POWERVR 3D Application Development Recommendations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Powervr SGX Series5xt IP Core Family
PowerVR SGX Series5XT IP Core Family The PowerVR™ SGX Series5XT Graphics Processing Unit (GPU) IP core family is a series Features of highly efficient graphics acceleration IP cores that meet the multimedia requirements of • Most comprehensive IP core family the next generation of consumer, communications and computing applications. and roadmap in the industry PowerVR SGX Series5XT architecture is fully scalable for a wide range of area and • USSE2 delivers twice the peak performance requirements, enabling it to target markets from low cost feature-rich mobile floating point and instruction multimedia products to very high performance consoles and computing devices. throughput of Series5 USSE • YUV and colour space accelerators The family incorporates the second-generation Universal Scalable Shader Engine (USSE2™), for improved performance with a feature set that exceeds the requirements of OpenGL 2.0 and Microsoft Shader • Upgraded PowerVR Series5XT Model 3, enabling 2D, 3D and general purpose (GP-GPU) processing in a single core. shader-driven tile-based deferred rendering (TBDR) architecture • Multi-processor options enable scalability to higher performance • Support for all industry standard PowerVR SGX Family mobile and desktop graphics APIs and operating sytems Series5XT SGX543MP1-16, SGX544MP1-16, SGX554MP1-16 • Fully backwards compatible with PowerVR MBX and SGX Series5 Series5 SGX520, SGX530, SGX531, SGX535, SGX540, SGX545 Benefits Multi-standard API and OS • Extensive product line supports all area/performance requirements OpenGL -

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
Case M:07-cv-01826-WHA Document 249 Filed 11/08/2007 Page 1 of 34 1 BOIES, SCHILLER & FLEXNER LLP WILLIAM A. ISAACSON (pro hac vice) 2 5301 Wisconsin Ave. NW, Suite 800 Washington, D.C. 20015 3 Telephone: (202) 237-2727 Facsimile: (202) 237-6131 4 Email: [email protected] 5 6 BOIES, SCHILLER & FLEXNER LLP BOIES, SCHILLER & FLEXNER LLP JOHN F. COVE, JR. (CA Bar No. 212213) PHILIP J. IOVIENO (pro hac vice) 7 DAVID W. SHAPIRO (CA Bar No. 219265) ANNE M. NARDACCI (pro hac vice) KEVIN J. BARRY (CA Bar No. 229748) 10 North Pearl Street 8 1999 Harrison St., Suite 900 4th Floor Oakland, CA 94612 Albany, NY 12207 9 Telephone: (510) 874-1000 Telephone: (518) 434-0600 Facsimile: (510) 874-1460 Facsimile: (518) 434-0665 10 Email: [email protected] Email: [email protected] [email protected] [email protected] 11 [email protected] 12 Attorneys for Plaintiff Jordan Walker Interim Class Counsel for Direct Purchaser 13 Plaintiffs 14 15 UNITED STATES DISTRICT COURT 16 NORTHERN DISTRICT OF CALIFORNIA 17 18 IN RE GRAPHICS PROCESSING UNITS ) Case No.: M:07-CV-01826-WHA ANTITRUST LITIGATION ) 19 ) MDL No. 1826 ) 20 This Document Relates to: ) THIRD CONSOLIDATED AND ALL DIRECT PURCHASER ACTIONS ) AMENDED CLASS ACTION 21 ) COMPLAINT FOR VIOLATION OF ) SECTION 1 OF THE SHERMAN ACT, 15 22 ) U.S.C. § 1 23 ) ) 24 ) ) JURY TRIAL DEMANDED 25 ) ) 26 ) ) 27 ) 28 THIRD CONSOLIDATED AND AMENDED CLASS ACTION COMPLAINT BY DIRECT PURCHASERS M:07-CV-01826-WHA Case M:07-cv-01826-WHA Document 249 Filed 11/08/2007 Page 2 of 34 1 Plaintiffs Jordan Walker, Michael Bensignor, d/b/a Mike’s Computer Services, Fred 2 Williams, and Karol Juskiewicz, on behalf of themselves and all others similarly situated in the 3 United States, bring this action for damages and injunctive relief under the federal antitrust laws 4 against Defendants named herein, demanding trial by jury, and complaining and alleging as 5 follows: 6 NATURE OF THE CASE 7 1. -

Driver Riva Tnt2 64
Driver riva tnt2 64 click here to download The following products are supported by the drivers: TNT2 TNT2 Pro TNT2 Ultra TNT2 Model 64 (M64) TNT2 Model 64 (M64) Pro Vanta Vanta LT GeForce. The NVIDIA TNT2™ was the first chipset to offer a bit frame buffer for better quality visuals at higher resolutions, bit color for TNT2 M64 Memory Speed. NVIDIA no longer provides hardware or software support for the NVIDIA Riva TNT GPU. The last Forceware unified display driver which. version now. NVIDIA RIVA TNT2 Model 64/Model 64 Pro is the first family of high performance. Drivers > Video & Graphic Cards. Feedback. NVIDIA RIVA TNT2 Model 64/Model 64 Pro: The first chipset to offer a bit frame buffer for better quality visuals Subcategory, Video Drivers. Update your computer's drivers using DriverMax, the free driver update tool - Display Adapters - NVIDIA - NVIDIA RIVA TNT2 Model 64/Model 64 Pro Computer. (In Windows 7 RC1 there was the build in TNT2 drivers). http://kemovitra. www.doorway.ru Use the links on this page to download the latest version of NVIDIA RIVA TNT2 Model 64/Model 64 Pro (Microsoft Corporation) drivers. All drivers available for. NVIDIA RIVA TNT2 Model 64/Model 64 Pro - Driver Download. Updating your drivers with Driver Alert can help your computer in a number of ways. From adding. Nvidia RIVA TNT2 M64 specs and specifications. Price comparisons for the Nvidia RIVA TNT2 M64 and also where to download RIVA TNT2 M64 drivers. Windows 7 and Windows Vista both fail to recognize the Nvidia Riva TNT2 ( Model64/Model 64 Pro) which means you are restricted to a low. -

(GPU) Computing
Graphics Processing Unit (GPU) computing This section describes the graphics processing unit (GPU) computing feature of OptiSystem. Note: The GPU computing feature is only configurable with OptiSystem Version 11 (or higher) What is GPU computing? GPU computing or GPGPU takes advantage of a computer’s grahics processing card to augment the speed of general purpose scientific and engineering computing tasks. Compute Unified Device Architecture (CUDA) implementation for OptiSystem NVIDIA revolutionized the GPGPU and accelerated computing when it introduced a new parallel computing architecture: Compute Unified Device Architecture (CUDA). CUDA is both a hardware and software architecture for issuing and managing computations within the GPU, thus allowing it to operate as a generic data-parallel computing device. CUDA allows the programmer to take advantage of the parallel computing power of an NVIDIA graphics card to perform general purpose computations. OptiSystem CUDA implementation The OptiSystem model for GPU computing involves using a central processing unit (CPU) and GPU together in a heterogeneous co-processing computing model. The sequential part of the application runs on the CPU and the computationally-intensive part is accelerated by the GPU. In the OptiSystem GPU programming model, the application has been modified to map the compute-intensive kernels to the GPU. The remainder of the application remains within the CPU. CUDA parallel computing architecture The NVIDIA CUDA parallel computing architecture is enabled on GeForce®, Quadro®, and Tesla™ products. Whereas GeForce and Quadro are designed for consumer graphics and professional visualization respectively, the Tesla product family is designed ground-up for parallel computing and offers exclusive computing 3 GRAPHICS PROCESSING UNIT (GPU) COMPUTING features, and is the recommended choice for the OptiSystem GPU. -

A Configurable General Purpose Graphics Processing Unit for Power, Performance, and Area Analysis
Iowa State University Capstones, Theses and Creative Components Dissertations Summer 2019 A configurable general purpose graphics processing unit for power, performance, and area analysis Garrett Lies Follow this and additional works at: https://lib.dr.iastate.edu/creativecomponents Part of the Digital Circuits Commons Recommended Citation Lies, Garrett, "A configurable general purpose graphics processing unit for power, performance, and area analysis" (2019). Creative Components. 329. https://lib.dr.iastate.edu/creativecomponents/329 This Creative Component is brought to you for free and open access by the Iowa State University Capstones, Theses and Dissertations at Iowa State University Digital Repository. It has been accepted for inclusion in Creative Components by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. A Configurable General Purpose Graphics Processing Unit for Power, Performance, and Area Analysis by Garrett Joseph Lies A Creative Component submitted to the graduate faculty in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE Major: Computer Engineering (Very-Large Scale Integration) Program of Study Committee: Joseph Zambreno, Major Professor The student author, whose presentation of the scholarship herein was approved by the program of study committee, is solely responsible for the content of this dissertation/thesis. The Graduate College will ensure this dissertation/thesis is globally accessible and will not permit alterations after a degree is conferred. Iowa State University Ames, Iowa 2019 Copyright c Garrett Joseph Lies, 2019. All rights reserved. ii TABLE OF CONTENTS Page LIST OF TABLES . iv LIST OF FIGURES . .v ACKNOWLEDGMENTS . vi ABSTRACT . vii CHAPTER 1. -

On the Energy Efficiency of Graphics Processing Units for Scientific
On the Energy Efficiency of Graphics Processing Units for Scientific Computing S. Huang, S. Xiao, W. Feng Department of Computer Science Virginia Tech {huangs, shucai, wfeng}@vt.edu Abstract sively parallel, multi-threaded multiprocessor design, combined with an appropriate data-parallel mapping of The graphics processing unit (GPU) has emerged as an application to it. a computational accelerator that dramatically reduces The emergence of more general-purpose program- the time to discovery in high-end computing (HEC). ming environments, such as Brook+ [1] and CUDA [2], However, while today’s state-of-the-art GPU can easily has made it easier to implement large-scale applica- reduce the execution time of a parallel code by many tions on GPUs. The CUDA programming model from orders of magnitude, it arguably comes at the expense NVIDIA was created for developing applications on of significant power and energy consumption. For ex- NVIDIA’s GPU cards, such as the GeForce 8 series. ample, the NVIDIA GTX 280 video card is rated at Similarly, Brook+ supports stream processing on the 236 watts, which is as much as the rest of a compute AMD/ATi GPU cards. For the purposes of this paper, node, thus requiring a 500-W power supply. As a we use CUDA atop an NVIDIA GTX 280 video card consequence, the GPU has been viewed as a “non- for our scientific computation. green” computing solution. GPGPU research has focused predominantly on ac- This paper seeks to characterize, and perhaps de- celerating scientific applications. This paper not only bunk, the notion of a “power-hungry GPU” via an accelerates scientific applications via GPU computing, empirical study of the performance, power, and en- but it also does so in the context of characterizing ergy characteristics of GPUs for scientific computing. -

GPU Programming Using C++ AMP
GPU programming using C++ AMP Petrika Manika Elda Xhumari Julian Fejzaj Dept. of Informatics Dept. of Informatics Dept. of Informatics University of Tirana University of Tirana University of Tirana [email protected] [email protected] [email protected] perform computation in applications traditionally handled by the central processing unit (CPU)1. The architecture of graphics processing units (GPUs) is Abstract very well suited for data-parallel problems. They Nowadays, a challenge for programmers is to support extremely high throughput through many make their programs better. The word "better" parallel processing units and very high memory means more simple, portable and much faster bandwidth. For problems that match the GPU in execution. Heterogeneous computing is a architecture well, it common to easily achieve a 2× new methodology in computer science field. speedup over a CPU implementation of the same GPGPU programming is a new and problem, and tuned implementations can outperform challenging technique which is used for the CPU by a factor of 10 to 100. Programming these solving problems with data parallel nature. In processors, however, remains a challenge because the this paper we describe this new programming architecture differs so significantly from the CPU. This methodology with focus on GPU paper describes the benefits of GPU programming programming using C++ AMP language, and using C++ AMP language, and what kinds of problems what kinds of problems are suitable for are suitable for acceleration using these parallel acceleration using these parallel techniques. techniques. Finally we describe the solution for a simple problem using C++ AMP and the advantages of this solution. -

NVIDIA Ampere GA102 GPU Architecture Whitepaper
NVIDIA AMPERE GA102 GPU ARCHITECTURE Second-Generation RTX Updated with NVIDIA RTX A6000 and NVIDIA A40 Information V2.0 Table of Contents Introduction 5 GA102 Key Features 7 2x FP32 Processing 7 Second-Generation RT Core 7 Third-Generation Tensor Cores 8 GDDR6X and GDDR6 Memory 8 Third-Generation NVLink® 8 PCIe Gen 4 9 Ampere GPU Architecture In-Depth 10 GPC, TPC, and SM High-Level Architecture 10 ROP Optimizations 11 GA10x SM Architecture 11 2x FP32 Throughput 12 Larger and Faster Unified Shared Memory and L1 Data Cache 13 Performance Per Watt 16 Second-Generation Ray Tracing Engine in GA10x GPUs 17 Ampere Architecture RTX Processors in Action 19 GA10x GPU Hardware Acceleration for Ray-Traced Motion Blur 20 Third-Generation Tensor Cores in GA10x GPUs 24 Comparison of Turing vs GA10x GPU Tensor Cores 24 NVIDIA Ampere Architecture Tensor Cores Support New DL Data Types 26 Fine-Grained Structured Sparsity 26 NVIDIA DLSS 8K 28 GDDR6X Memory 30 RTX IO 32 Introducing NVIDIA RTX IO 33 How NVIDIA RTX IO Works 34 Display and Video Engine 38 DisplayPort 1.4a with DSC 1.2a 38 HDMI 2.1 with DSC 1.2a 38 Fifth Generation NVDEC - Hardware-Accelerated Video Decoding 39 AV1 Hardware Decode 40 Seventh Generation NVENC - Hardware-Accelerated Video Encoding 40 NVIDIA Ampere GA102 GPU Architecture ii Conclusion 42 Appendix A - Additional GeForce GA10x GPU Specifications 44 GeForce RTX 3090 44 GeForce RTX 3070 46 Appendix B - New Memory Error Detection and Replay (EDR) Technology 49 Appendix C - RTX A6000 GPU Perf ormance 50 List of Figures Figure 1. -
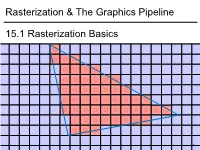
Rasterization & the Graphics Pipeline 15.1 Rasterization Basics
1 1 0.8 0.6 0.4 0.2 0 -0.2 -0.4 -0.6 -0.8 15.1Rasterization Basics Rasterization & TheGraphics Pipeline Rasterization& -1 -1 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 1 In This Video • The Graphics Pipeline and how it processes triangles – Projection, rasterisation, shading, depth testing • DirectX12 and its stages 2 Modern Graphics Pipeline • Input – Geometric model • Triangle vertices, vertex normals, texture coordinates – Lighting/material model (shader) • Light source positions, colors, intensities, etc. • Texture maps, specular/diffuse coefficients, etc. – Viewpoint + projection plane – You know this, you’ve done it! • Output – Color (+depth) per pixel Colbert & Krivanek 3 The Graphics Pipeline • Project vertices to 2D (image) • Rasterize triangle: find which pixels should be lit • Compute per-pixel color • Test visibility (Z-buffer), update frame buffer color 4 The Graphics Pipeline • Project vertices to 2D (image) • Rasterize triangle: find which pixels should be lit – For each pixel, test 3 edge equations • if all pass, draw pixel • Compute per-pixel color • Test visibility (Z-buffer), update frame buffer color 5 The Graphics Pipeline • Perform projection of vertices • Rasterize triangle: find which pixels should be lit • Compute per-pixel color • Test visibility, update frame buffer color – Store minimum distance to camera for each pixel in “Z-buffer” • ~same as tmin in ray casting! – if new_z < zbuffer[x,y] zbuffer[x,y]=new_z framebuffer[x,y]=new_color frame buffer Z buffer 6 The Graphics Pipeline For each triangle transform into eye space (perform projection) setup 3 edge equations for each pixel x,y if passes all edge equations compute z if z<zbuffer[x,y] zbuffer[x,y]=z framebuffer[x,y]=shade() 7 (Simplified version) DirectX 12 Pipeline (Vulkan & Metal are highly similar) Vertex & Textures, index data etc. -

CX92745 Interactive Display, Media, and Image Processor Complete Multimedia Solution on a Single Chip
Imaging Solutions Interactive Display Appliances CX92745 Interactive Display, Media, and Image Processor Complete Multimedia Solution on a Single Chip Conexant’s CX92745 System-on-Chip (SoC) and high-speed triple video DACs to support a is an integrated display, media, and image wide range of display applications. processor delivering a new level of performance ® and system integration. The SoC builds on Network connectivity including Bluetooth , 3G, ® Conexant’s strengths in image and mixed-signal WiFi , and integrated Ethernet is supported. processing, and integrates high performance The integrated camera card controller supports 1080p video and graphics processing hardware. all popular memory cards, and an advanced To support robust system design and lower NAND Flash Controller supports NAND boot Bill of Material (BOM) costs, the CX92745 and extended MLC-NAND ECC control. also integrates a stereo Class-D amplifier, A high-performance ARM RISC processor microphone input, touchscreen controller, and supports robust embedded operating system power supply controller. and application design. High-speed USB The hardware video subsystem supports 1080p 2.0 Host and Device ports support PC and decode and video post processing for popular peripheral connection. Enhanced multimedia video codecs, including H.264, and offloads and graphics processing is further supported the CPU from video decode tasks. Along with with the CX92745’s ARM Vector Floating Point video decode, the CX92745 supports a BT.656 Unit (VFP), large internal caches, and high compatible video-in port for video capture and speed DDR2 memory. docking applications. The CX92745 contains several features which For advanced GUI operations, the CX92745 lower cost and operating power while providing supports a hardware graphics processing unsurpassed image processing and flexibility. -

Powervr Graphics - Latest Developments and Future Plans
PowerVR Graphics - Latest Developments and Future Plans Latest Developments and Future Plans A brief introduction • Joe Davis • Lead Developer Support Engineer, PowerVR Graphics • With Imagination’s PowerVR Developer Technology team for ~6 years • PowerVR Developer Technology • SDK, tools, documentation and developer support/relations (e.g. this session ) facebook.com/imgtec @PowerVRInsider │ #idc15 2 Company overview About Imagination Multimedia, processors, communications and cloud IP Driving IP innovation with unrivalled portfolio . Recognised leader in graphics, GPU compute and video IP . #3 design IP company world-wide* Ensigma Communications PowerVR Processors Graphics & GPU Compute Processors SoC fabric PowerVR Video MIPS Processors General Processors PowerVR Vision Processors * source: Gartner facebook.com/imgtec @PowerVRInsider │ #idc15 4 About Imagination Our IP plus our partners’ know-how combine to drive and disrupt Smart WearablesGaming Security & VR/AR Advanced Automotive Wearables Retail eHealth Smart homes facebook.com/imgtec @PowerVRInsider │ #idc15 5 About Imagination Business model Licensees OEMs and ODMs Consumers facebook.com/imgtec @PowerVRInsider │ #idc15 6 About Imagination Our licensees and partners drive our business facebook.com/imgtec @PowerVRInsider │ #idc15 7 PowerVR Rogue Hardware PowerVR Rogue Recap . Tile-based deferred renderer . Building on technology proven over 5 previous generations . Formally announced at CES 2012 . USC - Universal Shading Cluster . New scalar SIMD shader core . General purpose compute is a first class citizen in the core … . … while not forgetting what makes a shader core great for graphics facebook.com/imgtec @PowerVRInsider │ #idc15 9 TBDR Tile-based . Tile-based . Split each render up into small tiles (32x32 for the most part) . Bin geometry after vertex shading into those tiles . Tile-based rasterisation and pixel shading . -

AN5072: Introduction to Embedded Graphics – Application Note
Freescale Semiconductor Document Number: AN5072 Application Note Rev 0, 02/2015 Introduction to Embedded Graphics with Freescale Devices by: Luis Olea and Ioseph Martinez Contents 1 Introduction 1 Introduction................................................................1 The purpose of this application note is to explain the basic 1.1 Graphics basic concepts.............. ...................1 concepts and requirements of embedded graphics applications, 2 Freescale graphics devices.............. ..........................7 helping software and hardware engineers easily understand the fundamental concepts behind color display technology, which 2.1 MPC5606S.....................................................7 is being expected by consumers more and more in varied 2.2 MPC5645S.....................................................8 applications from automotive to industrial markets. 2.3 Vybrid.............................................................8 This section helps the reader to familiarize with some of the most used concepts when working with graphics. Knowing 2.4 MAC57Dxx....................... ............................ 8 these definitions is basic for any developer that wants to get 2.5 Kinetis K70......................... ...........................8 started with embedded graphics systems, and these concepts apply to any system that handles graphics irrespective of the 2.6 QorIQ LS1021A................... ......................... 9 hardware used. 2.7 i.MX family........................ ........................... 9 2.8 Quick