3 Autocorrelation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
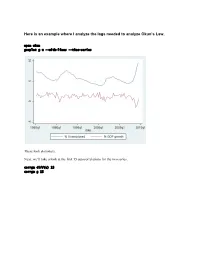
Here Is an Example Where I Analyze the Lags Needed to Analyze Okun's
Here is an example where I analyze the lags needed to analyze Okun’s Law. open okun gnuplot g u --with-lines --time-series These look stationary. Next, we’ll take a look at the first 15 autocorrelations for the two series. corrgm diff(u) 15 corrgm g 15 These are autocorrelated and so are these. I would expect that a simple regression will not be sufficient to model this relationship. Let’s try anyway. Run a simple regression and look at the residuals ols diff(u) const g series ehat=$uhat gnuplot ehat --with-lines --time-series These look positively autocorrelated to me. Notice how the residuals fall below zero for a while, then rise above for a while, and repeat this pattern. Take a look at the correlogram. The first autocorrelation is significant. More lags of D.u or g will probably fix this. LM test of residuals smpl 1985.2 2009.3 ols diff(u) const g modeltab add modtest 1 --autocorr --quiet modtest 2 --autocorr --quiet modtest 3 --autocorr --quiet modtest 4 --autocorr --quiet Breusch-Godfrey test for first-order autocorrelation Alternative statistic: TR^2 = 6.576105, with p-value = P(Chi-square(1) > 6.5761) = 0.0103 Breusch-Godfrey test for autocorrelation up to order 2 Alternative statistic: TR^2 = 7.922218, with p-value = P(Chi-square(2) > 7.92222) = 0.019 Breusch-Godfrey test for autocorrelation up to order 3 Alternative statistic: TR^2 = 11.200978, with p-value = P(Chi-square(3) > 11.201) = 0.0107 Breusch-Godfrey test for autocorrelation up to order 4 Alternative statistic: TR^2 = 11.220956, with p-value = P(Chi-square(4) > 11.221) = 0.0242 Yep, that’s not too good. -

Power Comparisons of Five Most Commonly Used Autocorrelation Tests
Pak.j.stat.oper.res. Vol.16 No. 1 2020 pp119-130 DOI: http://dx.doi.org/10.18187/pjsor.v16i1.2691 Pakistan Journal of Statistics and Operation Research Power Comparisons of Five Most Commonly Used Autocorrelation Tests Stanislaus S. Uyanto School of Economics and Business, Atma Jaya Catholic University of Indonesia, [email protected] Abstract In regression analysis, autocorrelation of the error terms violates the ordinary least squares assumption that the error terms are uncorrelated. The consequence is that the estimates of coefficients and their standard errors will be wrong if the autocorrelation is ignored. There are many tests for autocorrelation, we want to know which test is more powerful. We use Monte Carlo methods to compare the power of five most commonly used tests for autocorrelation, namely Durbin-Watson, Breusch-Godfrey, Box–Pierce, Ljung Box, and Runs tests in two different linear regression models. The results indicate the Durbin-Watson test performs better in the regression model without lagged dependent variable, although the advantage over the other tests reduce with increasing autocorrelation and sample sizes. For the model with lagged dependent variable, the Breusch-Godfrey test is generally superior to the other tests. Key Words: Correlated error terms; Ordinary least squares assumption; Residuals; Regression diagnostic; Lagged dependent variable. Mathematical Subject Classification: 62J05; 62J20. 1. Introduction An important assumption of the classical linear regression model states that there is no autocorrelation in the error terms. Autocorrelation of the error terms violates the ordinary least squares assumption that the error terms are uncorrelated, meaning that the Gauss Markov theorem (Plackett, 1949, 1950; Greene, 2018) does not apply, and that ordinary least squares estimators are no longer the best linear unbiased estimators. -

LECTURES 2 - 3 : Stochastic Processes, Autocorrelation Function
LECTURES 2 - 3 : Stochastic Processes, Autocorrelation function. Stationarity. Important points of Lecture 1: A time series fXtg is a series of observations taken sequentially over time: xt is an observation recorded at a specific time t. Characteristics of times series data: observations are dependent, become available at equally spaced time points and are time-ordered. This is a discrete time series. The purposes of time series analysis are to model and to predict or forecast future values of a series based on the history of that series. 2.2 Some descriptive techniques. (Based on [BD] x1.3 and x1.4) ......................................................................................... Take a step backwards: how do we describe a r.v. or a random vector? ² for a r.v. X: 2 d.f. FX (x) := P (X · x), mean ¹ = EX and variance σ = V ar(X). ² for a r.vector (X1;X2): joint d.f. FX1;X2 (x1; x2) := P (X1 · x1;X2 · x2), marginal d.f.FX1 (x1) := P (X1 · x1) ´ FX1;X2 (x1; 1) 2 2 mean vector (¹1; ¹2) = (EX1; EX2), variances σ1 = V ar(X1); σ2 = V ar(X2), and covariance Cov(X1;X2) = E(X1 ¡ ¹1)(X2 ¡ ¹2) ´ E(X1X2) ¡ ¹1¹2. Often we use correlation = normalized covariance: Cor(X1;X2) = Cov(X1;X2)=fσ1σ2g ......................................................................................... To describe a process X1;X2;::: we define (i) Def. Distribution function: (fi-di) d.f. Ft1:::tn (x1; : : : ; xn) = P (Xt1 · x1;:::;Xtn · xn); i.e. this is the joint d.f. for the vector (Xt1 ;:::;Xtn ). (ii) First- and Second-order moments. ² Mean: ¹X (t) = EXt 2 2 2 2 ² Variance: σX (t) = E(Xt ¡ ¹X (t)) ´ EXt ¡ ¹X (t) 1 ² Autocovariance function: γX (t; s) = Cov(Xt;Xs) = E[(Xt ¡ ¹X (t))(Xs ¡ ¹X (s))] ´ E(XtXs) ¡ ¹X (t)¹X (s) (Note: this is an infinite matrix). -

Alternative Tests for Time Series Dependence Based on Autocorrelation Coefficients
Alternative Tests for Time Series Dependence Based on Autocorrelation Coefficients Richard M. Levich and Rosario C. Rizzo * Current Draft: December 1998 Abstract: When autocorrelation is small, existing statistical techniques may not be powerful enough to reject the hypothesis that a series is free of autocorrelation. We propose two new and simple statistical tests (RHO and PHI) based on the unweighted sum of autocorrelation and partial autocorrelation coefficients. We analyze a set of simulated data to show the higher power of RHO and PHI in comparison to conventional tests for autocorrelation, especially in the presence of small but persistent autocorrelation. We show an application of our tests to data on currency futures to demonstrate their practical use. Finally, we indicate how our methodology could be used for a new class of time series models (the Generalized Autoregressive, or GAR models) that take into account the presence of small but persistent autocorrelation. _______________________________________________________________ An earlier version of this paper was presented at the Symposium on Global Integration and Competition, sponsored by the Center for Japan-U.S. Business and Economic Studies, Stern School of Business, New York University, March 27-28, 1997. We thank Paul Samuelson and the other participants at that conference for useful comments. * Stern School of Business, New York University and Research Department, Bank of Italy, respectively. 1 1. Introduction Economic time series are often characterized by positive -

Spatial Autocorrelation: Covariance and Semivariance Semivariance
Spatial Autocorrelation: Covariance and Semivariancence Lily Housese P eters GEOG 593 November 10, 2009 Quantitative Terrain Descriptorsrs Covariance and Semivariogram areare numericc methods used to describe the character of the terrain (ex. Terrain roughness, irregularity) Terrain character has important implications for: 1. the type of sampling strategy chosen 2. estimating DTM accuracy (after sampling and reconstruction) Spatial Autocorrelationon The First Law of Geography ““ Everything is related to everything else, but near things are moo re related than distant things.” (Waldo Tobler) The value of a variable at one point in space is related to the value of that same variable in a nearby location Ex. Moranan ’s I, Gearyary ’s C, LISA Positive Spatial Autocorrelation (Neighbors are similar) Negative Spatial Autocorrelation (Neighbors are dissimilar) R(d) = correlation coefficient of all the points with horizontal interval (d) Covariance The degree of similarity between pairs of surface points The value of similarity is an indicator of the complexity of the terrain surface Smaller the similarity = more complex the terrain surface V = Variance calculated from all N points Cov (d) = Covariance of all points with horizontal interval d Z i = Height of point i M = average height of all points Z i+d = elevation of the point with an interval of d from i Semivariancee Expresses the degree of relationship between points on a surface Equal to half the variance of the differences between all possible points spaced a constant distance apart -

Modeling and Generating Multivariate Time Series with Arbitrary Marginals Using a Vector Autoregressive Technique
Modeling and Generating Multivariate Time Series with Arbitrary Marginals Using a Vector Autoregressive Technique Bahar Deler Barry L. Nelson Dept. of IE & MS, Northwestern University September 2000 Abstract We present a model for representing stationary multivariate time series with arbitrary mar- ginal distributions and autocorrelation structures and describe how to generate data quickly and accurately to drive computer simulations. The central idea is to transform a Gaussian vector autoregressive process into the desired multivariate time-series input process that we presume as having a VARTA (Vector-Autoregressive-To-Anything) distribution. We manipulate the correlation structure of the Gaussian vector autoregressive process so that we achieve the desired correlation structure for the simulation input process. For the purpose of computational efficiency, we provide a numerical method, which incorporates a numerical-search procedure and a numerical-integration technique, for solving this correlation-matching problem. Keywords: Computer simulation, vector autoregressive process, vector time series, multivariate input mod- eling, numerical integration. 1 1 Introduction Representing the uncertainty or randomness in a simulated system by an input model is one of the challenging problems in the practical application of computer simulation. There are an abundance of examples, from manufacturing to service applications, where input modeling is critical; e.g., modeling the time to failure for a machining process, the demand per unit time for inventory of a product, or the times between arrivals of calls to a call center. Further, building a large- scale discrete-event stochastic simulation model may require the development of a large number of, possibly multivariate, input models. Development of these models is facilitated by accurate and automated (or nearly automated) input modeling support. -

The Bayesian Approach to Statistics
THE BAYESIAN APPROACH TO STATISTICS ANTHONY O’HAGAN INTRODUCTION the true nature of scientific reasoning. The fi- nal section addresses various features of modern By far the most widely taught and used statisti- Bayesian methods that provide some explanation for the rapid increase in their adoption since the cal methods in practice are those of the frequen- 1980s. tist school. The ideas of frequentist inference, as set out in Chapter 5 of this book, rest on the frequency definition of probability (Chapter 2), BAYESIAN INFERENCE and were developed in the first half of the 20th century. This chapter concerns a radically differ- We first present the basic procedures of Bayesian ent approach to statistics, the Bayesian approach, inference. which depends instead on the subjective defini- tion of probability (Chapter 3). In some respects, Bayesian methods are older than frequentist ones, Bayes’s Theorem and the Nature of Learning having been the basis of very early statistical rea- Bayesian inference is a process of learning soning as far back as the 18th century. Bayesian from data. To give substance to this statement, statistics as it is now understood, however, dates we need to identify who is doing the learning and back to the 1950s, with subsequent development what they are learning about. in the second half of the 20th century. Over that time, the Bayesian approach has steadily gained Terms and Notation ground, and is now recognized as a legitimate al- ternative to the frequentist approach. The person doing the learning is an individual This chapter is organized into three sections. -

Statistical Tool for Soil Biology : 11. Autocorrelogram and Mantel Test
‘i Pl w f ’* Em J. 1996, (4), i Soil BioZ., 32 195-203 Statistical tool for soil biology. XI. Autocorrelogram and Mantel test Jean-Pierre Rossi Laboratoire d Ecologie des Sols Trofiicaux, ORSTOM/Université Paris 6, 32, uv. Varagnat, 93143 Bondy Cedex, France. E-mail: rossij@[email protected]. fr. Received October 23, 1996; accepted March 24, 1997. Abstract Autocorrelation analysis by Moran’s I and the Geary’s c coefficients is described and illustrated by the analysis of the spatial pattern of the tropical earthworm Clzuniodrilus ziehe (Eudrilidae). Simple and partial Mantel tests are presented and illustrated through the analysis various data sets. The interest of these methods for soil ecology is discussed. Keywords: Autocorrelation, correlogram, Mantel test, geostatistics, spatial distribution, earthworm, plant-parasitic nematode. L’outil statistique en biologie du sol. X.?. Autocorrélogramme et test de Mantel. Résumé L’analyse de l’autocorrélation par les indices I de Moran et c de Geary est décrite et illustrée à travers l’analyse de la distribution spatiale du ver de terre tropical Chuniodi-ibs zielae (Eudrilidae). Les tests simple et partiel de Mantel sont présentés et illustrés à travers l’analyse de jeux de données divers. L’intérêt de ces méthodes en écologie du sol est discuté. Mots-clés : Autocorrélation, corrélogramme, test de Mantel, géostatistiques, distribution spatiale, vers de terre, nématodes phytoparasites. INTRODUCTION the variance that appear to be related by a simple power law. The obvious interest of that method is Spatial heterogeneity is an inherent feature of that samples from various sites can be included in soil faunal communities with significant functional the analysis. -

Applied Time Series Analysis
Applied Time Series Analysis SS 2018 February 12, 2018 Dr. Marcel Dettling Institute for Data Analysis and Process Design Zurich University of Applied Sciences CH-8401 Winterthur Table of Contents 1 INTRODUCTION 1 1.1 PURPOSE 1 1.2 EXAMPLES 2 1.3 GOALS IN TIME SERIES ANALYSIS 8 2 MATHEMATICAL CONCEPTS 11 2.1 DEFINITION OF A TIME SERIES 11 2.2 STATIONARITY 11 2.3 TESTING STATIONARITY 13 3 TIME SERIES IN R 15 3.1 TIME SERIES CLASSES 15 3.2 DATES AND TIMES IN R 17 3.3 DATA IMPORT 21 4 DESCRIPTIVE ANALYSIS 23 4.1 VISUALIZATION 23 4.2 TRANSFORMATIONS 26 4.3 DECOMPOSITION 29 4.4 AUTOCORRELATION 50 4.5 PARTIAL AUTOCORRELATION 66 5 STATIONARY TIME SERIES MODELS 69 5.1 WHITE NOISE 69 5.2 ESTIMATING THE CONDITIONAL MEAN 70 5.3 AUTOREGRESSIVE MODELS 71 5.4 MOVING AVERAGE MODELS 85 5.5 ARMA(P,Q) MODELS 93 6 SARIMA AND GARCH MODELS 99 6.1 ARIMA MODELS 99 6.2 SARIMA MODELS 105 6.3 ARCH/GARCH MODELS 109 7 TIME SERIES REGRESSION 113 7.1 WHAT IS THE PROBLEM? 113 7.2 FINDING CORRELATED ERRORS 117 7.3 COCHRANE‐ORCUTT METHOD 124 7.4 GENERALIZED LEAST SQUARES 125 7.5 MISSING PREDICTOR VARIABLES 131 8 FORECASTING 137 8.1 STATIONARY TIME SERIES 138 8.2 SERIES WITH TREND AND SEASON 145 8.3 EXPONENTIAL SMOOTHING 152 9 MULTIVARIATE TIME SERIES ANALYSIS 161 9.1 PRACTICAL EXAMPLE 161 9.2 CROSS CORRELATION 165 9.3 PREWHITENING 168 9.4 TRANSFER FUNCTION MODELS 170 10 SPECTRAL ANALYSIS 175 10.1 DECOMPOSING IN THE FREQUENCY DOMAIN 175 10.2 THE SPECTRUM 179 10.3 REAL WORLD EXAMPLE 186 11 STATE SPACE MODELS 187 11.1 STATE SPACE FORMULATION 187 11.2 AR PROCESSES WITH MEASUREMENT NOISE 188 11.3 DYNAMIC LINEAR MODELS 191 ATSA 1 Introduction 1 Introduction 1.1 Purpose Time series data, i.e. -

Quantitative Risk Management in R
QUANTITATIVE RISK MANAGEMENT IN R Characteristics of volatile return series Quantitative Risk Management in R Log-returns compared with iid data ● Can financial returns be modeled as independent and identically distributed (iid)? ● Random walk model for log asset prices ● Implies that future price behavior cannot be predicted ● Instructive to compare real returns with iid data ● Real returns o!en show volatility clustering QUANTITATIVE RISK MANAGEMENT IN R Let’s practice! QUANTITATIVE RISK MANAGEMENT IN R Estimating serial correlation Quantitative Risk Management in R Sample autocorrelations ● Sample autocorrelation function (acf) measures correlation between variables separated by lag (k) ● Stationarity is implicitly assumed: ● Expected return constant over time ● Variance of return distribution always the same ● Correlation between returns k apart always the same ● Notation for sample autocorrelation: ⇢ˆ(k) Quantitative Risk Management in R The sample acf plot or correlogram > acf(ftse) Quantitative Risk Management in R The sample acf plot or correlogram > acf(abs(ftse)) QUANTITATIVE RISK MANAGEMENT IN R Let’s practice! QUANTITATIVE RISK MANAGEMENT IN R The Ljung-Box test Quantitative Risk Management in R Testing the iid hypothesis with the Ljung-Box test ● Numerical test calculated from squared sample autocorrelations up to certain lag ● Compared with chi-squared distribution with k degrees of freedom (df) ● Should also be carried out on absolute returns k ⇢ˆ(j)2 X2 = n(n + 2) n j j=1 X − Quantitative Risk Management in R Example of -

Random Processes
Chapter 6 Random Processes Random Process • A random process is a time-varying function that assigns the outcome of a random experiment to each time instant: X(t). • For a fixed (sample path): a random process is a time varying function, e.g., a signal. – For fixed t: a random process is a random variable. • If one scans all possible outcomes of the underlying random experiment, we shall get an ensemble of signals. • Random Process can be continuous or discrete • Real random process also called stochastic process – Example: Noise source (Noise can often be modeled as a Gaussian random process. An Ensemble of Signals Remember: RV maps Events à Constants RP maps Events à f(t) RP: Discrete and Continuous The set of all possible sample functions {v(t, E i)} is called the ensemble and defines the random process v(t) that describes the noise source. Sample functions of a binary random process. RP Characterization • Random variables x 1 , x 2 , . , x n represent amplitudes of sample functions at t 5 t 1 , t 2 , . , t n . – A random process can, therefore, be viewed as a collection of an infinite number of random variables: RP Characterization – First Order • CDF • PDF • Mean • Mean-Square Statistics of a Random Process RP Characterization – Second Order • The first order does not provide sufficient information as to how rapidly the RP is changing as a function of timeà We use second order estimation RP Characterization – Second Order • The first order does not provide sufficient information as to how rapidly the RP is changing as a function -

On the Use of the Autocorrelation and Covariance Methods for Feedforward Control of Transverse Angle and Position Jitter in Linear Particle Beam Accelerators*
'^C 7 ON THE USE OF THE AUTOCORRELATION AND COVARIANCE METHODS FOR FEEDFORWARD CONTROL OF TRANSVERSE ANGLE AND POSITION JITTER IN LINEAR PARTICLE BEAM ACCELERATORS* Dean S. Ban- Advanced Photon Source, Argonne National Laboratory, 9700 S. Cass Ave., Argonne, IL 60439 ABSTRACT It is desired to design a predictive feedforward transverse jitter control system to control both angle and position jitter m pulsed linear accelerators. Such a system will increase the accuracy and bandwidth of correction over that of currently available feedback correction systems. Intrapulse correction is performed. An offline process actually "learns" the properties of the jitter, and uses these properties to apply correction to the beam. The correction weights calculated offline are downloaded to a real-time analog correction system between macropulses. Jitter data were taken at the Los Alamos National Laboratory (LANL) Ground Test Accelerator (GTA) telescope experiment at Argonne National Laboratory (ANL). The experiment consisted of the LANL telescope connected to the ANL ZGS proton source and linac. A simulation of the correction system using this data was shown to decrease the average rms jitter by a factor of two over that of a comparable standard feedback correction system. The system also improved the correction bandwidth. INTRODUCTION Figure 1 shows the standard setup for a feedforward transverse jitter control system. Note that one pickup #1 and two kickers are needed to correct beam position jitter, while two pickup #l's and one kicker are needed to correct beam trajectory-angle jitter. pickup #1 kicker pickup #2 Beam Fast loop Slow loop Processor Figure 1. Feedforward Transverse Jitter Control System It is assumed that the beam is fast enough to beat the correction signal (through the fast loop) to the kicker.