Les Cartes Graphiques/Version Imprimable — Wik
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

High End Visualization with Scalable Display System
HIGH END VISUALIZATION WITH SCALABLE DISPLAY SYSTEM Dinesh M. Sarode*, Bose S.K.*, Dhekne P.S.*, Venkata P.P.K.*, Computer Division, Bhabha Atomic Research Centre, Mumbai, India Abstract display, then the large number of pixels shows the picture Today we can have huge datasets resulting from in greater details and interaction with it enables the computer simulations (CFD, physics, chemistry etc) and greater insight in understanding the data. However, the sensor measurements (medical, seismic and satellite). memory constraints, lack of the rendering power and the There is exponential growth in computational display resolution offered by even the most powerful requirements in scientific research. Modern parallel graphics workstation makes the visualization of this computers and Grid are providing the required magnitude difficult or impossible. computational power for the simulation runs. The rich While the cost-performance ratio for the component visualization is essential in interpreting the large, dynamic based on semiconductor technologies doubling in every data generated from these simulation runs. The 18 months or beyond that for graphics accelerator cards, visualization process maps these datasets onto graphical the display resolution is lagging far behind. The representations and then generates the pixel resolutions of the displays have been increasing at an representation. The large number of pixels shows the annual rate of 5% for the last two decades. The ability to picture in greater details and interaction with it enables scale the components: graphics accelerator and display by the greater insight on the part of user in understanding the combining them is the most cost-effective way to meet data more quickly, picking out small anomalies that could the ever-increasing demands for high resolution. -

Order Independent Transparency in Opengl 4.X Christoph Kubisch – [email protected] TRANSPARENT EFFECTS
Order Independent Transparency In OpenGL 4.x Christoph Kubisch – [email protected] TRANSPARENT EFFECTS . Photorealism: – Glass, transmissive materials – Participating media (smoke...) – Simplification of hair rendering . Scientific Visualization – Reveal obscured objects – Show data in layers 2 THE CHALLENGE . Blending Operator is not commutative . Front to Back . Back to Front – Sorting objects not sufficient – Sorting triangles not sufficient . Very costly, also many state changes . Need to sort „fragments“ 3 RENDERING APPROACHES . OpenGL 4.x allows various one- or two-pass variants . Previous high quality approaches – Stochastic Transparency [Enderton et al.] – Depth Peeling [Everitt] 3 peel layers – Caveat: Multiple scene passes model courtesy of PTC required Peak ~84 layers 4 RECORD & SORT 4 2 3 1 . Render Opaque – Depth-buffer rejects occluded layout (early_fragment_tests) in; fragments 1 2 3 . Render Transparent 4 – Record color + depth uvec2(packUnorm4x8 (color), floatBitsToUint (gl_FragCoord.z) ); . Resolve Transparent 1 2 3 4 – Fullscreen sort & blend per pixel 4 2 3 1 5 RESOLVE . Fullscreen pass uvec2 fragments[K]; // encodes color and depth – Not efficient to globally sort all fragments per pixel n = load (fragments); sort (fragments,n); – Sort K nearest correctly via vec4 color = vec4(0); register array for (i < n) { blend (color, fragments[i]); – Blend fullscreen on top of } framebuffer gl_FragColor = color; 6 TAIL HANDLING . Tail Handling: – Discard Fragments > K – Blend below sorted and hope error is not obvious [Salvi et al.] . Many close low alpha values are problematic . May not be frame- coherent (flicker) if blend is not primitive- ordered K = 4 K = 4 K = 16 Tailblend 7 RECORD TECHNIQUES . Unbounded: – Record all fragments that fit in scratch buffer – Find & Sort K closest later + fast record - slow resolve - out of memory issues 8 HOW TO STORE . -

POWERVR 3D Application Development Recommendations
Imagination Technologies Copyright POWERVR 3D Application Development Recommendations Copyright © 2009, Imagination Technologies Ltd. All Rights Reserved. This publication contains proprietary information which is protected by copyright. The information contained in this publication is subject to change without notice and is supplied 'as is' without warranty of any kind. Imagination Technologies and the Imagination Technologies logo are trademarks or registered trademarks of Imagination Technologies Limited. All other logos, products, trademarks and registered trademarks are the property of their respective owners. Filename : POWERVR. 3D Application Development Recommendations.1.7f.External.doc Version : 1.7f External Issue (Package: POWERVR SDK 2.05.25.0804) Issue Date : 07 Jul 2009 Author : POWERVR POWERVR 1 Revision 1.7f Imagination Technologies Copyright Contents 1. Introduction .................................................................................................................................4 1. Golden Rules...............................................................................................................................5 1.1. Batching.........................................................................................................................5 1.1.1. API Overhead ................................................................................................................5 1.2. Opaque objects must be correctly flagged as opaque..................................................6 1.3. Avoid mixing -
Rasterization & the Graphics Pipeline 15.1 Rasterization Basics
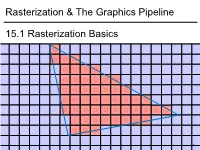
1 1 0.8 0.6 0.4 0.2 0 -0.2 -0.4 -0.6 -0.8 15.1Rasterization Basics Rasterization & TheGraphics Pipeline Rasterization& -1 -1 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 1 In This Video • The Graphics Pipeline and how it processes triangles – Projection, rasterisation, shading, depth testing • DirectX12 and its stages 2 Modern Graphics Pipeline • Input – Geometric model • Triangle vertices, vertex normals, texture coordinates – Lighting/material model (shader) • Light source positions, colors, intensities, etc. • Texture maps, specular/diffuse coefficients, etc. – Viewpoint + projection plane – You know this, you’ve done it! • Output – Color (+depth) per pixel Colbert & Krivanek 3 The Graphics Pipeline • Project vertices to 2D (image) • Rasterize triangle: find which pixels should be lit • Compute per-pixel color • Test visibility (Z-buffer), update frame buffer color 4 The Graphics Pipeline • Project vertices to 2D (image) • Rasterize triangle: find which pixels should be lit – For each pixel, test 3 edge equations • if all pass, draw pixel • Compute per-pixel color • Test visibility (Z-buffer), update frame buffer color 5 The Graphics Pipeline • Perform projection of vertices • Rasterize triangle: find which pixels should be lit • Compute per-pixel color • Test visibility, update frame buffer color – Store minimum distance to camera for each pixel in “Z-buffer” • ~same as tmin in ray casting! – if new_z < zbuffer[x,y] zbuffer[x,y]=new_z framebuffer[x,y]=new_color frame buffer Z buffer 6 The Graphics Pipeline For each triangle transform into eye space (perform projection) setup 3 edge equations for each pixel x,y if passes all edge equations compute z if z<zbuffer[x,y] zbuffer[x,y]=z framebuffer[x,y]=shade() 7 (Simplified version) DirectX 12 Pipeline (Vulkan & Metal are highly similar) Vertex & Textures, index data etc. -

Powervr Graphics - Latest Developments and Future Plans
PowerVR Graphics - Latest Developments and Future Plans Latest Developments and Future Plans A brief introduction • Joe Davis • Lead Developer Support Engineer, PowerVR Graphics • With Imagination’s PowerVR Developer Technology team for ~6 years • PowerVR Developer Technology • SDK, tools, documentation and developer support/relations (e.g. this session ) facebook.com/imgtec @PowerVRInsider │ #idc15 2 Company overview About Imagination Multimedia, processors, communications and cloud IP Driving IP innovation with unrivalled portfolio . Recognised leader in graphics, GPU compute and video IP . #3 design IP company world-wide* Ensigma Communications PowerVR Processors Graphics & GPU Compute Processors SoC fabric PowerVR Video MIPS Processors General Processors PowerVR Vision Processors * source: Gartner facebook.com/imgtec @PowerVRInsider │ #idc15 4 About Imagination Our IP plus our partners’ know-how combine to drive and disrupt Smart WearablesGaming Security & VR/AR Advanced Automotive Wearables Retail eHealth Smart homes facebook.com/imgtec @PowerVRInsider │ #idc15 5 About Imagination Business model Licensees OEMs and ODMs Consumers facebook.com/imgtec @PowerVRInsider │ #idc15 6 About Imagination Our licensees and partners drive our business facebook.com/imgtec @PowerVRInsider │ #idc15 7 PowerVR Rogue Hardware PowerVR Rogue Recap . Tile-based deferred renderer . Building on technology proven over 5 previous generations . Formally announced at CES 2012 . USC - Universal Shading Cluster . New scalar SIMD shader core . General purpose compute is a first class citizen in the core … . … while not forgetting what makes a shader core great for graphics facebook.com/imgtec @PowerVRInsider │ #idc15 9 TBDR Tile-based . Tile-based . Split each render up into small tiles (32x32 for the most part) . Bin geometry after vertex shading into those tiles . Tile-based rasterisation and pixel shading . -

Best Practice for Mobile
If this doesn’t look familiar, you’re in the wrong conference 1 This section of the course is about the ways that mobile graphics hardware works, and how to work with this hardware to get the best performance. The focus here is on the Vulkan API because the explicit nature exposes the hardware, but the principles apply to other programming models. There are ways of getting better mobile efficiency by reducing what you’re drawing: running at lower frame rate or resolution, only redrawing what and when you need to, etc.; we’ve addressed those in previous years and you can find some content on the course web site, but this time the focus is on high-performance 3D rendering. Those other techniques still apply, but this talk is about how to keep the graphics moving and assuming you’re already doing what you can to reduce your workload. 2 Mobile graphics processing units are usually fundamentally different from classical desktop designs. * Mobile GPUs mostly (but not exclusively) use tiling, desktop GPUs tend to use immediate-mode renderers. * They use system RAM rather than dedicated local memory and a bus connection to the GPU. * They have multiple cores (but not so much hyperthreading), some of which may be optimised for low power rather than performance. * Vulkan and similar APIs make these features more visible to the developer. Here, we’re mostly using Vulkan for examples – but the architectural behaviour applies to other APIs. 3 Let’s start with the tiled renderer. There are many approaches to tiling, even within a company. -

Power Optimizations for Graphics Processors
POWER OPTIMIZATIONS FOR GRAPHICS PROCESSORS B.V.N.SILPA DEPARTMENT OF COMPUTER SCIENCE & ENGINEERING INDIAN INSTITUTE OF TECHNOLOGY DELHI March 2011 POWER OPTIMAZTIONS FOR GRAPHICS PROCESSORS by B.V.N.SILPA Department of Computer Science and Engineering Submitted in fulfillment of the requirements of the degree of Doctor of Philosophy to the Indian Institute of Technology Delhi March 2011 Certificate This is to certify that the thesis titled Power optimizations for graphics pro- cessors being submitted by B V N Silpa for the award of Doctor of Philosophy in Computer Science & Engg. is a record of bona fide work carried out by her under my guidance and supervision at the Deptartment of Computer Science & Engineer- ing, Indian Institute of Technology Delhi. The work presented in this thesis has not been submitted elsewhere, either in part or full, for the award of any other degree or diploma. Preeti Ranjan Panda Professor Dept. of Computer Science & Engg. Indian Institute of Technology Delhi Acknowledgment It is with immense gratitude that I acknowledge the support and help of my Professor Preeti Ranjan Panda in guiding me through this thesis. I would like to thank Professors M. Balakrishnan, Anshul Kumar, G.S. Visweswaran and Kolin Paul for their valuable feedback, suggestions and help in all respects. I am indebted to my dear friend G Kr- ishnaiah for being my constant support and an impartial critique. I would like to thank Neeraj Goel, Anant Vishnoi and Aryabartta Sahu for their technical and moral support. I would also like to thank the staff of Philips, FPGA, Intel laboratories and IIT Delhi for their help. -

Real-Time Ray Traced Ambient Occlusion and Animation Image Quality and Performance of Hardware- Accelerated Ray Traced Ambient Occlusion
DEGREE PROJECTIN COMPUTER SCIENCE AND ENGINEERING, SECOND CYCLE, 30 CREDITS STOCKHOLM, SWEDEN 2021 Real-time Ray Traced Ambient Occlusion and Animation Image quality and performance of hardware- accelerated ray traced ambient occlusion FABIAN WALDNER KTH ROYAL INSTITUTE OF TECHNOLOGY SCHOOL OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE Real-time Ray Traced Ambient Occlusion and Animation Image quality and performance of hardware-accelerated ray traced ambient occlusion FABIAN Waldner Master’s Programme, Industrial Engineering and Management, 120 credits Date: June 2, 2021 Supervisor: Christopher Peters Examiner: Tino Weinkauf School of Electrical Engineering and Computer Science Swedish title: Strålspårad ambient ocklusion i realtid med animationer Swedish subtitle: Bildkvalité och prestanda av hårdvaruaccelererad, strålspårad ambient ocklusion © 2021 Fabian Waldner Abstract | i Abstract Recently, new hardware capabilities in GPUs has opened the possibility of ray tracing in real-time at interactive framerates. These new capabilities can be used for a range of ray tracing techniques - the focus of this thesis is on ray traced ambient occlusion (RTAO). This thesis evaluates real-time ray RTAO by comparing it with ground- truth ambient occlusion (GTAO), a state-of-the-art screen space ambient occlusion (SSAO) method. A contribution by this thesis is that the evaluation is made in scenarios that includes animated objects, both rigid-body animations and skinning animations. This approach has some advantages: it can emphasise visual artefacts that arise due to objects moving and animating. Furthermore, it makes the performance tests better approximate real-world applications such as video games and interactive visualisations. This is particularly true for RTAO, which gets more expensive as the number of objects in a scene increases and have additional costs from managing the ray tracing acceleration structures. -

Opengl FAQ and Troubleshooting Guide
OpenGL FAQ and Troubleshooting Guide Table of Contents OpenGL FAQ and Troubleshooting Guide v1.2001.11.01..............................................................................1 1 About the FAQ...............................................................................................................................................13 2 Getting Started ............................................................................................................................................18 3 GLUT..............................................................................................................................................................33 4 GLU.................................................................................................................................................................37 5 Microsoft Windows Specifics........................................................................................................................40 6 Windows, Buffers, and Rendering Contexts...............................................................................................48 7 Interacting with the Window System, Operating System, and Input Devices........................................49 8 Using Viewing and Camera Transforms, and gluLookAt().......................................................................51 9 Transformations.............................................................................................................................................55 10 Clipping, Culling, -

Michael Doggett Department of Computer Science Lund University Overview
Graphics Architectures and OpenCL Michael Doggett Department of Computer Science Lund university Overview • Parallelism • Radeon 5870 • Tiled Graphics Architectures • Important when Memory and Bandwidth limited • Different to Tiled Rasterization! • Tessellation • OpenCL • Programming the GPU without Graphics © mmxii mcd “Only 10% of our pixels require lots of samples for soft shadows, but determining which 10% is slower than always doing the samples. ” by ID_AA_Carmack, Twitter, 111017 Parallelism • GPUs do a lot of work in parallel • Pipelining, SIMD and MIMD • What work are they doing? © mmxii mcd What’s running on 16 unifed shaders? 128 fragments in parallel 16 cores = 128 ALUs MIMD 16 simultaneous instruction streams 5 Slide courtesy Kayvon Fatahalian vertices/fragments primitives 128 [ OpenCL work items ] in parallel CUDA threads vertices primitives fragments 6 Slide courtesy Kayvon Fatahalian Unified Shader Architecture • Let’s take the ATI Radeon 5870 • From 2009 • What are the components of the modern graphics hardware pipeline? © mmxii mcd Unified Shader Architecture Grouper Rasterizer Unified shader Texture Z & Alpha FrameBuffer © mmxii mcd Unified Shader Architecture Grouper Rasterizer Unified Shader Texture Z & Alpha FrameBuffer ATI Radeon 5870 © mmxii mcd Shader Inputs Vertex Grouper Tessellator Geometry Grouper Rasterizer Unified Shader Thread Scheduler 64 KB GDS SIMD 32 KB LDS Shader Processor 5 32bit FP MulAdd Texture Sampler Texture 16 Shader Processors 256 KB GPRs 8 KB L1 Tex Cache 20 SIMD Engines Shader Export Z & Alpha 4 -

Ray Tracing on Programmable Graphics Hardware
Ray Tracing on Programmable Graphics Hardware Timothy J. Purcell Ian Buck William R. Mark ∗ Pat Hanrahan Stanford University † Abstract In this paper, we describe an alternative approach to real-time ray tracing that has the potential to out perform CPU-based algorithms Recently a breakthrough has occurred in graphics hardware: fixed without requiring fundamentally new hardware: using commodity function pipelines have been replaced with programmable vertex programmable graphics hardware to implement ray tracing. Graph- and fragment processors. In the near future, the graphics pipeline ics hardware has recently evolved from a fixed-function graph- is likely to evolve into a general programmable stream processor ics pipeline optimized for rendering texture-mapped triangles to a capable of more than simply feed-forward triangle rendering. graphics pipeline with programmable vertex and fragment stages. In this paper, we evaluate these trends in programmability of In the near-term (next year or two) the graphics processor (GPU) the graphics pipeline and explain how ray tracing can be mapped fragment program stage will likely be generalized to include float- to graphics hardware. Using our simulator, we analyze the per- ing point computation and a complete, orthogonal instruction set. formance of a ray casting implementation on next generation pro- These capabilities are being demanded by programmers using the grammable graphics hardware. In addition, we compare the perfor- current hardware. As we will show, these capabilities are also suf- mance difference between non-branching programmable hardware ficient for us to write a complete ray tracer for this hardware. As using a multipass implementation and an architecture that supports the programmable stages become more general, the hardware can branching. -

3/4-Discrete Optimal Transport
3 4-discrete optimal transport Fr´ed´ericde Gournay Jonas Kahn L´eoLebrat July 26, 2021 Abstract 3 This paper deals with the 4 -discrete 2-Wasserstein optimal transport between two measures, where one is supported by a set of segment and the other one is supported by a set of Dirac masses. We select the most suitable optimization procedure that computes the optimal transport and provide numerical examples of approximation of cloud data by segments. Introduction The numerical computation of optimal transport in the sense of the 2-Wasserstein distance has known several break- throughs in the last decade. One can distinguish three kinds of methods : The first method is based on underlying PDEs [2] and is only available when the measures are absolutely continuous with respect to the Lebesgue measure. The second method deals with discrete measures and is known as the Sinkhorn algorithm [7, 3]. The main idea of this method is to add an entropic regularization in the Kantorovitch formulation. The third method is known as semi- discrete [19, 18, 8] optimal transport and is limited to the case where one measure is atomic and the other is absolutely continuous. This method uses tools of computational geometry, the Laguerre tessellation which is an extension of the Voronoi diagram. The aim of this paper is to develop an efficient method to approximate a discrete measure (a point cloud) by a measure carried by a curve. This requires a novel way to compute an optimal transportation distance between two such measures, none of the methods quoted above comply fully to this framework.