Unicode Cree Syllabics for Windows and Macintosh
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Aborlit Algonquian Eastern Canada 20080411
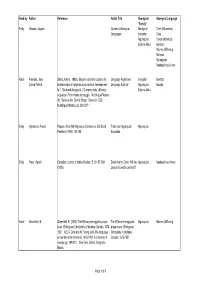
Read by Author Reference Article Title Aboriginal Aboriginal Language "Family" Emily Maurais, Jaques Quebec's Aboriginal Aboriginal Cree (Atikamekw) Languages Iroquoian Cree Algonquian Huron (Wyandot) Eskimo-Aleut Inuktitut Micmac (Mi’kmaq) Mohawk Montagnais Naskapi-Innu-Aimun Karlie Freeland, Jane Stairs, Arlene. 1988a. Beyond cultural inclusion: An Language Rights and Iroquoian Inuktitut Donna Patrick Inuit example of indigenous educational development. Language Survival Algonquian Inupiaq In T. Skutnabb-Kangas & J. Cummins (eds.) Minority Eskimo-Aleut education: From shame to struggle. Multilingual Matters 40. Series editor Derrick Sharp. Clevedon, G.B.: Multilingual Matters, pp. 308-327. Emily Hjartarson, Freida Papers of the 26th Algonquin Conference. Ed. David Traditional Algonquian Algonquian Pentland (1995): 151-168 Education Emily Press, Harold Canadian Journal of Native Studies 15 (2) 187-209 Davis Inlet in Crisis: Will the Algonquian Naskapi-Innu-Aimun (1995) Lessons Ever be Learned? Karlie Greenfield, B. Greenfield, B. (2000) The Mi’kmaq hieroglyphic prayer The Mi’kmaq hieroglyphic Algonquian Micmac (Mi’kmaq) book: Writing and Christianity in Maritime Canada, 1675- prayer book: Writing and 1921. In E.G. Gray and N. Fiering (eds) The language Christianity in Maritime encounter in the Americas, 1492-1800: A collection of Canada, 1675-1921 essays (pp. 189-211). New York, Oxford: Berghahn Books. Page 1 of 9 Majority Relevant Area Specific Area Age Time Period Discipline of Research Type of Language Research French Canada Quebec -

The Unicode Cookbook for Linguists: Managing Writing Systems Using Orthography Profiles
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2017 The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles Moran, Steven ; Cysouw, Michael DOI: https://doi.org/10.5281/zenodo.290662 Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-135400 Monograph The following work is licensed under a Creative Commons: Attribution 4.0 International (CC BY 4.0) License. Originally published at: Moran, Steven; Cysouw, Michael (2017). The Unicode Cookbook for Linguists: Managing writing systems using orthography profiles. CERN Data Centre: Zenodo. DOI: https://doi.org/10.5281/zenodo.290662 The Unicode Cookbook for Linguists Managing writing systems using orthography profiles Steven Moran & Michael Cysouw Change dedication in localmetadata.tex Preface This text is meant as a practical guide for linguists, and programmers, whowork with data in multilingual computational environments. We introduce the basic concepts needed to understand how writing systems and character encodings function, and how they work together. The intersection of the Unicode Standard and the International Phonetic Al- phabet is often not met without frustration by users. Nevertheless, thetwo standards have provided language researchers with a consistent computational architecture needed to process, publish and analyze data from many different languages. We bring to light common, but not always transparent, pitfalls that researchers face when working with Unicode and IPA. Our research uses quantitative methods to compare languages and uncover and clarify their phylogenetic relations. However, the majority of lexical data available from the world’s languages is in author- or document-specific orthogra- phies. -

1996 Matthewson Reinholtz.Pdf
211 TIlE SYNTAX AND SEMANTICS OF DETERMINERS:' (2) OP A COMPARISON OF SALISH AND CREEl /~ Specifier 0' Lisa Matthewson, UBC and SCES/SFU Charlotte Reinholtz, University of Manitoha o/"" NP I ~ the coyote 1. Introduction According to the OP-analysis, the determiner is the head of the phrase and takes NP as its The goal of this paper is to provide a comparative analysis of determiners in Salish languages complement. 0 is a functional head, which selects a lexical projection (NP) as its complement. and in Cree. We will show that there are considerable surface differences between Salish and The lexical/functional split is summarized in (3): Cree, both in the syntax and the semantics of the determiners. However, we argue that these differences can and should be treated as part of a restricted range of cross-linguistic variation (3) If X" E {V, N, P, A}, then X" is a Lexical head (open-class element). within a universally-provided OP (Determiner Phrase)-system. If X" E {Tense, Oet, Comp, Case}, then X" is a Functional head (closed-class element). The paper is structured as follows. We first provide an introduction to relevant theoretical ~haine 1993:2) proposals about the syntax and semantics of determiners. Section 2 presents an analysis of Salish determiners, and section 3 presents an analysis of Cree determiners. The two systems are briefly A major motivation for the OP-analysis of noun phrases comes from the many parallels between compared and contrasted in section 4. clauses and noun phrases. For example, Abney (1987) notes that many languages contain agreement within noun phrases which parallels agreement at the clausal level. -

Unicode and Code Page Support
Natural for Mainframes Unicode and Code Page Support Version 4.2.6 for Mainframes October 2009 This document applies to Natural Version 4.2.6 for Mainframes and to all subsequent releases. Specifications contained herein are subject to change and these changes will be reported in subsequent release notes or new editions. Copyright © Software AG 1979-2009. All rights reserved. The name Software AG, webMethods and all Software AG product names are either trademarks or registered trademarks of Software AG and/or Software AG USA, Inc. Other company and product names mentioned herein may be trademarks of their respective owners. Table of Contents 1 Unicode and Code Page Support .................................................................................... 1 2 Introduction ..................................................................................................................... 3 About Code Pages and Unicode ................................................................................ 4 About Unicode and Code Page Support in Natural .................................................. 5 ICU on Mainframe Platforms ..................................................................................... 6 3 Unicode and Code Page Support in the Natural Programming Language .................... 7 Natural Data Format U for Unicode-Based Data ....................................................... 8 Statements .................................................................................................................. 9 Logical -

The Evolution of Health Status and Health Determinants in the Cree Region (Eeyou Istchee)
The Evolution of Health Status and Health Determinants in the Cree Region (Eeyou Istchee): Eastmain 1-A Powerhouse and Rupert Diversion Sectoral Report Volume 1: Context and Findings Series 4 Number 3: Report on the health status of the population Cree Board of Health and Social Services of James Bay The Evolution of Health Status and Health Determinants in the Cree Region (Eeyou Istchee): Eastmain-1-A Powerhouse and Rupert Diversion Sectoral Report Volume 1 Context and Findings Jill Torrie Ellen Bobet Natalie Kishchuk Andrew Webster Series 4 Number 3: Report on the Health Status of the Population. Public Health Department of the Cree Territory of James Bay Cree Board of Health and Social Services of James Bay The views expressed in this document are those of the authors and do not necessarily reflect those of the Cree Board of Health and Social Services of James Bay. Authors Jill Torrie Cree Board of Health & Social Services of James Bay (Montreal) [email protected] Ellen Bobet Confluence Research and Writing (Gatineau) [email protected] Natalie Kishchuk Programme evaluation and applied social research consultant (Montreal) [email protected] Andrew Webster Analyst in health negotiations, litigation, and administration (Ottawa) [email protected] Series editor & co-ordinator: Jill Torrie, Cree Public Health Department Cover design: Katya Petrov [email protected] Photo credit: Catherine Godin This document can be found online at: www.Creepublichealth.org Reproduction is authorised for non-commercial purposes with acknowledgement of the source. Document deposited on Santécom (http://www. Santecom.qc.ca) Call Number: INSPQ-2005-18-2005-001 Legal deposit – 2nd trimester 2005 Bibliothèque Nationale du Québec National Library of Canada ISSN: 2-550-443779-9 © April 2005. -

CSS 2.1) Specification
Cascading Style Sheets Level 2 Revision 1 (CSS 2.1) Specification W3C Editors Draft 26 February 2014 This version: http://www.w3.org/TR/2014/ED-CSS2-20140226 Latest version: http://www.w3.org/TR/CSS2 Previous versions: http://www.w3.org/TR/2011/REC-CSS2-20110607 http://www.w3.org/TR/2008/REC-CSS2-20080411/ Editors: Bert Bos <bert @w3.org> Tantek Çelik <tantek @cs.stanford.edu> Ian Hickson <ian @hixie.ch> Håkon Wium Lie <howcome @opera.com> Please refer to the errata for this document. This document is also available in these non-normative formats: plain text, gzip'ed tar file, zip file, gzip'ed PostScript, PDF. See also translations. Copyright © 2011 W3C® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. Abstract This specification defines Cascading Style Sheets, level 2 revision 1 (CSS 2.1). CSS 2.1 is a style sheet language that allows authors and users to attach style (e.g., fonts and spacing) to structured documents (e.g., HTML documents and XML applications). By separating the presentation style of documents from the content of documents, CSS 2.1 simplifies Web authoring and site maintenance. CSS 2.1 builds on CSS2 [CSS2] which builds on CSS1 [CSS1]. It supports media- specific style sheets so that authors may tailor the presentation of their documents to visual browsers, aural devices, printers, braille devices, handheld devices, etc. It also supports content positioning, table layout, features for internationalization and some properties related to user interface. CSS 2.1 corrects a few errors in CSS2 (the most important being a new definition of the height/width of absolutely positioned elements, more influence for HTML's "style" attribute and a new calculation of the 'clip' property), and adds a few highly requested features which have already been widely implemented. -

Past Tense, Imperfective Aspect, and Irreality in Cree
143 PAST TENSE, IMPERFECTIVE ASPECT, AND IRREALITY IN CREE Deborah James Scarborough College, University of Toronto In the Cree-Montagnais-Naskapi language complex, and also in at least some other Algonquian languages as well, there are two differ ent types of morphological device for indicating past tense. One of these is the use of a prefix, which in Cree-Montagnais-Naskapi takes the form /ki:/ or /ci:/.1 The other is the use of what are known in the literature as "preterit" suffixes. In the dialect of Moose Factory, Ontario, with which this paper will be primarily concerned, the pre terit suffix takes the form /htay/ when the verb is in the indepen dent indicative and when either the subject or the object of the verb is first or second person, and it take a form characterized basically by the element /pan/ in all other cases.2 It is of interest to ask how, if at all, these two devices for indicating past tense differ from each other in meaning and usage. In this paper, I will examine in detail one dialect, the Mosse Cree dialect, and I will show that there are two major types of difference between the /ki:/ prefix and the pre terit suffix. The first difference involves an aspectual distinction; the second involves the fact that the preterit—but not /ki:/—can be used to indicate things which are not past tense at all, but are instead hypothetical or irreal. And it will be shown that this latter use of the preterit is semantically linked both with its use to indicate past tense and also more specifically with its use to indicate aspect. -

Death and Life for Inuit and Innu
skin for skin Narrating Native Histories Series editors: K. Tsianina Lomawaima Alcida Rita Ramos Florencia E. Mallon Joanne Rappaport Editorial Advisory Board: Denise Y. Arnold Noenoe K. Silva Charles R. Hale David Wilkins Roberta Hill Juan de Dios Yapita Narrating Native Histories aims to foster a rethinking of the ethical, methodological, and conceptual frameworks within which we locate our work on Native histories and cultures. We seek to create a space for effective and ongoing conversations between North and South, Natives and non- Natives, academics and activists, throughout the Americas and the Pacific region. This series encourages analyses that contribute to an understanding of Native peoples’ relationships with nation- states, including histo- ries of expropriation and exclusion as well as projects for autonomy and sovereignty. We encourage collaborative work that recognizes Native intellectuals, cultural inter- preters, and alternative knowledge producers, as well as projects that question the relationship between orality and literacy. skin for skin DEATH AND LIFE FOR INUIT AND INNU GERALD M. SIDER Duke University Press Durham and London 2014 © 2014 Duke University Press All rights reserved Printed in the United States of America on acid- free paper ∞ Designed by Heather Hensley Typeset in Arno Pro by Copperline Book Services, Inc. Library of Congress Cataloging- in- Publication Data Sider, Gerald M. Skin for skin : death and life for Inuit and Innu / Gerald M. Sider. pages cm—(Narrating Native histories) Includes bibliographical references and index. isbn 978- 0- 8223- 5521- 2 (cloth : alk. paper) isbn 978- 0- 8223- 5536- 6 (pbk. : alk. paper) 1. Naskapi Indians—Newfoundland and Labrador—Labrador— Social conditions. -

Jtc1/Sc2/Wg2 N3427 L2/08-132
JTC1/SC2/WG2 N3427 L2/08-132 2008-04-08 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal to encode 39 Unified Canadian Aboriginal Syllabics in the UCS Source: Michael Everson and Chris Harvey Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2008-04-08 1. Summary. This document requests 39 additional characters to be added to the UCS and contains the proposal summary form. 1. Syllabics hyphen (U+1400). Many Aboriginal Canadian languages use the character U+1428 CANADIAN SYLLABICS FINAL SHORT HORIZONTAL STROKE, which looks like the Latin script hyphen. Algonquian languages like western dialects of Cree, Oji-Cree, western and northern dialects of Ojibway employ this character to represent /tʃ/, /c/, or /j/, as in Plains Cree ᐊᓄᐦᐨ /anohc/ ‘today’. In Athabaskan languages, like Chipewyan, the sound is /d/ or an alveolar onset, as in Sayisi Dene ᐨᕦᐣᐨᕤ /t’ąt’ú/ ‘how’. To avoid ambiguity between this character and a line-breaking hyphen, a SYLLABICS HYPHEN was developed which resembles an equals sign. Depending on the typeface, the width of the syllabics hyphen can range from a short ᐀ to a much longer ᐀. This hyphen is line-breaking punctuation, and should not be confused with the Blackfoot syllable internal-w final proposed for U+167F. See Figures 1 and 2. 2. DHW- additions for Woods Cree (U+1677..U+167D). ᙷᙸᙹᙺᙻᙼᙽ/ðwē/ /ðwi/ /ðwī/ /ðwo/ /ðwō/ /ðwa/ /ðwā/. The basic syllable structure in Cree is (C)(w)V(C)(C). -

Typotheque North American Syllabics Proposed Revisions to The
Typotheque Prepared by Kevin King Typotheque [email protected] www.typotheque.com 04/06/21 North American Syllabics Proposed revisions to the representative characters of the Unified Canadian Aboriginal Syllabics code charts Typotheque Proposed representative character revisions of the Unified Canadian Aboriginal Syllabics 2 CONTENTS 1 Summary of proposed character revisions 3 2 Revisions for Carrier 9 3 Revisions for Sayisi 36 4 Revisions for Ojibway 46 Bibliography 52 Acknowledgements 54 Typotheque Proposed representative character revisions of the Unified Canadian Aboriginal Syllabics 3 1 Summary of proposed character revisions The following proposal requests 120 revisions to the representative char- acters in the official code charts of Unified Canadian Aboriginal Syllabics main and extended blocks. The proposed characters for revision have been summarized below with representative glyphs and corresponding character names with annotations where applicable. Additionally, revised code charts for UCAS main and extended has been provided in the following section with the proposed revised representative characters marked in pink, imple- mented into their corresponding code point locations. The author has prepared a style-matched font for the purpose of imple- menting into the code chart: 144B ᑋ CANADIAN SYLLABICS carrier H 160D ᘍ CANADIAN SYLLABICS carrier ma 14D1 ᓑ CANADIAN SYLLABICS carrier NG 160E ᘎ CANADIAN SYLLABICS carrier yu 1506 ᔆ CANADIAN SYLLABICS athapascan s 160F ᘏ CANADIAN SYLLABICS carrier yO 15C0 ᗀ CANADIAN SYLLABICS Sayisi -

Introduction to Unicode
Introduction to Unicode Presented by developerWorks, your source for great tutorials ibm.com/developerWorks Table of Contents If you're viewing this document online, you can click any of the topics below to link directly to that section. 1. Tutorial basics 2 2. Introduction 3 3. Unicode-based multilingual form development 5 4. Going interactive: Adding the Perl CGI script 10 5. Conclusions and resources 13 6. Feedback 15 Introduction to Unicode Page 1 Presented by developerWorks, your source for great tutorials ibm.com/developerWorks Section 1. Tutorial basics Is this tutorial right for you? This tutorial is for anyone who wants to understand the basics of Unicode-based multilingual Web page development. It is an introduction to how multilingual characters, the Unicode encoding standard, XML, and Perl CGI scripts can be integrated to produce a truly multilingual Web page. The tutorial explains the concepts behind this process and lays the groundwork for future development. Navigation Navigating through the tutorial is easy: * Use the Next and Previous buttons to move forward and backward. * Use the Menu button to return to the tutorial menu. * If you'd like to tell us what you think, use the Feedback button. * If you need help with the tutorial, use the Help button. What is required: Hardware and software needed No additional hardware is needed for this tutorial; however, in order to view some of the files online, Unicode fonts must be loaded. See Resources for information on Unicode fonts if you don't already have one loaded. (Note: Many Unicode fonts are still incomplete or in development, so one particular font may not contain every character; however, for the purposes of this tutorial, the Unicode font downloaded by the user will ideally contain all or most of the language characters used in our examples. -

Iso/Iec Jtc1 Sc2 Wg2 N3984
ISO/IEC JTC1 SC2 WG2 N3984 Notes on the naming of some characters proposed in the FCD of ISO/IEC 10646:2012 (3rd ed.) (JTC1/SC2/WG2 N3945, JTC1/SC2 N4168) Karl Pentzlin — 2011-02-02 This paper addresses the naming of the following characters proposed for inclusion: U+2E33 RAISED DOT U+2E34 RAISED COMMA (both proposed in JTC1/SC2/WG2 N3912) U+A78F LATIN LETTER GLOTTAL DOT (proposed in JTC1/SC2/WG2 N3567 as LATIN LETTER MIDDLE DOT) shown by the following excerpts from N3945: 1. Dots, Points, and "middle" and "raised" characters encoded in Unicode 6.0 (without script-specific ones and fullwidth/small forms; of similar characters within a block, a single character is selected as representative): Dots and Points: U+002E FULL STOP U+00B7 MIDDLE DOT U+02D9 DOT ABOVE U+0387 GREEK ANO TELEIA U+2024 ONE DOT LEADER U+2027 HYPHENATION POINT U+22C5 DOT OPERATOR U+2E31 WORD SEPARATOR MIDDLE DOT U+02D9 has the property Sk (Symbol, modifier), U+22C5 has Sm (Symbol, math), while all others have Po (Punctuation, other). U+A78F is proposed to have Lo (Letter, other). "Middle" and "raised" characters: U+02F4 MODIFIER LETTER MIDDLE GRAVE ACCENT U+2E0C LEFT RAISED OMISSION BRACKET (representing several similar characters in the same block) U+02F8 MODIFIER LETTER RAISED COLON U+A71B MODIFIER LETTER RAISED UP ARROW The following table will show these characters using some different widespread fonts. Font 002E 00B7 02D9 0387 2024 2027 22C5 2E31 02F4 2E0C 02F8 A71B Andron Mega Corpus x.E x·E x˙E α·Ε x․E x‧E x⋅E --- x˴E x⸌E x˸E --- Arial x.E x·E x˙E α·Ε x․E x‧E