Neo-Formation of Chromosomes in Bacteria
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
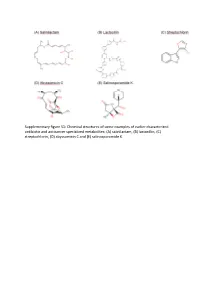
Chemical Structures of Some Examples of Earlier Characterized Antibiotic and Anticancer Specialized
Supplementary figure S1: Chemical structures of some examples of earlier characterized antibiotic and anticancer specialized metabolites: (A) salinilactam, (B) lactocillin, (C) streptochlorin, (D) abyssomicin C and (E) salinosporamide K. Figure S2. Heat map representing hierarchical classification of the SMGCs detected in all the metagenomes in the dataset. Table S1: The sampling locations of each of the sites in the dataset. Sample Sample Bio-project Site depth accession accession Samples Latitude Longitude Site description (m) number in SRA number in SRA AT0050m01B1-4C1 SRS598124 PRJNA193416 Atlantis II water column 50, 200, Water column AT0200m01C1-4D1 SRS598125 21°36'19.0" 38°12'09.0 700 and above the brine N "E (ATII 50, ATII 200, 1500 pool water layers AT0700m01C1-3D1 SRS598128 ATII 700, ATII 1500) AT1500m01B1-3C1 SRS598129 ATBRUCL SRS1029632 PRJNA193416 Atlantis II brine 21°36'19.0" 38°12'09.0 1996– Brine pool water ATBRLCL1-3 SRS1029579 (ATII UCL, ATII INF, N "E 2025 layers ATII LCL) ATBRINP SRS481323 PRJNA219363 ATIID-1a SRS1120041 PRJNA299097 ATIID-1b SRS1120130 ATIID-2 SRS1120133 2168 + Sea sediments Atlantis II - sediments 21°36'19.0" 38°12'09.0 ~3.5 core underlying ATII ATIID-3 SRS1120134 (ATII SDM) N "E length brine pool ATIID-4 SRS1120135 ATIID-5 SRS1120142 ATIID-6 SRS1120143 Discovery Deep brine DDBRINP SRS481325 PRJNA219363 21°17'11.0" 38°17'14.0 2026– Brine pool water N "E 2042 layers (DD INF, DD BR) DDBRINE DD-1 SRS1120158 PRJNA299097 DD-2 SRS1120203 DD-3 SRS1120205 Discovery Deep 2180 + Sea sediments sediments 21°17'11.0" -

Deconstruction of Lignin: from Enzymes to Microorganisms
molecules Review Deconstruction of Lignin: From Enzymes to Microorganisms Jéssica P. Silva 1, Alonso R. P. Ticona 1 , Pedro R. V. Hamann 1, Betania F. Quirino 2 and Eliane F. Noronha 1,* 1 Enzymology Laboratory, Cell Biology Department, University of Brasilia, 70910-900 Brasília, Brazil; [email protected] (J.P.S.); [email protected] (A.R.P.T.); [email protected] (P.R.V.H.) 2 Genetics and Biotechnology Laboratory, Embrapa-Agroenergy, 70770-901 Brasília, Brazil; [email protected] * Correspondence: [email protected]; Tel.: +55-61-3307-2152 Abstract: Lignocellulosic residues are low-cost abundant feedstocks that can be used for industrial applications. However, their recalcitrance currently makes lignocellulose use limited. In natural environments, microbial communities can completely deconstruct lignocellulose by synergistic action of a set of enzymes and proteins. Microbial degradation of lignin by fungi, important lignin degraders in nature, has been intensively studied. More recently, bacteria have also been described as able to break down lignin, and to have a central role in recycling this plant polymer. Nevertheless, bacterial deconstruction of lignin has not been fully elucidated yet. Direct analysis of environmental samples using metagenomics, metatranscriptomics, and metaproteomics approaches is a powerful strategy to describe/discover enzymes, metabolic pathways, and microorganisms involved in lignin breakdown. Indeed, the use of these complementary techniques leads to a better understanding of the composition, function, and dynamics of microbial communities involved in lignin deconstruction. We focus on omics approaches and their contribution to the discovery of new enzymes and reactions that impact the development of lignin-based bioprocesses. -

Evolution of the 3-Hydroxypropionate Bicycle and Recent Transfer of Anoxygenic Photosynthesis Into the Chloroflexi
Evolution of the 3-hydroxypropionate bicycle and recent transfer of anoxygenic photosynthesis into the Chloroflexi Patrick M. Shiha,b,1, Lewis M. Wardc, and Woodward W. Fischerc,1 aFeedstocks Division, Joint BioEnergy Institute, Emeryville, CA 94608; bEnvironmental Genomics and Systems Biology Division, Lawrence Berkeley National Laboratory, Berkeley, CA 94720; and cDivision of Geological and Planetary Sciences, California Institute of Technology, Pasadena, CA 91125 Edited by Bob B. Buchanan, University of California, Berkeley, CA, and approved August 21, 2017 (received for review June 14, 2017) Various lines of evidence from both comparative biology and the provide a hard geological constraint on these analyses, the timing geologic record make it clear that the biochemical machinery for of these evolutionary events remains relative, thus highlighting anoxygenic photosynthesis was present on early Earth and provided the uncertainty in our understanding of when and how anoxy- the evolutionary stock from which oxygenic photosynthesis evolved genic photosynthesis may have originated. ca. 2.3 billion years ago. However, the taxonomic identity of these A less recognized alternative is that anoxygenic photosynthesis early anoxygenic phototrophs is uncertain, including whether or not might have been acquired in modern bacterial clades relatively they remain extant. Several phototrophic bacterial clades are thought recently. This possibility is supported by the observation that to have evolved before oxygenic photosynthesis emerged, including anoxygenic photosynthesis often sits within a derived position in the Chloroflexi, a phylum common across a wide range of modern the phyla in which it is found (3). Moreover, it is increasingly environments. Although Chloroflexi have traditionally been thought being recognized that horizontal gene transfer (HGT) has likely to be an ancient phototrophic lineage, genomics has revealed a much played a major role in the distribution of phototrophy (8–10). -

A Genomic Journey Through a Genus of Large DNA Viruses
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Virology Papers Virology, Nebraska Center for 2013 Towards defining the chloroviruses: a genomic journey through a genus of large DNA viruses Adrien Jeanniard Aix-Marseille Université David D. Dunigan University of Nebraska-Lincoln, [email protected] James Gurnon University of Nebraska-Lincoln, [email protected] Irina V. Agarkova University of Nebraska-Lincoln, [email protected] Ming Kang University of Nebraska-Lincoln, [email protected] See next page for additional authors Follow this and additional works at: https://digitalcommons.unl.edu/virologypub Part of the Biological Phenomena, Cell Phenomena, and Immunity Commons, Cell and Developmental Biology Commons, Genetics and Genomics Commons, Infectious Disease Commons, Medical Immunology Commons, Medical Pathology Commons, and the Virology Commons Jeanniard, Adrien; Dunigan, David D.; Gurnon, James; Agarkova, Irina V.; Kang, Ming; Vitek, Jason; Duncan, Garry; McClung, O William; Larsen, Megan; Claverie, Jean-Michel; Van Etten, James L.; and Blanc, Guillaume, "Towards defining the chloroviruses: a genomic journey through a genus of large DNA viruses" (2013). Virology Papers. 245. https://digitalcommons.unl.edu/virologypub/245 This Article is brought to you for free and open access by the Virology, Nebraska Center for at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in Virology Papers by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. Authors Adrien Jeanniard, David D. Dunigan, James Gurnon, Irina V. Agarkova, Ming Kang, Jason Vitek, Garry Duncan, O William McClung, Megan Larsen, Jean-Michel Claverie, James L. Van Etten, and Guillaume Blanc This article is available at DigitalCommons@University of Nebraska - Lincoln: https://digitalcommons.unl.edu/ virologypub/245 Jeanniard, Dunigan, Gurnon, Agarkova, Kang, Vitek, Duncan, McClung, Larsen, Claverie, Van Etten & Blanc in BMC Genomics (2013) 14. -

Distribution of Long Linear and Branched Polyamines in the Thermophiles Belonging to the Domain Bacteria
Journal of Japanese Society for Extremophiles (2008) Vol.7 (1) Journal of Japanese Society for Extremophiles (2008), Vol. 7, 10-20 ORIGINAL PAPER Hamana Ka,b,e, Hosoya Ra, Yokota Ac, Niitsu Md, Hayashi He and Itoh Tb Distribution of long linear and branched polyamines in the thermophiles belonging to the domain Bacteria a Gunma University School of Health Sciences, Maebashi, Gunma 371-8514, Japan. bJapan Collection of Microorganisms, RIKEN, BioResource Center, Wako, Saitama 351-0198, Japan. c Institute of Molecular and Cellular Biosciences, The University of Tokyo, Tokyo 113-0032, Japan. d Faculty of Pharmaceutical Sciences, Josai University, Sakado, Saitama 350-0290, Japan. e Faculty of Engineering, Maebashi Institute of Technology, Maebashi, Gunma 371-0816, Japan. Corresponding author : Koei Hamana, [email protected] Phone : +81-27-220-8916, FAX : +81-27-220-8999 Received: April 3, 2008/ Reviced:May 26, 2008/ Acepted:June 3, 2008 Abstract Cellular polyamines of 44 newly validated have been published in eubacteria 15, 16). However, the eubacterial thermophiles growing at 45-80℃, belonging degree of thermophily is roughly estimated and not to eight orders (six phyla) of the domain Bacteria, were defined exactly. The cellular occurrence of long linear analyzed by HPLC and GC. A quaternary branched and/or branched polyamines in extremely thermophilic penta-amine, N4-bis(aminopropyl)norspermidine, was (or hyperthermophilic) eubacteria suggested that the found in Hydrogenivirga and Sulfurihydrogenibium extreme thermophiles (or hyperthermophiles) may have belonging to the order of Aquificales. Another some novel polyamine synthetic abilities possibly quaternary branched penta-amine, N4-bis(aminopropyl) associated with their thermophily 8-11, 13-15, 18, 23, 24). -

Thermobaculum Terrenum' Type Strain (YNP1)
Lawrence Berkeley National Laboratory Recent Work Title Complete genome sequence of 'Thermobaculum terrenum' type strain (YNP1). Permalink https://escholarship.org/uc/item/5d44s5qf Journal Standards in genomic sciences, 3(2) ISSN 1944-3277 Authors Kiss, Hajnalka Cleland, David Lapidus, Alla et al. Publication Date 2010-10-27 DOI 10.4056/sigs.1153107 Peer reviewed eScholarship.org Powered by the California Digital Library University of California Standards in Genomic Sciences (2010) 3:153-162 DOI:10.4056/sigs.1153107 Complete genome sequence of ‘Thermobaculum T terrenum’ type strain (YNP1 ) Hajnalka Kiss1, David Cleland2, Alla Lapidus3, Susan Lucas3, Tijana Glavina Del Rio3, Matt Nolan3, Hope Tice3, Cliff Han1, Lynne Goodwin1,3, Sam Pitluck3, Konstantinos Liolios3, Natalia Ivanova3, Konstantinos Mavromatis3, Galina Ovchinnikova3, Amrita Pati3, Amy Chen4, Krishna Palaniappan4, Miriam Land3,5, Loren Hauser3,5, Yun-Juan Chang3,5, Cynthia D. Jeffries3,5, Megan Lu3, Thomas Brettin3, John C. Detter1, Markus Göker6, Brian J. Tindall6, Brian Beck2, Timothy R. McDermott7, Tanja Woyke3, James Bristow3, Jonathan A. Eisen3,8, Victor Markowitz4, Philip Hugenholtz3, Nikos C. Kyrpides3, Hans-Peter Klenk6*, and Jan-Fang Cheng3 1 Los Alamos National Laboratory, Bioscience Division, Los Alamos, New Mexico, USA 2 ATCC- American Type Culture Collection, Manassas, Virginia, USA 3 DOE Joint Genome Institute, Walnut Creek, California, USA 4 Biological Data Management and Technology Center, Lawrence Berkeley National Laboratory, Berkeley, California, USA 5 Oak Ridge National Laboratory, Oak Ridge, Tennessee, USA 6 DSMZ - German Collection of Microorganisms and Cell Cultures GmbH, Braunschweig, Germany 7 Thermal Biology Institute, Montana State University, Bozeman, Montana, USA 8 University of California Davis Genome Center, Davis, California, USA *Corresponding author: Hans-Peter Klenk Keywords: extreme thermal soil, thermoacidophile, Gram-positive, nonmotile, non-spore- forming, obligate aerobe, Incertae sedis, Chloroflexi, GEBA ‘Thermobaculum terrenum’ Botero et al. -

Systema Naturae. the Classification of Living Organisms
Systema Naturae. The classification of living organisms. c Alexey B. Shipunov v. 5.601 (June 26, 2007) Preface Most of researches agree that kingdom-level classification of living things needs the special rules and principles. Two approaches are possible: (a) tree- based, Hennigian approach will look for main dichotomies inside so-called “Tree of Life”; and (b) space-based, Linnaean approach will look for the key differences inside “Natural System” multidimensional “cloud”. Despite of clear advantages of tree-like approach (easy to develop rules and algorithms; trees are self-explaining), in many cases the space-based approach is still prefer- able, because it let us to summarize any kinds of taxonomically related da- ta and to compare different classifications quite easily. This approach also lead us to four-kingdom classification, but with different groups: Monera, Protista, Vegetabilia and Animalia, which represent different steps of in- creased complexity of living things, from simple prokaryotic cell to compound Nature Precedings : doi:10.1038/npre.2007.241.2 Posted 16 Aug 2007 eukaryotic cell and further to tissue/organ cell systems. The classification Only recent taxa. Viruses are not included. Abbreviations: incertae sedis (i.s.); pro parte (p.p.); sensu lato (s.l.); sedis mutabilis (sed.m.); sedis possi- bilis (sed.poss.); sensu stricto (s.str.); status mutabilis (stat.m.); quotes for “environmental” groups; asterisk for paraphyletic* taxa. 1 Regnum Monera Superphylum Archebacteria Phylum 1. Archebacteria Classis 1(1). Euryarcheota 1 2(2). Nanoarchaeota 3(3). Crenarchaeota 2 Superphylum Bacteria 3 Phylum 2. Firmicutes 4 Classis 1(4). Thermotogae sed.m. 2(5). -

Widespread Impact of Horizontal Gene Transfer on Plant Colonization of Land
ARTICLE Received 10 Jun 2012 | Accepted 20 Sep 2012 | Published 23 Oct 2012 DOI: 10.1038/ncomms2148 Widespread impact of horizontal gene transfer on plant colonization of land Jipei Yue1,2, Xiangyang Hu1,3, Hang Sun1, Yongping Yang1,3 & Jinling Huang2 In complex multicellular eukaryotes such as animals and plants, horizontal gene transfer is commonly considered rare with very limited evolutionary significance. Here we show that horizontal gene transfer is a dynamic process occurring frequently in the early evolution of land plants. Our genome analyses of the moss Physcomitrella patens identified 57 families of nuclear genes that were acquired from prokaryotes, fungi or viruses. Many of these gene families were transferred to the ancestors of green or land plants. Available experimental evidence shows that these anciently acquired genes are involved in some essential or plant- specific activities such as xylem formation, plant defence, nitrogen recycling as well as the biosynthesis of starch, polyamines, hormones and glutathione. These findings suggest that horizontal gene transfer had a critical role in the transition of plants from aquatic to terrestrial environments. On the basis of these findings, we propose a model of horizontal gene transfer mechanism in nonvascular and seedless vascular plants. 1 Key Laboratory of Biodiversity and Biogeography, Kunming Institute of Botany, Chinese Academy of Sciences, Kunming 650201, China. 2 Department of Biology, East Carolina University, Greenville, North Carolina 27858, USA. 3 Institute of Tibet Plateau Research, Chinese Academy of Sciences, Kunming 650201, China. Correspondence and requests for materials should be addressed to J.H. (email: [email protected]). NATURE COMMUNICATIONS | 3:1152 | DOI: 10.1038/ncomms2148 | www.nature.com/naturecommunications © 2012 Macmillan Publishers Limited. -

Nitrolancea Hollandica Gen. Nov., Sp. Nov., a Chemolithoautotrophic Nitrite-Oxidizing Bacterium Isolated from a Bioreactor Belonging to the Phylum Chloroflexi
International Journal of Systematic and Evolutionary Microbiology (2014), 64, 1859–1865 DOI 10.1099/ijs.0.062232-0 Nitrolancea hollandica gen. nov., sp. nov., a chemolithoautotrophic nitrite-oxidizing bacterium isolated from a bioreactor belonging to the phylum Chloroflexi Dimitry Y. Sorokin,1,2 Dana Vejmelkova,3 Sebastian Lu¨cker,4 Galina M. Streshinskaya,5 W. Irene C. Rijpstra,6 Jaap S. Sinninghe Damste´,6 Robbert Kleerbezem,2 Mark van Loosdrecht,2 Gerard Muyzer7 and Holger Daims4 Correspondence 1Winogradsky Institute of Microbiology RAS, Moscow, Russia Dimitry Y. Sorokin 2Department of Biotechnology, TU Delft, The Netherlands [email protected] 3Department of Water Technology, ICT Prague, Czech Republic 4Department of Microbial Ecology, Ecology Centre, University of Vienna, Vienna, Austria 5Microbiology Department, Faculty of Biology, Lomonosov Moscow State University, Moscow, Russia 6Department of Marine Organic Biogeochemistry, NIOZ Royal Netherlands Institute for Sea Research, Den Burg, The Netherlands 7Department of Aquatic Microbiology, Institute for Biodiversity and Ecosystem Dynamics, University of Amsterdam, Amsterdam, The Netherlands A novel nitrite-oxidizing bacterium (NOB), strain LbT, was isolated from a nitrifying bioreactor with a high loading of ammonium bicarbonate in a mineral medium with nitrite as the energy source. The cells were oval (lancet-shaped) rods with pointed edges, non-motile, Gram-positive (by staining and from the cell wall structure) and non-spore-forming. Strain LbT was an obligately aerobic, chemolitoautotrophic NOB, utilizing nitrite or formate as the energy source and CO2 as the carbon source. Ammonium served as the only source of assimilated nitrogen. Growth with nitrite was optimal at pH 6.8–7.5 and at 40 6C (maximum 46 6C). -

Plastid-Localized Amino Acid Biosynthetic Pathways of Plantae Are Predominantly Composed of Non-Cyanobacterial Enzymes
Plastid-localized amino acid biosynthetic pathways of Plantae are predominantly SUBJECT AREAS: MOLECULAR EVOLUTION composed of non-cyanobacterial PHYLOGENETICS PLANT EVOLUTION enzymes PHYLOGENY Adrian Reyes-Prieto1* & Ahmed Moustafa2* Received 1 26 September 2012 Canadian Institute for Advanced Research and Department of Biology, University of New Brunswick, Fredericton, Canada, 2Department of Biology and Biotechnology Graduate Program, American University in Cairo, Egypt. Accepted 27 November 2012 Studies of photosynthetic eukaryotes have revealed that the evolution of plastids from cyanobacteria Published involved the recruitment of non-cyanobacterial proteins. Our phylogenetic survey of .100 Arabidopsis 11 December 2012 nuclear-encoded plastid enzymes involved in amino acid biosynthesis identified only 21 unambiguous cyanobacterial-derived proteins. Some of the several non-cyanobacterial plastid enzymes have a shared phylogenetic origin in the three Plantae lineages. We hypothesize that during the evolution of plastids some enzymes encoded in the host nuclear genome were mistargeted into the plastid. Then, the activity of those Correspondence and foreign enzymes was sustained by both the plastid metabolites and interactions with the native requests for materials cyanobacterial enzymes. Some of the novel enzymatic activities were favored by selective compartmentation should be addressed to of additional complementary enzymes. The mosaic phylogenetic composition of the plastid amino acid A.R.-P. ([email protected]) biosynthetic pathways and the reduced number of plastid-encoded proteins of non-cyanobacterial origin suggest that enzyme recruitment underlies the recompartmentation of metabolic routes during the evolution of plastids. * Equal contribution made by these authors. rimary plastids of plants and algae are the evolutionary outcome of an endosymbiotic association between eukaryotes and cyanobacteria1. -

Highly Abundant and Diverse Planktonic Freshwater Chloroflexi
bioRxiv preprint doi: https://doi.org/10.1101/366732; this version posted July 10, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 Hidden in plain sight - highly abundant and diverse planktonic freshwater Chloroflexi 2 3 Maliheh Mehrshad1*, Michaela M. Salcher2, Yusuke Okazaki3, Shin-ichi Nakano3, Karel Šimek1, 4 Adrian-Stefan Andrei1, Rohit Ghai1* 5 6 1 Biology Centre of the Czech Academy of Sciences, Institute of Hydrobiology, Department of Aquatic 7 Microbial Ecology, České Budějovice, Czech Republic 8 2 Department of Limnology, Institute of Plant Biology, University of Zurich, Seestrasse 187, CH-8802 9 Kilchberg, Switzerland 10 3 Center for Ecological Research, Kyoto University, 2-509-3 Hirano, Otsu, Shiga, 520-2113, Japan 11 12 *Corresponding authors: 13 Maliheh Mehrshad 14 Rohit Ghai 15 Institute of Hydrobiology, Department of Aquatic Microbial Ecology, Biology Centre ASCR 16 Na Sádkách 7, 370 05, České Budějovice, Czech Republic 17 Tel: 00420 38777 5819 18 Email: [email protected], 19 [email protected] 20 bioRxiv preprint doi: https://doi.org/10.1101/366732; this version posted July 10, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 21 Abstract 22 Background: Representatives of the phylum Chloroflexi, though reportedly highly abundant (up to 23 30% of total prokaryotes) in the extensive deep water habitats of both marine (SAR202) and 24 freshwater (CL500-11), remain uncultivated and uncharacterized. -

Multidomain Ribosomal Protein Trees and the Planctobacterial Origin of Neomura (Eukaryotes, Archaebacteria)
Protoplasma https://doi.org/10.1007/s00709-019-01442-7 REVIEW Multidomain ribosomal protein trees and the planctobacterial origin of neomura (eukaryotes, archaebacteria) Thomas Cavalier-Smith1 & Ema E-Yung Chao1 Received: 25 February 2019 /Accepted: 19 September 2019 # The Author(s) 2020 Abstract Palaeontologically, eubacteria are > 3× older than neomura (eukaryotes, archaebacteria). Cell biology contrasts ancestral eubac- terial murein peptidoglycan walls and derived neomuran N-linked glycoprotein coats/walls. Misinterpreting long stems connecting clade neomura to eubacteria on ribosomal sequence trees (plus misinterpreted protein paralogue trees) obscured this historical pattern. Universal multiprotein ribosomal protein (RP) trees, more accurate than rRNA trees, are taxonomically undersampled. To reduce contradictions with genically richer eukaryote trees and improve eubacterial phylogeny, we constructed site-heterogeneous and maximum-likelihood universal three-domain, two-domain, and single-domain trees for 143 eukaryotes (branching now congruent with 187-protein trees), 60 archaebacteria, and 151 taxonomically representative eubacteria, using 51 and 26 RPs. Site-heterogeneous trees greatly improve eubacterial phylogeny and higher classification, e.g. showing gracilicute monophyly, that many ‘rDNA-phyla’ belong in Proteobacteria, and reveal robust new phyla Synthermota and Aquithermota. Monoderm Posibacteria and Mollicutes (two separate wall losses) are both polyphyletic: multiple outer membrane losses in Endobacteria occurred separately