Supporting Information
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
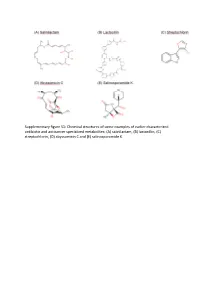
Chemical Structures of Some Examples of Earlier Characterized Antibiotic and Anticancer Specialized
Supplementary figure S1: Chemical structures of some examples of earlier characterized antibiotic and anticancer specialized metabolites: (A) salinilactam, (B) lactocillin, (C) streptochlorin, (D) abyssomicin C and (E) salinosporamide K. Figure S2. Heat map representing hierarchical classification of the SMGCs detected in all the metagenomes in the dataset. Table S1: The sampling locations of each of the sites in the dataset. Sample Sample Bio-project Site depth accession accession Samples Latitude Longitude Site description (m) number in SRA number in SRA AT0050m01B1-4C1 SRS598124 PRJNA193416 Atlantis II water column 50, 200, Water column AT0200m01C1-4D1 SRS598125 21°36'19.0" 38°12'09.0 700 and above the brine N "E (ATII 50, ATII 200, 1500 pool water layers AT0700m01C1-3D1 SRS598128 ATII 700, ATII 1500) AT1500m01B1-3C1 SRS598129 ATBRUCL SRS1029632 PRJNA193416 Atlantis II brine 21°36'19.0" 38°12'09.0 1996– Brine pool water ATBRLCL1-3 SRS1029579 (ATII UCL, ATII INF, N "E 2025 layers ATII LCL) ATBRINP SRS481323 PRJNA219363 ATIID-1a SRS1120041 PRJNA299097 ATIID-1b SRS1120130 ATIID-2 SRS1120133 2168 + Sea sediments Atlantis II - sediments 21°36'19.0" 38°12'09.0 ~3.5 core underlying ATII ATIID-3 SRS1120134 (ATII SDM) N "E length brine pool ATIID-4 SRS1120135 ATIID-5 SRS1120142 ATIID-6 SRS1120143 Discovery Deep brine DDBRINP SRS481325 PRJNA219363 21°17'11.0" 38°17'14.0 2026– Brine pool water N "E 2042 layers (DD INF, DD BR) DDBRINE DD-1 SRS1120158 PRJNA299097 DD-2 SRS1120203 DD-3 SRS1120205 Discovery Deep 2180 + Sea sediments sediments 21°17'11.0" -

Expanding the Chlamydiae Tree
Digital Comprehensive Summaries of Uppsala Dissertations from the Faculty of Science and Technology 2040 Expanding the Chlamydiae tree Insights into genome diversity and evolution JENNAH E. DHARAMSHI ACTA UNIVERSITATIS UPSALIENSIS ISSN 1651-6214 ISBN 978-91-513-1203-3 UPPSALA urn:nbn:se:uu:diva-439996 2021 Dissertation presented at Uppsala University to be publicly examined in A1:111a, Biomedical Centre (BMC), Husargatan 3, Uppsala, Tuesday, 8 June 2021 at 13:15 for the degree of Doctor of Philosophy. The examination will be conducted in English. Faculty examiner: Prof. Dr. Alexander Probst (Faculty of Chemistry, University of Duisburg-Essen). Abstract Dharamshi, J. E. 2021. Expanding the Chlamydiae tree. Insights into genome diversity and evolution. Digital Comprehensive Summaries of Uppsala Dissertations from the Faculty of Science and Technology 2040. 87 pp. Uppsala: Acta Universitatis Upsaliensis. ISBN 978-91-513-1203-3. Chlamydiae is a phylum of obligate intracellular bacteria. They have a conserved lifecycle and infect eukaryotic hosts, ranging from animals to amoeba. Chlamydiae includes pathogens, and is well-studied from a medical perspective. However, the vast majority of chlamydiae diversity exists in environmental samples as part of the uncultivated microbial majority. Exploration of microbial diversity in anoxic deep marine sediments revealed diverse chlamydiae with high relative abundances. Using genome-resolved metagenomics various marine sediment chlamydiae genomes were obtained, which significantly expanded genomic sampling of Chlamydiae diversity. These genomes formed several new clades in phylogenomic analyses, and included Chlamydiaceae relatives. Despite endosymbiosis-associated genomic features, hosts were not identified, suggesting chlamydiae with alternate lifestyles. Genomic investigation of Anoxychlamydiales, newly described here, uncovered genes for hydrogen metabolism and anaerobiosis, suggesting they engage in syntrophic interactions. -

Genomic Analysis of Family UBA6911 (Group 18 Acidobacteria)
bioRxiv preprint doi: https://doi.org/10.1101/2021.04.09.439258; this version posted April 10, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. 1 2 Genomic analysis of family UBA6911 (Group 18 3 Acidobacteria) expands the metabolic capacities of the 4 phylum and highlights adaptations to terrestrial habitats. 5 6 Archana Yadav1, Jenna C. Borrelli1, Mostafa S. Elshahed1, and Noha H. Youssef1* 7 8 1Department of Microbiology and Molecular Genetics, Oklahoma State University, Stillwater, 9 OK 10 *Correspondence: Noha H. Youssef: [email protected] bioRxiv preprint doi: https://doi.org/10.1101/2021.04.09.439258; this version posted April 10, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. 11 Abstract 12 Approaches for recovering and analyzing genomes belonging to novel, hitherto unexplored 13 bacterial lineages have provided invaluable insights into the metabolic capabilities and 14 ecological roles of yet-uncultured taxa. The phylum Acidobacteria is one of the most prevalent 15 and ecologically successful lineages on earth yet, currently, multiple lineages within this phylum 16 remain unexplored. Here, we utilize genomes recovered from Zodletone spring, an anaerobic 17 sulfide and sulfur-rich spring in southwestern Oklahoma, as well as from multiple disparate soil 18 and non-soil habitats, to examine the metabolic capabilities and ecological role of members of 19 the family UBA6911 (group18) Acidobacteria. -

Deconstruction of Lignin: from Enzymes to Microorganisms
molecules Review Deconstruction of Lignin: From Enzymes to Microorganisms Jéssica P. Silva 1, Alonso R. P. Ticona 1 , Pedro R. V. Hamann 1, Betania F. Quirino 2 and Eliane F. Noronha 1,* 1 Enzymology Laboratory, Cell Biology Department, University of Brasilia, 70910-900 Brasília, Brazil; [email protected] (J.P.S.); [email protected] (A.R.P.T.); [email protected] (P.R.V.H.) 2 Genetics and Biotechnology Laboratory, Embrapa-Agroenergy, 70770-901 Brasília, Brazil; [email protected] * Correspondence: [email protected]; Tel.: +55-61-3307-2152 Abstract: Lignocellulosic residues are low-cost abundant feedstocks that can be used for industrial applications. However, their recalcitrance currently makes lignocellulose use limited. In natural environments, microbial communities can completely deconstruct lignocellulose by synergistic action of a set of enzymes and proteins. Microbial degradation of lignin by fungi, important lignin degraders in nature, has been intensively studied. More recently, bacteria have also been described as able to break down lignin, and to have a central role in recycling this plant polymer. Nevertheless, bacterial deconstruction of lignin has not been fully elucidated yet. Direct analysis of environmental samples using metagenomics, metatranscriptomics, and metaproteomics approaches is a powerful strategy to describe/discover enzymes, metabolic pathways, and microorganisms involved in lignin breakdown. Indeed, the use of these complementary techniques leads to a better understanding of the composition, function, and dynamics of microbial communities involved in lignin deconstruction. We focus on omics approaches and their contribution to the discovery of new enzymes and reactions that impact the development of lignin-based bioprocesses. -

Evolution Génomique Chez Les Bactéries Du Super Phylum Planctomycetes-Verrucomicrobiae-Chlamydia
AIX-MARSEILLE UNIVERSITE FACULTE DE MEDECINE DE MARSEILLE ECOLE DOCTORALE : SCIENCE DE LA VIE ET DE LA SANTE THESE Présentée et publiquement soutenue devant LA FACULTE DE MEDECINE DE MARSEILLE Le 15 janvier 2016 Par Mme Sandrine PINOS Née à Saint-Gaudens le 09 octobre 1989 TITRE DE LA THESE: Evolution génomique chez les bactéries du super phylum Planctomycetes-Verrucomicrobiae-Chlamydia Pour obtenir le grade de DOCTORAT d'AIX-MARSEILLE UNIVERSITE Spécialité : Génomique et Bioinformatique Membres du jury de la Thèse: Pr Didier RAOULT .................................................................................Directeur de thèse Dr Pierre PONTAROTTI ....................................................................Co-directeur de thèse Pr Gilbert GREUB .............................................................................................Rapporteur Dr Pascal SIMONET............................................................................................Rapporteur Laboratoires d’accueil Unité de Recherche sur les Maladies Infectieuses et Tropicales Emergentes – UMR CNRS 6236, IRD 198 I2M - UMR CNRS 7373 - EBM 1 Avant propos Le format de présentation de cette thèse correspond à une recommandation de la spécialité Maladies Infectieuses et Microbiologie, à l’intérieur du Master de Sciences de la Vie et de la Santé qui dépend de l’Ecole Doctorale des Sciences de la Vie de Marseille. Le candidat est amené à respecter des règles qui lui sont imposées et qui comportent un format de thèse utilisé dans le Nord de l’Europe permettant un meilleur rangement que les thèses traditionnelles. Par ailleurs, la partie introduction et bibliographie est remplacée par une revue envoyée dans un journal afin de permettre une évaluation extérieure de la qualité de la revue et de permettre à l’étudiant de le commencer le plus tôt possible une bibliographie exhaustive sur le domaine de cette thèse. Par ailleurs, la thèse est présentée sur article publié, accepté ou soumis associé d’un bref commentaire donnant le sens général du travail. -

Evolution of the 3-Hydroxypropionate Bicycle and Recent Transfer of Anoxygenic Photosynthesis Into the Chloroflexi
Evolution of the 3-hydroxypropionate bicycle and recent transfer of anoxygenic photosynthesis into the Chloroflexi Patrick M. Shiha,b,1, Lewis M. Wardc, and Woodward W. Fischerc,1 aFeedstocks Division, Joint BioEnergy Institute, Emeryville, CA 94608; bEnvironmental Genomics and Systems Biology Division, Lawrence Berkeley National Laboratory, Berkeley, CA 94720; and cDivision of Geological and Planetary Sciences, California Institute of Technology, Pasadena, CA 91125 Edited by Bob B. Buchanan, University of California, Berkeley, CA, and approved August 21, 2017 (received for review June 14, 2017) Various lines of evidence from both comparative biology and the provide a hard geological constraint on these analyses, the timing geologic record make it clear that the biochemical machinery for of these evolutionary events remains relative, thus highlighting anoxygenic photosynthesis was present on early Earth and provided the uncertainty in our understanding of when and how anoxy- the evolutionary stock from which oxygenic photosynthesis evolved genic photosynthesis may have originated. ca. 2.3 billion years ago. However, the taxonomic identity of these A less recognized alternative is that anoxygenic photosynthesis early anoxygenic phototrophs is uncertain, including whether or not might have been acquired in modern bacterial clades relatively they remain extant. Several phototrophic bacterial clades are thought recently. This possibility is supported by the observation that to have evolved before oxygenic photosynthesis emerged, including anoxygenic photosynthesis often sits within a derived position in the Chloroflexi, a phylum common across a wide range of modern the phyla in which it is found (3). Moreover, it is increasingly environments. Although Chloroflexi have traditionally been thought being recognized that horizontal gene transfer (HGT) has likely to be an ancient phototrophic lineage, genomics has revealed a much played a major role in the distribution of phototrophy (8–10). -

MIAMI UNIVERSITY the Graduate School Certificate for Approving The
MIAMI UNIVERSITY The Graduate School Certificate for Approving the Dissertation We hereby approve the Dissertation of Qiuyuan Huang Candidate for the Degree: Doctor of Philosophy _______________________________________ Hailiang Dong, Director ________________________________________ Yildirim Dilek, Reader ________________________________________ Jonathan Levy, Reader ______________________________________ Chuanlun Zhang, External examiner ______________________________________ Annette Bollmann, Graduate School Representative ABSTRACT GEOMICROBIAL INVESTIGATIONS ON EXTREME ENVIRONMENTS: LINKING GEOCHEMISTRY TO MICROBIAL ECOLOGY IN TERRESTRIAL HOT SPRINGS AND SALINE LAKES by Qiuyuan Huang Terrestrial hot springs and saline lakes represent two extreme environments for microbial life and constitute an important part of global ecosystems that affect the biogeochemical cycling of life-essential elements. Despite the advances in our understanding of microbial ecology in the past decade, important questions remain regarding the link between microbial diversity and geochemical factors under these extreme conditions. This dissertation first investigates a series of hot springs with wide ranges of temperature (26-92oC) and pH (3.72-8.2) from the Tibetan Plateau in China and the Philippines. Within each region, microbial diversity and geochemical conditions were studied using an integrated approach with 16S rRNA molecular phylogeny and a suite of geochemical analyses. In Tibetan springs, the microbial community was dominated by archaeal phylum Thaumarchaeota -

Molecular Diversity and Ecology of Microbial Plankton Stephen J
02 Giovanni 9-14 6/9/05 9:22 AM Page 9 NATURE|Vol 437|15 September 2005|doi:10.1038/nature04158 INSIGHT REVIEW Molecular diversity and ecology of microbial plankton Stephen J. Giovannoni1 & Ulrich Stingl1 The history of microbial evolution in the oceans is probably as old as the history of life itself. In contrast to terrestrial ecosystems, microorganisms are the main form of biomass in the oceans, and form some of the largest populations on the planet. Theory predicts that selection should act more efficiently in large populations. But whether microbial plankton populations harbour organisms that are models of adaptive sophistication remains to be seen. Genome sequence data are piling up, but most of the key microbial plankton clades have no cultivated representatives, and information about their ecological activities is sparse. Certain characteristics of the ocean environment — the prevailing cultivation of key organisms, metagenomics and ongoing biogeo- low-nutrient state of the ocean surface, in particular — mean it is chemical studies. It seems very likely that the biology of the dominant sometimes regarded as an extreme ecosystem. Fixed forms of nitrogen, microbial plankton groups will be unravelled in the years ahead. phosphorus and iron are often at very low or undetectable levels in the Here we review current knowledge about marine bacterial and ocean’s circulatory gyres, which occur in about 70% of the oceans1. archaeal diversity, as inferred from phylogenies of genes recovered Photosynthesis is the main source of metabolic energy and the basis of from the ocean water column, and consider the implications of micro- the food chain; ocean phytoplankton account for nearly 50% of global bial diversity for understanding the ecology of the oceans. -

Multi-Targeting Therapeutic Mechanisms of the Chinese Herbal Medicine QHD in the Treatment of Non-Alcoholic Fatty Liver Disease
www.impactjournals.com/oncotarget/ Oncotarget, 2017, Vol. 8, (No. 17), pp: 27820-27838 Research Paper Multi-targeting therapeutic mechanisms of the Chinese herbal medicine QHD in the treatment of non-alcoholic fatty liver disease Qin Feng1,2,3,*, Wensheng Liu2,3,*, Susan S. Baker2,3, Hongshan Li4, Cheng Chen1, Qian Liu1, Shijie Tang5, Lingyu Guan5, Maria Tsompana6, Rafal Kozielski8,9, Robert D. Baker2,3, Jinghua Peng1, Ping Liu1, Ruixin Zhu5, Yiyang Hu1, Lixin Zhu2,3,7 1Institute of Liver Disease, Shuguang Hospital, Shanghai University of Traditional Chinese Medicine, Shanghai, China 2Digestive Diseases and Nutrition Center, Women and Children’s Hospital of Buffalo, Buffalo, NY, USA 3Department of Pediatrics, The State University of New York at Buffalo, Buffalo, New York, USA 4Ningbo No.2 Hospital, Ningbo, Zhejiang Province, China 5Department of Bioinformatics, Tongji University, Shanghai, China 6Center of Excellence in Bioinformatics and Life Sciences, The State University of New York at Buffalo, Buffalo, New York, USA 7Institute of Digestive Diseases, Longhua Hospital, Shanghai University of Traditional Chinese Medicine, Shanghai, China 8Women and Children’s Hospital of Buffalo, Buffalo, NY, USA 9Department of Pathology, The State University of New York at Buffalo, Buffalo, New York, USA *These authors contributed equally to this work Correspondence to: Lixin Zhu, email: [email protected] Yiyang Hu, email: [email protected] Keywords: NAFLD, lipid synthesis, anti-oxidant, gut microbiome, Treg Received: December 28, 2016 Accepted: February 08, 2017 Published: February 18, 2017 Copyright: Feng et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC-BY), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. -

Bacterial Biomarkers of Marcellus Shale Activity in Pennsylvania
Lawrence Berkeley National Laboratory Recent Work Title Bacterial Biomarkers of Marcellus Shale Activity in Pennsylvania. Permalink https://escholarship.org/uc/item/40b5p10v Journal Frontiers in microbiology, 9(AUG) ISSN 1664-302X Authors Chen See, Jeremy R Ulrich, Nikea Nwanosike, Hephzibah et al. Publication Date 2018 DOI 10.3389/fmicb.2018.01697 Peer reviewed eScholarship.org Powered by the California Digital Library University of California fmicb-09-01697 July 30, 2018 Time: 16:56 # 1 ORIGINAL RESEARCH published: 02 August 2018 doi: 10.3389/fmicb.2018.01697 Bacterial Biomarkers of Marcellus Shale Activity in Pennsylvania Jeremy R. Chen See1, Nikea Ulrich1, Hephzibah Nwanosike1, Christopher J. McLimans1, Vasily Tokarev1, Justin R. Wright1, Maria F. Campa2, Christopher J. Grant1, Terry C. Hazen2,3,4, Jonathan M. Niles5, Daniel Ressler6 and Regina Lamendella1* 1 Department of Biology, Juniata College, Huntingdon, PA, United States, 2 The Bredesen Center, The University of Tennessee, Knoxville, Knoxville, TN, United States, 3 Department of Civil and Environmental Engineering, The University of Tennessee, Knoxville, Knoxville, TN, United States, 4 Biosciences Division, Oak Ridge National Laboratory, Oak Ridge, TN, United States, 5 Freshwater Research Initiative, Susquehanna University, Selinsgrove, PA, United States, 6 Department of Earth and Environmental Sciences, Susquehanna University, Selinsgrove, PA, United States Unconventional oil and gas (UOG) extraction, also known as hydraulic fracturing, is becoming more prevalent with the increasing use and demand for natural gas; however, the full extent of its environmental impacts is still unknown. Here we measured physicochemical properties and bacterial community composition of sediment samples Edited by: taken from twenty-eight streams within the Marcellus shale formation in northeastern James Cotner, Pennsylvania differentially impacted by hydraulic fracturing activities. -

A Genomic Journey Through a Genus of Large DNA Viruses
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Virology Papers Virology, Nebraska Center for 2013 Towards defining the chloroviruses: a genomic journey through a genus of large DNA viruses Adrien Jeanniard Aix-Marseille Université David D. Dunigan University of Nebraska-Lincoln, [email protected] James Gurnon University of Nebraska-Lincoln, [email protected] Irina V. Agarkova University of Nebraska-Lincoln, [email protected] Ming Kang University of Nebraska-Lincoln, [email protected] See next page for additional authors Follow this and additional works at: https://digitalcommons.unl.edu/virologypub Part of the Biological Phenomena, Cell Phenomena, and Immunity Commons, Cell and Developmental Biology Commons, Genetics and Genomics Commons, Infectious Disease Commons, Medical Immunology Commons, Medical Pathology Commons, and the Virology Commons Jeanniard, Adrien; Dunigan, David D.; Gurnon, James; Agarkova, Irina V.; Kang, Ming; Vitek, Jason; Duncan, Garry; McClung, O William; Larsen, Megan; Claverie, Jean-Michel; Van Etten, James L.; and Blanc, Guillaume, "Towards defining the chloroviruses: a genomic journey through a genus of large DNA viruses" (2013). Virology Papers. 245. https://digitalcommons.unl.edu/virologypub/245 This Article is brought to you for free and open access by the Virology, Nebraska Center for at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in Virology Papers by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. Authors Adrien Jeanniard, David D. Dunigan, James Gurnon, Irina V. Agarkova, Ming Kang, Jason Vitek, Garry Duncan, O William McClung, Megan Larsen, Jean-Michel Claverie, James L. Van Etten, and Guillaume Blanc This article is available at DigitalCommons@University of Nebraska - Lincoln: https://digitalcommons.unl.edu/ virologypub/245 Jeanniard, Dunigan, Gurnon, Agarkova, Kang, Vitek, Duncan, McClung, Larsen, Claverie, Van Etten & Blanc in BMC Genomics (2013) 14. -

Marine Sediments Illuminate Chlamydiae Diversity and Evolution
Supplementary Information for: Marine sediments illuminate Chlamydiae diversity and evolution Jennah E. Dharamshi1, Daniel Tamarit1†, Laura Eme1†, Courtney Stairs1, Joran Martijn1, Felix Homa1, Steffen L. Jørgensen2, Anja Spang1,3, Thijs J. G. Ettema1,4* 1 Department of Cell and Molecular Biology, Science for Life Laboratory, Uppsala University, SE-75123 Uppsala, Sweden 2 Department of Earth Science, Centre for Deep Sea Research, University of Bergen, N-5020 Bergen, Norway 3 Department of Marine Microbiology and Biogeochemistry, NIOZ Royal Netherlands Institute for Sea Research, and Utrecht University, NL-1790 AB Den Burg, The Netherlands 4 Laboratory of Microbiology, Department of Agrotechnology and Food Sciences, Wageningen University, 6708 WE Wageningen, The Netherlands. † These authors contributed equally * Correspondence to: Thijs J. G. Ettema, Email: [email protected] Supplementary Information Supplementary Discussions ............................................................................................................................ 3 1. Evolutionary relationships within the Chlamydiae phylum ............................................................................. 3 2. Insights into the evolution of pathogenicity in Chlamydiaceae ...................................................................... 8 3. Secretion systems and flagella in Chlamydiae .............................................................................................. 13 4. Phylogenetic diversity of chlamydial nucleotide transporters. ....................................................................