Proceedings of the 6Th Workshop on South and Southeast Asian Natural Language Processing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Universality, Similarity, and Translation in the Wikipedia Inter-Language Link Network
In Search of the Ur-Wikipedia: Universality, Similarity, and Translation in the Wikipedia Inter-language Link Network Morten Warncke-Wang1, Anuradha Uduwage1, Zhenhua Dong2, John Riedl1 1GroupLens Research Dept. of Computer Science and Engineering 2Dept. of Information Technical Science University of Minnesota Nankai University Minneapolis, Minnesota Tianjin, China {morten,uduwage,riedl}@cs.umn.edu [email protected] ABSTRACT 1. INTRODUCTION Wikipedia has become one of the primary encyclopaedic in- The world: seven seas separating seven continents, seven formation repositories on the World Wide Web. It started billion people in 193 nations. The world's knowledge: 283 in 2001 with a single edition in the English language and has Wikipedias totalling more than 20 million articles. Some since expanded to more than 20 million articles in 283 lan- of the content that is contained within these Wikipedias is guages. Criss-crossing between the Wikipedias is an inter- probably shared between them; for instance it is likely that language link network, connecting the articles of one edition they will all have an article about Wikipedia itself. This of Wikipedia to another. We describe characteristics of ar- leads us to ask whether there exists some ur-Wikipedia, a ticles covered by nearly all Wikipedias and those covered by set of universal knowledge that any human encyclopaedia only a single language edition, we use the network to under- will contain, regardless of language, culture, etc? With such stand how we can judge the similarity between Wikipedias a large number of Wikipedia editions, what can we learn based on concept coverage, and we investigate the flow of about the knowledge in the ur-Wikipedia? translation between a selection of the larger Wikipedias. -

Multilingual Ranking of Wikipedia Articles with Quality and Popularity Assessment in Different Topics
computers Article Multilingual Ranking of Wikipedia Articles with Quality and Popularity Assessment in Different Topics Włodzimierz Lewoniewski * , Krzysztof W˛ecel and Witold Abramowicz Department of Information Systems, Pozna´nUniversity of Economics and Business, 61-875 Pozna´n,Poland * Correspondence: [email protected]; Tel.: +48-(61)-639-27-93 Received: 10 May 2019; Accepted: 13 August 2019; Published: 14 August 2019 Abstract: On Wikipedia, articles about various topics can be created and edited independently in each language version. Therefore, the quality of information about the same topic depends on the language. Any interested user can improve an article and that improvement may depend on the popularity of the article. The goal of this study is to show what topics are best represented in different language versions of Wikipedia using results of quality assessment for over 39 million articles in 55 languages. In this paper, we also analyze how popular selected topics are among readers and authors in various languages. We used two approaches to assign articles to various topics. First, we selected 27 main multilingual categories and analyzed all their connections with sub-categories based on information extracted from over 10 million categories in 55 language versions. To classify the articles to one of the 27 main categories, we took into account over 400 million links from articles to over 10 million categories and over 26 million links between categories. In the second approach, we used data from DBpedia and Wikidata. We also showed how the results of the study can be used to build local and global rankings of the Wikipedia content. -

The Dravidian Languages
THE DRAVIDIAN LANGUAGES BHADRIRAJU KRISHNAMURTI The Pitt Building, Trumpington Street, Cambridge, United Kingdom The Edinburgh Building, Cambridge CB2 2RU, UK 40 West 20th Street, New York, NY 10011–4211, USA 477 Williamstown Road, Port Melbourne, VIC 3207, Australia Ruiz de Alarc´on 13, 28014 Madrid, Spain Dock House, The Waterfront, Cape Town 8001, South Africa http://www.cambridge.org C Bhadriraju Krishnamurti 2003 This book is in copyright. Subject to statutory exception and to the provisions of relevant collective licensing agreements, no reproduction of any part may take place without the written permission of Cambridge University Press. First published 2003 Printed in the United Kingdom at the University Press, Cambridge Typeface Times New Roman 9/13 pt System LATEX2ε [TB] A catalogue record for this book is available from the British Library ISBN 0521 77111 0hardback CONTENTS List of illustrations page xi List of tables xii Preface xv Acknowledgements xviii Note on transliteration and symbols xx List of abbreviations xxiii 1 Introduction 1.1 The name Dravidian 1 1.2 Dravidians: prehistory and culture 2 1.3 The Dravidian languages as a family 16 1.4 Names of languages, geographical distribution and demographic details 19 1.5 Typological features of the Dravidian languages 27 1.6 Dravidian studies, past and present 30 1.7 Dravidian and Indo-Aryan 35 1.8 Affinity between Dravidian and languages outside India 43 2 Phonology: descriptive 2.1 Introduction 48 2.2 Vowels 49 2.3 Consonants 52 2.4 Suprasegmental features 58 2.5 Sandhi or morphophonemics 60 Appendix. Phonemic inventories of individual languages 61 3 The writing systems of the major literary languages 3.1 Origins 78 3.2 Telugu–Kannada. -

Requiem-For-Our-Times-E-Book.Pdf
Like those in his earlier book, The Losers Shall Inherit the World, these articles too were first published in Frontier and deal with current socio-economic-cultural issues of a diverse range of topics. These include, Sanskrit, Hinduism, Bhimsen Joshi, Education Manifesto, Euthanasia, Small States, Population, Cities, Peak Oil and the Politics of Non-Violence. There are also two small articles dealing with the Passion (Christ’s suffering at the Cross) and the concept of Liberation. ‘If a political activist can be defined as a person who is not only trying to promote the interests of his own particular group or class but trying, generally speaking, to create a better world, then she must first have a good understanding of the state of the present-day world. And then Vijayendra’s article (Yugant in this book) is a must-read for her, because it is an excellent short introduction to the subject.’ Saral Sarkar, author of Eco-Socialism You can read this book online or download a copy at www.peakoilindia.org REQUIEM FOR OUR TIMES T. Vijayendra SANGATYA REQUIEM FOR OUR TIMES Author: T. Vijayendra Copy Editor: Sajai Jose Year: 2015 Price: Rs. 100 Copies: 500 L Copy Left: All Rights Reversed Publishers: Sangatya Sahitya Bhandar Post Nakre, Taluk Karkala, Dist. Udupi Karnataka 576 117 Phone: 08258 205340 Email: [email protected] Blog: t-vijayendra.blogspot.com SCRIBD: vijayendra tungabhadra Mobile: +91 94907 05634 For Copies: Manchi Pustakam 12-13-439, St. No. 1 Tarnaka, Secunderabad 500017 Email: [email protected] Mobile: +91 73822 97430 Layout and Printing: Charita Impressions Azamabad, Hyderabad - 500 020. -

Depicting the Indian Diaspora
THE INDIAN DIASPORA & AN INDIAN IN COWBOY COUNTRY © Pradeep Anand Harvard University, April 24, 2007 www.pradeepanand.com When the South Asian organizers at Harvard University told me that the audience was interested in discussing how authors depict the Indian Diaspora, I was confronted with a topic that I had not thought about, ever. I had not set out to create a work of fiction about the Diaspora and I had never seen my book, An Indian in Cowboy Country, through those lenses before. When forced to think about this topic, my knee-jerk reaction was to be conventional and think about the global Indian Diaspora – from India to Fiji, to West Indies, to Yuba City, to British Columbia, to the countries of the Indian Ocean, to Great Britain, Canada, and the United States. My mind immediately went to the big, macro historical picture, with all these turbid rivers of brown-skinned workforce flowing out of the country, migrating to unknown destinations. I saw these huge torrents flowing out of India and I was a particle in it. And then something made me look at my own family history. At first blush, it seemed like I was one of the seeds of the global Indian Diaspora for just one generation. But then I recognized a reality. My family uprooted itself three generations ago, when my grandfather moved to Bangalore. That’s where my father grew up and then, he, in his turn, moved to Bombay. I grew up in Bombay and then I moved from Bombay to Texas. To put this in perspective, my family moved from a Tamil- speaking region to a Kannada-speaking one, then to a Marathi/Gujarati-speaking one, and finally to an English speaking one (at least for now). -

Identity and Language of Tamil Community in Malaysia: Issues and Challenges
DOI: 10.7763/IPEDR. 2012. V48. 17 Identity and Language of Tamil Community in Malaysia: Issues and Challenges + + + M. Rajantheran1 , Balakrishnan Muniapan2 and G. Manickam Govindaraju3 1Indian Studies Department, University of Malaya, Kuala Lumpur, Malaysia 2Swinburne University of Technology, Sarawak, Malaysia 3School of Communication, Taylor’s University, Subang Jaya, Malaysia Abstract. Malaysia’s ruling party came under scrutiny in the 2008 general election for the inability to resolve pressing issues confronted by the minority Malaysian Indian community. Some of the issues include unequal distribution of income, religion, education as well as unequal job opportunity. The ruling party’s affirmation came under critical situation again when the ruling government decided against recognising Tamil language as a subject for the major examination (SPM) in Malaysia. This move drew dissatisfaction among Indians, especially the Tamil community because it is considered as a move to destroy the identity of Tamils. Utilising social theory, this paper looks into the fundamentals of the language and the repercussion of this move by Malaysian government and the effect to the Malaysian Indians identity. Keywords: Identity, Tamil, Education, Marginalisation. 1. Introduction Concepts of identity and community had been long debated in the arena of sociology, anthropology and social philosophy. Every community has distinctive identities that are based upon values, attitudes, beliefs and norms. All identities emerge within a system of social relations and representations (Guibernau, 2007). Identity of a community is largely related to the race it represents. Race matters because it is one of the ways to distinguish and segregate people besides being a heated political matter (Higginbotham, 2006). -

The Combined Wordnet Bahasa
The combined Wordnet Bahasa Francis B?, Lian Tze L⋄, Enya Kong T† and Hammam R‡ ?Nanyang Technological University, Singapore ⋄KDU College Penang †Linton University College, Malaysia ‡Agency for the Assessment and Application of Technology, Indonesia [email protected], [email protected], [email protected], [email protected] This paper outlines the creation of an open combined semantic lexicon as a resource for the study of lexical semantics in the Malay languages (Malaysian and Indonesian). It is created by combining three earlier wordnets, each built using different resources and approaches: the Malay Wordnet (Lim & Hussein 2006), the Indonesian Wordnet (Riza, Budiono & Hakim 2010) and the Wordnet Bahasa (Nurril Hirfana, Sapuan & Bond 2011). The final wordnet has been validated and extended as part of sense annotation of the Indonesian portion of the NTU Multilingual Corpus (Tan & Bond 2012). The wordnet has over 48,000 concepts and 58,000 words for Indonesian and 38,000 concepts and 45,000 words for Malaysian. 1. Introduction1 This paper discusses the creation of a new release of the Open Wordnet Bahasa, an open- source semantic lexicon of Malay. The Wordnet is the result of merging with three wordnet projects for Malaysian and Indonesian, then adding data from other resources and finally by tagging a collection of Indonesian text. Up until now, there has been no richly linked, broad coverage semantic lexicon for Malay- sian and Indonesian. The Center of the International Cooperation for Computerization produced dictionaries for Malaysian and Indonesian (CICC 1994a,b) but the semantic hi- erarchy was limited to an upper level ontology for Indonesian. -

A Study on Divergence in Malayalam and Tamil Language in Machine Translation Perceptive
A Study on Divergence in Malayalam and Tamil Language in Machine Translation Perceptive Jisha P Jayan Elizabeth Sherly Virtual Resource Centre for Virtual Resource Centre for Language Computing Language Computing IIITM-K,Trivandrum IIITM-K,Trivandrum [email protected] [email protected] Abstract others are specific with respect to the language pair (Lavanya et al., 2005; Saboor and Khan, Machine Translation has made significant 2010). Hence, the divergence in the translation achievements for the past decades. How- need to be studied both perspectives that is across ever, in many languages, the complex- the languages and language specific pair (Sinha, ity with its rich inflection and agglutina- 2005).The most problematic area in translation is tion poses many challenges, that forced the lexicon and the role it plays in the act of creat- for manual translation to make the cor- ing deviations in sense and reference based on the pus available. The divergence in lexi- context of its occurrence in texts (Dash, 2013). cal, syntactic and semantic in any pair Indian languages come under Indo-Aryan or of languages makes machine translation Dravidian scripts. Though there are similarities more difficult. And many systems still de- in scripts, there are many issues and challenges pend on rules heavily, that deteriates sys- in translation between languages such as lexical tem performance. In this paper, a study divergences, ambiguities, lexical mismatches, re- on divergence in Malayalam-Tamil lan- ordering, syntactic and semantic issues, structural guages is attempted at source language changes etc. Human translators try to choose the analysis to make translation process easy. -

Historiographical Approaches to Past Archaeological Research
Historiographical Approaches to Past Archaeological Research Gisela Eberhardt Fabian Link (eds.) BERLIN STUDIES OF THE ANCIENT WORLD has become increasingly diverse in recent years due to developments in the historiography of the sciences and the human- ities. A move away from hagiography and presentations of scientifi c processes as an inevitable progression has been requested in this context. Historians of archae- olo gy have begun to utilize approved and new histo- rio graphical concepts to trace how archaeological knowledge has been acquired as well as to refl ect on the historical conditions and contexts in which knowledge has been generated. This volume seeks to contribute to this trend. By linking theories and models with case studies from the nineteenth and twentieth century, the authors illuminate implications of communication on archaeological knowledge and scrutinize routines of early archaeological practices. The usefulness of di erent approaches such as narratological concepts or the concepts of habitus is thus considered. berlin studies of 32 the ancient world berlin studies of the ancient world · 32 edited by topoi excellence cluster Historiographical Approaches to Past Archaeological Research edited by Gisela Eberhardt Fabian Link Bibliographic information published by the Deutsche Nationalbibliothek The Deutsche Nationalbibliothek lists this publication in the Deutsche Nationalbibliographie; detailed bibliographic data are available in the Internet at http://dnb.d-nb.de. © 2015 Edition Topoi / Exzellenzcluster Topoi der Freien Universität Berlin und der Humboldt-Universität zu Berlin Typographic concept and cover design: Stephan Fiedler Printed and distributed by PRO BUSINESS digital printing Deutschland GmbH, Berlin ISBN 978-3-9816384-1-7 URN urn:nbn:de:kobv:11-100233492 First published 2015 The text of this publication is licensed under Creative Commons BY-NC 3.0 DE. -

Looking at Popular Muslim Films Through the Lens of Genre
Rupkatha Journal on Interdisciplinary Studies in Humanities, Vol. IX, No. 1, 2017 0975-2935 DOI: https://dx.doi.org/10.21659/rupkatha.v9n1.17 Full Text: http://rupkatha.com/V9/n1/v9n117.pdf Is Islamicate a Genre? Looking at Popular Muslim Films through the Lens of Genre Asmita Das Department of Film Studies, Jadavpur University, Kolkata. ORCID: 0000-0002-7307-5818. Email: [email protected] Received February 25, 2017; Revised April 9, 2017; Accepted April 10, 2017; Published May 7, 2017. Abstract This essay engages with genre as a theory and how it can be used as a framework to determine whether Islamicate or the Muslim films can be called a genre by themselves, simply by their engagement with and representation of the Muslim culture or practice. This has been done drawing upon the influence of Hollywood in genre theory and arguments surrounding the feasibility / possibility of categorizing Hindi cinema in similar terms. The essay engages with films representing Muslim culture, and how they feed into the audience’s desires to be offered a window into another world (whether it is the past or the inner world behind the purdah). It will conclude by trying to ascertain whether the Islamicate films fall outside the categories of melodrama (which is the most prominent and an umbrella genre that is represented in Indian cinema) and forms a genre by itself or does the Islamicate form a sub-category within melodrama. Keywords: genre, Muslim socials, socials, Islamicate films, Hindi cinema, melodrama. 1. Introduction The close association between genre and popular culture (in this case cinema) ensured generic categories (structured by mass demands) to develop within cinema for its influence as a popular art. -
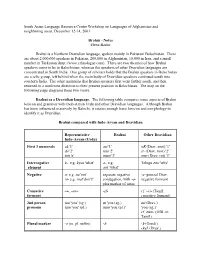
Introduction to Brahui
South Asian Language Resource Center Workshop on Languages of Afghanistan and neighboring areas, December 12-14, 2003 Brahui - Notes Elena Bashir Brahui is a Northern Dravidian language, spoken mainly in Pakistani Balochistan. There are about 2,000,000 speakers in Pakistan, 200,000 in Afghanistan, 10,000 in Iran, and a small number in Turkestan (http://www.ethnologue.com). There are two theories of how Brahui speakers come to be in Balochistan, whereas the speakers of other Dravidian languages are concentrated in South India. One group of scholars holds that the Brahui speakers in Balochistan are a relic group, left behind when the main body of Dravidian speakers continued south into southern India. The other maintains that Brahui speakers first went farther south, and then returned in a northwest direction to their present position in Balochistan. The map on the following page diagrams these two views. Brahui as a Dravidian language. The following table compares some aspects of Brahui lexicon and grammar with Indo-Aryan Urdu and other Dravidian languages. Although Brahui has been influenced massively by Balochi, it retains enough basic lexicon and morphology to identify it as Dravidian. Brahui compared with Indo-Aryan and Dravidian Representative Brahui Other Dravidian Indo-Aryan (Urdu) First 3 numerals ek '1' asi '1' oR (Drav. root) '1' do '2' iraa '2' ir- (Drav. root) '2' tiin 'e' musi '3' mur (Drav. rot) '3' Interrogative k-, e.g. kyaa 'what' a-, e.g. Telugu emi 'why' element ant 'what' Negative n- e.g. na 'not' separate negative -a- general Drav. m- e.g. -

Neo-Vernacularization of South Asian Languages
LLanguageanguage EEndangermentndangerment andand PPreservationreservation inin SSouthouth AAsiasia ed. by Hugo C. Cardoso Language Documentation & Conservation Special Publication No. 7 Language Endangerment and Preservation in South Asia ed. by Hugo C. Cardoso Language Documentation & Conservation Special Publication No. 7 PUBLISHED AS A SPECIAL PUBLICATION OF LANGUAGE DOCUMENTATION & CONSERVATION LANGUAGE ENDANGERMENT AND PRESERVATION IN SOUTH ASIA Special Publication No. 7 (January 2014) ed. by Hugo C. Cardoso LANGUAGE DOCUMENTATION & CONSERVATION Department of Linguistics, UHM Moore Hall 569 1890 East-West Road Honolulu, Hawai’i 96822 USA http:/nflrc.hawaii.edu/ldc UNIVERSITY OF HAWAI’I PRESS 2840 Kolowalu Street Honolulu, Hawai’i 96822-1888 USA © All text and images are copyright to the authors, 2014 Licensed under Creative Commons Attribution Non-Commercial No Derivatives License ISBN 978-0-9856211-4-8 http://hdl.handle.net/10125/4607 Contents Contributors iii Foreword 1 Hugo C. Cardoso 1 Death by other means: Neo-vernacularization of South Asian 3 languages E. Annamalai 2 Majority language death 19 Liudmila V. Khokhlova 3 Ahom and Tangsa: Case studies of language maintenance and 46 loss in North East India Stephen Morey 4 Script as a potential demarcator and stabilizer of languages in 78 South Asia Carmen Brandt 5 The lifecycle of Sri Lanka Malay 100 Umberto Ansaldo & Lisa Lim LANGUAGE ENDANGERMENT AND PRESERVATION IN SOUTH ASIA iii CONTRIBUTORS E. ANNAMALAI ([email protected]) is director emeritus of the Central Institute of Indian Languages, Mysore (India). He was chair of Terralingua, a non-profit organization to promote bi-cultural diversity and a panel member of the Endangered Languages Documentation Project, London.