Correlation and Regression Analysis
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
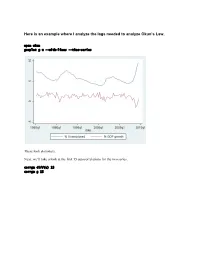
Here Is an Example Where I Analyze the Lags Needed to Analyze Okun's
Here is an example where I analyze the lags needed to analyze Okun’s Law. open okun gnuplot g u --with-lines --time-series These look stationary. Next, we’ll take a look at the first 15 autocorrelations for the two series. corrgm diff(u) 15 corrgm g 15 These are autocorrelated and so are these. I would expect that a simple regression will not be sufficient to model this relationship. Let’s try anyway. Run a simple regression and look at the residuals ols diff(u) const g series ehat=$uhat gnuplot ehat --with-lines --time-series These look positively autocorrelated to me. Notice how the residuals fall below zero for a while, then rise above for a while, and repeat this pattern. Take a look at the correlogram. The first autocorrelation is significant. More lags of D.u or g will probably fix this. LM test of residuals smpl 1985.2 2009.3 ols diff(u) const g modeltab add modtest 1 --autocorr --quiet modtest 2 --autocorr --quiet modtest 3 --autocorr --quiet modtest 4 --autocorr --quiet Breusch-Godfrey test for first-order autocorrelation Alternative statistic: TR^2 = 6.576105, with p-value = P(Chi-square(1) > 6.5761) = 0.0103 Breusch-Godfrey test for autocorrelation up to order 2 Alternative statistic: TR^2 = 7.922218, with p-value = P(Chi-square(2) > 7.92222) = 0.019 Breusch-Godfrey test for autocorrelation up to order 3 Alternative statistic: TR^2 = 11.200978, with p-value = P(Chi-square(3) > 11.201) = 0.0107 Breusch-Godfrey test for autocorrelation up to order 4 Alternative statistic: TR^2 = 11.220956, with p-value = P(Chi-square(4) > 11.221) = 0.0242 Yep, that’s not too good. -

T-TEST Outline Hypothesis Testing Steps Bivariate Analysis
Bivariate Analysis T-TEST Variable 1 2 LEVELS >2 LEVELS CONTINUOUS Variable 2 2 LEVELS X2 X2 t-test chi square test chi square test >2 LEVELS X2 X2 ANOVA chi square test chi square test (F-test) CONTINUOUS t-test ANOVA -Correlation (F-test) -Simple linear Regression Outline Comparison of means: t-test Hypothesis testing steps T-test is used when one variable is of a continuous nature and the other is dichotomous. T-test The t-test is used to compare the means of two groups on a given variable. Anova Examples: Difference in average blood pressure among males & females. Difference in average BMI among those who exercise and those who do not. Hypothesis testing steps Comparison of means: t-test Example 1: Identify the study objective Research question: Among university students, is there a State the null & alternative hypothesis difference between the average weight for males versus females? Select the proper test statistic Null hypothesis (Ho): μ weight males = μ weight females Calculate the test statistic Alternative hypothesis (Ha): μ weight males ≠ μ weight females Take a statistical decision based on the p-value. Statistical test: t-test Reject or accept the null hypothesis Comparison of means: t-test Comparison of means: t-test T-Test (SPSS output) If this p-value is < 0.05 then reject null hypothesis and conclude that the variances are different (accept alternative) Group Statistics and hence check this p-value for the t-test. Std. Error gender N Mean Std. Deviation Mean weight male 804 75.92 12.843 .453 If this p-value is > 0.05 then accept null hypothesis and female 1135 56.47 8.923 .265 conclude that the variances are equal and hence check this p-value for the t-test. -

A Simple Censored Median Regression Estimator
Statistica Sinica 16(2006), 1043-1058 A SIMPLE CENSORED MEDIAN REGRESSION ESTIMATOR Lingzhi Zhou The Hong Kong University of Science and Technology Abstract: Ying, Jung and Wei (1995) proposed an estimation procedure for the censored median regression model that regresses the median of the survival time, or its transform, on the covariates. The procedure requires solving complicated nonlinear equations and thus can be very difficult to implement in practice, es- pecially when there are multiple covariates. Moreover, the asymptotic covariance matrix of the estimator involves the density of the errors that cannot be esti- mated reliably. In this paper, we propose a new estimator for the censored median regression model. Our estimation procedure involves solving some convex min- imization problems and can be easily implemented through linear programming (Koenker and D'Orey (1987)). In addition, a resampling method is presented for estimating the covariance matrix of the new estimator. Numerical studies indi- cate the superiority of the finite sample performance of our estimator over that in Ying, Jung and Wei (1995). Key words and phrases: Censoring, convexity, LAD, resampling. 1. Introduction The accelerated failure time (AFT) model, which relates the logarithm of the survival time to covariates, is an attractive alternative to the popular Cox (1972) proportional hazards model due to its ease of interpretation. The model assumes that the failure time T , or some monotonic transformation of it, is linearly related to the covariate vector Z 0 Ti = β0Zi + "i; i = 1; : : : ; n: (1.1) Under censoring, we only observe Yi = min(Ti; Ci), where Ci are censoring times, and Ti and Ci are independent conditional on Zi. -

Cluster Analysis, a Powerful Tool for Data Analysis in Education
International Statistical Institute, 56th Session, 2007: Rita Vasconcelos, Mßrcia Baptista Cluster Analysis, a powerful tool for data analysis in Education Vasconcelos, Rita Universidade da Madeira, Department of Mathematics and Engeneering Caminho da Penteada 9000-390 Funchal, Portugal E-mail: [email protected] Baptista, Márcia Direcção Regional de Saúde Pública Rua das Pretas 9000 Funchal, Portugal E-mail: [email protected] 1. Introduction A database was created after an inquiry to 14-15 - year old students, which was developed with the purpose of identifying the factors that could socially and pedagogically frame the results in Mathematics. The data was collected in eight schools in Funchal (Madeira Island), and we performed a Cluster Analysis as a first multivariate statistical approach to this database. We also developed a logistic regression analysis, as the study was carried out as a contribution to explain the success/failure in Mathematics. As a final step, the responses of both statistical analysis were studied. 2. Cluster Analysis approach The questions that arise when we try to frame socially and pedagogically the results in Mathematics of 14-15 - year old students, are concerned with the types of decisive factors in those results. It is somehow underlying our objectives to classify the students according to the factors understood by us as being decisive in students’ results. This is exactly the aim of Cluster Analysis. The hierarchical solution that can be observed in the dendogram presented in the next page, suggests that we should consider the 3 following clusters, since the distances increase substantially after it: Variables in Cluster1: mother qualifications; father qualifications; student’s results in Mathematics as classified by the school teacher; student’s results in the exam of Mathematics; time spent studying. -

Alternative Tests for Time Series Dependence Based on Autocorrelation Coefficients
Alternative Tests for Time Series Dependence Based on Autocorrelation Coefficients Richard M. Levich and Rosario C. Rizzo * Current Draft: December 1998 Abstract: When autocorrelation is small, existing statistical techniques may not be powerful enough to reject the hypothesis that a series is free of autocorrelation. We propose two new and simple statistical tests (RHO and PHI) based on the unweighted sum of autocorrelation and partial autocorrelation coefficients. We analyze a set of simulated data to show the higher power of RHO and PHI in comparison to conventional tests for autocorrelation, especially in the presence of small but persistent autocorrelation. We show an application of our tests to data on currency futures to demonstrate their practical use. Finally, we indicate how our methodology could be used for a new class of time series models (the Generalized Autoregressive, or GAR models) that take into account the presence of small but persistent autocorrelation. _______________________________________________________________ An earlier version of this paper was presented at the Symposium on Global Integration and Competition, sponsored by the Center for Japan-U.S. Business and Economic Studies, Stern School of Business, New York University, March 27-28, 1997. We thank Paul Samuelson and the other participants at that conference for useful comments. * Stern School of Business, New York University and Research Department, Bank of Italy, respectively. 1 1. Introduction Economic time series are often characterized by positive -

Chapter Five Multivariate Statistics
Chapter Five Multivariate Statistics Jorge Luis Romeu IIT Research Institute Rome, NY 13440 April 23, 1999 Introduction In this chapter we treat the multivariate analysis problem, which occurs when there is more than one piece of information from each subject, and present and discuss several materials analysis real data sets. We first discuss several statistical procedures for the bivariate case: contingency tables, covariance, correlation and linear regression. They occur when both variables are either qualitative or quantitative: Then, we discuss the case when one variable is qualitative and the other quantitative, via the one way ANOVA. We then overview the general multivariate regression problem. Finally, the non-parametric case for comparison of several groups is discussed. We emphasize the assessment of all model assumptions, prior to model acceptance and use and we present some methods of detection and correction of several types of assumption violation problems. The Case of Bivariate Data Up to now, we have dealt with data sets where each observation consists of a single measurement (e.g. each observation consists of a tensile strength measurement). These are called univariate observations and the related statistical problem is known as univariate analysis. In many cases, however, each observation yields more than one piece of information (e.g. tensile strength, material thickness, surface damage). These are called multivariate observations and the statistical problem is now called multivariate analysis. Multivariate analysis is of great importance and can help us enhance our data analysis in several ways. For, coming from the same subject, multivariate measurements are often associated with each other. If we are able to model this association then we can take advantage of the situation to obtain one from the other. -

The Detection of Heteroscedasticity in Regression Models for Psychological Data
Psychological Test and Assessment Modeling, Volume 58, 2016 (4), 567-592 The detection of heteroscedasticity in regression models for psychological data Andreas G. Klein1, Carla Gerhard2, Rebecca D. Büchner2, Stefan Diestel3 & Karin Schermelleh-Engel2 Abstract One assumption of multiple regression analysis is homoscedasticity of errors. Heteroscedasticity, as often found in psychological or behavioral data, may result from misspecification due to overlooked nonlinear predictor terms or to unobserved predictors not included in the model. Although methods exist to test for heteroscedasticity, they require a parametric model for specifying the structure of heteroscedasticity. The aim of this article is to propose a simple measure of heteroscedasticity, which does not need a parametric model and is able to detect omitted nonlinear terms. This measure utilizes the dispersion of the squared regression residuals. Simulation studies show that the measure performs satisfactorily with regard to Type I error rates and power when sample size and effect size are large enough. It outperforms the Breusch-Pagan test when a nonlinear term is omitted in the analysis model. We also demonstrate the performance of the measure using a data set from industrial psychology. Keywords: Heteroscedasticity, Monte Carlo study, regression, interaction effect, quadratic effect 1Correspondence concerning this article should be addressed to: Prof. Dr. Andreas G. Klein, Department of Psychology, Goethe University Frankfurt, Theodor-W.-Adorno-Platz 6, 60629 Frankfurt; email: [email protected] 2Goethe University Frankfurt 3International School of Management Dortmund Leipniz-Research Centre for Working Environment and Human Factors 568 A. G. Klein, C. Gerhard, R. D. Büchner, S. Diestel & K. Schermelleh-Engel Introduction One of the standard assumptions underlying a linear model is that the errors are inde- pendently identically distributed (i.i.d.). -

Krishnan Correlation CUSB.Pdf
SELF INSTRUCTIONAL STUDY MATERIAL PROGRAMME: M.A. DEVELOPMENT STUDIES COURSE: STATISTICAL METHODS FOR DEVELOPMENT RESEARCH (MADVS2005C04) UNIT III-PART A CORRELATION PROF.(Dr). KRISHNAN CHALIL 25, APRIL 2020 1 U N I T – 3 :C O R R E L A T I O N After reading this material, the learners are expected to : . Understand the meaning of correlation and regression . Learn the different types of correlation . Understand various measures of correlation., and, . Explain the regression line and equation 3.1. Introduction By now we have a clear idea about the behavior of single variables using different measures of Central tendency and dispersion. Here the data concerned with one variable is called ‗univariate data‘ and this type of analysis is called ‗univariate analysis‘. But, in nature, some variables are related. For example, there exists some relationships between height of father and height of son, price of a commodity and amount demanded, the yield of a plant and manure added, cost of living and wages etc. This is a a case of ‗bivariate data‘ and such analysis is called as ‗bivariate data analysis. Correlation is one type of bivariate statistics. Correlation is the relationship between two variables in which the changes in the values of one variable are followed by changes in the values of the other variable. 3.2. Some Definitions 1. ―When the relationship is of a quantitative nature, the approximate statistical tool for discovering and measuring the relationship and expressing it in a brief formula is known as correlation‖—(Craxton and Cowden) 2. ‗correlation is an analysis of the co-variation between two or more variables‖—(A.M Tuttle) 3. -

3 Autocorrelation
3 Autocorrelation Autocorrelation refers to the correlation of a time series with its own past and future values. Autocorrelation is also sometimes called “lagged correlation” or “serial correlation”, which refers to the correlation between members of a series of numbers arranged in time. Positive autocorrelation might be considered a specific form of “persistence”, a tendency for a system to remain in the same state from one observation to the next. For example, the likelihood of tomorrow being rainy is greater if today is rainy than if today is dry. Geophysical time series are frequently autocorrelated because of inertia or carryover processes in the physical system. For example, the slowly evolving and moving low pressure systems in the atmosphere might impart persistence to daily rainfall. Or the slow drainage of groundwater reserves might impart correlation to successive annual flows of a river. Or stored photosynthates might impart correlation to successive annual values of tree-ring indices. Autocorrelation complicates the application of statistical tests by reducing the effective sample size. Autocorrelation can also complicate the identification of significant covariance or correlation between time series (e.g., precipitation with a tree-ring series). Autocorrelation implies that a time series is predictable, probabilistically, as future values are correlated with current and past values. Three tools for assessing the autocorrelation of a time series are (1) the time series plot, (2) the lagged scatterplot, and (3) the autocorrelation function. 3.1 Time series plot Positively autocorrelated series are sometimes referred to as persistent because positive departures from the mean tend to be followed by positive depatures from the mean, and negative departures from the mean tend to be followed by negative departures (Figure 3.1). -

Testing Hypotheses for Differences Between Linear Regression Lines
United States Department of Testing Hypotheses for Differences Agriculture Between Linear Regression Lines Forest Service Stanley J. Zarnoch Southern Research Station e-Research Note SRS–17 May 2009 Abstract The general linear model (GLM) is often used to test for differences between means, as for example when the Five hypotheses are identified for testing differences between simple linear analysis of variance is used in data analysis for designed regression lines. The distinctions between these hypotheses are based on a priori assumptions and illustrated with full and reduced models. The studies. However, the GLM has a much wider application contrast approach is presented as an easy and complete method for testing and can also be used to compare regression lines. The for overall differences between the regressions and for making pairwise GLM allows for the use of both qualitative and quantitative comparisons. Use of the Bonferroni adjustment to ensure a desired predictor variables. Quantitative variables are continuous experimentwise type I error rate is emphasized. SAS software is used to illustrate application of these concepts to an artificial simulated dataset. The values such as diameter at breast height, tree height, SAS code is provided for each of the five hypotheses and for the contrasts age, or temperature. However, many predictor variables for the general test and all possible specific tests. in the natural resources field are qualitative. Examples of qualitative variables include tree class (dominant, Keywords: Contrasts, dummy variables, F-test, intercept, SAS, slope, test of conditional error. codominant); species (loblolly, slash, longleaf); and cover type (clearcut, shelterwood, seed tree). Fraedrich and others (1994) compared linear regressions of slash pine cone specific gravity and moisture content Introduction on collection date between families of slash pine grown in a seed orchard. -

ED441031.Pdf
DOCUMENT RESUME ED 441 031 TM 030 830 AUTHOR Fahoome, Gail; Sawilowsky, Shlomo S. TITLE Review of Twenty Nonparametric Statistics and Their Large Sample Approximations. PUB DATE 2000-04-00 NOTE 42p.; Paper presented at the Annual Meeting of the American Educational Research Association (New Orleans, LA, April 24-28, 2000). PUB TYPE Information Analyses (070)-- Numerical/Quantitative Data (110) Speeches/Meeting Papers (150) EDRS PRICE MF01/PCO2 Plus Postage. DESCRIPTORS Monte Carlo Methods; *Nonparametric Statistics; *Sample Size; *Statistical Distributions ABSTRACT Nonparametric procedures are often more powerful than classical tests for real world data, which are rarely normally distributed. However, there are difficulties in using these tests. Computational formulas are scattered tnrous-hout the literature, and there is a lack of avalialalicy of tables of critical values. This paper brings together the computational formulas for 20 commonly used nonparametric tests that have large-sample approximations for the critical value. Because there is no generally agreed upon lower limit for the sample size, Monte Carlo methods have been used to determine the smallest sample size that can be used with the large-sample approximations. The statistics reviewed include single-population tests, comparisons of two populations, comparisons of several populations, and tests of association. (Contains 4 tables and 59 references.)(Author/SLD) Reproductions supplied by EDRS are the best that can be made from the original document. Review of Twenty Nonparametric Statistics and Their Large Sample Approximations Gail Fahoome Shlomo S. Sawilowsky U.S. DEPARTMENT OF EDUCATION Mice of Educational Research and Improvement PERMISSION TO REPRODUCE AND UCATIONAL RESOURCES INFORMATION DISSEMINATE THIS MATERIAL HAS f BEEN GRANTED BY CENTER (ERIC) This document has been reproduced as received from the person or organization originating it. -

Detecting Trends Using Spearman's Rank Correlation Coefficient
Environmental Forensics 2001) 2, 359±362 doi:10.1006/enfo.2001.0061, available online at http://www.idealibrary.com on Detecting Trends Using Spearman's Rank Correlation Coecient Thomas D. Gauthier Sciences International Inc, 6150 State Road 70, East Bradenton, FL 34203, U.S.A. Received 23 August 2001, Revised manuscript accepted 1 October 2001) Spearman's rank correlation coecient is a useful tool for exploratory data analysis in environmental forensic investigations. In this application it is used to detect monotonic trends in chemical concentration with time or space. # 2001 AEHS Keywords: Spearman rank correlation coecient; trend analysis; soil; groundwater. Environmental forensic investigations can involve a The idea behind the rank correlation coecient is variety of statistical analysis techniques. A relatively simple. Each variable is ranked separately from lowest simple technique that can be used for exploratory data to highest e.g. 1, 2, 3, etc.) and the dierence between analysis is the Spearman rank correlation coecient. In ranks for each data pair is recorded. If the data are this technical note, I describe howthe Spearman rank correlated, then the sum of the square of the dierence correlation coecient can be used as a statistical tool between ranks will be small. The magnitude of the sum to detect monotonic trends in chemical concentrations is related to the signi®cance of the correlation. with time or space. The Spearman rank correlation coecient is calcu- Trend analysis can be useful for detecting chemical lated according to the following equation: ``footprints'' at a site or evaluating the eectiveness of Pn an installed or natural attenuation remedy.