Adaptation Dynamique Par Tissage D'aspects D'assemblage
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Souhrada Awaits Trial, Maintains Innocence
The Volume V, Issue 21 March 19, 1996 Steal this issue. Profile: SOUHRADA AWAITS TRIAL, Gordon Bauer MAINTAINS INNOCENCE by Aaron Olk by Michelle Wolper Souhrada was released from the Gordon Bauer, psychology professor Ernest Souhrada is awaiting arraign Sarasota County Jail on March 8, the and Social Science Chair, was in Hawaii ment. The New College community is same day of his arrest. J. Alder, correc doing research on humpback whales and waiting for a complete story. While most tions officer at the jail, said that Afford working for the Veterans details cannot be disclosed at this time able Bail Bonds posted his bail amount of ~ u: Administration until he due to legal complications, Souhrada is $3508. Souhrada now awaits his arraign 0 came to New College five defending his innocence, while his ac ment, scheduled for April 19. a: a.. years ago. cuser has come forward. Alford has also made a statement re Bauer was working with Stephenie Alford and another uniden garding Harry's theft and her confession veterans plagued by post-traumatic stress tified source told University Police on to the police. disorder (JYTSD), an illness similar to March 7 that Souhrada, Alford's es "The students need to have the shell shock and battle fatigue, in an at tranged husband, stole Harry, the computer which was taken from them tempt to better understand the disease. computer that served as a student server Bauer said that the opinion most people in Hanson Lab. She also told police under SEE "SOUHRADA" ON PAGE 2 had at the time was that "there must be oath that Souhrada had changed the exte something wrong with the JYTSD victim rior container of Harry at the residence to begin with." that they shared at the time. -

The Complete Solutions Guide for Every Linux/Windows System Administrator!
Integrating Linux and Windows Integrating Linux and Windows By Mike McCune Publisher : Prentice Hall PTR Pub Date : December 19, 2000 ISBN : 0-13-030670-3 • Pages : 416 The complete solutions guide for every Linux/Windows system administrator! This complete Linux/Windows integration guide offers detailed coverage of dual- boot issues, data compatibility, and networking. It also handles topics such as implementing Samba file/print services for Windows workstations and providing cross-platform database access. Running Linux and Windows in the same environment? Here's the comprehensive, up-to-the-minute solutions guide you've been searching for! In Integrating Linux and Windows, top consultant Mike McCune brings together hundreds of solutions for the problems that Linux/Windows system administrators encounter most often. McCune focuses on the critical interoperability issues real businesses face: networking, program/data compatibility, dual-boot systems, and more. You'll discover exactly how to: Use Samba and Linux to deliver high-performance, low-cost file and print services to Windows workstations Compare and implement the best Linux/Windows connectivity techniques: NFS, FTP, remote commands, secure shell, telnet, and more Provide reliable data exchange between Microsoft Office and StarOffice for Linux Provide high-performance cross-platform database access via ODBC Make the most of platform-independent, browser-based applications Manage Linux and Windows on the same workstation: boot managers, partitioning, compressed drives, file systems, and more. For anyone running both Linux and Windows, McCune delivers honest and objective explanations of all your integration options, plus realistic, proven solutions you won't find anywhere else. Integrating Linux and Windows will help you keep your users happy, your costs under control, and your sanity intact! 1 Integrating Linux and Windows 2 Integrating Linux and Windows Library of Congress Cataloging-in-Publication Data McCune, Mike. -

Introducción a Linux Equivalencias Windows En Linux Ivalencias
No has iniciado sesión Discusión Contribuciones Crear una cuenta Acceder Página discusión Leer Editar Ver historial Buscar Introducción a Linux Equivalencias Windows en Linux Portada < Introducción a Linux Categorías de libros Equivalencias Windows en GNU/Linux es una lista de equivalencias, reemplazos y software Cam bios recientes Libro aleatorio análogo a Windows en GNU/Linux y viceversa. Ayuda Contenido [ocultar] Donaciones 1 Algunas diferencias entre los programas para Windows y GNU/Linux Comunidad 2 Redes y Conectividad Café 3 Trabajando con archivos Portal de la comunidad 4 Software de escritorio Subproyectos 5 Multimedia Recetario 5.1 Audio y reproductores de CD Wikichicos 5.2 Gráficos 5.3 Video y otros Imprimir/exportar 6 Ofimática/negocios Crear un libro 7 Juegos Descargar como PDF Versión para im primir 8 Programación y Desarrollo 9 Software para Servidores Herramientas 10 Científicos y Prog s Especiales 11 Otros Cambios relacionados 12 Enlaces externos Subir archivo 12.1 Notas Páginas especiales Enlace permanente Información de la Algunas diferencias entre los programas para Windows y y página Enlace corto GNU/Linux [ editar ] Citar esta página La mayoría de los programas de Windows son hechos con el principio de "Todo en uno" (cada Idiomas desarrollador agrega todo a su producto). De la misma forma, a este principio le llaman el Añadir enlaces "Estilo-Windows". Redes y Conectividad [ editar ] Descripción del programa, Windows GNU/Linux tareas ejecutadas Firefox (Iceweasel) Opera [NL] Internet Explorer Konqueror Netscape / -

Pipenightdreams Osgcal-Doc Mumudvb Mpg123-Alsa Tbb
pipenightdreams osgcal-doc mumudvb mpg123-alsa tbb-examples libgammu4-dbg gcc-4.1-doc snort-rules-default davical cutmp3 libevolution5.0-cil aspell-am python-gobject-doc openoffice.org-l10n-mn libc6-xen xserver-xorg trophy-data t38modem pioneers-console libnb-platform10-java libgtkglext1-ruby libboost-wave1.39-dev drgenius bfbtester libchromexvmcpro1 isdnutils-xtools ubuntuone-client openoffice.org2-math openoffice.org-l10n-lt lsb-cxx-ia32 kdeartwork-emoticons-kde4 wmpuzzle trafshow python-plplot lx-gdb link-monitor-applet libscm-dev liblog-agent-logger-perl libccrtp-doc libclass-throwable-perl kde-i18n-csb jack-jconv hamradio-menus coinor-libvol-doc msx-emulator bitbake nabi language-pack-gnome-zh libpaperg popularity-contest xracer-tools xfont-nexus opendrim-lmp-baseserver libvorbisfile-ruby liblinebreak-doc libgfcui-2.0-0c2a-dbg libblacs-mpi-dev dict-freedict-spa-eng blender-ogrexml aspell-da x11-apps openoffice.org-l10n-lv openoffice.org-l10n-nl pnmtopng libodbcinstq1 libhsqldb-java-doc libmono-addins-gui0.2-cil sg3-utils linux-backports-modules-alsa-2.6.31-19-generic yorick-yeti-gsl python-pymssql plasma-widget-cpuload mcpp gpsim-lcd cl-csv libhtml-clean-perl asterisk-dbg apt-dater-dbg libgnome-mag1-dev language-pack-gnome-yo python-crypto svn-autoreleasedeb sugar-terminal-activity mii-diag maria-doc libplexus-component-api-java-doc libhugs-hgl-bundled libchipcard-libgwenhywfar47-plugins libghc6-random-dev freefem3d ezmlm cakephp-scripts aspell-ar ara-byte not+sparc openoffice.org-l10n-nn linux-backports-modules-karmic-generic-pae -

Review, Email Clients with Source Code Editing
Review, Email Clients with Source Code Editing By Micheline Johnson Updated 2013-12-05 Why is source code editing desirable? It enables the addition of variable indenting and hanging indents, tables, images, charts, videos etc. the replacement of <p> tags with <div> tags, if para spacing is not required. Wikipedia lists most email clients. Of these, the free Windows or cross-platform GUI email clients are included in the Appendix. Of these, the current mainstream desktop GUI email clients include: 1. Outlook, overkill for most purposes, and is not free. 2. Outlook Express, not available for Windows 7 3. Windows Live Mail 4. Mozilla Thunderbird, does not natively support HTML editing or tables. 5. Eudora v7.1, runs on Microsoft Windows XP/2000 (http://www.eudora.com/download/). It has problems with Windows 7, see http://mcaf.ee/cxsw8 . It runs on Windows XP, and does not appear to support editing HTML source code, or tables. 6. Eureka Email. It is very difficult to uninstall, see http://mcaf.ee/1q0ka , so I did not test it. 7. Pegasus Mail. Pegasus v4.63 allows the insertion of a table and the editing of the number of rows or columns of that table; but it does not support editing of HTML source code. It supports hanging indents to increments of one tab spacing, which is very crude. 8. DreamMail 9. FoxMail 10. SeaMonkey. http://www.seamonkey-project.org/. Allows inserting of tables. Appears to allow insertion of HTML code, but does not allow viewing of the entire HTML source code. 11. Netscape Messenger used to have an HTML editor. -
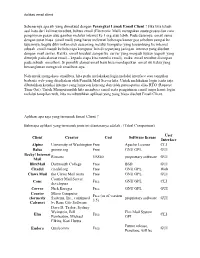
Sebenarnya Apa Sih Yang Dimaksud Dengan Perangkat Lunak Email Client
Aplikasi email client Sebenarnya apa sih yang dimaksud dengan Perangkat Lunak Email Client ? Jika kita telaah asal kata dari kalimat tersebut, bahwa email (Electronic Mail) merupakan suatu proses dan cara pengiriman pesan atau gambar melalui internet ke 1 org atau lebih. Pada dasarnya email sama dengan surat biasa (snail mail) yang harus melewati beberapa kantor pos sebelum sampai ke tujuannya, begitu dikirimkan oleh seseorang melalui komputer yang tersambung ke internet sebuah email masuk ke beberapa komputer lain di sepanjang jaringan internet yang disebut dengan mail server. Ketika email tersebut sampai ke server yang menjadi tujuan (seperti yang ditunjuk pada alamat email – kepada siapa kita menulis email), maka email tersebut disimpan pada sebuah emailbox. Si pemilik alamat email baru bisa mendapatkan email itu kalau yang bersangkutan mengecek emailbox-nya. Nah untuk mengakses emailbox, kita perlu melakukan login melalui interface atau tampilan berbasis web yang disediakan oleh Pemilik Mail Server kita. Untuk melakukan login tentu saja dibutuhkan koneksi internet yang lumayan kencang dan tidak putus-putus alias RTO (Request Time Out). Untuk Mempermudah kita membaca email serta pengiriman email tanpa harus login melalui tampilan web, kita membutuhkan aplikasi yang yang biasa disebut Email Client. Aplikasi apa saja yang termasuk Email Client ? Beberapa aplikasi yang termasuk jenis ini diantaranya adalah : (Tabel Comparison) User Client Creator Cost Software license Interface Alpine University of Washington Free Apache License CLI Balsa gnome.org Free GNU GPL GUI Becky! Internet Rimarts US$40 proprietary software GUI Mail BlitzMail Dartmouth College Free BSD GUI Citadel citadel.org Free GNU GPL Web Claws Mail the Claws Mail team Free GNU GPL GUI Courier Mail Server Cone Free GNU GPL CLI developers Correo Nick Kreeger Free GNU GPL GUI Courier Micro Computer Free (as of version (formerly Systems, Inc., continued proprietary software GUI 3.5) Calypso) by Rose City Software Dave D. -

US Fish and Wildlife Service 1889-1985
Selected Research Publication Series of the U.S. Fish and Wildlife Service 1889-1985 UNITED STATES DEPARTMENT OF THE INTERIOR FISH AND WILDLIFE SERVICE / RESOURCE PUBLICATION 159 Resource Publication This publication of the Fish and Wildlife Service is one of a series of semitechnical or instructional materials dealing with investigations related to wildlife and fish. Each is published as a separate paper. The Service distributes a limited number of these reports for the use of Federal and State agencies and cooperators. Copies of this publication may be obtained from the Publications Unit, U.S. Fish and Wildlife Service, Matomic Building, Room 148, Washington, DC 20240, or may be purchased from the Government Print ing Office, Superintendent of Documents, Washington, DC 20402, and the National Technical Informa tion Service (NTIS), 5285 Port Royal Road, Springfield, VA 22161. Library of Congress Cataloging-in-Publication Data Research and development series. (Resource publication / United States Department of the Interior, Fish and Wildlife Service ; 159) Bibliography: p. 163 Supt.ofDocs.no.: 1:49.66:159 1. U.S. Fish and Wildlife Service-Bibliography. 2. Wild life management—United States—Bibliography. 3. Wildlife conservation—United States—Bibliography. I. Cortese, Thomas J. II. Groshek, Barbara A. III. Series: Resource publication (U.S. Fish and Wildlife Service); 159. S914.A3 no. 159 [016.639] 86-600039 [Z7994.W55] [SK361] Selected Research Publication Series of the U.S . Fish and Wildlife Service, 1889-1985 Compiled by Thomas J. Cortese Barbara A. Groshek UNITED STATES DEPARTMENT OF THE INTERIOR FISH AND WILDLIFE SERVICE Resource Publication 159 Washington, DC " 1987 Preface This bibliography provides a detailed record of publications in 10 selected Research and Development series produced by the U.S . -

Selected Essays of Richard M. Stallman
Free Software, Free Society: Selected Essays of Richard M. Stallman Introduction by Lawrence Lessig Edited by Joshua Gay GNU Press www.gnupress.org Free Software Foundation Boston, MA USA First printing, first edition. Copyright © 2002 Free Software Foundation, Inc. ISBN 1-882114-98-1 Published by the Free Software Foundation 59 Temple Place Boston, MA Tel: 1-617-542-5942 Fax: 1-617-542-2652 Email: [email protected] Web: www.gnu.org GNU Press is an imprint of the FSF. Email: [email protected] Web: www.gnupress.org Please contact the GNU Press for information regarding bulk purchases for class- room or user group use, reselling, or any other questions or comments. Original artwork by Etienne Suvasa. Cover design by Jonathan Richard. Permission is granted to make and distribute verbatim copies of this book provided the copyright notice and this permission notice are preserved on all copies. Permission is granted to copy and distribute translations of this book into another language, from the original English, with respect to the conditions on distribution of modified versions above, provided that it has been approved by the Free Software Foundation. i Short Contents Editor’s Note................................................ 1 A Note on Software .......................................... 3 Topic Guide ................................................ 7 Introduction ............................................... 11 Section One ............................................... 15 1 The GNU Project ....................................... 17 2 The GNU Manifesto ..................................... 33 3 Free Software Definition ................................. 43 4 Why Software Should Not Have Owners ..................... 47 5 What’s in a Name? ...................................... 53 6 Why “Free Software” is Better than “Open Source” ............ 57 7 Releasing Free Software if You Work at a University ........... 63 8 Selling Free Software ................................... -

Towards Left Duff S Mdbg Holt Winters Gai Incl Tax Drupal Fapi Icici
jimportneoneo_clienterrorentitynotfoundrelatedtonoeneo_j_sdn neo_j_traversalcyperneo_jclientpy_neo_neo_jneo_jphpgraphesrelsjshelltraverserwritebatchtransactioneventhandlerbatchinsertereverymangraphenedbgraphdatabaseserviceneo_j_communityjconfigurationjserverstartnodenotintransactionexceptionrest_graphdbneographytransactionfailureexceptionrelationshipentityneo_j_ogmsdnwrappingneoserverbootstrappergraphrepositoryneo_j_graphdbnodeentityembeddedgraphdatabaseneo_jtemplate neo_j_spatialcypher_neo_jneo_j_cyphercypher_querynoe_jcypherneo_jrestclientpy_neoallshortestpathscypher_querieslinkuriousneoclipseexecutionresultbatch_importerwebadmingraphdatabasetimetreegraphawarerelatedtoviacypherqueryrecorelationshiptypespringrestgraphdatabaseflockdbneomodelneo_j_rbshortpathpersistable withindistancegraphdbneo_jneo_j_webadminmiddle_ground_betweenanormcypher materialised handaling hinted finds_nothingbulbsbulbflowrexprorexster cayleygremlintitandborient_dbaurelius tinkerpoptitan_cassandratitan_graph_dbtitan_graphorientdbtitan rexter enough_ram arangotinkerpop_gremlinpyorientlinkset arangodb_graphfoxxodocumentarangodborientjssails_orientdborientgraphexectedbaasbox spark_javarddrddsunpersist asigned aql fetchplanoriento bsonobjectpyspark_rddrddmatrixfactorizationmodelresultiterablemlibpushdownlineage transforamtionspark_rddpairrddreducebykeymappartitionstakeorderedrowmatrixpair_rddblockmanagerlinearregressionwithsgddstreamsencouter fieldtypes spark_dataframejavarddgroupbykeyorg_apache_spark_rddlabeledpointdatabricksaggregatebykeyjavasparkcontextsaveastextfilejavapairdstreamcombinebykeysparkcontext_textfilejavadstreammappartitionswithindexupdatestatebykeyreducebykeyandwindowrepartitioning -

List Software Pengganti Windows Ke Linux
Tabel Padanan Aplikasi Windows di Linux Untuk Migrasi Selasa, 18-08-2009 Kesulitan besar dalam melakukan migrasi dari Windows ke Linux adalah mencari software pengganti yang berkesesuaian. Berikut ini adalah tabel padanan aplikasi Windows di Linux yang disusun dalam beberapa kategori. Nama Program Windows Linux 1) Networking. 1) Netscape / Mozilla. 2) Galeon. 3) Konqueror. 4) Opera. [Prop] Internet Explorer, 5) Firefox. Web browser Netscape / Mozilla, Opera 6) Nautilus. [Prop], Firefox, ... 7) Epiphany. 8) Links. (with "-g" key). 9) Dillo. 10) Encompass. 1) Links. 1) Links 2) ELinks. Console web browser 2) Lynx 3) Lynx. 3) Xemacs + w3. 4) w3m. 5) Xemacs + w3. 1) Evolution. 2) Netscape / Mozilla/Thunderbird messenger. 3) Sylpheed / Claws Mail. 4) Kmail. Outlook Express, 5) Gnus. Netscape / Mozilla, 6) Balsa. Thunderbird, The Bat, 7) Bynari Insight GroupWare Suite. Email client Eudora, Becky, Datula, [Prop] Sylpheed / Claws Mail, 8) Arrow. Opera 9) Gnumail. 10) Althea. 11) Liamail. 12) Aethera. 13) MailWarrior. 14) Opera. 1) Evolution. Email client / PIM in MS 2) Bynari Insight GroupWare Suite. Outlook Outlook style [Prop] 3) Aethera. 4) Sylpheed. 5) Claws Mail 1) Sylpheed. 2) Claws Mail Email client in The Bat The Bat 3) Kmail. style 4) Gnus. 5) Balsa. 1) Pine. [NF] 2) Mutt. Mutt [de], Pine, Pegasus, Console email client 3) Gnus. Emacs 4) Elm. 5) Emacs. 1) Knode. 2) Pan. 1) Agent [Prop] 3) NewsReader. 2) Free Agent 4) Netscape / Mozilla Thunderbird. 3) Xnews 5) Opera [Prop] 4) Outlook 6) Sylpheed / Claws Mail. 5) Netscape / Mozilla Console: News reader 6) Opera [Prop] 7) Pine. [NF] 7) Sylpheed / Claws Mail 8) Mutt. -
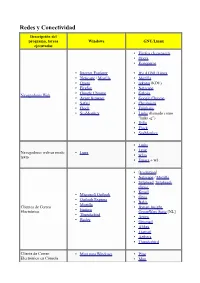
Redes Y Conectividad Descripción Del Programa, Tareas Windows GNU/Linux Ejecutadas • Firefox (Iceweasel) • Opera • Konqueror
Redes y Conectividad Descripción del programa, tareas Windows GNU/Linux ejecutadas • Firefox (Iceweasel) • Opera • Konqueror • Internet Explorer • IEs 4 GNU/Linux • Netscape / Mozilla • Mozilla • Opera • rekonq (KDE) • Firefox • Netscape • Google Chrome • Galeón Navegadores Web • Avant Browser • Google Chrome • Safari • Chromium • Flock • Epiphany • SeaMonkey • Links (llamado como "links -g") • Dillo • Flock • SeaMonkey • Links • • Lynx Navegadores web en modo Lynx • texto w3m • Emacs + w3. • [Evolution] • Netscape / Mozilla • Sylpheed , Sylpheed- claws. • Kmail • Microsoft Outlook • Gnus • Outlook Express • Balsa • Mozilla Clientes de Correo • Bynari Insight • Eudora Electrónico GroupWare Suite [NL] • Thunderbird • Arrow • Becky • Gnumail • Althea • Liamail • Aethera • Thunderbird Cliente de Correo • Mutt para Windows • Pine Electrónico en Cónsola • Mutt • Gnus • de , Pine para Windows • Elm. • Xemacs • Liferea • Knode. • Pan • Xnews , Outlook, • NewsReader Lector de noticias Netscape / Mozilla • Netscape / Mozilla. • Sylpheed / Sylpheed- claws • MultiGet • Orbit Downloader • Downloader para X. • MetaProducts Download • Caitoo (former Kget). Express • Prozilla . • Flashget • wxDownloadFast . • Go!zilla • Kget (KDE). Gestor de Descargas • Reget • Wget (console, standard). • Getright GUI: Kmago, QTget, • Wget para Windows Xget, ... • Download Accelerator Plus • Aria. • Axel. • Httrack. • WWW Offline Explorer. • Wget (consola, estándar). GUI: Kmago, QTget, Extractor de Sitios Web Teleport Pro, Webripper. Xget, ... • Downloader para X. • -

Migration from Windows to Linux for a Small Engineering Firm "A&G Associates"
Rochester Institute of Technology RIT Scholar Works Theses 2004 Migration from Windows to Linux for a small engineering firm "A&G Associates" Trimbak Vohra Follow this and additional works at: https://scholarworks.rit.edu/theses Recommended Citation Vohra, Trimbak, "Migration from Windows to Linux for a small engineering firm A&G" Associates"" (2004). Thesis. Rochester Institute of Technology. Accessed from This Thesis is brought to you for free and open access by RIT Scholar Works. It has been accepted for inclusion in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact [email protected]. Migration from Windows to Linux for a Small Engineering Firm "A&G Associates" (H ' _T ^^L. WBBmBmBBBBmb- Windows Linux by Trimbak Vohra Thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Information Technology Rochester Institute of Technology B. Thomas Golisano College of Computing and Information Sciences Date: December 2, 2004 12/B2/28B2 14:46 5854752181 RIT INFORMATION TECH PAGE 02 Rochester Institute of Teehnology B. Thomas Golisano College of Computing and Information Sciences Master of Science in Information Technology Thesis Approval Form Student Name: Trimbak Vohra Thesis Title: Migration from Windows to Unux for a Small Engineeriog Firm "A&G Associates" Thesis Committee Name Signature Date Luther Troell luther IrQell, Ph.D ttL ",j7/Uy Chair G. L. Barido Prof. ~~orge Barido ? - Dec:. -cl7' Committee Member Thomas Oxford Mr. Thomas OxfocQ \ 2. L~( Q~ Committee Member Thesis Reproduction Permission Form Rochester Institute of Technology B. Thomas Golisano College of Computing and Information Sciences Master of Science in Information Technology Migration from Windows to Linux for a Small Engineering Firm "A&G Associates" I,Trimbak Vohra, hereby grant permission to the Wallace Library of the Rochester Institute of Technology to reproduce my thesis in whole or in part.