Missing People in Casanare
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Meta River Report Card
Meta River 2016 Report Card c Casanare b Lower Meta Tame CASANARE RIVER Cravo Norte Hato Corozal Puerto Carreño d+ Upper Meta Paz de Ariporo Pore La Primavera Yopal Aguazul c Middle Meta Garagoa Maní META RIVER Villanueva Villavicencio Puerto Gaitán c+ Meta Manacacías Puerto López MANACACÍAS RIVER Human nutrition Mining in sensitive ecosystems Characteristics of the MAN & AG LE GOV E P RE ER M O TU N E E L A N P U N RI C T Meta River Basin C TA V / E ER E M B Water The Meta River originates in the Andes and is the largest I O quality index sub-basin of the Colombian portion of the Orinoco River D I R V E (1,250 km long and 10,673,344 ha in area). Due to its size E B C T R A H A Risks to S S T and varied land-uses, the Meta sub-basin has been split I I L W T N HEA water into five reporting regions for this assessment, the Upper River Y quality EC S dolphins & OSY TEM L S S Water supply Meta, Meta Manacacías, Middle Meta, Casanare and Lower ANDSCAPE Meta. The basin includes many ecosystem types such as & demand Ecosystem the Páramo, Andean forests, flooded savannas, and flooded Fire frequency services forests. Main threats to the sub-basin are from livestock expansion, pollution by urban areas and by the oil and gas Natural industry, natural habitat loss by mining and agro-industry, and land cover Terrestrial growing conflict between different sectors for water supply. -

BPXC's Operations in Casanare, Colombia
Paper Number 31 July 1999 BPXCs Operations in Casanare, Colombia: Factoring social concerns into development decisionmaking Aidan Davy Kathryn McPhail Favian Sandoval Moreno Social Development Papers Paper Number 31 July 1999 BPXCs Operations in Casanare, Colombia: Factoring social concerns into development decisionmaking Aidan Davy Kathryn McPhail Favian Sandoval Moreno This publication was developed and produced by the Social Development Family of the World Bank. The Environment, Rural Development, and Social Development Families are part of the Environmentally and Socially Sustainable Development (ESSD) Network. The Social Development Family is made up of World Bank staff working on social issues. Papers in the Social Development series are not formal publications of the World Bank. They are published informally and circulated to encourage discussion and comment within the development community. The findings, interpretations, judgments, and conclusions expressed in this paper are those of the author(s) and should not be attributed to the World Bank, to its affiliated organizations, or to members of the Board of Executive Directors or the governments they represent. Copies of this paper are available from: Social Development The World Bank 1818 H Street, N.W. Washington, D.C. 20433 USA Fax: 202-522-3247 E-mail: [email protected] Contents Executive Summary 1 1. Introduction 7 Aims and Objectives 7 Approach 8 Project Location 8 Main Issues to Factor into the Evaluation 9 Route Map to the Report 9 2. An Evolving Social and Environmental Context 11 Description of BPXCs Operations 11 The Environmental Context of BPXCs Operations 13 The Social Context of BPXCs Operations 13 Key Stakeholders and Their Interactions 13 The Evolving Demographic and Socioeconomic Context 16 Conflict in Casanare 19 3. -

ESTMA Identification Number E798884 Amended Report
Extractive Sector Transparency Measures Act - Annual Report Reporting Entity Name Parex Resources Inc. Reporting Year From 2020-01-01 To: 2020-12-31 Date submitted 2021-05-26 Original Submission Reporting Entity ESTMA Identification Number E798884 Amended Report Other Subsidiaries Included (optional field) Not Consolidated Not Substituted Attestation Through Independent Audit In accordance with the requirements of the ESTMA, and in particular section 9 thereof, I attest that I engaged an independent auditor to undertake an audit of the ESTMA report for the entity(ies) and reporting year listed above. Such an audit was conducted in accordance with the Technical Reporting Specifications issued by Natural Resources Canada for independent attestation of ESTMA reports. The auditor expressed an unmodified opinion, dated YYYY-MM-DD, on the ESTMA Report for the entity(ies) and period listed above. The independent auditor's report can be found at Calgary. Full Name of Director or Officer of Reporting Entity Kenneth G. Pinsky Date 2021-05-26 Position Title Chief Financial Officer Extractive Sector Transparency Measures Act - Annual Report Reporting Year From: 2020-01-01 To: 2020-12-31 Reporting Entity Name Parex Resources Inc. Currency of the Report USD Reporting Entity ESTMA Identification E798884 Number Subsidiary Reporting Entities (if necessary) Payments by Payee Departments, Agency, etc… Infrastructure Total Amount paid to Country Payee Name within Payee that Received Taxes Royalties Fees Production Entitlements Bonuses Dividends Notes Improvement -
Presentación De Powerpoint
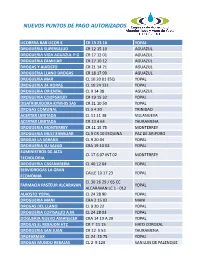
NUEVOS PUNTOS DE PAGO AUTORIZADOS LICORERA BAR LICOR S CR 19 23 10 YOPAL DROGUERIA SUPERSALUD CR 12 15 10 AGUAZUL DROGUERIA VIDA AGUAZUL P G CR 17 12 01 AGUAZUL DROGUERIA FAMILIAR CR 17 10 12 AGUAZUL DROGAS Y ALKOSTO CR 21 14 71 AGUAZUL DROGUERIA LLANO DROGAS CR 18 17 99 AGUAZUL DROGUERIA MAR CL 10 20 01 ESQ YOPAL DROGUERIA 24 HORAS CL 10 24 131 YOPAL DROGUERIA ORIENTAL CL 9 14 38 AGUAZUL DROGUERIA COOPSALUD CR 19 15 32 YOPAL DISATRIBUIDORA KYWHIS SAS CR 21 10 50 YOPAL DROGAS COMUNAL CL 5 4 20 TRINIDAD ACERTAR LIMITADA CL 11 11 38 VILLANUEVA ACERTAR LIMITADA CR 13 4 64 TAURAMENA DROGUERIA MONTERREY CR 11 15 75 MONTERREY DROGUERIA MULTIFAMILIAR CL 9 CR 10 ESQUINA PAZ DE ARIPORO DROGAS LA SABANA CL 9 20 04 YOPAL DROGUERIA SU SALUD CRA 19 10 02 YOPAL SUMINISTROS DE ALTA CL 17 6 07 INT 02 MONTERREY TECNOLOGIA DROGUERIA CASANAREÑA CL 40 12 04 YOPAL SERVIDROGAS LA GRAN CALLE 10 17 23 YOPAL ECONOMIA CL 30 26 29 / 65 CC FARMACIA PASTEUR ALCARAVAN YOPAL ALCARAVAN LC 1 - 012 ALKOSTO YOPAL CL 24 28 90 YOPAL DROGUERIA MANI CRA 2 15 02 MANI DROGAS DEL LLANO CL 9 20 22 YOPAL DROGUERIA COPISALUD A.M. CL 24 28 03 YOPAL DOGUERIA NUEVO AMANECER CRA 14 19 A 20 YOPAL DROGAS EL REBAJON HTZ CR 7 11 15 HATO COROZAL DROGUERIA SAN JUAN CR 12 5 53 TAURAMENA DROFARMAX CL 24 25 75 YOPAL DROGAS MUNDO REBAJAS CL 2 9 123 SAN LUIS DE PALENQUE NUEVOS PUNTOS DE PAGO AUTORIZADOS DROGUERIA ANFREX SALUD CL 16 21 05 YOPAL DROGUERIA COLFAM CL 15 17 67 AGUAZUL DROGUERIA SU SALUD 2 CL 9 16 29 AGUAZUL DROGUERIA SAN JUAN CARRERA 16 # 36B-26 YOPAL CASANARE BRR EL PORTAL DROGUERIA -

“La Corocora” Alza El Vuelo En Investigación Para El Casanare
Investigación - Fedearroz - Fondo Nacional del Arroz 28 “LA COROCORA” ALZA EL VUELO EN INVESTIGACIÓN PARA EL CASANARE Ph. D. Mario Sandoval C* M. Sc. Jose Omar Ospina G* Ing. Juan Carlos Diaz* Ing. Jorge Ardila Cuevas * *Investigador y transferidor FEDEARROZ- Fondo Nacional del Arroz-FNA. La Corocora, nombre que identifica una de las aves más hermosas y representativas de los Llanos Orientales, lo es también de la granja que será modernizada y tecnificada como uno de los componentes centrales del proyecto de investigación, que con el objetivo de obtener variedades de arroz específicas para el departamento de Casanare, ha empezado a ser desarrollado como resultado de los esfuerzos compartidos entre Fedearroz, La gobernación, la alcaldía de Aguazul y la Universidad Unitrópico. Es el punto de partida de un gran Centro Experimental para el arroz en ese departamento, que es hoy el mayor productor del grano en el país y que le permitirá avanzar en los diferentes aspectos agronómicos de este cultivo. El siguiente artículo, hace un recorrido por los antecedentes y los diferentes aspectos puntuales del proyecto que ya está en ejecución. Vol. 66 - Noviembre - Diciembre 2018 Investigación - Fedearroz - Fondo Nacional del Arroz 29 ¿Como inició el proyecto? • Programa de Genética: Con los subprogramas de Fitomejoramiento convencional y Biotecnología. Hoy en día uno de los principales desafíos lo constituye el cambio • Programa de Agronomía: Con los subprogramas de climático que ejerce presión sobre la genética de las plantas y Fisiología de la producción y Manejo Integrado de Plagas la capacidad productiva de las tierras agrícolas afectando el (Malherbología, Insectos, Enfermedades) crecimiento económico agrícola de las regiones. -

Disponibilidad Hídrica, Cambio Climático Y Configuraciones Territoriales En Tauramena, Casanare
DISPONIBILIDAD HÍDRICA, CAMBIO CLIMÁTICO Y CONFIGURACIONES TERRITORIALES EN TAURAMENA, CASANARE IVONNE ANGÉLICA MONTAÑA MOLINA UNIVERSIDAD EXTERNADO DE COLOMBIA FACULTAD DE CIENCIAS SOCIALES Y HUMANAS ÁREA DE DEMOGRAFÍA Y ESTUDIOS DE POBLACIÓN BOGOTÁ D.C. 2019 DISPONIBILIDAD HÍDRICA, CAMBIO CLIMÁTICO Y CONFIGURACIONES TERRITORIALES EN TAURAMENA, CASANARE IVONNE ANGÉLICA MONTAÑA MOLINA Trabajo de grado presentado como requisito para optar al título de: Magíster en Planeación Territorial y Dinámicas de Población Asesores: Norma Rubiano Orlando Velazco Docentes Área de Demografía y Estudios de Población Proyecto Marco: Planeación Territorial, Dinámicas Poblacionales Y Cambio Climático UNIVERSIDAD EXTERNADO DE COLOMBIA FACULTAD DE CIENCIAS SOCIALES Y HUMANAS CENTRO DE ESTUDIOS SOBRE DINÁMICA SOCIAL (CIDS) ÁREA DE DEMOGRAFÍA Y ESTUDIOS DE POBLACIÓN BOGOTÁ D.C. 2019 1 AGRADECIMIENTOS En primer lugar, agradezco a la vida por los distintos caminos que me han llevado a la Universidad Externado, pues allí no sólo he crecido como profesional y ahora magíster, sino que he crecido como una persona con conciencia ético-política crítica y un compromiso hacia la transformación que incorpora al ser y trasciende al colectivo. Agradezco a la doctora Lucero Zamudio (Q.E.P.D.) y a los docentes del área de Demografía y Estudios de Población, especialmente al equipo que desarrolla BIT-PASE: Norma Rubiano, Alejandro González, Juan Andrés Castro, Orlando Velasco y Rafael Navarro; ellas y ellos me han brindado las oportunidades para aprender en un entorno de crecimiento pleno, personal e intelectual. Agradezco infinitamente a mis padres, Alicia Molina y Fernando Montaña, quienes han dado absolutamente todo de sí mismos para apoyarme incondicionalmente en el cumplimiento de mis objetivos. -

Algunos Indicadores Sobre La Situación De Los Derechos Humanos En El Departamento De Casanare
Actualizado a marzo de 2005 ALGUNOS INDICADORES SOBRE LA SITUACIÓN DE LOS DERECHOS HUMANOS EN EL DEPARTAMENTO DE CASANARE DEDEPARTAMENTO DE CASANARE El departamento del Casanare es hoy un complejo escenario de la confrontación armada por el accionar de los grupos guerrilleros y en especial, de autodefensa. Las condiciones geográficas y económicas del departamento han convertido su territorio en una zona estratégica para los grupos al margen de la ley que se disputan su dominio. Casanare presenta estribaciones de la cordillera occidental aunque se encuentra ubicado en los llanos orientales del país. Limita con Arauca en el norte, Boyacá en el occidente y, Vichada y Meta en el suroriente y en el sur, departamentos que desde hace varias décadas han tenido una alta actividad armada por parte de los grupos insurgentes y de autodefensa. Topográficamente, Casanare tiene una parte montañosa en su parte occidental y un terreno plano en el centro y en el sector oriental, situación que favorece la presencia y movilidad de los grupos de guerrilla y autodefensa. La incursión de los grupos de autodefensa y de guerrilla tiene sus raíces en los reductos de la violencia de los años cincuenta. En 1980, las FARC OBSERVATORIO DEL PROGRAMA PRESIDENCIAL DE DERECHOS 1 HUMANOS Y DIH Actualizado a marzo de 2005 mostraban una incipiente presencia en este departamento, sin embargo alrededor de la década de los noventa, motivadas por objetivos estratégicos de expansión territorial, consignados en las conclusiones de su Séptima Conferencia (1982) y sus intereses en torno al dominio de la cordillera oriental, al auge petrolero y al fortalecimiento del narcotráfico, posiciona en esta zona dos de sus frentes pertenecientes al bloque Oriental. -

2014-10-15 Diálogo Regional DNP Yopal VF.Pdf
Departamento Nacional de Planeación www.dnp.gov.co Todos por un nuevo país DIÁLOGO REGIONAL PARA LA CONSTRUCCIÓN DEL PLAN NACIONAL DE DESARROLLO 2014-2018 Bogotá, octubre 16 de 2014 LLANOS - CASANARE Todos por un nuevo país AGENDA 01 02 Enfoque metodológico y Los Llanos planteamiento estratégico en el PND2014-2018 PND 2014-2018 03 04 Situación actual y Proyectos estratégicos perspectivas para Casanare Todos por un nuevo país 01 Planteamiento estratégico PND 2014 -2018 Todos por un nuevo país 01 Secuencia de preparación del PND 2014-2018 COMPONENTES PASOS PARA LA ELABORACIÓN Planteamiento de diagnóstico y propuestas Bases Proceso de construcción con regiones por primera vez Consulta previa con grupos étnicos Plan plurianual de inversiones Las bases son entregadas al CNP y consultadas con la sociedad civil Se consolida un documento para socializar Articulado Se elaboran el plan plurianual de inversiones y el articulado para presentar al Congreso Todos por un nuevo país 01 Planteamiento estratégico PND 2014-2018 No necesariamente existe correspondencia entre ejecución presupuestal y resultados Ejecución presupuestal y logro de metas del PND a agosto de 2014 PND 79% 88% Vivienda 83% Transporte e Infraestructura 75% 61% 72% Trabajo 89% 72% TIC 78% 84% Salud y Protección Social 81% 77% Relaciones Exteriores 100% Minas y Energía 74% 50% 62% Justicia y del Derecho 83% 61% Interior 86% Inclusión Social y Reconciliación 77% Ejecución 47% 71% Hacienda y Crédito Público 93% Avances PND 59% Función Pública 91% 71% Educación 86% 68% Deporte y Recreación -

RESOLUCION No. 296 DE 2020
C0NTRAL0RA DEPARTAMENTAL DE CASANARE —NIT. 800183.9129— RESOLUCION No. 296 DE 2020 (29 de septiembre de 2020) "For medio de Ia cual se derogan las Resoluciones 088 del 4 de marzo y 215 del 26 de Iunio de 2020, y en consecuencia se reglamentan los Sujetos y Puntos de Control a cargo de Ia ContralorIa Departamental de Casanare" LA CONTRALORA DEPARTAMENTAL DE CASANARE, En uso de sus facultades Constitucionales y Legales, especialmente las conferidas en el artIculo 9 de Ia Ley 330 de 1996 y, CO NSID E RAN DO Que el articulo 267 de Ia Constituciôn PolItica de Colombia, establece que el control fiscal es una funciOn publica atribuible a Ia Contraloria General de Ia Republica, Ia cual se ejerce en forma posterior y selectiva de conformidad con los procedimientos, sistemas y principios que establece Ia ley para vigilar Ia gestion fiscal de Ia administración nacional en todos sus niveles y Ia de los particulares o entidades que manejan fondos o bienes de Ia nación, al igual que las entidades territoriales tanto del nivel central como el descentralizado. Que a su vez Ia precitada norma señala que Ia vigilancia de Ia gestión fiscal de los departamentos, distritos y municipios donde haya Contralorias corresponde a éstas y se ejercerá en forma posterior y selectiva, y faculta a los contralores de este nivel para ejercer en el ámbito de su jurisdicción las funciones atribuidas al Contralor General de Ia Repüblica. Que el artIculo 20 de Ia Ley 42 de 1993 define quienes son sujetos de control fiscal, en los siguientes términos: 'Son sujetos de control -

Casanare 4-8-2014
PROGRAMA DE APOYO AL SECTOR ARROCERO 2014 PRODUCTORES INSCRITOS PRIMER SEMESTRE DE 2014 DEPARTAMENTO DE CASANARE PRIMER LISTADO 4 de agosto de 2014 AREA PRODUCCION MAXIMA N° DEPARTAMENTO MUNICIPIO APELLIDO NOMBRE IDENTIFICACION REGISTRADA (Ton de paddy verde) (Has) 1 CASANARE AGUAZUL ACOSTA MENDOZA JOSE GREGORIO 74751800 345 1.725 2 CASANARE AGUAZUL ACOSTA MONTAÑA OSCAR EUSEBIO 74752227 39 195 3 CASANARE AGUAZUL BARRAGAN MOLINA RAUL FERNANDO 10542189 55 275 4 CASANARE AGUAZUL BERNAL BARON SANDRA TIBISAY 1116543899 80 400 5 CASANARE AGUAZUL BERNAL GUTIERREZ DANILO 74751131 60 300 6 CASANARE AGUAZUL BONILLA DIEZ LUIS AUGUSTO 79949358 113 565 7 CASANARE AGUAZUL CABIATIVA RIAÑO FABIAN CAMILO 1116548213 5 25 8 CASANARE AGUAZUL CACHAY RODRIGUEZ MARTHA SOFIA 24228743 50 250 9 CASANARE AGUAZUL CADENA MANCHAY LILIA 52551624 80 400 10 CASANARE AGUAZUL CALLE ROJAS URSULA 49770666 27 135 11 CASANARE AGUAZUL CARVAJAL PINZON HERNANDO JOAQUIN 7178872 36 180 12 CASANARE AGUAZUL CASTRO ALONSO JORGE HUMBERTO 19216941 100 500 13 CASANARE AGUAZUL CHAPARRO PEREZ YONY ANTONIO 74811772 50 250 14 CASANARE AGUAZUL CONTRERAS DE SANDOVAL MARTHA 40760351 52 260 15 CASANARE AGUAZUL DIAZ BARRERA LUIS ALEJANDRO 9513529 92 460 16 CASANARE AGUAZUL DIAZ CHAPARRO DIEGO ABRAHAM 74085492 40 200 17 CASANARE AGUAZUL DIAZ GALINDO JOSE GUILLERMO 4295193 112 560 18 CASANARE AGUAZUL DIAZ NIÑO GONZALO 74750838 45 225 19 CASANARE AGUAZUL DIAZ RAMIREZ OSCAR 74861867 6 30 20 CASANARE AGUAZUL DIAZ RODRIGUEZ OSCAR ALBEIRO 1116542829 34 170 21 CASANARE AGUAZUL DURAN BUAVABE LUZ MARINA -

Documento Línea Base De La Subzona Hidrográfica Del Río Cusiana
IMPLEMENTACIÓN DE LA TASA DE LA TASA RETRIBUTIVA CORPORACIÓN AUTÓNOMA REGIONAL DE LA ORINOQUIA SUBDIRECCIÓN DE PLANEACIÓN AMBIENTAL JULIO 2019 Contenido 1. INTRODUCCIÓN ...................................................................................................................................................................................................... 5 2. OBJETIVO ................................................................................................................................................................................................................. 5 3. ALCANCE ................................................................................................................................................................................................................. 6 4. JUSTIFICACIÓN ....................................................................................................................................................................................................... 6 5. DIAGNÓSTICO GENERAL DE LA SUBZONA HIDROGRÁFICA DEL RÍO CUSIANA ...................................................................................... 7 5.1 Localización de la Subzona Hidrográfica del Río Cusiana ........................................................................................................................... 7 ...................................................................................................................................................................................................................................... -

El Casanare: Futuro Centro Competitivo De La Región Juan D. González
El Casanare: futuro centro competitivo de la región Juan D. González González Yuri M. Vargas Urrego Martha L. Vargas Bacci Resumen El Casanare se caracteriza por ser un territorio principalmente agrícola, sus extensos territorios le otorgan a este departamento la ventaja de producir en grandes cantidades productos agrícolas y pecuarios destacando en esta última las representativas cifras de cabezas de ganado que se comercializan en la región. Las producciones con mayor presencia en la zona son quienes cuentan con asociaciones capaces de acceder y solicitar múltiples recursos a las entidades gubernamentales beneficiando simultáneamente la comunidad con la masificación y la mejora de procesos productivos. En el presente la gobernación del departamento adelanta la vinculación de empresas privadas que cuentan con presencia en algunos municipios con el fin de fortalecer las relaciones comerciales entre estas entidades y la región. Esta alianza estratégica permitirá desarrollar nuevos mercados para los productores locales. El objetivo de todo el ejercicio económico promovido por los sectores públicos y privados debe ser la formalización de las actividades productivas, guiadas por las asociaciones involucradas en la comercialización de los productos y Estudiante de Mercadeo. Universidad de los Llanos. Facultad de Ciencias Económicas. Programa de Mercadeo. Territorio y Ambiente. Correo: [email protected] Estudiante de Mercadeo. Universidad de los Llanos. Facultad de Ciencias Económicas. Programa de Mercadeo. Territorio y Ambiente. Correo: [email protected] Magister en Mercadeo Agroindutrial. Docente de Mercadeo. Universidad de los Llanos. Facultad de Ciencias Económicas. Programa de Mercadeo. Territorio y Ambiente. Correo: [email protected] que busquen mejorar la competitividad de la zona centro e incluso del departamento con respecto a la región orinoquense.