Dell EMC Powerscale Network Design Considerations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
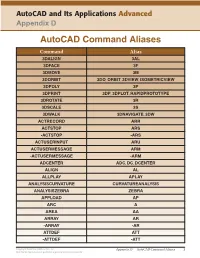
Autocad Command Aliases
AutoCAD and Its Applications Advanced Appendix D AutoCAD Command Aliases Command Alias 3DALIGN 3AL 3DFACE 3F 3DMOVE 3M 3DORBIT 3DO, ORBIT, 3DVIEW, ISOMETRICVIEW 3DPOLY 3P 3DPRINT 3DP, 3DPLOT, RAPIDPROTOTYPE 3DROTATE 3R 3DSCALE 3S 3DWALK 3DNAVIGATE, 3DW ACTRECORD ARR ACTSTOP ARS -ACTSTOP -ARS ACTUSERINPUT ARU ACTUSERMESSAGE ARM -ACTUSERMESSAGE -ARM ADCENTER ADC, DC, DCENTER ALIGN AL ALLPLAY APLAY ANALYSISCURVATURE CURVATUREANALYSIS ANALYSISZEBRA ZEBRA APPLOAD AP ARC A AREA AA ARRAY AR -ARRAY -AR ATTDEF ATT -ATTDEF -ATT Copyright Goodheart-Willcox Co., Inc. Appendix D — AutoCAD Command Aliases 1 May not be reproduced or posted to a publicly accessible website. Command Alias ATTEDIT ATE -ATTEDIT -ATE, ATTE ATTIPEDIT ATI BACTION AC BCLOSE BC BCPARAMETER CPARAM BEDIT BE BLOCK B -BLOCK -B BOUNDARY BO -BOUNDARY -BO BPARAMETER PARAM BREAK BR BSAVE BS BVSTATE BVS CAMERA CAM CHAMFER CHA CHANGE -CH CHECKSTANDARDS CHK CIRCLE C COLOR COL, COLOUR COMMANDLINE CLI CONSTRAINTBAR CBAR CONSTRAINTSETTINGS CSETTINGS COPY CO, CP CTABLESTYLE CT CVADD INSERTCONTROLPOINT CVHIDE POINTOFF CVREBUILD REBUILD CVREMOVE REMOVECONTROLPOINT CVSHOW POINTON Copyright Goodheart-Willcox Co., Inc. Appendix D — AutoCAD Command Aliases 2 May not be reproduced or posted to a publicly accessible website. Command Alias CYLINDER CYL DATAEXTRACTION DX DATALINK DL DATALINKUPDATE DLU DBCONNECT DBC, DATABASE, DATASOURCE DDGRIPS GR DELCONSTRAINT DELCON DIMALIGNED DAL, DIMALI DIMANGULAR DAN, DIMANG DIMARC DAR DIMBASELINE DBA, DIMBASE DIMCENTER DCE DIMCONSTRAINT DCON DIMCONTINUE DCO, DIMCONT DIMDIAMETER DDI, DIMDIA DIMDISASSOCIATE DDA DIMEDIT DED, DIMED DIMJOGGED DJO, JOG DIMJOGLINE DJL DIMLINEAR DIMLIN, DLI DIMORDINATE DOR, DIMORD DIMOVERRIDE DOV, DIMOVER DIMRADIUS DIMRAD, DRA DIMREASSOCIATE DRE DIMSTYLE D, DIMSTY, DST DIMTEDIT DIMTED DIST DI, LENGTH DIVIDE DIV DONUT DO DRAWINGRECOVERY DRM DRAWORDER DR Copyright Goodheart-Willcox Co., Inc. -

CS101 Lecture 9
How do you copy/move/rename/remove files? How do you create a directory ? What is redirection and piping? Readings: See CCSO’s Unix pages and 9-2 cp option file1 file2 First Version cp file1 file2 file3 … dirname Second Version This is one version of the cp command. file2 is created and the contents of file1 are copied into file2. If file2 already exits, it This version copies the files file1, file2, file3,… into the directory will be replaced with a new one. dirname. where option is -i Protects you from overwriting an existing file by asking you for a yes or no before it copies a file with an existing name. -r Can be used to copy directories and all their contents into a new directory 9-3 9-4 cs101 jsmith cs101 jsmith pwd data data mp1 pwd mp1 {FILES: mp1_data.m, mp1.m } {FILES: mp1_data.m, mp1.m } Copy the file named mp1_data.m from the cs101/data Copy the file named mp1_data.m from the cs101/data directory into the pwd. directory into the mp1 directory. > cp ~cs101/data/mp1_data.m . > cp ~cs101/data/mp1_data.m mp1 The (.) dot means “here”, that is, your pwd. 9-5 The (.) dot means “here”, that is, your pwd. 9-6 Example: To create a new directory named “temp” and to copy mv option file1 file2 First Version the contents of an existing directory named mp1 into temp, This is one version of the mv command. file1 is renamed file2. where option is -i Protects you from overwriting an existing file by asking you > cp -r mp1 temp for a yes or no before it copies a file with an existing name. -

How to Find out the IP Address of an Omron
Communications Middleware/Network Browser How to find an Omron Controller’s IP address Valin Corporation | www.valin.com Overview • Many Omron PLC’s have Ethernet ports or Ethernet port options • The IP address for a PLC is usually changed by the programmer • Most customers do not mark the controller with IP address (label etc.) • Very difficult to communicate to the PLC over Ethernet if the IP address is unknown. Valin Corporation | www.valin.com Simple Ethernet Network Basics IP address is up to 12 digits (4 octets) Ex:192.168.1.1 For MOST PLC programming applications, the first 3 octets are the network address and the last is the node address. In above example 192.168.1 is network address, 1 is node address. For devices to communicate on a simple network: • Every device IP Network address must be the same. • Every device node number must be different. Device Laptop EX: Omron PLC 192.168.1.1 192.168.1.1 Device Laptop EX: Omron PLC 127.27.250.5 192.168.1.1 Device Laptop EX: Omron PLC 192.168.1.3 192.168.1.1 Valin Corporation | www.valin.com Omron Default IP Address • Most Omron Ethernet devices use one of the following IP addresses by default. Omron PLC 192.168.250.1 OR 192.168.1.1 Valin Corporation | www.valin.com PING Command • PING is a way to check if the device is connected (both virtually and physically) to the network. • Windows Command Prompt command. • PC must use the same network number as device (See previous) • Example: “ping 172.21.90.5” will test to see if a device with that IP address is connected to the PC. -

Xerox® Colorqube 8580/8880 Color Printer 3 System Administrator Guide
Xerox® ColorQube® 8580 / 8880 Color Printer Imprimante couleur System Administrator Guide Guide de l’administrateur système © 2015 Xerox Corporation. All rights reserved. Unpublished rights reserved under the copyright laws of the United States. Contents of this publication may not be reproduced in any form without permission of Xerox Corporation. Copyright protection claimed includes all forms of matters of copyrightable materials and information now allowed by statutory or judicial law or hereinafter granted, including without limitation, material generated from the software programs which are displayed on the screen such as styles, templates, icons, screen displays, looks, and so on. Xerox® and Xerox and Design®, Phaser®, PhaserSMART®, PhaserMatch®, PhaserCal®, PhaserMeter™, CentreWare®, PagePack®, eClick®, PrintingScout®, Walk-Up®, WorkCentre®, FreeFlow®, SMARTsend®, Scan to PC Desktop®, MeterAssistant®, SuppliesAssistant®, Xerox Secure Access Unified ID System®, Xerox Extensible Interface Platform®, ColorQube®, Global Print Driver®, and Mobile Express Driver® are trademarks of Xerox Corporation in the United States and/or other countries. Adobe® Reader®, Adobe® Type Manager®, ATM™, Flash®, Macromedia®, Photoshop®, and PostScript® are trademarks of Adobe Systems Incorporated in the United States and/or other countries. Apple, Bonjour, EtherTalk, TrueType, iPad, iPhone, iPod, iPod touch, Mac and Mac OS are trademarks of Apple Inc., registered in the U.S. and other countries. AirPrint and the AirPrint logo are trademarks of Apple Inc. HP-GL®, HP-UX®, and PCL® are trademarks of Hewlett-Packard Corporation in the United States and/or other countries. IBM® and AIX® are trademarks of International Business Machines Corporation in the United States and/or other countries. Microsoft®, Windows Vista®, Windows®, and Windows Server® are trademarks of Microsoft Corporation in the United States and other countries. -

A Comparison of TCP Automatic Tuning Techniques for Distributed
A Comparison of TCP Automatic Tuning Techniques for Distributed Computing Eric Weigle [email protected] Computer and Computational Sciences Division (CCS-1) Los Alamos National Laboratory Los Alamos, NM 87545 Abstract— Manual tuning is the baseline by which we measure autotun- Rather than painful, manual, static, per-connection optimization of TCP ing methods. To perform manual tuning, a human uses tools buffer sizes simply to achieve acceptable performance for distributed appli- ping pathchar pipechar cations [1], [2], many researchers have proposed techniques to perform this such as and or to determine net- tuning automatically [3], [4], [5], [6], [7], [8]. This paper first discusses work latency and bandwidth. The results are multiplied to get the relative merits of the various approaches in theory, and then provides the bandwidth £ delay product, and buffers are generally set to substantial experimental data concerning two competing implementations twice that value. – the buffer autotuning already present in Linux 2.4.x and “Dynamic Right- Sizing.” This paper reveals heretofore unknown aspects of the problem and PSC’s tuning is a mostly sender-based approach. Here the current solutions, provides insight into the proper approach for various cir- cumstances, and points toward ways to improve performance further. sender uses TCP packet header information and timestamps to estimate the bandwidth £ delay product of the network, which Keywords: dynamic right-sizing, autotuning, high-performance it uses to resize its send window. The receiver simply advertises networking, TCP, flow control, wide-area network. the maximal possible window. Paper [3] presents results for a NetBSD 1.2 implementation, showing improvement over stock I. -

Cs-204: Computer Networks
CS-204: COMPUTER NETWORKS Lecture 5 Chapter 19- Network Layer: Logical Addressing Instructor: Dr. Vandana Kushwaha 1. INTRODUCTION Communication at the network layer is host-to-host (computer-to-computer); a computer somewhere in the world needs to communicate with another computer somewhere else in the world. Usually, computers communicate through the Internet. The packet transmitted by the sending computer may pass through several LANs or WANs before reaching the destination computer. For this level of communication, we need a global addressing scheme; we called this logical addressing or IP address. 2. IPv4 ADDRESSES An IPv4 address is a 32-bit address that uniquely and universally defines the connection of a device (for example, a computer or a router) to the Internet. IPv4 addresses are unique. They are unique in the sense that each address defines one, and only one, connection to the Internet. Two devices on the Internet can never have the same address at the same time. But by using some strategies, an address may be assigned to a device for a time period and then taken away and assigned to another device. On the other hand, if a device operating at the network layer has m connections to the Internet, it needs to have m addresses. A router is such a device which needs as many IP addresses as the number of ports are there in it. 2.1. Address Space A protocol such as IPv4 that defines addresses has an address space. An address space is the total number of addresses used by the protocol. If a protocol uses N bits to define an address, the address space is 2N because each bit can have two different values (0 or 1) and N bits can have 2N values. -

Network Tuning and Monitoring for Disaster Recovery Data Backup and Retrieval ∗ ∗
Network Tuning and Monitoring for Disaster Recovery Data Backup and Retrieval ∗ ∗ 1 Prasad Calyam, 2 Phani Kumar Arava, 1 Chris Butler, 3 Jeff Jones 1 Ohio Supercomputer Center, Columbus, Ohio 43212. Email:{pcalyam, cbutler}@osc.edu 2 The Ohio State University, Columbus, Ohio 43210. Email:[email protected] 3 Wright State University, Dayton, Ohio 45435. Email:[email protected] Abstract frequently moving a copy of their local data to tape-drives at off-site sites. With the increased access to high-speed net- Every institution is faced with the challenge of setting up works, most copy mechanisms rely on IP networks (versus a system that can enable backup of large amounts of critical postal service) as a medium to transport the backup data be- administrative data. This data should be rapidly retrieved in tween the institutions and off-site backup facilities. the event of a disaster. For serving the above Disaster Re- Today’s IP networks, which are designed to provide covery (DR) purpose, institutions have to invest significantly only “best-effort” service to network-based applications, fre- and address a number of software, storage and networking quently experience performance bottlenecks. The perfor- issues. Although, a great deal of attention is paid towards mance bottlenecks can be due to issues such as lack of ad- software and storage issues, networking issues are gener- equate end-to-end bandwidth provisioning, intermediate net- ally overlooked in DR planning. In this paper, we present work links congestion or device mis-configurations such as a DR pilot study that considered different networking issues duplex mismatches [1] and outdated NIC drivers at DR-client that need to be addressed and managed during DR plan- sites. -

Click to Add Title Click to Add Subtitle (If Applicable) Click to Add
Identifying Command, Control and Communication Networks from Interactions and Activities Observations Georgiy Levchuk, Ph.D., Aptima Inc. Yuri Levchuk, Ph.D., Aptima Inc. CCRTS, 2006 © 2006, Aptima, Inc. 1 Agenda Challenges of tactical operations Proposed integrated solution concept Focus of this research: adversary organization identification Technical approach Results and conclusions © 2006, Aptima, Inc. 2 3 Major Challenges of Tactical Operations Conflicts Trends Technology/Information Trends Adversary’s Trends 70 4500 Past 60 4000 Large-size forces of well-known 3500 50 organizational forms 3000 40 Current 2500 Main telephone lines 30 Small- to moderate-size militia 2000 Mobile cellular forces taking many less #, Millions subscribers 20 1500 Internet users organized forms # of US forces ops forces US # of 10 1000 Future: Adaptive Enemy 0 500 Almost unrestricted ability to 1946-1969 1970-1990 1991-2006 0 connect and coordinate 1992 1998 2004 2010 (est) Years Year Can change size and adapt Past Past structure Slow-time conflict Mainly hard-line communications Numbered engagements Current Internet traffic doubles/year Current 630,000 phone lines installed/week Tactical Planning Issues Asymmetric threats and 50,000 new wireless users/day changing missions 650M SIGINT cables generated High manpower needs (~0.001% to products) Takes long time Future: Increased # of Ops 34M voice mail messages/day High info gaps, complexity, Fast-paced engagements 7.7M e-mails sent/min overload Larger number of and Future: Data Explosion Biases of human decisions higher time criticality Data impossible to analyze manually © 2006, Aptima, Inc. 3 Solution: A System to Aid Battlefield CMDR to Design Effective Counteractions against Tactical Adversary Semi-automated System CMDR & planning staff Battlefield Execute attacks against enemy Gather intel INPUT PRODUCT •comm. -

Multitech Bluetooth Network Access Point Administrator Guide S000619 Rev 1.2 for Use with Model: MT200B2E
MultiTech Bluetooth® Network Access Point Administrator Guide MultiTech Bluetooth Network Access Point Administrator Guide S000619 Rev 1.2 For use with model: MT200B2E Copyright This publication may not be reproduced, in whole or in part, without the specific and express prior written permission signed by an executive officer of Multi-Tech Systems, Inc. All rights reserved. Copyright © 2015 by Multi-Tech Systems, Inc. Multi-Tech Systems, Inc. makes no representations or warranties, whether express, implied or by estoppels, with respect to the content, information, material and recommendations herein and specifically disclaims any implied warranties of merchantability, fitness for any particular purpose and non- infringement. Multi-Tech Systems, Inc. reserves the right to revise this publication and to make changes from time to time in the content hereof without obligation of Multi-Tech Systems, Inc. to notify any person or organization of such revisions or changes. Trademarks MultiTech, MultiConnect, and the MultiTech logo are registered trademarks of Multi-Tech Systems, Inc. Bluetooth is a registered trademark of Bluetooth SIG, Inc. All other brand and product names are trademarks or registered trademarks of their respective companies. Contacting MultiTech Knowledge Base The Knowledge Base provides immediate access to support information and resolutions for all MultiTech products. Visit http://www.multitech.com/kb.go. Support Portal To create an account and submit a support case directly to our technical support team, visit: https://support.multitech.com Support Business Hours: M-F, 9am to 5pm CT Country By Email By Phone Europe, Middle East, Africa: [email protected] +(44) 118 959 7774 U.S., Canada, all others: [email protected] (800) 972-2439 or (763) 717-5863 World Headquarters Multi-Tech Systems, Inc. -

Powerview Command Reference
PowerView Command Reference TRACE32 Online Help TRACE32 Directory TRACE32 Index TRACE32 Documents ...................................................................................................................... PowerView User Interface ............................................................................................................ PowerView Command Reference .............................................................................................1 History ...................................................................................................................................... 12 ABORT ...................................................................................................................................... 13 ABORT Abort driver program 13 AREA ........................................................................................................................................ 14 AREA Message windows 14 AREA.CLEAR Clear area 15 AREA.CLOSE Close output file 15 AREA.Create Create or modify message area 16 AREA.Delete Delete message area 17 AREA.List Display a detailed list off all message areas 18 AREA.OPEN Open output file 20 AREA.PIPE Redirect area to stdout 21 AREA.RESet Reset areas 21 AREA.SAVE Save AREA window contents to file 21 AREA.Select Select area 22 AREA.STDERR Redirect area to stderr 23 AREA.STDOUT Redirect area to stdout 23 AREA.view Display message area in AREA window 24 AutoSTOre .............................................................................................................................. -

Shell Variables
Shell Using the command line Orna Agmon ladypine at vipe.technion.ac.il Haifux Shell – p. 1/55 TOC Various shells Customizing the shell getting help and information Combining simple and useful commands output redirection lists of commands job control environment variables Remote shell textual editors textual clients references Shell – p. 2/55 What is the shell? The shell is the wrapper around the system: a communication means between the user and the system The shell is the manner in which the user can interact with the system through the terminal. The shell is also a script interpreter. The simplest script is a bunch of shell commands. Shell scripts are used in order to boot the system. The user can also write and execute shell scripts. Shell – p. 3/55 Shell - which shell? There are several kinds of shells. For example, bash (Bourne Again Shell), csh, tcsh, zsh, ksh (Korn Shell). The most important shell is bash, since it is available on almost every free Unix system. The Linux system scripts use bash. The default shell for the user is set in the /etc/passwd file. Here is a line out of this file for example: dana:x:500:500:Dana,,,:/home/dana:/bin/bash This line means that user dana uses bash (located on the system at /bin/bash) as her default shell. Shell – p. 4/55 Starting to work in another shell If Dana wishes to temporarily use another shell, she can simply call this shell from the command line: [dana@granada ˜]$ bash dana@granada:˜$ #In bash now dana@granada:˜$ exit [dana@granada ˜]$ bash dana@granada:˜$ #In bash now, going to hit ctrl D dana@granada:˜$ exit [dana@granada ˜]$ #In original shell now Shell – p. -

S.Ha.R.K. Installation Howto Tools Knoppix Live CD Linux Fdisk HD
S.Ha.R.K. Installation Tools HowTo • Linux fdisk utility • A copy of Linux installation CD • A copy of Windows® installation CD Tullio Facchinetti University of Pavia - Italy • Some FreeDOS utilities • A copy of S.Ha.R.K. S.Ha.R.K. Workshop S.Ha.R.K. Workshop Knoppix live CD Linux fdisk Command action a toggle a bootable flag Download ISO from b edit bsd disklabel c toggle the dos compatibility flag d delete a partition http://www.knoppix.org l list known partition types m print this menu n add a new partition o create a new empty DOS partition table p print the partition table q quit without saving changes • boot from CD s create a new empty Sun disklabel t change a partition's system id • open a command shell u change display/entry units v verify the partition table • type “su” (become root ), password is empty w write table to disk and exit x extra functionality (experts only) • start fdisk (ex. fdisk /dev/hda ) Command (m for help): S.Ha.R.K. Workshop S.Ha.R.K. Workshop HD partitioning HD partitioning 1st FreeDOS FAT32 FreeDOS must be installed Primary 2nd Windows® FAT32 into the first partition of your HD or it may not boot 3rd Linux / extX Data 1 FAT32 format data partitions as ... Extended FAT32, so that you can share Data n FAT32 your data between Linux, last Linux swap swap Windows® and FreeDOS S.Ha.R.K. Workshop S.Ha.R.K. Workshop 1 HD partitioning Windows ® installation FAT32 Windows® partition type Install Windows®..