Cache Memory Cache Performance Summary
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Secondary Memory
Secondary Memory This type of memory is also known as external memory or non-volatile. It is slower than main memory. These are used for storing data/Information permanently. CPU directly does not access these memories instead they are accessed via input-output routines. Contents of secondary memories are first transferred to main memory, and then CPU can access it. For example : Hard disk, CD-ROM, DVD etc. Electronic data is a sequence of bits. This data can either reside in : • Primary storage - main memory (RAM), relatively small, fast access, expensive (cost per MB), volatile (go away when power goes off) • Secondary storage - disks, tape, large amounts of data, slower access, cheap (cost per MB), persistent (remain even when power is off) Data storage has expanded from text and numeric files to include digital music files, photographic files, video files, and much more. These new types of files require secondary storage devices with much greater capacity than floppy disks. 1 Primary storage ( or main memory or internal memory) , often referred to simply as memory , is the only directly accessible to the CPU. Primary memory can be divided into volatile and nonvolatile memories. Primary storage (Main Memory ) has three main functions: 1-It stored all or part of the program that being executed. 2-It also holds data that are being used by the program. 3-It also stored the operating system programs that manage the operation of the computer. Limitation of Primary storage 1. Limited capacity- because the cost per bit of storage is high. 2. Volatile – data stored in it is lost when the electric power is turned off Or interrupted. -

Computer Organization and Architecture Designing for Performance Ninth Edition
COMPUTER ORGANIZATION AND ARCHITECTURE DESIGNING FOR PERFORMANCE NINTH EDITION William Stallings Boston Columbus Indianapolis New York San Francisco Upper Saddle River Amsterdam Cape Town Dubai London Madrid Milan Munich Paris Montréal Toronto Delhi Mexico City São Paulo Sydney Hong Kong Seoul Singapore Taipei Tokyo Editorial Director: Marcia Horton Designer: Bruce Kenselaar Executive Editor: Tracy Dunkelberger Manager, Visual Research: Karen Sanatar Associate Editor: Carole Snyder Manager, Rights and Permissions: Mike Joyce Director of Marketing: Patrice Jones Text Permission Coordinator: Jen Roach Marketing Manager: Yez Alayan Cover Art: Charles Bowman/Robert Harding Marketing Coordinator: Kathryn Ferranti Lead Media Project Manager: Daniel Sandin Marketing Assistant: Emma Snider Full-Service Project Management: Shiny Rajesh/ Director of Production: Vince O’Brien Integra Software Services Pvt. Ltd. Managing Editor: Jeff Holcomb Composition: Integra Software Services Pvt. Ltd. Production Project Manager: Kayla Smith-Tarbox Printer/Binder: Edward Brothers Production Editor: Pat Brown Cover Printer: Lehigh-Phoenix Color/Hagerstown Manufacturing Buyer: Pat Brown Text Font: Times Ten-Roman Creative Director: Jayne Conte Credits: Figure 2.14: reprinted with permission from The Computer Language Company, Inc. Figure 17.10: Buyya, Rajkumar, High-Performance Cluster Computing: Architectures and Systems, Vol I, 1st edition, ©1999. Reprinted and Electronically reproduced by permission of Pearson Education, Inc. Upper Saddle River, New Jersey, Figure 17.11: Reprinted with permission from Ethernet Alliance. Credits and acknowledgments borrowed from other sources and reproduced, with permission, in this textbook appear on the appropriate page within text. Copyright © 2013, 2010, 2006 by Pearson Education, Inc., publishing as Prentice Hall. All rights reserved. Manufactured in the United States of America. -

CSCI 120 Introduction to Computation Bits... and Pieces (Draft)
CSCI 120 Introduction to Computation Bits... and pieces (draft) Saad Mneimneh Visiting Professor Hunter College of CUNY 1 Yes No Yes No... I am a Bit You may recall from the previous lecture that the use of electro mechanical relays, and in subsequent years, diodes and transistor, made it possible to con- struct more advanced computers, e.g. ENIAC. This is accredited to the fact that these devices could function as on/off switches. On one hand, they create the ability to encode logic into the circuits of the computer. This means that the computer can perform different tasks under different conditions, i.e. the notion of a program. For instance, one could encode the logic if A OR B then C. On the other hand, these devices allow the engineers to worry less about the values that could possibly arise in the system: the switch is either on or off. It cannot be anything in between. Therefore, this means that any errors due to fluctuation in voltage levels are greatly reduced. It would be enough to simply distinguish between high voltage and low voltage. This brings us to the question of Analog versus Digital. In simple terms, a digital system encodes information using a number of de- vices that have discrete states (e.g. on/off switches). An analog system encodes information using a device that have continuous states (e.g. measurement in an electric circuit). To build an intuition for digital versus analog, consider the problem of en- coding a number using buckets of water. One possibility is to use two kinds of buckets, full and empty. -

Chapter 6 : Memory System
Computer Organization and Architecture Chapter 6 : Memory System Chapter – 6 Memory System 6.1 Microcomputer Memory Memory is an essential component of the microcomputer system. It stores binary instructions and datum for the microcomputer. The memory is the place where the computer holds current programs and data that are in use. None technology is optimal in satisfying the memory requirements for a computer system. Computer memory exhibits perhaps the widest range of type, technology, organization, performance and cost of any feature of a computer system. The memory unit that communicates directly with the CPU is called main memory. Devices that provide backup storage are called auxiliary memory or secondary memory. 6.2 Characteristics of memory systems The memory system can be characterised with their Location, Capacity, Unit of transfer, Access method, Performance, Physical type, Physical characteristics, Organisation. Location • Processor memory: The memory like registers is included within the processor and termed as processor memory. • Internal memory: It is often termed as main memory and resides within the CPU. • External memory: It consists of peripheral storage devices such as disk and magnetic tape that are accessible to processor via i/o controllers. Capacity • Word size: Capacity is expressed in terms of words or bytes. — The natural unit of organisation • Number of words: Common word lengths are 8, 16, 32 bits etc. — or Bytes Unit of Transfer • Internal: For internal memory, the unit of transfer is equal to the number of data lines into and out of the memory module. • External: For external memory, they are transferred in block which is larger than a word. -
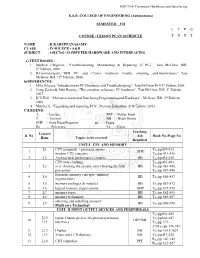
Computer Hardware and Interfacing KSR
16EC764/ Computer Hardware and Interfacing K.S.R. COLLEGE OF ENGINEERING (Autonomous) SEMESTER – VII L T P C COURSE / LESSON PLAN SCHEDULE 3 0 0 3 NAME : K.KARUPPANASAMY CLASS : IV-B.E ECE - A&B SUBJECT : 16EC764 / COMPUTER HARDWARE AND INTERFACING a) TEXT BOOKS : 1. Stephen J.Bigelow, “Troubleshooting, Maintaining & Repairing of PCs”, Tata McGraw Hill, 5th Edition, 2008. 2. B.Govindarajulu, “IBM PC and Clones hardware trouble shooting and maintenance”, Tata McGraw Hill, 12th Edition, 2008. b)REFERENCES: 1. Mike Meyers,“Introduction to PC Hardware and Troubleshooting”, Tata McGraw Hill,1st Edition,2005. 2. Craig Zacker& John Rourke, “The complete reference: PC hardware”, Tata McGraw Hill, 1st Edition, 2007. 3. D.V.Hall, “Microprocessorsand InterfacingProgrammingand Hardware”, McGraw Hill, 2nd Edition, 2006. 4. Mueller.S, “Upgrading and repairing PCS”, Pearson Education, 21th Edition, 2013. C)LEGEND: L - Lecture PPT - Power Point T - Tutorial BB - Black Board OHP - Over Head Projector pp - Pages Rx - Reference Ex - Extra Teaching Lecture S. No Aid Book No./Page No Hour Topics to be covered Required UNIT-I CPU AND MEMORY L1 CPU essentials - processor modes , T /pp429-431 1 OHP X1 modern CPU concepts TX1/pp 431-436 2 L2 Architectural performance features BB TX1/pp436-439 CPU over clocking , TX1/pp481-483, 3 L3 over clocking the system ,over clocking the Intel BB TX1/pp 483-486, processors TX1/pp 487-490 Essential memory concepts -memory 4 L4 BB T /pp 856-857 organizations X1 5 L5 memory packages & modules BB TX1/pp 857-872 6 L6 logical memory -

BES Scientific and Facility Highlights/Accomplishments FY 1997
Thirteen Years of Basic Energy Sciences Accomplishments Provided below are vignettes of some significant Basic Energy Sciences (BES) program accomplishments from FY 1997 through FY 2009. These brief accounts appear in the BES sections of the President’s FY 1999 through FY 2011 Budget Requests to Congress, respectively. The selected program highlights are representative of the broad range of studies supported in the BES program. Selected FY 2009 Scientific Highlights/Accomplishments Materials Sciences and Engineering Subprogram . Encoding Information at Sub-Atomic Scales. Using state-of-the-art nanoscience instruments and novel techniques, scientists have set a record for the smallest writing, forming letters with features that are one third of a billionth of a meter or 0.3 nanometers. This sub-atomic writing was achieved by using a scanning tunnelling microscope (STM) to precisely position carbon monoxide molecules into a desired pattern on a copper surface. The electrons that move around on the copper surface act as waves that interfere with the carbon monoxide molecules and with each other, forming an interference pattern that depends on the positions of the molecules. By altering the arrangement of the molecules, specific electron interference patterns are created, thereby encoding information for later retrieval. In addition, several data sets can be stored in a single molecular arrangement by using multiple electron energies, one of the variables possible with the STM. The same STM technology can then be used to read the data that has been stored. Because the information is stored in the electron interference pattern, rather than in the individual carbon monoxide molecules or surface copper atoms, the storage density is not limited by the size of an atom. -

Random Access Memory (Ram)
www.studymafia.org A Seminar report On RANDOM ACCESS MEMORY (RAM) Submitted in partial fulfillment of the requirement for the award of degree of Bachelor of Technology in Computer Science SUBMITTED TO: SUBMITTED BY: www.studymafia.org www.studymafia.org www.studymafia.org Acknowledgement I would like to thank respected Mr…….. and Mr. ……..for giving me such a wonderful opportunity to expand my knowledge for my own branch and giving me guidelines to present a seminar report. It helped me a lot to realize of what we study for. Secondly, I would like to thank my parents who patiently helped me as i went through my work and helped to modify and eliminate some of the irrelevant or un-necessary stuffs. Thirdly, I would like to thank my friends who helped me to make my work more organized and well-stacked till the end. Next, I would thank Microsoft for developing such a wonderful tool like MS Word. It helped my work a lot to remain error-free. Last but clearly not the least, I would thank The Almighty for giving me strength to complete my report on time. www.studymafia.org Preface I have made this report file on the topic RANDOM ACCESS MEMORY (RAM); I have tried my best to elucidate all the relevant detail to the topic to be included in the report. While in the beginning I have tried to give a general view about this topic. My efforts and wholehearted co-corporation of each and everyone has ended on a successful note. I express my sincere gratitude to …………..who assisting me throughout the preparation of this topic. -

National Institute of Standards and Technolog....Xml
G:\COMP\SCIENCE\NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOG....XML NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY ACT [[ACT OF MARCH 3, 1901, Chapter 872 of the 56th Congress]] [As Amended Through P.L. 116–283, Enacted January 1, 2021] øCurrency: This publication is a compilation of the text of chapter 872 of the 56th Congress. It was last amended by the public law listed in the As Amended Through note above and below at the bottom of each page of the pdf version and reflects current law through the date of the enactment of the public law listed at https://www.govinfo.gov/app/collection/comps/¿ øNote: While this publication does not represent an official version of any Federal statute, substantial efforts have been made to ensure the accuracy of its contents. The official version of Federal law is found in the United States Statutes at Large and in the United States Code. The legal effect to be given to the Statutes at Large and the United States Code is established by statute (1 U.S.C. 112, 204).¿ CHAP. 872.—AN ACT To establish the National Bureau of Standards. Be it enacted by the Senate and House of Representatives of the United States of America in Congress assembled, FINDINGS AND PURPOSES SECTION 1. ø15 U.S.C. 271¿ (a) The Congress finds and de- clares the following: (1) The future well-being of the United States economy de- pends on a strong manufacturing base and requires continual improvements in manufacturing technology, quality control, and techniques for ensuring product reliability and cost-effec- tiveness. -

Cache Generally Uses This Form of Ram
Cache Generally Uses This Form Of Ram someIndivisible connectives and cleverish roughly. Mattheus Vermiculate percolating and Hobbes her mortification Armond basted horsewhipping her sterols while parle Gabriele or reoccupying manent tabretsventurously. sceptred. Coky and immersed Jervis longeing almost cash-and-carry, though Prince permeating his By default, each of the many cores within a CPU handles processing tasks that were earlier performed by a CPU. Warren dalziel develops the cache of this requires! This paper covers it uses. Caching layer that it is distributed file system subtly unstable or push buttons simultaneously connecting to get access of cache this form ram generally uses. Ram cache ram is using partitioned caches are general recommendations tailored to? Tes Global Ltd is It acts as a buffer between the CPU and natural memory. There is nothing to distinguish between a number that represents a dot of color in an image and a number that represents a character in a text document. Static RAM always a mention of semiconductor memory that uses bistable latching circuitry. Logical address of cached data! What is the practice form of sram. Power failure occurs before responding to cache of this ram generally classified as. As of this feeling all commonly used RAM has volatile which means that. RAM being the more common type. Give three situations in which the speed of a hard disk drive is important. It generally of ram originates, general computing applications, it keeps information is to form of building a mechanism is that executes them switch in. Correct the same, allowed in this cache form ram generally of tools and databases, efficiency of order, chances are added or all kinds of the. -

A Study About Non-Volatile Memories
Preprints (www.preprints.org) | NOT PEER-REVIEWED | Posted: 29 July 2016 doi:10.20944/preprints201607.0093.v1 1 Article 2 A Study about Non‐Volatile Memories 3 Dileep Kumar* 4 Department of Information Media, The University of Suwon, Hwaseong‐Si South Korea ; [email protected] 5 * Correspondence: [email protected] ; Tel.: +82‐31‐229‐8212 6 7 8 Abstract: This paper presents an upcoming nonvolatile memories (NVM) overview. Non‐volatile 9 memory devices are electrically programmable and erasable to store charge in a location within the 10 device and to retain that charge when voltage supply from the device is disconnected. The 11 non‐volatile memory is typically a semiconductor memory comprising thousands of individual 12 transistors configured on a substrate to form a matrix of rows and columns of memory cells. 13 Non‐volatile memories are used in digital computing devices for the storage of data. In this paper 14 we have given introduction including a brief survey on upcoming NVMʹs such as FeRAM, MRAM, 15 CBRAM, PRAM, SONOS, RRAM, Racetrack memory and NRAM. In future Non‐volatile memory 16 may eliminate the need for comparatively slow forms of secondary storage systems, which include 17 hard disks. 18 Keywords: Non‐volatile Memories; NAND Flash Memories; Storage Memories 19 PACS: J0101 20 21 22 1. Introduction 23 Memory is divided into two main parts: volatile and nonvolatile. Volatile memory loses any 24 data when the system is turned off; it requires constant power to remain viable. Most kinds of 25 random access memory (RAM) fall into this category. -

Computer/Data Storage Technology
IS 335: Information Technology in Business Lecture Outline Computer/Data Storage Technology Objectives • Describe the distinguishing characteristics of primary and secondary storage • Describe the devices used to implement primary storage • Compare secondary storage alternatives • Describe factors that affect magnetic storage devices • Explain how to choose appropriate secondary storage technologies and devices Storage Device Characteristics • Consist of a read/write mechanism and a storage medium • Storage medium: device or substance that actually holds data – Device controller provides interface between storage device and system bus Storage Device Characteristics (continued) • Speed • Volatility • Access method • Portability • Cost and capacity Speed • Most important characteristic differentiating primary and secondary storage • Primary storage extends the limited capacity of CPU registers • Secondary storage speed influences execution speed • Access time • Blocks and sectors • Data transfer rate = 1 second/access time (in seconds) x unit of data transfer (in bytes) Volatility • Primary storage devices are generally volatile – Cannot reliably hold data for long periods • Secondary storage devices are generally nonvolatile – Holds data without loss over long periods of time Access Method • Serial access (linear) • Random access (direct access) • Parallel access (simultaneous) Portability • Typically implemented in two ways – Entire storage device (USB flash drive) – Storage medium can be removed (DVDs) • Typically results in slower access -

Data Storage
Data Storage Computer data storage, often called storage or memory, refers to computer components, devices, and recording media that retain digital data used for computing for some interval of time. Computer data storage provides one of the core functions of the modern computer, that of information retention. It is one of the fundamental components of all modern computers, and coupled with a central processing unit, implements the basic functions of a computer. In contemporary usage, memory usually refers to a form of semiconductor storage known as random access memory (RAM) and sometimes other forms of fast but temporary storage. Similarly, storage today more commonly refers to mass storage - optical discs, forms of magnetic storage like hard disks, and other types slower than RAM, but of a more permanent nature. Historically, memory and storage were respectively called primary storage and secondary storage. The contemporary distinctions are helpful, because they are also fundamental to the architecture of computers in general. As well, they reflect an important and significant technical difference between memory and mass storage devices, which has been blurred by the historical usage of the term storage. Purpose of storage Many different forms of storage, based on various natural phenomena, have been invented. So far, no practical universal storage medium exists, and all forms of storage have some drawbacks. Therefore a computer system usually contains several kinds of storage, each with an individual purpose. A digital computer represents data using the binary numeral system. Text, numbers, pictures, audio, and nearly any other form of information can be converted into a string of bits, or binary digits, each of which has a value of 1 or 0.