PAI Pandemics, Detection and Management
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Full Year Statutory Accounts
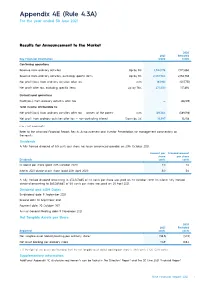
Appendix 4E (Rule 4.3A) For the year ended 30 June 2021 Results for Announcement to the Market 2020 2021 Restated Key Financial Information $’000 $’000 Continuing operations Revenue from ordinary activities Up by 8% 2,342,178 2,172,060 Revenue from ordinary activities, excluding specific items Up by 8% 2,332,984 2,156,785 Net profit/(loss) from ordinary activities after tax n/m 183,961 (507,751) Net profit after tax, excluding specific items Up by 76% 277,530 157,694 Discontinued operations Profit/(loss) from ordinary activities after tax — (66,189) Total income attributable to: Net profit/(loss) from ordinary activities after tax — owners of the parent n/m 169,364 (589,198) Net profit from ordinary activities after tax — non-controlling interest Down by 4% 14,597 15,258 n/m = not meaningful Refer to the attached Financial Report, Results Announcement and Investor Presentation for management commentary on the results. Dividends A fully franked dividend of 5.5 cents per share has been announced payable on 20th October 2021. Amount per Franked amount share per share Dividends cents cents Dividend per share (paid 20th October 2020) 2.0 2.0 Interim 2021 dividend per share (paid 20th April 2021) 5.0 5.0 A fully franked dividend amounting to $34,107,865 of 2.0 cents per share was paid on 20 October 2020. An interim fully franked dividend amounting to $85,269,663 of 5.0 cents per share was paid on 20 April 2021. Dividend and AGM Dates Ex-dividend date: 9 September 2021 Record date: 10 September 2021 Payment date: 20 October 2021 Annual General Meeting date: 11 November 2021 Net Tangible Assets per Share 2020 2021 Restated Reported cents cents Net tangible asset (deficit)/backing per ordinary share 1 (38.3) (40.9) Net asset backing per ordinary share 114.9 108.4 1. -

1 Transcript of 2019 Nine Entertainment AGM Sydney
1 Transcript of 2019 Nine Entertainment AGM Sydney, November 12, 2019 Chairman Peter Costello Good morning ladies and gentleman. As your Chairman, it's my pleasure to welcome you to the 2019 AGM of Nine Entertainment Company. My name is Peter Costello. Before opening the meeting, I refer you to the disclaimer here on the screen behind me and available through our ASX lodgement. It is now shortly after 10am and I am advised that this is a properly constituted meeting. There's a quorum of at least two shareholders present so I declare the 2019 Annual General Meeting open. Unless there are any objections, I propose to take the Notice of Meeting as read. Copies of the Notice of Meeting are available from the registration desk outside should you require them. Let me now introduce the people who are with us this morning. To my immediate left is Rachel Launders, our General Counsel and Company Secretary. Then Hugh Marks, our Chief Executive Officer, who will address the meeting a little later. Next to Hugh is Nick Falloon, the Independent, Non-Executive Director and Deputy Chair and Member of the People and Remuneration Committee. Then we have Patrick Alloway, Independent, Non-Executive Director and a member of the Audit and Risk Management Committee. Next to Patrick is Sam Lewis, Independent, Non-Executive Director, Chair of the Audit and Risk Committee and a Member of the People and Remuneration Committee. Then we have Mickie Rosen, Independent, Non-Executive Director. At the far end, we have Catherine West, Independent, Non-Executive Director, the Chair of the People and Remuneration Committee and a member of the Audit and Risk Committee. -

Annual Report to Shareholders
create distribute engage ifc The Year in Brief 2 Chairman’s Address 4 Chief Executive Officer’s Address 6 Divisional Results 8 Operational Review 16 Nine Cares create 17 Governance 18 Board of Directors 20 Directors’ Report distribute 25 Remuneration Report 44 Operating and Financial Review 48 Financial Report engage 108 Shareholder Information ibc Corporate Directory During FY17, Nine achieved its goal of turning the Network performance around, after a disappointing year in FY16. Momentum in Free To Air TV turned positive for Nine in Q2, and this improvement continued throughout the remainder of the financial year. The success of Nine’s broadcast content has, in turn, driven take-up and use of 9Now which has grown exponentially to over 4 million registered users, and is becoming a valuable contributor to the P&L. Nine’s Subscription Video on Demand platform Stan, has matured significantly over the past 12 months and now holds a clear number 2 position in the market. Nine’s digital publishing business has been successfully repositioned post the Microsoft relationship, laying the foundations for growth into the future. All of Nine’s businesses are built around the key content verticals of news, sport, lifestyle and entertainment. Result In Brief In FY17, on a revenue decline of 4%, Nine reported Group EBITDA of $206 million, up 2% on FY16. Driving this growth was an underlying cost decrease of 1%, and a reported cost decrease of 4% which included the Government regulated licence fee relief of $33 million. Net Profit after Tax increased by 3% to $123.6 million compared to the Pro Forma FY16 result. -

Swift Media Appoints Pippa Leary As Ceo and Darren Smorgon As Non-Executive Chairman
ASX RELEASE 26 JUNE 2019 ASX: SW1 SWIFT MEDIA APPOINTS PIPPA LEARY AS CEO AND DARREN SMORGON AS NON-EXECUTIVE CHAIRMAN HIGHLIGHTS Swift appoints experienced media and advertising executive Pippa Leary as Chief Executive Officer Ms Leary is a consistent driver of growth, commercial innovation and shareholder value through senior roles at Nine Entertainment Company, Fairfax Media and APEX Advertising Swift appoints current Director Darren Smorgon as Non-Executive Chairman Medical Media integration ahead of schedule, on track to deliver at least $3 million of annual synergies and business improvements across FY 2019 and FY 2020 Swift's geographic and market sector diversification continues to develop, with recent contract wins, expansions and renewals seeing the Company deliver material organic growth. Swift's footprint now exceeds more than 74,000 screens across 1,842 sites in the resources, aged care health and hospitality sectors Leading communications, content and advertising solutions provider Swift Media Limited (ASX: SW1, “Swift” or “the Company”) is pleased to announce the appointment of Pippa Leary as Chief Executive Officer (CEO) and current Director Darren Smorgon as Non-Executive Chairman. Ms Leary brings a proven track record of commercial innovation and success in the digital media space, having spent more than 20 years with Nine Entertainment Company (ASX: NEC) and Fairfax Media, as well as several non-executive roles. Prior to joining Swift, she was Commercial Director of Nine’s Digital Sales team, achieving the number one ranking in the Australian market during her tenure, and is the former CEO of APEX Advertising, a joint venture between Nine and Fairfax Media. -

Adstream Powerpoint Presentation
Broadcast Centres List Metropolitan Stations/Regulatory Nine (NPC) 7 BCM 7 BCM cont’d Nine (NPC) cont’d Ten Network 9HD & SD / 9Go! / 9Gem / 9Life Adelaide 7HD & SD / 7mate / 7two / 7Flix Melbourne 7 / 7mate / 7two / 7Flix Rockhampton QTQ Nine Brisbane Ten HD (all metro) 9HD & SD / 9Go! / 9Gem / 9Life Brisbane 7HD & SD / 7mate / 7two / 7Flix Perth 7 / 7mate / 7two / 7Flix Toowoomba STW Nine Perth Ten SD (all metro) 9HD & SD / 9Go! / 9Gem / Darwin 7HD & SD / 7mate / 7two / 7Flix Adelaide 7 / 7mate / 7two / 7Flix Townsville TCN Nine Sydney One (all metro) 9HD & SD / 9Go! / 9Gem / 9Life Melbourne 7 / 7mate HD / 7two / 7Flix Sydney 7 / 7mate / 7two / 7Flix Wide Bay Channel 11 (all metro) 7 / 7mate HD / 7two / 7Flix Brisbane 9HD & SD / 9Go! / 9Gem / 9Life Perth SBS National 7 / 7mate HD / 7two / 7Flix Gold Coast 9HD & SD / 9Go! / 9Gem / 9Life Sydney SBS HD / SBS Free TV CAD 7 / 7mate HD / 7two / 7Flix Sunshine Coast ABC GTV Nine Melbourne Viceland 7 / 7mate HD / 7two / 7Flix Maroochydore NWS Nine Adelaide SBS Food Network 7 / 7mate / 7two / 7Flix Townsville NTD 8 Darwin National Indigenous TV (NITV) 7 / 7mate / 7two / 7Flix Cairns WORLD MOVIES 7 / 7mate / 7two / 7Flix Mackay Regional Stations Prime 7 cont’d SCA TV Cont’d WIN TV cont’d VIC Mildura Bendigo WIN / 11 / One Regional: WIN Ballarat Send via WIN Wollongong Imparja TV Newcastle Bundaberg Albury Orange/Dubbo Ballarat Canberra NBN TV Port Macquarie/Taree Bendigo QLD Shepparton Cairns Central Coast Canberra WIN Rockhampton South Coast Dubbo Cairns Send via WIN Wollongong Coffs Harbour -

2020 Half Year Results Announcement
26 February 2020 ASX Markets Announcement Office ASX Limited 20 Bridge Street Sydney NSW 2000 2020 HALF YEAR RESULTS ANNOUNCEMENT Attached is a copy of the ASX release relating to the 2020 Half Year Financial Results for Nine Entertainment Co. Holdings Limited Rachel Launders Company Secretary Authorised for release: Nine Board sub-committee Further information: Nola Hodgson Victoria Buchan Head of Investor Relations Director of Communications +61 2 9965 2306 +61 2 9965 2296 [email protected] [email protected] NINE ENTERTAINMENT CO. FY20 INTERIM RESULTS 26 February 2020: Nine Entertainment Co. (ASX: NEC) has released its H1 FY20 results for the 6 months to December 2019. On a Statutory basis, pre Specific Items, on Revenue of $1.2b, Nine reported Group EBITDA of $251m, and a Net Profit After Tax of $114m. Post Specific Items, the Statutory Net Profit was $102m. These numbers are stated excluding Discontinued Businesses. On a pre AASB16 and Specific Item basis, Nine reported Group EBITDA of $231m, down 8% on the Pro Forma results in H1 FY19 for its Continuing Businesses. On the same basis, Net Profit After Tax and Minority Interests was $115m, down 9%. Key takeaways include: • Strong growth from digital video businesses o $35m EBITDA improvement at Stan1, with subscribers exceeding 1.8m o 65% growth in EBITDA at 9Now1, with market leading BVOD share of ~50% o Further investment in 9Now to accelerate growth into the broader digital video market • Result was heavily impacted by challenging cycles o Broad based ad market weakness including a 7% decline in Metro FTA revenues o Housing market softness impacting Domain’s residential listing volumes • Stability in Metro Media earnings1 • Synergies of $9m identified following completion of the Macquarie Media acquisition • Nine expects FY20 EBITDA at a similar level to FY191 1 like-basis, pre AASB16 Hugh Marks, Chief Executive Officer of Nine Entertainment Co. -

Audience Insights Tracker As at 27 April, 2020
Audience Insights Tracker As at 27 April, 2020 Linear TV BVOD Digital & Publishing Radio Nine maintains its dominance as Dwell times on all Nine’s digital news sites 9Now continues to be the leading Audiences continue to turn to Nine Australia’s preferred demographic delivered double digital growth in CFTA BVOD platform with a year-to- Radio for trusted voices and platforms network for primetime, driven by March, a reflection of audiences turning date share of 50% in total minutes. where they can voice their own trusted news and current affairs, and to trusted news sites for up-to-the minute opinions. The second GfK Radio Survey premium entertainment content. information. Furthermore 9Now has ranked as the of 2020 has seen 2GB, 3AW, 4BC and leading CFTA BVOD platform for 15 out 6PR post significant audience growth Nine continues to reach new As audiences look to inspiration at of 17 weeks (YTD) for both live and during the COVID-19 crisis. audiences across all key demos, with home 9Honey, Traveller and Good Food VOD minutes weekly share. +1.7 reach points for P25-54 in the last are connecting with Nine Radio has had 1.45M podcast month compared to previous. Australians, providing content to indulge As viewers continue to turn to downloads to date, and a 16% their passions across health, food and entertainment for an escape during increase in downloads month to date. Extended time spent at home is travel. seeing increased engagement on the current global pandemic, family favourite LEGO Masters S2 continues to Gfk’s COVID-19 radio user survey has linear TV year-on-year, with P25-54 Nine’s Consumer Pulse survey spanning captivate audiences taking the top found that 72% of respondents trust spending 11 more minutes a week readers of the Herald, The Age, The two spots for live viewing last week. -

January 12, 2017 a Study Session of the Utah S
UTAH STATE BOARD OF EDUCATION MEETING MINUTES January 12-13, 2017 STUDY SESSION - January 12, 2017 A study session of the Utah State Board of Education was held January 12, 2017 at the Utah State Board of Education Building, 250 East 500 South, Salt Lake City, Utah. Chair Mark Huntsman conducted. Board members present included Chair Mark Huntsman, 1st Vice Chair Terryl Warner, 2nd Vice Chair Brittney Cummins, 3rd Vice Chair Alisa Ellis, Laura Belnap, Michelle Boulter, Lisa Cummins, Janet Cannon, Jennifer Graviet, Linda Hansen, Carol Lear, Scott Neilson, and Kathleen Riebe. Members absent: Spencer Stokes, Joel Wright. Others present included Sydney Dickson, Scott Jones, Angie Stallings–USBE staff; David Thomas, Bryan Quesenberry–Assistant Attorney General’s Office; Alan Shino–Monticello Academy; Wendi Baggaley; Heidi Nichols-Payne; Chase Clyde, Jay Blain–Utah Education Association; Caren Burns; Brad Asay–American Federation of Teachers. Chair Mark Huntsman called the meeting to order at 2:07 p.m. Swearing In of New Board Members Lt. Governor Spencer Cox was introduced by Vice Chair Terryl Warner. Lt. Governor Cox administered the Oath of Office individually to Board members Jennifer Graviet, Alisa Ellis, Carol Barlow Lear, Janet Cannon, Kathleen Riebe, Lisa Cummins, Scott Neilson, and Michelle Boulter. The new members introduced family and friends. Lt. Governor Cox acknowledged that families that are part of this journey will sacrifice much, and expressed appreciation to them for their support. ADA Compliant: 12/3/2019 USBE Meeting Minutes -2- January 12-13, 2017 Minimum School Program Scott Jones, Deputy Superintendent of Operations, introduced Natalie Grange, Assistant Superintendent of Operations, and Jaime Barrett, MSP Coordinator. -

GETTING TOGETHER TODAY COVER SLIDE with Social Distancing the New Norm, People Are Finding Ways to Stay Social at a Distance
GETTING TOGETHER TODAY COVER SLIDE With social distancing the new norm, people are finding ways to stay social at a distance. “I miss social interaction” Now more than ever, technology is playing a major role in keeping Australians connected with their friends, “I can’t hug my grandchildren” family and the community. With the help of Nine, your brand can play a part in keeping Australians connected. Introducing Getting Together Today – Powered by Nine. Source: Nine Consumer Pulse Survey: Week 3 - commencing 29th March 2020. As the pandemic continues to People are using their phones and There is an opportunity for a telco brand change the way we live, the way we technology to connect with the people to be at the forefront of this movement connect with our friends, families, they love, miss, and work with: and champion the new art of staying colleagues and community changes connected from afar. with it. But just because we can’t Apps that foster collaboration like physically be together doesn’t mean Zoom have gone from 50,000 daily We will engage the depth and breadth we can’t get together and stay downloads to 2 million of the Nine ecosystem with a campaign connected with the help of titled “Getting Together Today” to speak technology. The average screen time for adults to a broad spectrum of demographics has surpassed 11 hours per day including everyone from families, parents, the 25-45sand 45-65s to high- Informative articles on how to avoid income earners. loneliness during isolation are trending across Nine Digital sites TELEVISION -

Annual Report 2019 OVERVIEW
Annual Report 2019 OVERVIEW During FY19, Nine completed the merger with Fairfax Media, creating Australia’s leading integrated media business. Nine today has a clearly diversified earnings base, with four key operational pillars — Broadcasting, Digital and Publishing, Stan as well as a 59% stake in Domain. These businesses are all at different stages of their evolution, and are all scale businesses in their own right. In FY19, on a Pro Forma basis, the traditional Broadcasting business contributed just over half of Group revenue, down from 84% in FY18, marking a real change in the drivers of Nine for the future. Result in brief In FY19, Nine reported Group EBITDA of $350 million, up 36% on FY18, driven by a 40% increase in Group Revenues to $1.8 billion, reflecting the impact of the merger with Fairfax from 7 December. On a continuing business basis, Statutory Net Profit after Tax and Specific Items, which were predominately accounting led non-cash items, was $217 million, up 3%. On a Pro Forma basis, NEC reported Group EBITDA of $424 million, up 10% on FY18, on revenue of $2.3 billion. Net Profit after Tax and minority interests increased by 16% to $198 million compared to the FY18 result. Earnings per share was 11.6 cents, (+16%) and a full-year dividend of 10c per share, fully franked, was declared. Revenue1 split FY19 10% Pro Forma EBITDA growth driven by 300 7% 250 -11% 9% 200 150 +56% 100 54% -17% 30% 50 0 +48% -50 +56% +48% -100 FY18 FY19 Broadcasting Domain Digital & Publishing Stan Broadcasting Digital & Publishing Domain Stan -

Nine Entertainment Co. Holdings (ASX:NEC)
24 FEBRUARY, 2021 Important Notice and Disclaimer expectations about the performance of its businesses. likelihood of achievement or reasonableness of any This document is a presentation of general background Forward looking statements can generally be identified by forward looking statements, forecast financial information information about the activities of Nine Entertainment Co. the use of forward looking words such as, ‘expect’, or other forecast. Nothing contained in this presentation Holdings Limited (“NEC”) current at the date of the ‘anticipate’, ‘likely’, ‘intend’, ‘should’, ‘could’, ‘may’, nor any information made available to you is, or shall be presentation, (24 February 2021). The information ‘predict’, ‘plan’, ‘propose’, ‘will’, ‘believe’, ‘forecast’, relied upon as, a promise, representation, warranty or contained in this presentation is of general background ‘estimate’, ‘target’ and other similar expressions within the guarantee as to the past, present or the future and does not purport to be complete. It is not intended to meaning of securities laws of applicable jurisdictions. performance of NEC. be relied upon as advice to investors or potential investors Indications of, and guidance on, future earnings or and does not take into account the investment objectives, financial position or performance are also forward looking Pro Forma Financial Information statements. financial situation or needs of any particular investor. These The Company has set out in this presentation certain non- should be considered, with or without professional advice, Forward looking statements involve inherent risks and IFRS financial information, in addition to information when deciding if an investment is appropriate. uncertainties, both general and specific, and there is a risk regarding its IFRS statutory information. -

Nation-Wide Heatwave Kicks Off As Summer Finally Arrives in Australia
Nation-wide heatwave kicks off as summer finally arrives in Australia 8:06am Dec 11, 2017 Australians should prepare to swelter with every capital city set to have at least one day in the high 30s this week. The nation-wide heatwave comes as a “hot air mass” moves across the country, Weatherzone meteorologist Craig McIntosh told 9news.com.au. “A trough which will move across Australia, dragging hot air ahead of it,” Mr McIntosh said. “Adelaide and Melbourne will be hottest on Wednesday, as a hot air mass is driven over the region by north North-West winds. “Heaps of hot air is building up in the interior and it’s being pushed over Adelaide and Melbourne over the coming days peaking on Wednesday before a cold front brings relief.” It won’t be too hot in Melbourne today with only a maximum of 23C expected, but that will change on Tuesday with the mercury expected to rise to 29C. It will jump again on Thursday to 36C. In Adelaide tops of 30C, 36C and 37C are predicted for today, tomorrow and Wednesday respectively. Both cities will have some relief by Thursday with a southerly change bringing the mercury back down to the mid-20s. Mr McIntosh said the hot air mass will “push up into the ACT and NSW” after moving on from Adelaide and Melbourne. In Canberra the mercury is expected to sit in the low- to mid-30s all week, and Sydney is already starting to warm up today with a high of 26C expected, but by Wednesday the mercury should rise to 29C, and again to 34C on Thursday.