Forecasting and Predictive Analytics with Forecast X, 7E (Keating) Chapter 2 the Forecast Process, Data Considerations, and Model Selection
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
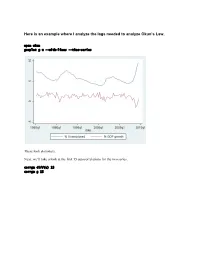
Here Is an Example Where I Analyze the Lags Needed to Analyze Okun's
Here is an example where I analyze the lags needed to analyze Okun’s Law. open okun gnuplot g u --with-lines --time-series These look stationary. Next, we’ll take a look at the first 15 autocorrelations for the two series. corrgm diff(u) 15 corrgm g 15 These are autocorrelated and so are these. I would expect that a simple regression will not be sufficient to model this relationship. Let’s try anyway. Run a simple regression and look at the residuals ols diff(u) const g series ehat=$uhat gnuplot ehat --with-lines --time-series These look positively autocorrelated to me. Notice how the residuals fall below zero for a while, then rise above for a while, and repeat this pattern. Take a look at the correlogram. The first autocorrelation is significant. More lags of D.u or g will probably fix this. LM test of residuals smpl 1985.2 2009.3 ols diff(u) const g modeltab add modtest 1 --autocorr --quiet modtest 2 --autocorr --quiet modtest 3 --autocorr --quiet modtest 4 --autocorr --quiet Breusch-Godfrey test for first-order autocorrelation Alternative statistic: TR^2 = 6.576105, with p-value = P(Chi-square(1) > 6.5761) = 0.0103 Breusch-Godfrey test for autocorrelation up to order 2 Alternative statistic: TR^2 = 7.922218, with p-value = P(Chi-square(2) > 7.92222) = 0.019 Breusch-Godfrey test for autocorrelation up to order 3 Alternative statistic: TR^2 = 11.200978, with p-value = P(Chi-square(3) > 11.201) = 0.0107 Breusch-Godfrey test for autocorrelation up to order 4 Alternative statistic: TR^2 = 11.220956, with p-value = P(Chi-square(4) > 11.221) = 0.0242 Yep, that’s not too good. -

Synthpop: Bespoke Creation of Synthetic Data in R
synthpop: Bespoke Creation of Synthetic Data in R Beata Nowok Gillian M Raab Chris Dibben University of Edinburgh University of Edinburgh University of Edinburgh Abstract In many contexts, confidentiality constraints severely restrict access to unique and valuable microdata. Synthetic data which mimic the original observed data and preserve the relationships between variables but do not contain any disclosive records are one possible solution to this problem. The synthpop package for R, introduced in this paper, provides routines to generate synthetic versions of original data sets. We describe the methodology and its consequences for the data characteristics. We illustrate the package features using a survey data example. Keywords: synthetic data, disclosure control, CART, R, UK Longitudinal Studies. This introduction to the R package synthpop is a slightly amended version of Nowok B, Raab GM, Dibben C (2016). synthpop: Bespoke Creation of Synthetic Data in R. Journal of Statistical Software, 74(11), 1-26. doi:10.18637/jss.v074.i11. URL https://www.jstatsoft. org/article/view/v074i11. 1. Introduction and background 1.1. Synthetic data for disclosure control National statistical agencies and other institutions gather large amounts of information about individuals and organisations. Such data can be used to understand population processes so as to inform policy and planning. The cost of such data can be considerable, both for the collectors and the subjects who provide their data. Because of confidentiality constraints and guarantees issued to data subjects the full access to such data is often restricted to the staff of the collection agencies. Traditionally, data collectors have used anonymisation along with simple perturbation methods such as aggregation, recoding, record-swapping, suppression of sensitive values or adding random noise to prevent the identification of data subjects. -

Bootstrapping Regression Models
Bootstrapping Regression Models Appendix to An R and S-PLUS Companion to Applied Regression John Fox January 2002 1 Basic Ideas Bootstrapping is a general approach to statistical inference based on building a sampling distribution for a statistic by resampling from the data at hand. The term ‘bootstrapping,’ due to Efron (1979), is an allusion to the expression ‘pulling oneself up by one’s bootstraps’ – in this case, using the sample data as a population from which repeated samples are drawn. At first blush, the approach seems circular, but has been shown to be sound. Two S libraries for bootstrapping are associated with extensive treatments of the subject: Efron and Tibshirani’s (1993) bootstrap library, and Davison and Hinkley’s (1997) boot library. Of the two, boot, programmed by A. J. Canty, is somewhat more capable, and will be used for the examples in this appendix. There are several forms of the bootstrap, and, additionally, several other resampling methods that are related to it, such as jackknifing, cross-validation, randomization tests,andpermutation tests. I will stress the nonparametric bootstrap. Suppose that we draw a sample S = {X1,X2, ..., Xn} from a population P = {x1,x2, ..., xN };imagine further, at least for the time being, that N is very much larger than n,andthatS is either a simple random sample or an independent random sample from P;1 I will briefly consider other sampling schemes at the end of the appendix. It will also help initially to think of the elements of the population (and, hence, of the sample) as scalar values, but they could just as easily be vectors (i.e., multivariate). -

A Survey on Data Collection for Machine Learning a Big Data - AI Integration Perspective
1 A Survey on Data Collection for Machine Learning A Big Data - AI Integration Perspective Yuji Roh, Geon Heo, Steven Euijong Whang, Senior Member, IEEE Abstract—Data collection is a major bottleneck in machine learning and an active research topic in multiple communities. There are largely two reasons data collection has recently become a critical issue. First, as machine learning is becoming more widely-used, we are seeing new applications that do not necessarily have enough labeled data. Second, unlike traditional machine learning, deep learning techniques automatically generate features, which saves feature engineering costs, but in return may require larger amounts of labeled data. Interestingly, recent research in data collection comes not only from the machine learning, natural language, and computer vision communities, but also from the data management community due to the importance of handling large amounts of data. In this survey, we perform a comprehensive study of data collection from a data management point of view. Data collection largely consists of data acquisition, data labeling, and improvement of existing data or models. We provide a research landscape of these operations, provide guidelines on which technique to use when, and identify interesting research challenges. The integration of machine learning and data management for data collection is part of a larger trend of Big data and Artificial Intelligence (AI) integration and opens many opportunities for new research. Index Terms—data collection, data acquisition, data labeling, machine learning F 1 INTRODUCTION E are living in exciting times where machine learning expertise. This problem applies to any novel application that W is having a profound influence on a wide range of benefits from machine learning. -

Alternative Tests for Time Series Dependence Based on Autocorrelation Coefficients
Alternative Tests for Time Series Dependence Based on Autocorrelation Coefficients Richard M. Levich and Rosario C. Rizzo * Current Draft: December 1998 Abstract: When autocorrelation is small, existing statistical techniques may not be powerful enough to reject the hypothesis that a series is free of autocorrelation. We propose two new and simple statistical tests (RHO and PHI) based on the unweighted sum of autocorrelation and partial autocorrelation coefficients. We analyze a set of simulated data to show the higher power of RHO and PHI in comparison to conventional tests for autocorrelation, especially in the presence of small but persistent autocorrelation. We show an application of our tests to data on currency futures to demonstrate their practical use. Finally, we indicate how our methodology could be used for a new class of time series models (the Generalized Autoregressive, or GAR models) that take into account the presence of small but persistent autocorrelation. _______________________________________________________________ An earlier version of this paper was presented at the Symposium on Global Integration and Competition, sponsored by the Center for Japan-U.S. Business and Economic Studies, Stern School of Business, New York University, March 27-28, 1997. We thank Paul Samuelson and the other participants at that conference for useful comments. * Stern School of Business, New York University and Research Department, Bank of Italy, respectively. 1 1. Introduction Economic time series are often characterized by positive -

3 Autocorrelation
3 Autocorrelation Autocorrelation refers to the correlation of a time series with its own past and future values. Autocorrelation is also sometimes called “lagged correlation” or “serial correlation”, which refers to the correlation between members of a series of numbers arranged in time. Positive autocorrelation might be considered a specific form of “persistence”, a tendency for a system to remain in the same state from one observation to the next. For example, the likelihood of tomorrow being rainy is greater if today is rainy than if today is dry. Geophysical time series are frequently autocorrelated because of inertia or carryover processes in the physical system. For example, the slowly evolving and moving low pressure systems in the atmosphere might impart persistence to daily rainfall. Or the slow drainage of groundwater reserves might impart correlation to successive annual flows of a river. Or stored photosynthates might impart correlation to successive annual values of tree-ring indices. Autocorrelation complicates the application of statistical tests by reducing the effective sample size. Autocorrelation can also complicate the identification of significant covariance or correlation between time series (e.g., precipitation with a tree-ring series). Autocorrelation implies that a time series is predictable, probabilistically, as future values are correlated with current and past values. Three tools for assessing the autocorrelation of a time series are (1) the time series plot, (2) the lagged scatterplot, and (3) the autocorrelation function. 3.1 Time series plot Positively autocorrelated series are sometimes referred to as persistent because positive departures from the mean tend to be followed by positive depatures from the mean, and negative departures from the mean tend to be followed by negative departures (Figure 3.1). -

A First Step Into the Bootstrap World
INSTITUTE FOR DEFENSE ANALYSES A First Step into the Bootstrap World Matthew Avery May 2016 Approved for public release. IDA Document NS D-5816 Log: H 16-000624 INSTITUTE FOR DEFENSE ANALYSES 4850 Mark Center Drive Alexandria, Virginia 22311-1882 The Institute for Defense Analyses is a non-profit corporation that operates three federally funded research and development centers to provide objective analyses of national security issues, particularly those requiring scientific and technical expertise, and conduct related research on other national challenges. About This Publication This briefing motivates bootstrapping through an intuitive explanation of basic statistical inference, discusses the right way to resample for bootstrapping, and uses examples from operational testing where the bootstrap approach can be applied. Bootstrapping is a powerful and flexible tool when applied appropriately. By treating the observed sample as if it were the population, the sampling distribution of statistics of interest can be generated with precision equal to Monte Carlo error. This approach is nonparametric and requires only acceptance of the observed sample as an estimate for the population. Careful resampling is used to generate the bootstrap distribution. Applications include quantifying uncertainty for availability data, quantifying uncertainty for complex distributions, and using the bootstrap for inference, such as the two-sample t-test. Copyright Notice © 2016 Institute for Defense Analyses 4850 Mark Center Drive, Alexandria, Virginia 22311-1882 -

Notes Mean, Median, Mode & Range
Notes Mean, Median, Mode & Range How Do You Use Mode, Median, Mean, and Range to Describe Data? There are many ways to describe the characteristics of a set of data. The mode, median, and mean are all called measures of central tendency. These measures of central tendency and range are described in the table below. The mode of a set of data Use the mode to show which describes which value occurs value in a set of data occurs most frequently. If two or more most often. For the set numbers occur the same number {1, 1, 2, 3, 5, 6, 10}, of times and occur more often the mode is 1 because it occurs Mode than all the other numbers in the most frequently. set, those numbers are all modes for the data set. If each number in the set occurs the same number of times, the set of data has no mode. The median of a set of data Use the median to show which describes what value is in the number in a set of data is in the middle if the set is ordered from middle when the numbers are greatest to least or from least to listed in order. greatest. If there are an even For the set {1, 1, 2, 3, 5, 6, 10}, number of values, the median is the median is 3 because it is in the average of the two middle the middle when the numbers are Median values. Half of the values are listed in order. greater than the median, and half of the values are less than the median. -

Statistical Tool for Soil Biology : 11. Autocorrelogram and Mantel Test
‘i Pl w f ’* Em J. 1996, (4), i Soil BioZ., 32 195-203 Statistical tool for soil biology. XI. Autocorrelogram and Mantel test Jean-Pierre Rossi Laboratoire d Ecologie des Sols Trofiicaux, ORSTOM/Université Paris 6, 32, uv. Varagnat, 93143 Bondy Cedex, France. E-mail: rossij@[email protected]. fr. Received October 23, 1996; accepted March 24, 1997. Abstract Autocorrelation analysis by Moran’s I and the Geary’s c coefficients is described and illustrated by the analysis of the spatial pattern of the tropical earthworm Clzuniodrilus ziehe (Eudrilidae). Simple and partial Mantel tests are presented and illustrated through the analysis various data sets. The interest of these methods for soil ecology is discussed. Keywords: Autocorrelation, correlogram, Mantel test, geostatistics, spatial distribution, earthworm, plant-parasitic nematode. L’outil statistique en biologie du sol. X.?. Autocorrélogramme et test de Mantel. Résumé L’analyse de l’autocorrélation par les indices I de Moran et c de Geary est décrite et illustrée à travers l’analyse de la distribution spatiale du ver de terre tropical Chuniodi-ibs zielae (Eudrilidae). Les tests simple et partiel de Mantel sont présentés et illustrés à travers l’analyse de jeux de données divers. L’intérêt de ces méthodes en écologie du sol est discuté. Mots-clés : Autocorrélation, corrélogramme, test de Mantel, géostatistiques, distribution spatiale, vers de terre, nématodes phytoparasites. INTRODUCTION the variance that appear to be related by a simple power law. The obvious interest of that method is Spatial heterogeneity is an inherent feature of that samples from various sites can be included in soil faunal communities with significant functional the analysis. -

Applied Time Series Analysis
Applied Time Series Analysis SS 2018 February 12, 2018 Dr. Marcel Dettling Institute for Data Analysis and Process Design Zurich University of Applied Sciences CH-8401 Winterthur Table of Contents 1 INTRODUCTION 1 1.1 PURPOSE 1 1.2 EXAMPLES 2 1.3 GOALS IN TIME SERIES ANALYSIS 8 2 MATHEMATICAL CONCEPTS 11 2.1 DEFINITION OF A TIME SERIES 11 2.2 STATIONARITY 11 2.3 TESTING STATIONARITY 13 3 TIME SERIES IN R 15 3.1 TIME SERIES CLASSES 15 3.2 DATES AND TIMES IN R 17 3.3 DATA IMPORT 21 4 DESCRIPTIVE ANALYSIS 23 4.1 VISUALIZATION 23 4.2 TRANSFORMATIONS 26 4.3 DECOMPOSITION 29 4.4 AUTOCORRELATION 50 4.5 PARTIAL AUTOCORRELATION 66 5 STATIONARY TIME SERIES MODELS 69 5.1 WHITE NOISE 69 5.2 ESTIMATING THE CONDITIONAL MEAN 70 5.3 AUTOREGRESSIVE MODELS 71 5.4 MOVING AVERAGE MODELS 85 5.5 ARMA(P,Q) MODELS 93 6 SARIMA AND GARCH MODELS 99 6.1 ARIMA MODELS 99 6.2 SARIMA MODELS 105 6.3 ARCH/GARCH MODELS 109 7 TIME SERIES REGRESSION 113 7.1 WHAT IS THE PROBLEM? 113 7.2 FINDING CORRELATED ERRORS 117 7.3 COCHRANE‐ORCUTT METHOD 124 7.4 GENERALIZED LEAST SQUARES 125 7.5 MISSING PREDICTOR VARIABLES 131 8 FORECASTING 137 8.1 STATIONARY TIME SERIES 138 8.2 SERIES WITH TREND AND SEASON 145 8.3 EXPONENTIAL SMOOTHING 152 9 MULTIVARIATE TIME SERIES ANALYSIS 161 9.1 PRACTICAL EXAMPLE 161 9.2 CROSS CORRELATION 165 9.3 PREWHITENING 168 9.4 TRANSFER FUNCTION MODELS 170 10 SPECTRAL ANALYSIS 175 10.1 DECOMPOSING IN THE FREQUENCY DOMAIN 175 10.2 THE SPECTRUM 179 10.3 REAL WORLD EXAMPLE 186 11 STATE SPACE MODELS 187 11.1 STATE SPACE FORMULATION 187 11.2 AR PROCESSES WITH MEASUREMENT NOISE 188 11.3 DYNAMIC LINEAR MODELS 191 ATSA 1 Introduction 1 Introduction 1.1 Purpose Time series data, i.e. -

Quantitative Risk Management in R
QUANTITATIVE RISK MANAGEMENT IN R Characteristics of volatile return series Quantitative Risk Management in R Log-returns compared with iid data ● Can financial returns be modeled as independent and identically distributed (iid)? ● Random walk model for log asset prices ● Implies that future price behavior cannot be predicted ● Instructive to compare real returns with iid data ● Real returns o!en show volatility clustering QUANTITATIVE RISK MANAGEMENT IN R Let’s practice! QUANTITATIVE RISK MANAGEMENT IN R Estimating serial correlation Quantitative Risk Management in R Sample autocorrelations ● Sample autocorrelation function (acf) measures correlation between variables separated by lag (k) ● Stationarity is implicitly assumed: ● Expected return constant over time ● Variance of return distribution always the same ● Correlation between returns k apart always the same ● Notation for sample autocorrelation: ⇢ˆ(k) Quantitative Risk Management in R The sample acf plot or correlogram > acf(ftse) Quantitative Risk Management in R The sample acf plot or correlogram > acf(abs(ftse)) QUANTITATIVE RISK MANAGEMENT IN R Let’s practice! QUANTITATIVE RISK MANAGEMENT IN R The Ljung-Box test Quantitative Risk Management in R Testing the iid hypothesis with the Ljung-Box test ● Numerical test calculated from squared sample autocorrelations up to certain lag ● Compared with chi-squared distribution with k degrees of freedom (df) ● Should also be carried out on absolute returns k ⇢ˆ(j)2 X2 = n(n + 2) n j j=1 X − Quantitative Risk Management in R Example of -

Common Data Set 2020-2021 University of Pennsylvania
Common Data Set 2020-2021 University of Pennsylvania Table of Contents A General Information page 3 B Enrollment and Persistence 5 C First Time, First Year Admission 8 D Transfer Admission 14 E Academic Offerings and Policies 16 F Student Life 18 G Annual Expenses 20 H Financial Aid 22 I Instructional Faculty and Class Size 28 J Disciplinary Areas of Degrees Conferred 30 Common Data Set Definitions 32 Common Data Set 2020-21 1 25 Jun 2021 Common Data Set 2020-21 2 25 Jun 2021 A. General Information return to Table of Contents A1 Address Information A1 University of Pennsylvania A1 Mailing Address: 1 College Hall, Room 100 A1 City/State/Zip/Country: Philadelphia, PA 19104-6228 A1 Main Phone Number: 215-898-5000 A1 Home Page Address www.upenn.edu A1 Admissions Phone Number: 215-898-7507 A1 Admissions Office Mailing Address: 1 College Hall A1 City/State/Zip/Country: Philadelphia, PA 19104 A1 Admissions Fax Number: 215-898-9670 A1 Admissions E-mail Address: [email protected] A1 Online application www.admissions.upenn.edu A2 Source of institutional control (Check only one): A2 Public A2 Private (nonprofit) x A2 Proprietary A3 Classify your undergraduate institution: A3 Coeducational college A3 Men's college A3 Women's college A4 Academic year calendar: A4 Semester x A4 Quarter A4 Trimester A4 4-1-4 A4 Continuous A5 Degrees offered by your institution: A5 Certificate x A5 Diploma A5 Associate x A5 Transfer Associate A5 Terminal Associate x A5 Bachelor's x A5 Postbachelor's certificate x A5 Master's x A5 Post-master's certificate x A5 Doctoral degree - research/scholarship x A5 Doctoral degree - professional practice x A5 Doctoral degree - other x A5 Doctoral degree -- other Common Data Set 2020-21 3 25 Jun 2021 Common Data Set 2020-21 4 25 Jun 2021 B.