Applied Time Series Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mathematical Statistics
Mathematical Statistics MAS 713 Chapter 1.2 Previous subchapter 1 What is statistics ? 2 The statistical process 3 Population and samples 4 Random sampling Questions? Mathematical Statistics (MAS713) Ariel Neufeld 2 / 70 This subchapter Descriptive Statistics 1.2.1 Introduction 1.2.2 Types of variables 1.2.3 Graphical representations 1.2.4 Descriptive measures Mathematical Statistics (MAS713) Ariel Neufeld 3 / 70 1.2 Descriptive Statistics 1.2.1 Introduction Introduction As we said, statistics is the art of learning from data However, statistical data, obtained from surveys, experiments, or any series of measurements, are often so numerous that they are virtually useless unless they are condensed ; data should be presented in ways that facilitate their interpretation and subsequent analysis Naturally enough, the aspect of statistics which deals with organising, describing and summarising data is called descriptive statistics Mathematical Statistics (MAS713) Ariel Neufeld 4 / 70 1.2 Descriptive Statistics 1.2.2 Types of variables Types of variables Mathematical Statistics (MAS713) Ariel Neufeld 5 / 70 1.2 Descriptive Statistics 1.2.2 Types of variables Types of variables The range of available descriptive tools for a given data set depends on the type of the considered variable There are essentially two types of variables : 1 categorical (or qualitative) variables : take a value that is one of several possible categories (no numerical meaning) Ex. : gender, hair color, field of study, political affiliation, status, ... 2 numerical (or quantitative) -
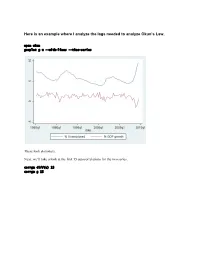
Here Is an Example Where I Analyze the Lags Needed to Analyze Okun's
Here is an example where I analyze the lags needed to analyze Okun’s Law. open okun gnuplot g u --with-lines --time-series These look stationary. Next, we’ll take a look at the first 15 autocorrelations for the two series. corrgm diff(u) 15 corrgm g 15 These are autocorrelated and so are these. I would expect that a simple regression will not be sufficient to model this relationship. Let’s try anyway. Run a simple regression and look at the residuals ols diff(u) const g series ehat=$uhat gnuplot ehat --with-lines --time-series These look positively autocorrelated to me. Notice how the residuals fall below zero for a while, then rise above for a while, and repeat this pattern. Take a look at the correlogram. The first autocorrelation is significant. More lags of D.u or g will probably fix this. LM test of residuals smpl 1985.2 2009.3 ols diff(u) const g modeltab add modtest 1 --autocorr --quiet modtest 2 --autocorr --quiet modtest 3 --autocorr --quiet modtest 4 --autocorr --quiet Breusch-Godfrey test for first-order autocorrelation Alternative statistic: TR^2 = 6.576105, with p-value = P(Chi-square(1) > 6.5761) = 0.0103 Breusch-Godfrey test for autocorrelation up to order 2 Alternative statistic: TR^2 = 7.922218, with p-value = P(Chi-square(2) > 7.92222) = 0.019 Breusch-Godfrey test for autocorrelation up to order 3 Alternative statistic: TR^2 = 11.200978, with p-value = P(Chi-square(3) > 11.201) = 0.0107 Breusch-Godfrey test for autocorrelation up to order 4 Alternative statistic: TR^2 = 11.220956, with p-value = P(Chi-square(4) > 11.221) = 0.0242 Yep, that’s not too good. -

This History of Modern Mathematical Statistics Retraces Their Development
BOOK REVIEWS GORROOCHURN Prakash, 2016, Classic Topics on the History of Modern Mathematical Statistics: From Laplace to More Recent Times, Hoboken, NJ, John Wiley & Sons, Inc., 754 p. This history of modern mathematical statistics retraces their development from the “Laplacean revolution,” as the author so rightly calls it (though the beginnings are to be found in Bayes’ 1763 essay(1)), through the mid-twentieth century and Fisher’s major contribution. Up to the nineteenth century the book covers the same ground as Stigler’s history of statistics(2), though with notable differences (see infra). It then discusses developments through the first half of the twentieth century: Fisher’s synthesis but also the renewal of Bayesian methods, which implied a return to Laplace. Part I offers an in-depth, chronological account of Laplace’s approach to probability, with all the mathematical detail and deductions he drew from it. It begins with his first innovative articles and concludes with his philosophical synthesis showing that all fields of human knowledge are connected to the theory of probabilities. Here Gorrouchurn raises a problem that Stigler does not, that of induction (pp. 102-113), a notion that gives us a better understanding of probability according to Laplace. The term induction has two meanings, the first put forward by Bacon(3) in 1620, the second by Hume(4) in 1748. Gorroochurn discusses only the second. For Bacon, induction meant discovering the principles of a system by studying its properties through observation and experimentation. For Hume, induction was mere enumeration and could not lead to certainty. Laplace followed Bacon: “The surest method which can guide us in the search for truth, consists in rising by induction from phenomena to laws and from laws to forces”(5). -

Alternative Tests for Time Series Dependence Based on Autocorrelation Coefficients
Alternative Tests for Time Series Dependence Based on Autocorrelation Coefficients Richard M. Levich and Rosario C. Rizzo * Current Draft: December 1998 Abstract: When autocorrelation is small, existing statistical techniques may not be powerful enough to reject the hypothesis that a series is free of autocorrelation. We propose two new and simple statistical tests (RHO and PHI) based on the unweighted sum of autocorrelation and partial autocorrelation coefficients. We analyze a set of simulated data to show the higher power of RHO and PHI in comparison to conventional tests for autocorrelation, especially in the presence of small but persistent autocorrelation. We show an application of our tests to data on currency futures to demonstrate their practical use. Finally, we indicate how our methodology could be used for a new class of time series models (the Generalized Autoregressive, or GAR models) that take into account the presence of small but persistent autocorrelation. _______________________________________________________________ An earlier version of this paper was presented at the Symposium on Global Integration and Competition, sponsored by the Center for Japan-U.S. Business and Economic Studies, Stern School of Business, New York University, March 27-28, 1997. We thank Paul Samuelson and the other participants at that conference for useful comments. * Stern School of Business, New York University and Research Department, Bank of Italy, respectively. 1 1. Introduction Economic time series are often characterized by positive -

3 Autocorrelation
3 Autocorrelation Autocorrelation refers to the correlation of a time series with its own past and future values. Autocorrelation is also sometimes called “lagged correlation” or “serial correlation”, which refers to the correlation between members of a series of numbers arranged in time. Positive autocorrelation might be considered a specific form of “persistence”, a tendency for a system to remain in the same state from one observation to the next. For example, the likelihood of tomorrow being rainy is greater if today is rainy than if today is dry. Geophysical time series are frequently autocorrelated because of inertia or carryover processes in the physical system. For example, the slowly evolving and moving low pressure systems in the atmosphere might impart persistence to daily rainfall. Or the slow drainage of groundwater reserves might impart correlation to successive annual flows of a river. Or stored photosynthates might impart correlation to successive annual values of tree-ring indices. Autocorrelation complicates the application of statistical tests by reducing the effective sample size. Autocorrelation can also complicate the identification of significant covariance or correlation between time series (e.g., precipitation with a tree-ring series). Autocorrelation implies that a time series is predictable, probabilistically, as future values are correlated with current and past values. Three tools for assessing the autocorrelation of a time series are (1) the time series plot, (2) the lagged scatterplot, and (3) the autocorrelation function. 3.1 Time series plot Positively autocorrelated series are sometimes referred to as persistent because positive departures from the mean tend to be followed by positive depatures from the mean, and negative departures from the mean tend to be followed by negative departures (Figure 3.1). -

How to Handle Seasonality
q:u:z '9* I ~ ,I ~ \l I I I National Criminal Justice Reference Service 1- --------------~~------------------------------------------------------ li nCJrs This microfiche was produced from documents received for inclusion in the NCJRS data base. Since NCJRS cannot exercise control over the physical condition of the documents submitted, HOW TO SEASONALITY the individual frame quality will vary. The resolution chart on HAN~JE this frame may be used to evaluate the document quality. Introduction to the Detection an~ Ana~y~is of Seasonal Fluctuation ln Crlmlnal Justice Time Series L. May 1983 2 5 0 11111 . IIIII 1. IIIII~ .' . .. .' '.. ,,\ 16 \\\\\~ IIIII 1.4 11111 . MICROCOPY RESOLUTION TEST CHART NATIONAL BUREAU OF STANDARDS-J963-A Microfilming procedures used to create this fiche comply with the standards set forth in 41CFR 101-11.504. 1 .~ Points of view or opinions stated in this document are those of the author(s) and do not represent the official position or policies of the U. S. Department of Justice. 1 , ~!. ~ , National Institute of Justice j United States Department of Justice I, ,I, Washington, D. C. 20531 , .1 I! d ...:.,. 1 ·1;··'1~~;:~ ~~' ~ ; ~ ., 3/30/84 \ , ,;;:'. 1 ... ,'f '\! 1*,,-: ,j '"-=-~-~'- f qq .... 191f' I III I to( ' .. ~J ( ,] (J ,(] ....,.. t ~\ . 1 HOW TO HANDJE SEASONALITY Introduction to the Detection and Analysis of Seasonal Fluctuation in Criminal Justice Time Series _i. May 1983 by Carolyn Rebecca Blocv. Statistical Analysis Center ILLINOIS CRIMINAL JUSTICE INFORMATION AUTHORITY William Gould, Chairman J. David Coldren, Executive Director U.S. DopsrtrMnt of •• u~lIce NatlonaIlattiut. of Juallce II Thi. documont has .os"n reproouood (!)(actty t.\l received from the /1 _on or organl.tation originating II. -

Statistical Tool for Soil Biology : 11. Autocorrelogram and Mantel Test
‘i Pl w f ’* Em J. 1996, (4), i Soil BioZ., 32 195-203 Statistical tool for soil biology. XI. Autocorrelogram and Mantel test Jean-Pierre Rossi Laboratoire d Ecologie des Sols Trofiicaux, ORSTOM/Université Paris 6, 32, uv. Varagnat, 93143 Bondy Cedex, France. E-mail: rossij@[email protected]. fr. Received October 23, 1996; accepted March 24, 1997. Abstract Autocorrelation analysis by Moran’s I and the Geary’s c coefficients is described and illustrated by the analysis of the spatial pattern of the tropical earthworm Clzuniodrilus ziehe (Eudrilidae). Simple and partial Mantel tests are presented and illustrated through the analysis various data sets. The interest of these methods for soil ecology is discussed. Keywords: Autocorrelation, correlogram, Mantel test, geostatistics, spatial distribution, earthworm, plant-parasitic nematode. L’outil statistique en biologie du sol. X.?. Autocorrélogramme et test de Mantel. Résumé L’analyse de l’autocorrélation par les indices I de Moran et c de Geary est décrite et illustrée à travers l’analyse de la distribution spatiale du ver de terre tropical Chuniodi-ibs zielae (Eudrilidae). Les tests simple et partiel de Mantel sont présentés et illustrés à travers l’analyse de jeux de données divers. L’intérêt de ces méthodes en écologie du sol est discuté. Mots-clés : Autocorrélation, corrélogramme, test de Mantel, géostatistiques, distribution spatiale, vers de terre, nématodes phytoparasites. INTRODUCTION the variance that appear to be related by a simple power law. The obvious interest of that method is Spatial heterogeneity is an inherent feature of that samples from various sites can be included in soil faunal communities with significant functional the analysis. -

Quantitative Risk Management in R
QUANTITATIVE RISK MANAGEMENT IN R Characteristics of volatile return series Quantitative Risk Management in R Log-returns compared with iid data ● Can financial returns be modeled as independent and identically distributed (iid)? ● Random walk model for log asset prices ● Implies that future price behavior cannot be predicted ● Instructive to compare real returns with iid data ● Real returns o!en show volatility clustering QUANTITATIVE RISK MANAGEMENT IN R Let’s practice! QUANTITATIVE RISK MANAGEMENT IN R Estimating serial correlation Quantitative Risk Management in R Sample autocorrelations ● Sample autocorrelation function (acf) measures correlation between variables separated by lag (k) ● Stationarity is implicitly assumed: ● Expected return constant over time ● Variance of return distribution always the same ● Correlation between returns k apart always the same ● Notation for sample autocorrelation: ⇢ˆ(k) Quantitative Risk Management in R The sample acf plot or correlogram > acf(ftse) Quantitative Risk Management in R The sample acf plot or correlogram > acf(abs(ftse)) QUANTITATIVE RISK MANAGEMENT IN R Let’s practice! QUANTITATIVE RISK MANAGEMENT IN R The Ljung-Box test Quantitative Risk Management in R Testing the iid hypothesis with the Ljung-Box test ● Numerical test calculated from squared sample autocorrelations up to certain lag ● Compared with chi-squared distribution with k degrees of freedom (df) ● Should also be carried out on absolute returns k ⇢ˆ(j)2 X2 = n(n + 2) n j j=1 X − Quantitative Risk Management in R Example of -

Mathematical Statistics the Sample Distribution of the Median
Course Notes for Math 162: Mathematical Statistics The Sample Distribution of the Median Adam Merberg and Steven J. Miller February 15, 2008 Abstract We begin by introducing the concept of order statistics and ¯nding the density of the rth order statistic of a sample. We then consider the special case of the density of the median and provide some examples. We conclude with some appendices that describe some of the techniques and background used. Contents 1 Order Statistics 1 2 The Sample Distribution of the Median 2 3 Examples and Exercises 4 A The Multinomial Distribution 5 B Big-Oh Notation 6 C Proof That With High Probability jX~ ¡ ¹~j is Small 6 D Stirling's Approximation Formula for n! 7 E Review of the exponential function 7 1 Order Statistics Suppose that the random variables X1;X2;:::;Xn constitute a sample of size n from an in¯nite population with continuous density. Often it will be useful to reorder these random variables from smallest to largest. In reordering the variables, we will also rename them so that Y1 is a random variable whose value is the smallest of the Xi, Y2 is the next smallest, and th so on, with Yn the largest of the Xi. Yr is called the r order statistic of the sample. In considering order statistics, it is naturally convenient to know their probability density. We derive an expression for the distribution of the rth order statistic as in [MM]. Theorem 1.1. For a random sample of size n from an in¯nite population having values x and density f(x), the probability th density of the r order statistic Yr is given by ·Z ¸ ·Z ¸ n! yr r¡1 1 n¡r gr(yr) = f(x) dx f(yr) f(x) dx : (1.1) (r ¡ 1)!(n ¡ r)! ¡1 yr Proof. -

Autocorrelation and Seasonality Otexts.Com/Fpp/2/ Otexts.Com/Fpp/6/1
Rob J Hyndman Forecasting using 3. Autocorrelation and seasonality OTexts.com/fpp/2/ OTexts.com/fpp/6/1 Forecasting using R 1 Outline 1 Time series graphics 2 Seasonal or cyclic? 3 Autocorrelation Forecasting using R Time series graphics 2 Time series graphics Time plots R command: plot or plot.ts Seasonal plots R command: seasonplot Seasonal subseries plots R command: monthplot Lag plots R command: lag.plot ACF plots R command: Acf Forecasting using R Time series graphics 3 Time series graphics Economy class passengers: Melbourne−Sydney plot(melsyd[,"Economy.Class"]) 30 25 20 15 Thousands 10 5 0 1988 1989 1990 1991 1992 1993 Year Forecasting using R Time series graphics 4 Time series graphics Antidiabetic drug sales 30 > plot(a10) 25 20 15 $ million 10 5 1995 2000 2005 Year Forecasting using R Time series graphics 5 Time series graphics Seasonal plot: antidiabetic drug sales 30 2008 ● 2007 ● ● 2007 ● 25 ● ● 2006 ● ● ● ● ● ● 2006 ● ● ● ● 2005 ● ● ● ● 2005 20 ● ● ● ● 2004 ● ● 2004 ● ● ● ● ● ● ● ● ● 2003 ● ● ● ● ● ● 2003 2002 ● ● ● ● ● ● $ million ● 2002 15 ● ● 2001 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 2001 2000 ● ● ● ● ● ● ● 2000 ● ● ● 1999 ● ● ● ● ● ● ● ● ● ● 1998 1999 ● ● ● ● ● ● ● 1997 10 ● ● ● ● ● ● ● ● ● ● ● 1998 ● ● 1996 19961997 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 19931995 ● ● ● ● ● 19941995 ● ● ● ● ● ● ● ● ● ● ● ● 1993 ● ● ● 1994 ● ● ● ● ● ● ● 1992 ● ● ● ● ● ● ● ● ● 5 1992 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1991 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec Year Forecasting using R Time series graphics 6 Seasonal plots Data plotted against the individual “seasons” in which the data were observed. (In this case a “season” is a month.) Something like a time plot except that the data from each season are overlapped. Enables the underlying seasonal pattern to be seen more clearly, and also allows any substantial departures from the seasonal pattern to be easily identified. -

Nonparametric Multivariate Kurtosis and Tailweight Measures
Nonparametric Multivariate Kurtosis and Tailweight Measures Jin Wang1 Northern Arizona University and Robert Serfling2 University of Texas at Dallas November 2004 – final preprint version, to appear in Journal of Nonparametric Statistics, 2005 1Department of Mathematics and Statistics, Northern Arizona University, Flagstaff, Arizona 86011-5717, USA. Email: [email protected]. 2Department of Mathematical Sciences, University of Texas at Dallas, Richardson, Texas 75083- 0688, USA. Email: [email protected]. Website: www.utdallas.edu/∼serfling. Support by NSF Grant DMS-0103698 is gratefully acknowledged. Abstract For nonparametric exploration or description of a distribution, the treatment of location, spread, symmetry and skewness is followed by characterization of kurtosis. Classical moment- based kurtosis measures the dispersion of a distribution about its “shoulders”. Here we con- sider quantile-based kurtosis measures. These are robust, are defined more widely, and dis- criminate better among shapes. A univariate quantile-based kurtosis measure of Groeneveld and Meeden (1984) is extended to the multivariate case by representing it as a transform of a dispersion functional. A family of such kurtosis measures defined for a given distribution and taken together comprises a real-valued “kurtosis functional”, which has intuitive appeal as a convenient two-dimensional curve for description of the kurtosis of the distribution. Several multivariate distributions in any dimension may thus be compared with respect to their kurtosis in a single two-dimensional plot. Important properties of the new multivariate kurtosis measures are established. For example, for elliptically symmetric distributions, this measure determines the distribution within affine equivalence. Related tailweight measures, influence curves, and asymptotic behavior of sample versions are also discussed. -

Chapter 5: Spatial Autocorrelation Statistics
Chapter 5: Spatial Autocorrelation Statistics Ned Levine1 Ned Levine & Associates Houston, TX 1 The author would like to thank Dr. David Wong for help with the Getis-Ord >G= and local Getis-Ord statistics. Table of Contents Spatial Autocorrelation 5.1 Spatial Autocorrelation Statistics for Zonal Data 5.3 Indices of Spatial Autocorrelation 5.3 Assigning Point Data to Zones 5.3 Spatial Autocorrelation Statistics for Attribute Data 5.5 Moran=s “I” Statistic 5.5 Adjust for Small Distances 5.6 Testing the Significance of Moran’s “I” 5.7 Example: Testing Houston Burglaries with Moran’s “I” 5.8 Comparing Moran’s “I” for Two Distributions 5.10 Geary=s “C” Statistic 5.10 Adjusted “C” 5.13 Adjust for Small Distances 5.13 Testing the Significance of Geary’s “C” 5.14 Example: Testing Houston Burglaries with Geary’s “C” 5.14 Getis-Ord “G” Statistic 5.16 Testing the Significance of “G” 5.18 Simulating Confidence Intervals for “G” 5.20 Example: Testing Simulated Data with the Getis-Ord AG@ 5.20 Example: Testing Houston Burglaries with the Getis-Ord AG@ 5.25 Use and Limitations of the Getis-Ord AG@ 5.25 Moran Correlogram 5.26 Adjust for Small Distances 5.27 Simulation of Confidence Intervals 5.27 Example: Moran Correlogram of Baltimore County Vehicle Theft and Population 5.27 Uses and Limitations of the Moran Correlogram 5.30 Geary Correlogram 5.34 Adjust for Small Distances 5.34 Geary Correlogram Simulation of Confidence Intervals 5.34 Example: Geary Correlogram of Baltimore County Vehicle Thefts 5.34 Uses and Limitations of the Geary Correlogram 5.35 Table of Contents (continued) Getis-Ord Correlogram 5.35 Getis-Ord Simulation of Confidence Intervals 5.37 Example: Getis-Ord Correlogram of Baltimore County Vehicle Thefts 5.37 Uses and Limitations of the Getis-Ord Correlogram 5.39 Running the Spatial Autocorrelation Routines 5.39 Guidelines for Examining Spatial Autocorrelation 5.39 References 5.42 Attachments 5.44 A.