATION Ph.D., Information Science, University of Washington - Seattle, WA, Spring 2017 Emphasis on Human-Computer Interaction and Accessibility Thesis: Design for Social Accessibility: Incorporating Social Factors in the Design of Accessible Technologies Committee: Jacob O. Wobbrock (advisor), Wanda Pratt (co-advisor), Clayton Lewis, David Hendry, Richard Ladner M.S., Computing and Software Systems, University of Washington - Tacoma, WA, June 2006 Final project focused on Human-Centered Design and Accessibility Advisor: Josh Tenenberg B.S., Computer Science, University of Puget Sound - Tacoma, WA, May 2002 Minors in Mathematics and Physics FUNDING Kristen Shinohara (PI). Aug 2019 – Jul 2022. “Ethical Approaches to Empower Disabled Graduate Students in STEM.” National Science Foundation Cultivating Cultures of Ethical STEM. Award No. 1926209, Funding total: $281,900. Matt Huenerfauth (PI), Kristen Shinohara (Joined as Co-PI in 2018). Dec 2015 – Nov 2019. “Ethical Inclusion of People with Disabilities through Undergraduate Computing Education.” National Science Foundation Cultivating Cultures of Ethical STEM. Award No. SES-1540396, Funding total: $449,987. Kristen Shinohara (PI). Aug 2018 – Aug 2019. “Method Cards for User Centered Design.” RIT Provost’s Learning Innovation Grant (PLIG), Funding total: $1000. Kristen Shinohara (PI). May 2018 – Aug 2019. “Academic Success for Blind Graduate Students in Computing and Information Sciences.” RIT Grant Writer’s Boot Camp, Funding Total: $5000. -

SIGCHI Conferences Report for Members May 2018
SIGCHI Conferences Report " ! " ! " May 22, 2018 SIGCHI (Special Interest Group on Computer-Human Interaction) is led by the SIGCHI Executive committee and one of the appointed roles on this committee is the ACM SIGCHI Vice President for Conferences. This person is responsible for overseeing all aspects of SIGCHI-sponsored conferences and SIGCHI currently sponsors 24 conferences. www.si In addition to the annual CHI conference, the Specialised Conferences program of ACM SIGCHI has gradually evolved and has now become a significant part of the conference program that is offered to the HCI community at large. Across our conferences we have over 9,000 delegates attend our 24 conferences, with around 3000 of these attending CHI. This program includes all conferences involving ACM SIGCHI other than the annual CHI conferences. Throughout this report there are references to Specialised Conferences (e.g. Group to VRST) and CHI. Each conference has a steering committee and the chair of each steering committee serves on the ACM SIGCHI Council of Steering Committee Chairs. In addition we have an Adjunct Chair for CHI on the SIGCHI EC along with a SIGCHI Conference Board which works with the ACM SIGCHI VP for Conferences. The CHI Steering Committee oversees the activities of all CHI conference committee chairs from CHI 2018 onwards. It ensures that the objectives of the conference as established by the Steering Committee and EC are met. The CHI Steering Committee was created by SIGCHI Executive Committee in 2016. From CHI 2018 onwards, this committee serves as a focal point for communications between the conference committee, CHI attendees, CHI committees, CHI vendors, CHI liaison, SIGCHI and the SIGCHI Services Staff. -

Accessibility and Computing
ISSUE 91, JUNE 2008 Accessibility and Computing A regular publication of the ACM Special Interest Group on Accessible Computing A Note from the Editor Inside This Issue Dear SIGACCESS member: 1 A Note from the Editor Welcome to the new look of the online edition of the 2 SIGACCESS Officers and Information SIGACCESS Newsletter – with new layout, the use of 3 Vocal Control of a Radio-controlled Car sans-serif and larger font throughout, left-justification, 8 Structuring and Designing Web and the inclusion of authors’ short biographies and Information System for Stroke Care: A photographs (so that you can say hi when you meet Malaysian Perspective them in meetings and conference). 17 Defining an Agenda for Human- Centered Computing Following the tradition of including a variety of work 22 CFP: the First International Workshop on from around the world, this issue encompasses a Requirements Engineering and Law variety of topics, from a report from Italy and Czech Republic on the use of non-verbal vocal input to control an RC car to Web-based system for helping stroke survivors and their caregivers in Malaysia. This issue also includes a report on two workshops aimed at identifying important and emerging research areas and trends in Human-Centered Computing, in which accessibility is a part of the agenda. Sri Kurniawan Newsletter editor PAGE 1 SIGACCESS NEWSLETTER, ISSUE 91, JUN 2008 SIGACCESS Officers and Information Chairperson Who we are Vicki Hanson SIGACCESS is a special interest group of IBM T.J. Watson Research Center ACM. The SIGACCESS Newsletter is a regular 19 Skyline Drive online publication of SIGACCESS. -

Dronepaint: Swarm Light Painting with DNN-Based Gesture Recognition
DronePaint: Swarm Light Painting with DNN-based Gesture Recognition Valerii Serpiva Ekaterina Karmanova Aleksey Fedoseev Skolkovo Institute of Science and Skolkovo Institute of Science and Skolkovo Institute of Science and Technology Technology Technology Moscow, Russia Moscow, Russia Moscow, Russia [email protected] [email protected] [email protected] Stepan Perminov Dzmitry Tsetserukou Skolkovo Institute of Science and Skolkovo Institute of Science and Technology Technology Moscow, Russia Moscow, Russia [email protected] [email protected] Figure 1: a) View of user screen. Drawing trajectory by hand and gesture recognition. b) Long exposure light painting of “Siggraph" logo by drone. c) Single swarm agent with the LED circle. ABSTRACT trajectory patterns. The proposed system can be potentially applied We propose a novel human-swarm interaction system, allowing the in complex environment exploration, spray painting using drones, user to directly control a swarm of drones in a complex environment and interactive drone shows, allowing users to create their own art through trajectory drawing with a hand gesture interface based on objects by drone swarms. the DNN-based gesture recognition. The developed CV-based system allows the user to control the CCS CONCEPTS swarm behavior without additional devices through human ges- • Human-centered computing ! Human-computer interac- tures and motions in real-time, providing convenient tools to change tion (HCI). the swarm’s shape and formation.