Real-Time Ray Traced Ambient Occlusion and Animation Image Quality and Performance of Hardware- Accelerated Ray Traced Ambient Occlusion
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Raytracing Prefiltered Occlusion for Aggregate Geometry
Raytracing Prefiltered Occlusion for Aggregate Geometry Dylan Lacewell1,2 Brent Burley1 Solomon Boulos3 Peter Shirley4,2 1 Walt Disney Animation Studios 2 University of Utah 3 Stanford University 4 NVIDIA Corporation Figure 1: Computing shadows using a prefiltered BVH is more efficient than using an ordinary BVH. (a) Using an ordinary BVH with 4 shadow rays per shading point requires 112 seconds for shadow rays, and produces significant visible noise. (b) Using a prefiltered BVH with 9 shadow rays requires 74 seconds, and visible noise is decreased. (c) Reducing noise to a similar level with an ordinary BVH requires 25 shadow rays and 704 seconds (about 9.5× slower). All images use 5 × 5 samples per pixel. The scene consists of about 2M triangles, each of which is semi-opaque (α = 0.85) to shadow rays. ABSTRACT aggregate geometry, it suffices to use a prefiltering algorithm that is We prefilter occlusion of aggregate geometry, e.g., foliage or hair, linear in the number of nodes in the BVH. Once built, a prefiltered storing local occlusion as a directional opacity in each node of a BVH does not need to be updated unless geometry changes. bounding volume hierarchy (BVH). During intersection, we termi- During rendering, we terminate shadow rays at some level of the nate rays early at BVH nodes based on ray differential, and compos- BVH, dependent on the differential [10] of each ray, and return the ite the stored opacities. This makes intersection cost independent of stored opacity at the node. The combined opacity of the ray is com- geometric complexity for rays with large differentials, and simulta- puted by compositing the opacities of one or more nodes that the neously reduces the variance of occlusion estimates. -

Fast Precomputed Ambient Occlusion for Proximity Shadows
INSTITUT NATIONAL DE RECHERCHE EN INFORMATIQUE ET EN AUTOMATIQUE Fast Precomputed Ambient Occlusion for Proximity Shadows Mattias Malmer — Fredrik Malmer — Ulf Assarsson — Nicolas Holzschuch N° 5779 Décembre 2005 Thème COG apport de recherche ISRN INRIA/RR--5779--FR+ENG ISSN 0249-6399 Fast Precomputed Ambient Occlusion for Proximity Shadows Mattias Malmer∗ , Fredrik Malmer∗ , Ulf Assarsson† ‡ , Nicolas Holzschuch‡ Thème COG — Systèmes cognitifs Projets ARTIS Rapport de recherche n° 5779 — Décembre 2005 — 19 pages Abstract: Ambient occlusion is used widely for improving the realism of real-time lighting simulations. We present a new, simple method for storing ambient occlusion values, that is very easy to implement and uses very little CPU and GPU resources. This method can be used to store and retrieve the percentage of occlusion, either alone or in combination with the average occluded direction. The former is cheaper in memory costs, while being slightly less accurate. The latter is slightly more expensive in memory, but gives more accurate results, especially when combining several occluders. The speed of our algorithm is independent of the complexity of either the occluder or the receiving scene. This makes the algorithm highly suitable for games and other real-time applications. Key-words: ∗ Syndicate Ent., Grevgatan 53, SE-114 58 Stockholm, Sweden. † Chalmers University of Technology, SE-412 96 Göteborg, Sweden. ‡ ARTIS/GRAVIR – IMAG INRIA Rhône-Alpes, France. Unité de recherche INRIA Rhône-Alpes 655, avenue de l’Europe, 38334 Montbonnot Saint Ismier (France) Téléphone : +33 4 76 61 52 00 — Télécopie +33 4 76 61 52 52 Fast Precomputed Ambient Occlusion for Proximity Shadows Résumé : L’Ambient Occlusion est fréquemment utilisée pour améliorer le réalisme de simulations de l’éclairage en temps-réel. -

POWERVR 3D Application Development Recommendations
Imagination Technologies Copyright POWERVR 3D Application Development Recommendations Copyright © 2009, Imagination Technologies Ltd. All Rights Reserved. This publication contains proprietary information which is protected by copyright. The information contained in this publication is subject to change without notice and is supplied 'as is' without warranty of any kind. Imagination Technologies and the Imagination Technologies logo are trademarks or registered trademarks of Imagination Technologies Limited. All other logos, products, trademarks and registered trademarks are the property of their respective owners. Filename : POWERVR. 3D Application Development Recommendations.1.7f.External.doc Version : 1.7f External Issue (Package: POWERVR SDK 2.05.25.0804) Issue Date : 07 Jul 2009 Author : POWERVR POWERVR 1 Revision 1.7f Imagination Technologies Copyright Contents 1. Introduction .................................................................................................................................4 1. Golden Rules...............................................................................................................................5 1.1. Batching.........................................................................................................................5 1.1.1. API Overhead ................................................................................................................5 1.2. Opaque objects must be correctly flagged as opaque..................................................6 1.3. Avoid mixing -

Combining Screen-Space Ambient Occlusion and Cartoon Rendering on Graphics Hardware
Combining Screen-Space Ambient Occlusion and Cartoon Rendering on Graphics Hardware Brett Lajzer Dan Nottingham Figure 1: Four visualizations of the same scene: a) no SSAO or outlining, b) SSAO, no outlines, c) no SSAO, outlines, d) SSAO and outlines 1. Motivation Screen-Space Ambient Occlusion Screen-space ambient occlusion (SSAO) is a further Methods for non-photorealistic rendering of 3D scenes have approximation of this technique, which was developed by become more popular in recent years for computer CryTek for their game Crysis and its engine. This version animation and games. We were interested in combining computes ambient occlusion for each pixel visible on the two particular NPR techniques: ambient occlusion and screen, by generating random points in the hemisphere cartoon shading. Ambient occlusion is an approach to around that pixel, and determining occlusion for each point global lighting that assumes that a point on the surface of by comparing its depth to a depth map of the scene. The an object receives less ambient light if there are many other sample is considered occluded if it is further from the objects occupying the space nearby in the hemisphere camera than the depth of the nearest visible object at that around that point. Screen-space ambient occlusion point, unless the difference in depth is greater than the approximates this on the GPU using the depth buffer to test sample radius. The advantage of this method is that it can occlusion of sample points. We combine this with cartoon be implemented on graphics hardware and run in real time, shading, which draws dark outlines on objects based on making it more suited to dynamic, interactive scenes due to depth and normal discontinuities, and thresholds lighting its dependence only upon screen resolution rather than intensity to several discreet values. -
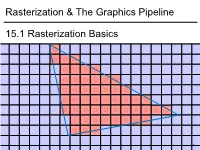
Rasterization & the Graphics Pipeline 15.1 Rasterization Basics
1 1 0.8 0.6 0.4 0.2 0 -0.2 -0.4 -0.6 -0.8 15.1Rasterization Basics Rasterization & TheGraphics Pipeline Rasterization& -1 -1 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 1 In This Video • The Graphics Pipeline and how it processes triangles – Projection, rasterisation, shading, depth testing • DirectX12 and its stages 2 Modern Graphics Pipeline • Input – Geometric model • Triangle vertices, vertex normals, texture coordinates – Lighting/material model (shader) • Light source positions, colors, intensities, etc. • Texture maps, specular/diffuse coefficients, etc. – Viewpoint + projection plane – You know this, you’ve done it! • Output – Color (+depth) per pixel Colbert & Krivanek 3 The Graphics Pipeline • Project vertices to 2D (image) • Rasterize triangle: find which pixels should be lit • Compute per-pixel color • Test visibility (Z-buffer), update frame buffer color 4 The Graphics Pipeline • Project vertices to 2D (image) • Rasterize triangle: find which pixels should be lit – For each pixel, test 3 edge equations • if all pass, draw pixel • Compute per-pixel color • Test visibility (Z-buffer), update frame buffer color 5 The Graphics Pipeline • Perform projection of vertices • Rasterize triangle: find which pixels should be lit • Compute per-pixel color • Test visibility, update frame buffer color – Store minimum distance to camera for each pixel in “Z-buffer” • ~same as tmin in ray casting! – if new_z < zbuffer[x,y] zbuffer[x,y]=new_z framebuffer[x,y]=new_color frame buffer Z buffer 6 The Graphics Pipeline For each triangle transform into eye space (perform projection) setup 3 edge equations for each pixel x,y if passes all edge equations compute z if z<zbuffer[x,y] zbuffer[x,y]=z framebuffer[x,y]=shade() 7 (Simplified version) DirectX 12 Pipeline (Vulkan & Metal are highly similar) Vertex & Textures, index data etc. -

Fast Image-Based Ambient Occlusion IBAO
The International Journal of Virtual Reality, 2011, 10(4):61-65 61 Fast Image-Based Ambient Occlusion IBAO Robert Sajko and Zeljka Mihajlovic University of Zagreb, Faculty of Electrical Engineering and Computing,Department of Electronics, Microelectronics, Computer and Intelligent Systems Ambient lighting is an approximation of the light reflected from Abstract— The quality of computer rendering and perception other objects in the scene. Its presence reveals the spatial of realism greatly depend on the shading method used to relationship between objects, their shape, depth and surface implement the interaction of light with the surfaces of objects in a complexity details. Ambient lighting can be locally occluded scene. Ambient occlusion (AO) enhances the realistic impression by nearby object or a fold in the surface. Ambient occlusion of rendered objects and scenes. Properties that make Screen produces only subtle visual cues, however, they are very Space Ambient Occlusion (SSAO) interesting for real-time important in natural perception and thus also in a convincing, graphics are scene complexity independence, and support for fully dynamic scenes. However, there are also important issues with realistic lighting model. current approaches: poor texture cache use, introduction of noise, Modern consumer GPUs offer impressive computational and performance swings. power which has allowed the use of various techniques and In this paper, a straightforward solution is presented. Instead algorithms in real-time computer graphics that were previously of a traditional, geometry-based sampling method, a novel, possible in offline rendering only. One such technique is image-based sampling method is developed, coupled with a ambient occlusion, which approximates soft shadows due to revised heuristic function for computing occlusion. -

Neural Network Ambient Occlusion
Neural Network Ambient Occlusion Daniel Holden∗ Jun Saitoy Taku Komuraz University of Edinburgh Method Studios University of Edinburgh Figure 1: Comparison showing Neural Network Ambient Occlusion enabled and disabled inside a game engine. Abstract which is more accurate than existing techniques, has better perfor- mance, no user parameters other than the occlusion radius, and can We present Neural Network Ambient Occlusion (NNAO), a fast, ac- be computed in a single pass allowing it to be used as a drop-in curate screen space ambient occlusion algorithm that uses a neural replacement for existing techniques. network to learn an optimal approximation of the ambient occlu- sion effect. Our network is carefully designed such that it can be 2 Related Work computed in a single pass allowing it to be used as a drop-in re- placement for existing screen space ambient occlusion techniques. Screen Space Ambient Occlusion Screen Space Ambient Oc- clusion (SSAO) was first introduced by Mittring [2007] for use in Keywords: neural networks, machine learning, screen space am- Cryengine2. The approach samples around the depth buffer in a bient occlusion, SSAO, HBAO view space sphere and counts the number of points which are in- side the depth surface to estimate the occlusion. This method has seen wide adoption but often produces artifacts such as dark halos 1 Introduction around object silhouettes or white highlights on object edges. Fil- ion and McNaughton [2008] presented SSAO+, an extension which Ambient Occlusion is a key component in the lighting of a scene samples in a hemisphere oriented in the direction of the surface nor- but expensive to calculate. -

Powervr Graphics - Latest Developments and Future Plans
PowerVR Graphics - Latest Developments and Future Plans Latest Developments and Future Plans A brief introduction • Joe Davis • Lead Developer Support Engineer, PowerVR Graphics • With Imagination’s PowerVR Developer Technology team for ~6 years • PowerVR Developer Technology • SDK, tools, documentation and developer support/relations (e.g. this session ) facebook.com/imgtec @PowerVRInsider │ #idc15 2 Company overview About Imagination Multimedia, processors, communications and cloud IP Driving IP innovation with unrivalled portfolio . Recognised leader in graphics, GPU compute and video IP . #3 design IP company world-wide* Ensigma Communications PowerVR Processors Graphics & GPU Compute Processors SoC fabric PowerVR Video MIPS Processors General Processors PowerVR Vision Processors * source: Gartner facebook.com/imgtec @PowerVRInsider │ #idc15 4 About Imagination Our IP plus our partners’ know-how combine to drive and disrupt Smart WearablesGaming Security & VR/AR Advanced Automotive Wearables Retail eHealth Smart homes facebook.com/imgtec @PowerVRInsider │ #idc15 5 About Imagination Business model Licensees OEMs and ODMs Consumers facebook.com/imgtec @PowerVRInsider │ #idc15 6 About Imagination Our licensees and partners drive our business facebook.com/imgtec @PowerVRInsider │ #idc15 7 PowerVR Rogue Hardware PowerVR Rogue Recap . Tile-based deferred renderer . Building on technology proven over 5 previous generations . Formally announced at CES 2012 . USC - Universal Shading Cluster . New scalar SIMD shader core . General purpose compute is a first class citizen in the core … . … while not forgetting what makes a shader core great for graphics facebook.com/imgtec @PowerVRInsider │ #idc15 9 TBDR Tile-based . Tile-based . Split each render up into small tiles (32x32 for the most part) . Bin geometry after vertex shading into those tiles . Tile-based rasterisation and pixel shading . -

Michael Doggett Department of Computer Science Lund University Overview
Graphics Architectures and OpenCL Michael Doggett Department of Computer Science Lund university Overview • Parallelism • Radeon 5870 • Tiled Graphics Architectures • Important when Memory and Bandwidth limited • Different to Tiled Rasterization! • Tessellation • OpenCL • Programming the GPU without Graphics © mmxii mcd “Only 10% of our pixels require lots of samples for soft shadows, but determining which 10% is slower than always doing the samples. ” by ID_AA_Carmack, Twitter, 111017 Parallelism • GPUs do a lot of work in parallel • Pipelining, SIMD and MIMD • What work are they doing? © mmxii mcd What’s running on 16 unifed shaders? 128 fragments in parallel 16 cores = 128 ALUs MIMD 16 simultaneous instruction streams 5 Slide courtesy Kayvon Fatahalian vertices/fragments primitives 128 [ OpenCL work items ] in parallel CUDA threads vertices primitives fragments 6 Slide courtesy Kayvon Fatahalian Unified Shader Architecture • Let’s take the ATI Radeon 5870 • From 2009 • What are the components of the modern graphics hardware pipeline? © mmxii mcd Unified Shader Architecture Grouper Rasterizer Unified shader Texture Z & Alpha FrameBuffer © mmxii mcd Unified Shader Architecture Grouper Rasterizer Unified Shader Texture Z & Alpha FrameBuffer ATI Radeon 5870 © mmxii mcd Shader Inputs Vertex Grouper Tessellator Geometry Grouper Rasterizer Unified Shader Thread Scheduler 64 KB GDS SIMD 32 KB LDS Shader Processor 5 32bit FP MulAdd Texture Sampler Texture 16 Shader Processors 256 KB GPRs 8 KB L1 Tex Cache 20 SIMD Engines Shader Export Z & Alpha 4 -

Light Propagation Volumes in Cryengine 3 Anton Kaplanyan1
Light Propagation Volumes in CryEngine 3 Anton Kaplanyan1 1 [email protected] 1 | P a g e Figure 1. Examples of current technique in CryEngine® 3. Top: Cornell box-like environment, middle left: indoor environment without global illumination, middle right indoor environment with global illumination, bottom: outdoor environment with foliage. Note the indirect lighting in shadow areas. 2 | P a g e 1 Abstract This chapter introduces a new technique for approximating the first bounce of diffuse global illumination in real-time. As diffuse global illumination is very computationally intensive, it is usually implemented only as static precomputed solutions thus negatively affecting game production time. In this chapter we present a completely dynamic solution using spherical harmonics (SH) radiance volumes for light field finite-element approximation, point-based injective volumetric rendering and a new iterative radiance propagation approach. Our implementation proves that it is possible to use this solution efficiently even with current generation of console hardware (Microsoft Xbox® 360, Sony PlayStation® 3). Because this technique does not require any preprocessing stages and fully supports dynamic lighting, objects, materials and view points, it is possible to harmoniously integrate it into an engine as complex as the cross-platform engine CryEngine® 3 with a large set of graphics technologies without requiring additional production time. Additional applications and combinations with existing techniques are dicussed in details in this chapter. 2 Introduction Some details on rendering pipeline of CryEngine 2 and CryEngine 3 G-Buffer 4 could be found in [MITTRING07], [MITTRING09]. However this paper is dedicated to diffuse global illumination solution in the engine. -

3/4-Discrete Optimal Transport
3 4-discrete optimal transport Fr´ed´ericde Gournay Jonas Kahn L´eoLebrat July 26, 2021 Abstract 3 This paper deals with the 4 -discrete 2-Wasserstein optimal transport between two measures, where one is supported by a set of segment and the other one is supported by a set of Dirac masses. We select the most suitable optimization procedure that computes the optimal transport and provide numerical examples of approximation of cloud data by segments. Introduction The numerical computation of optimal transport in the sense of the 2-Wasserstein distance has known several break- throughs in the last decade. One can distinguish three kinds of methods : The first method is based on underlying PDEs [2] and is only available when the measures are absolutely continuous with respect to the Lebesgue measure. The second method deals with discrete measures and is known as the Sinkhorn algorithm [7, 3]. The main idea of this method is to add an entropic regularization in the Kantorovitch formulation. The third method is known as semi- discrete [19, 18, 8] optimal transport and is limited to the case where one measure is atomic and the other is absolutely continuous. This method uses tools of computational geometry, the Laguerre tessellation which is an extension of the Voronoi diagram. The aim of this paper is to develop an efficient method to approximate a discrete measure (a point cloud) by a measure carried by a curve. This requires a novel way to compute an optimal transportation distance between two such measures, none of the methods quoted above comply fully to this framework. -

Ambient Occlusion Fields Janne Kontkanen∗ Samuli Laine, Helsinki University of Technology Helsinki University of Technology and Hybrid Graphics, Ltd
Ambient Occlusion Fields Janne Kontkanen∗ Samuli Laine, Helsinki University of Technology Helsinki University of Technology and Hybrid Graphics, Ltd. Abstract We present a novel real-time technique for computing inter-object ambient occlusion. For each occluding object, we precompute a field in the surrounding space that encodes an approximation of the occlusion caused by the object. This volumetric information is then used at run-time in a fragment program for quickly determining the shadow cast on the receiving objects. According to our results, both the computational and storage requirements are low enough for the technique to be directly applicable to computer games running on the current graphics hardware. CR Categories: I.3.7 [Computer Graphics]: Three-Dimensional Graphics and Realism—Color, shading, shadowing, and texture Keywords: shadowing techniques, games & GPUs, interactive global illumination, reflectance models & shading Figure 1: A tank casts shadows on the surrounding environment. 1 Introduction The shadows are rendered using the method described in this paper. The scene runs 136 fps at 1024 × 768 resolution on a Pentium 4 with ATI Radeon 9800XT graphics board. The idea of ambient occlusion is a special case of the obscurances technique which was first presented by Zhukov et al. [1998], but overhead. For this reason, ambient occlusion is gaining interest half of the credit belongs to the movie industry and the produc- also in the real-time graphics community [Pharr 2004]. However, tion rendering community for refining and popularizing the tech- the inter-object occlusion has to be re-evaluated whenever spatial nique [Landis 2002; Christensen 2002]. Ambient occlusion refers relationships of the objects change.