Performance Comparison on Rendering Methods for Voxel Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Application of Voxel Size Correction in X-Ray Computed Tomography for Dimensional Metrology
SINCE2013 Singapore International NDT Conference & Exhibition 2013, 19-20 July 2013 The Application of Voxel Size Correction in X-ray Computed Tomography for Dimensional Metrology Joseph J. LIFTON1,2, Andrew A. MALCOLM2, John W. MCBRIDE1,3, Kevin J. CROSS1 1The University of Southampton, United Kingdom; Email: [email protected]. 2Singapore Institute of Manufacturing Technology, Singapore; Email: [email protected]. 3The University of Southampton Malaysia Campus (USMC), Malaysia; Email: [email protected]. Abstract X-ray computed tomography (CT) is a non-destructive, radiographic scanning technique that enables the visualisation and dimensional evaluation of both internal and external features of a workpiece; it is therefore an attractive alternative for measurement tasks that prove problematic for conventional tactile and optical instruments. The data output of a CT measurement is a volume of grey value integers that describe the material distribution of the scanned workpiece; the relative spacing of volume-elements (voxels) is termed voxel size and influences all dimensional information evaluated from a CT data-set. Voxel size is defined by the position of a workpiece relative to the X-ray source and detector, and is therefore prone to axis position errors, errors in the geometric alignment of the CT system’s hardware, and the positional drift of the X-ray focal spot. In this work a method is presented for calculating a voxel scaling factor that corrects for voxel size errors, and this method is then applied to a general X-ray CT measurement task and demonstrated to reduce measurement errors. Keywords: X-ray computed tomography, dimensional metrology, calibration, uncertainty, voxel size. -

Master Thesis
Faculty of Computer Science and Management Field of study: COMPUTER SCIENCE Specialty: Information Systems Design Master Thesis Multithreaded game engine architecture Adrian Szczerbiński keywords: game engine multithreading DirectX 12 short summary: Project, implementation and research of a multithreaded 3D game engine architecture using DirectX 12. The goal is to create a layered architecture, parallelize it and compare the results in order to state the usefulness of multithreading in game engines. Supervisor ...................................................... ............................ ……………………. Title/ degree/ name and surname grade signature The final evaluation of the thesis Przewodniczący Komisji egzaminu ...................................................... ............................ ……………………. dyplomowego Title/ degree/ name and surname grade signature For the purposes of archival thesis qualified to: * a) Category A (perpetual files) b) Category BE 50 (subject to expertise after 50 years) * Delete as appropriate stamp of the faculty Wrocław 2019 1 Streszczenie W dzisiejszych czasach, gdy społeczność graczy staje się coraz większa i stawia coraz większe wymagania, jak lepsza grafika, czy ogólnie wydajność gry, pojawia się potrzeba szybszych i lepszych silników gier, ponieważ większość z obecnych jest albo stara, albo korzysta ze starych rozwiązań. Wielowątkowość jest postrzegana jako trudne zadanie do wdrożenia i nie jest w pełni rozwinięta. Programiści często unikają jej, ponieważ do prawidłowego wdrożenia wymaga wiele pracy. Według mnie wynikający z tego wzrost wydajności jest warty tych kosztów. Ponieważ nie ma wielu silników gier, które w pełni wykorzystują wielowątkowość, celem tej pracy jest zaprojektowanie i zaproponowanie wielowątkowej architektury silnika gry 3D, a także przedstawienie głównych systemów używanych do stworzenia takiego silnika gry 3D. Praca skupia się na technologii i architekturze silnika gry i jego podsystemach wraz ze strukturami danych i algorytmami wykorzystywanymi do ich stworzenia. -

Temporal Voxel Cone Tracing with Interleaved Sample Patterns by Sanghyeok Hong
c 2015, SangHyeok Hong. All Rights Reserved. The material presented within this document does not necessarily reflect the opinion of the Committee, the Graduate Study Program, or DigiPen Institute of Technology. TEMPORAL VOXEL CONE TRACING WITH INTERLEAVED SAMPLE PATTERNS BY SangHyeok Hong THESIS Submitted in partial fulfillment of the requirements for the degree of Master of Science in Computer Science awarded by DigiPen Institute of Technology Redmond, Washington United States of America March 2015 Thesis Advisor: Gary Herron DIGIPEN INSTITUTE OF TECHNOLOGY GRADUATE STUDIES PROGRAM DEFENSE OF THESIS THE UNDERSIGNED VERIFY THAT THE FINAL ORAL DEFENSE OF THE MASTER OF SCIENCE THESIS TITLED Temporal Voxel Cone Tracing with Interleaved Sample Patterns BY SangHyeok Hong HAS BEEN SUCCESSFULLY COMPLETED ON March 12th, 2015. MAJOR FIELD OF STUDY: COMPUTER SCIENCE. APPROVED: Dmitri Volper date Xin Li date Graduate Program Director Dean of Faculty Dmitri Volper date Claude Comair date Department Chair, Computer Science President DIGIPEN INSTITUTE OF TECHNOLOGY GRADUATE STUDIES PROGRAM THESIS APPROVAL DATE: March 12th, 2015 BASED ON THE CANDIDATE'S SUCCESSFUL ORAL DEFENSE, IT IS RECOMMENDED THAT THE THESIS PREPARED BY SangHyeok Hong ENTITLED Temporal Voxel Cone Tracing with Interleaved Sample Patterns BE ACCEPTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER OF SCIENCE IN COMPUTER SCIENCE AT DIGIPEN INSTITUTE OF TECHNOLOGY. Gary Herron date Xin Li date Thesis Committee Chair Thesis Committee Member Pushpak Karnick date Matt -

Driver Riva Tnt2 64
Driver riva tnt2 64 click here to download The following products are supported by the drivers: TNT2 TNT2 Pro TNT2 Ultra TNT2 Model 64 (M64) TNT2 Model 64 (M64) Pro Vanta Vanta LT GeForce. The NVIDIA TNT2™ was the first chipset to offer a bit frame buffer for better quality visuals at higher resolutions, bit color for TNT2 M64 Memory Speed. NVIDIA no longer provides hardware or software support for the NVIDIA Riva TNT GPU. The last Forceware unified display driver which. version now. NVIDIA RIVA TNT2 Model 64/Model 64 Pro is the first family of high performance. Drivers > Video & Graphic Cards. Feedback. NVIDIA RIVA TNT2 Model 64/Model 64 Pro: The first chipset to offer a bit frame buffer for better quality visuals Subcategory, Video Drivers. Update your computer's drivers using DriverMax, the free driver update tool - Display Adapters - NVIDIA - NVIDIA RIVA TNT2 Model 64/Model 64 Pro Computer. (In Windows 7 RC1 there was the build in TNT2 drivers). http://kemovitra. www.doorway.ru Use the links on this page to download the latest version of NVIDIA RIVA TNT2 Model 64/Model 64 Pro (Microsoft Corporation) drivers. All drivers available for. NVIDIA RIVA TNT2 Model 64/Model 64 Pro - Driver Download. Updating your drivers with Driver Alert can help your computer in a number of ways. From adding. Nvidia RIVA TNT2 M64 specs and specifications. Price comparisons for the Nvidia RIVA TNT2 M64 and also where to download RIVA TNT2 M64 drivers. Windows 7 and Windows Vista both fail to recognize the Nvidia Riva TNT2 ( Model64/Model 64 Pro) which means you are restricted to a low. -
Advanced Computer Graphics to Do Motivation Real-Time Rendering
To Do Advanced Computer Graphics § Assignment 2 due Feb 19 § Should already be well on way. CSE 190 [Winter 2016], Lecture 12 § Contact us for difficulties etc. Ravi Ramamoorthi http://www.cs.ucsd.edu/~ravir Motivation Real-Time Rendering § Today, create photorealistic computer graphics § Goal: interactive rendering. Critical in many apps § Complex geometry, lighting, materials, shadows § Games, visualization, computer-aided design, … § Computer-generated movies/special effects (difficult or impossible to tell real from rendered…) § Until 10-15 years ago, focus on complex geometry § CSE 168 images from rendering competition (2011) § § But algorithms are very slow (hours to days) Chasm between interactivity, realism Evolution of 3D graphics rendering Offline 3D Graphics Rendering Interactive 3D graphics pipeline as in OpenGL Ray tracing, radiosity, photon mapping § Earliest SGI machines (Clark 82) to today § High realism (global illum, shadows, refraction, lighting,..) § Most of focus on more geometry, texture mapping § But historically very slow techniques § Some tweaks for realism (shadow mapping, accum. buffer) “So, while you and your children’s children are waiting for ray tracing to take over the world, what do you do in the meantime?” Real-Time Rendering SGI Reality Engine 93 (Kurt Akeley) Pictures courtesy Henrik Wann Jensen 1 New Trend: Acquired Data 15 years ago § Image-Based Rendering: Real/precomputed images as input § High quality rendering: ray tracing, global illumination § Little change in CSE 168 syllabus, from 2003 to -

Development of Synthetic Cameras for Virtual Commissioning
DEVELOPMENT OF SYNTHETHIC CAMERAS FOR VIRTUAL COMMISSIONING Bachelor Degree Project in Automation Engineer 2020 DEVELOPMENT OF SYNTHETIC CAMERAS FOR VIRTUAL COMMISSIONING Bachelor Degree Project in Automation Engineering Bachelor Level 30 ECTS Spring term 2020 Francisco Vico Arjona Daniel Pérez Torregrosa Company supervisor: Mikel Ayani University supervisor: Wei Wang Examiner: Stefan Ericson 1 DEVELOPMENT OF SYNTHETHIC CAMERAS FOR VIRTUAL COMMISSIONING Bachelor Degree Project in Automation Engineer 2020 Abstract Nowadays, virtual commissioning has become an incredibly useful technology which has raised its importance hugely in the latest years. Creating virtual automated systems, as similar to reality as possible, to test their behaviour has become into a great tool for avoiding waste of time and cost in the real commissioning stage of any manufacturing system. Currently, lots of virtual automated systems are controlled by different vision tools, however, these tools are not integrated in most of emulation platforms, so it precludes testing the performance of numerous virtual systems. This thesis intends to give a solution to this limitation that nowadays exists for virtual commissioning. The main goal is the creation of a synthetic camera that allows to obtain different types of images inside any virtual automated system in the same way it would have been obtained in a real system. Subsequently, a virtual demonstrator of a robotic cell controlled by computer vision is developed to show the immense opportunities that synthetic camera can open for testing vision systems. 2 DEVELOPMENT OF SYNTHETIC CAMERAS FOR VIRTUAL COMMISSIONING Bachelor Degree Project in Automation Engineering 2020 Certify of Authenticity This thesis has been submitted by Francisco Vico Arjona and Daniel Pérez Torregrosa to the University of Skövde as a requirement for the degree of Bachelor of Science in Production Engineering. -

Human Body Model Acquisition and Tracking Using Voxel Data
Submitted to the International Journal of Computer Vision Human Body Model Acquisition and Tracking using Voxel Data Ivana Mikić2, Mohan Trivedi1, Edward Hunter2, Pamela Cosman1 1Department of Electrical and Computer Engineering University of California, San Diego 2Q3DM, Inc. Abstract We present an integrated system for automatic acquisition of the human body model and motion tracking using input from multiple synchronized video streams. The video frames are segmented and the 3D voxel reconstructions of the human body shape in each frame are computed from the foreground silhouettes. These reconstructions are then used as input to the model acquisition and tracking algorithms. The human body model consists of ellipsoids and cylinders and is described using the twists framework resulting in a non-redundant set of model parameters. Model acquisition starts with a simple body part localization procedure based on template fitting and growing, which uses prior knowledge of average body part shapes and dimensions. The initial model is then refined using a Bayesian network that imposes human body proportions onto the body part size estimates. The tracker is an extended Kalman filter that estimates model parameters based on the measurements made on the labeled voxel data. A voxel labeling procedure that handles large frame-to-frame displacements was designed resulting in the very robust tracking performance. Extensive evaluation shows that the system performs very reliably on sequences that include different types of motion such as walking, sitting, dancing, running and jumping and people of very different body sizes, from a nine year old girl to a tall adult male. 1. Introduction Tracking of the human body, also called motion capture or posture estimation, is a problem of estimating the parameters of the human body model (such as joint angles) from the video data as the position and configuration of the tracked body change over time. -

Sun Opengl 1.3 for Solaris Implementation and Performance Guide
Sun™ OpenGL 1.3 for Solaris™ Implementation and Performance Guide Sun Microsystems, Inc. www.sun.com Part No. 817-2997-11 November 2003, Revision A Submit comments about this document at: http://www.sun.com/hwdocs/feedback Copyright 2003 Sun Microsystems, Inc., 4150 Network Circle, Santa Clara, California 95054, U.S.A. All rights reserved. Sun Microsystems, Inc. has intellectual property rights relating to technology that is described in this document. In particular, and without limitation, these intellectual property rights may include one or more of the U.S. patents listed at http://www.sun.com/patents and one or more additional patents or pending patent applications in the U.S. and in other countries. This document and the product to which it pertains are distributed under licenses restricting their use, copying, distribution, and decompilation. No part of the product or of this document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Third-party software, including font technology, is copyrighted and licensed from Sun suppliers. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and in other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, SunSoft, SunDocs, SunExpress, and Solaris are trademarks, registered trademarks, or service marks of Sun Microsystems, Inc. in the U.S. and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. -

POWERVR 3D Application Development Recommendations
Imagination Technologies Copyright POWERVR 3D Application Development Recommendations Copyright © 2009, Imagination Technologies Ltd. All Rights Reserved. This publication contains proprietary information which is protected by copyright. The information contained in this publication is subject to change without notice and is supplied 'as is' without warranty of any kind. Imagination Technologies and the Imagination Technologies logo are trademarks or registered trademarks of Imagination Technologies Limited. All other logos, products, trademarks and registered trademarks are the property of their respective owners. Filename : POWERVR. 3D Application Development Recommendations.1.7f.External.doc Version : 1.7f External Issue (Package: POWERVR SDK 2.05.25.0804) Issue Date : 07 Jul 2009 Author : POWERVR POWERVR 1 Revision 1.7f Imagination Technologies Copyright Contents 1. Introduction .................................................................................................................................4 1. Golden Rules...............................................................................................................................5 1.1. Batching.........................................................................................................................5 1.1.1. API Overhead ................................................................................................................5 1.2. Opaque objects must be correctly flagged as opaque..................................................6 1.3. Avoid mixing -

Photorealistic Scene Reconstruction by Voxel Coloring
In Proc. Computer Vision and Pattern Recognition Conf., pp. 1067-1073, 1997. Photorealistic Scene Reconstruction by Voxel Coloring Steven M. Seitz Charles R. Dyer Department of Computer Sciences University of Wisconsin, Madison, WI 53706 g E-mail: fseitz,dyer @cs.wisc.edu WWW: http://www.cs.wisc.edu/computer-vision Broad Viewpoint Coverage: Reprojections should be Abstract accurate over a large range of target viewpoints. This A novel scene reconstruction technique is presented, requires that the input images are widely distributed different from previous approaches in its ability to cope about the environment with large changes in visibility and its modeling of in- trinsic scene color and texture information. The method The photorealistic scene reconstruction problem, as avoids image correspondence problems by working in a presently formulated, raises a number of unique challenges discretized scene space whose voxels are traversed in a that push the limits of existing reconstruction techniques. fixed visibility ordering. This strategy takes full account Photo integrity requires that the reconstruction be dense of occlusions and allows the input cameras to be far apart and sufficiently accurate to reproduce the original images. and widely distributed about the environment. The algo- This criterion poses a problem for existing feature- and rithm identifies a special set of invariant voxels which to- contour-based techniques that do not provide dense shape gether form a spatial and photometric reconstruction of the estimates. While these techniques can produce texture- scene, fully consistent with the input images. The approach mapped models [1, 3, 4], accuracy is ensured only in places is evaluated with images from both inward- and outward- where features have been detected. -
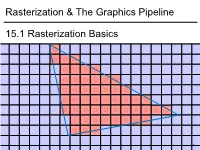
Rasterization & the Graphics Pipeline 15.1 Rasterization Basics
1 1 0.8 0.6 0.4 0.2 0 -0.2 -0.4 -0.6 -0.8 15.1Rasterization Basics Rasterization & TheGraphics Pipeline Rasterization& -1 -1 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 1 In This Video • The Graphics Pipeline and how it processes triangles – Projection, rasterisation, shading, depth testing • DirectX12 and its stages 2 Modern Graphics Pipeline • Input – Geometric model • Triangle vertices, vertex normals, texture coordinates – Lighting/material model (shader) • Light source positions, colors, intensities, etc. • Texture maps, specular/diffuse coefficients, etc. – Viewpoint + projection plane – You know this, you’ve done it! • Output – Color (+depth) per pixel Colbert & Krivanek 3 The Graphics Pipeline • Project vertices to 2D (image) • Rasterize triangle: find which pixels should be lit • Compute per-pixel color • Test visibility (Z-buffer), update frame buffer color 4 The Graphics Pipeline • Project vertices to 2D (image) • Rasterize triangle: find which pixels should be lit – For each pixel, test 3 edge equations • if all pass, draw pixel • Compute per-pixel color • Test visibility (Z-buffer), update frame buffer color 5 The Graphics Pipeline • Perform projection of vertices • Rasterize triangle: find which pixels should be lit • Compute per-pixel color • Test visibility, update frame buffer color – Store minimum distance to camera for each pixel in “Z-buffer” • ~same as tmin in ray casting! – if new_z < zbuffer[x,y] zbuffer[x,y]=new_z framebuffer[x,y]=new_color frame buffer Z buffer 6 The Graphics Pipeline For each triangle transform into eye space (perform projection) setup 3 edge equations for each pixel x,y if passes all edge equations compute z if z<zbuffer[x,y] zbuffer[x,y]=z framebuffer[x,y]=shade() 7 (Simplified version) DirectX 12 Pipeline (Vulkan & Metal are highly similar) Vertex & Textures, index data etc. -

Online Detector Response Calculations for High-Resolution PET Image Reconstruction
Home Search Collections Journals About Contact us My IOPscience Online detector response calculations for high-resolution PET image reconstruction This article has been downloaded from IOPscience. Please scroll down to see the full text article. 2011 Phys. Med. Biol. 56 4023 (http://iopscience.iop.org/0031-9155/56/13/018) View the table of contents for this issue, or go to the journal homepage for more Download details: IP Address: 171.65.80.217 The article was downloaded on 15/06/2011 at 20:11 Please note that terms and conditions apply. IOP PUBLISHING PHYSICS IN MEDICINE AND BIOLOGY Phys. Med. Biol. 56 (2011) 4023–4040 doi:10.1088/0031-9155/56/13/018 Online detector response calculations for high-resolution PET image reconstruction Guillem Pratx1 and Craig Levin2 1 Department of Radiation Oncology, Stanford University, Stanford, CA 94305, USA 2 Departments of Radiology, Physics and Electrical Engineering, and Molecular Imaging Program at Stanford, Stanford University, Stanford, CA 94305, USA E-mail: [email protected] Received 3 January 2011, in final form 19 May 2011 Published 15 June 2011 Online at stacks.iop.org/PMB/56/4023 Abstract Positron emission tomography systems are best described by a linear shift- varying model. However, image reconstruction often assumes simplified shift- invariant models to the detriment of image quality and quantitative accuracy. We investigated a shift-varying model of the geometrical system response based on an analytical formulation. The model was incorporated within a list- mode, fully 3D iterative reconstruction process in which the system response coefficients are calculated online on a graphics processing unit (GPU).