Reference Manual
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
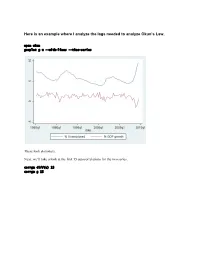
Here Is an Example Where I Analyze the Lags Needed to Analyze Okun's
Here is an example where I analyze the lags needed to analyze Okun’s Law. open okun gnuplot g u --with-lines --time-series These look stationary. Next, we’ll take a look at the first 15 autocorrelations for the two series. corrgm diff(u) 15 corrgm g 15 These are autocorrelated and so are these. I would expect that a simple regression will not be sufficient to model this relationship. Let’s try anyway. Run a simple regression and look at the residuals ols diff(u) const g series ehat=$uhat gnuplot ehat --with-lines --time-series These look positively autocorrelated to me. Notice how the residuals fall below zero for a while, then rise above for a while, and repeat this pattern. Take a look at the correlogram. The first autocorrelation is significant. More lags of D.u or g will probably fix this. LM test of residuals smpl 1985.2 2009.3 ols diff(u) const g modeltab add modtest 1 --autocorr --quiet modtest 2 --autocorr --quiet modtest 3 --autocorr --quiet modtest 4 --autocorr --quiet Breusch-Godfrey test for first-order autocorrelation Alternative statistic: TR^2 = 6.576105, with p-value = P(Chi-square(1) > 6.5761) = 0.0103 Breusch-Godfrey test for autocorrelation up to order 2 Alternative statistic: TR^2 = 7.922218, with p-value = P(Chi-square(2) > 7.92222) = 0.019 Breusch-Godfrey test for autocorrelation up to order 3 Alternative statistic: TR^2 = 11.200978, with p-value = P(Chi-square(3) > 11.201) = 0.0107 Breusch-Godfrey test for autocorrelation up to order 4 Alternative statistic: TR^2 = 11.220956, with p-value = P(Chi-square(4) > 11.221) = 0.0242 Yep, that’s not too good. -

12.6 Sign Test (Web)
12.4 Sign test (Web) Click on 'Bookmarks' in the Left-Hand menu and then click on the required section. 12.6 Sign test (Web) 12.6.1 Introduction The Sign Test is a one sample test that compares the median of a data set with a specific target value. The Sign Test performs the same function as the One Sample Wilcoxon Test, but it does not rank data values. Without the information provided by ranking, the Sign Test is less powerful (9.4.5) than the Wilcoxon Test. However, the Sign Test is useful for problems involving 'binomial' data, where observed data values are either above or below a target value. 12.6.2 Sign Test The Sign Test aims to test whether the observed data sample has been drawn from a population that has a median value, m, that is significantly different from (or greater/less than) a specific value, mO. The hypotheses are the same as in 12.1.2. We will illustrate the use of the Sign Test in Example 12.14 by using the same data as in Example 12.2. Example 12.14 The generation times, t, (5.2.4) of ten cultures of the same micro-organisms were recorded. Time, t (hr) 6.3 4.8 7.2 5.0 6.3 4.2 8.9 4.4 5.6 9.3 The microbiologist wishes to test whether the generation time for this micro- organism is significantly greater than a specific value of 5.0 hours. See following text for calculations: In performing the Sign Test, each data value, ti, is compared with the target value, mO, using the following conditions: ti < mO replace the data value with '-' ti = mO exclude the data value ti > mO replace the data value with '+' giving the results in Table 12.14 Difference + - + ----- + - + - + + Table 12.14 Signs of Differences in Example 12.14 12.4.p1 12.4 Sign test (Web) We now calculate the values of r + = number of '+' values: r + = 6 in Example 12.14 n = total number of data values not excluded: n = 9 in Example 12.14 Decision making in this test is based on the probability of observing particular values of r + for a given value of n. -

Alternative Tests for Time Series Dependence Based on Autocorrelation Coefficients
Alternative Tests for Time Series Dependence Based on Autocorrelation Coefficients Richard M. Levich and Rosario C. Rizzo * Current Draft: December 1998 Abstract: When autocorrelation is small, existing statistical techniques may not be powerful enough to reject the hypothesis that a series is free of autocorrelation. We propose two new and simple statistical tests (RHO and PHI) based on the unweighted sum of autocorrelation and partial autocorrelation coefficients. We analyze a set of simulated data to show the higher power of RHO and PHI in comparison to conventional tests for autocorrelation, especially in the presence of small but persistent autocorrelation. We show an application of our tests to data on currency futures to demonstrate their practical use. Finally, we indicate how our methodology could be used for a new class of time series models (the Generalized Autoregressive, or GAR models) that take into account the presence of small but persistent autocorrelation. _______________________________________________________________ An earlier version of this paper was presented at the Symposium on Global Integration and Competition, sponsored by the Center for Japan-U.S. Business and Economic Studies, Stern School of Business, New York University, March 27-28, 1997. We thank Paul Samuelson and the other participants at that conference for useful comments. * Stern School of Business, New York University and Research Department, Bank of Italy, respectively. 1 1. Introduction Economic time series are often characterized by positive -

3 Autocorrelation
3 Autocorrelation Autocorrelation refers to the correlation of a time series with its own past and future values. Autocorrelation is also sometimes called “lagged correlation” or “serial correlation”, which refers to the correlation between members of a series of numbers arranged in time. Positive autocorrelation might be considered a specific form of “persistence”, a tendency for a system to remain in the same state from one observation to the next. For example, the likelihood of tomorrow being rainy is greater if today is rainy than if today is dry. Geophysical time series are frequently autocorrelated because of inertia or carryover processes in the physical system. For example, the slowly evolving and moving low pressure systems in the atmosphere might impart persistence to daily rainfall. Or the slow drainage of groundwater reserves might impart correlation to successive annual flows of a river. Or stored photosynthates might impart correlation to successive annual values of tree-ring indices. Autocorrelation complicates the application of statistical tests by reducing the effective sample size. Autocorrelation can also complicate the identification of significant covariance or correlation between time series (e.g., precipitation with a tree-ring series). Autocorrelation implies that a time series is predictable, probabilistically, as future values are correlated with current and past values. Three tools for assessing the autocorrelation of a time series are (1) the time series plot, (2) the lagged scatterplot, and (3) the autocorrelation function. 3.1 Time series plot Positively autocorrelated series are sometimes referred to as persistent because positive departures from the mean tend to be followed by positive depatures from the mean, and negative departures from the mean tend to be followed by negative departures (Figure 3.1). -

Statistical Tool for Soil Biology : 11. Autocorrelogram and Mantel Test
‘i Pl w f ’* Em J. 1996, (4), i Soil BioZ., 32 195-203 Statistical tool for soil biology. XI. Autocorrelogram and Mantel test Jean-Pierre Rossi Laboratoire d Ecologie des Sols Trofiicaux, ORSTOM/Université Paris 6, 32, uv. Varagnat, 93143 Bondy Cedex, France. E-mail: rossij@[email protected]. fr. Received October 23, 1996; accepted March 24, 1997. Abstract Autocorrelation analysis by Moran’s I and the Geary’s c coefficients is described and illustrated by the analysis of the spatial pattern of the tropical earthworm Clzuniodrilus ziehe (Eudrilidae). Simple and partial Mantel tests are presented and illustrated through the analysis various data sets. The interest of these methods for soil ecology is discussed. Keywords: Autocorrelation, correlogram, Mantel test, geostatistics, spatial distribution, earthworm, plant-parasitic nematode. L’outil statistique en biologie du sol. X.?. Autocorrélogramme et test de Mantel. Résumé L’analyse de l’autocorrélation par les indices I de Moran et c de Geary est décrite et illustrée à travers l’analyse de la distribution spatiale du ver de terre tropical Chuniodi-ibs zielae (Eudrilidae). Les tests simple et partiel de Mantel sont présentés et illustrés à travers l’analyse de jeux de données divers. L’intérêt de ces méthodes en écologie du sol est discuté. Mots-clés : Autocorrélation, corrélogramme, test de Mantel, géostatistiques, distribution spatiale, vers de terre, nématodes phytoparasites. INTRODUCTION the variance that appear to be related by a simple power law. The obvious interest of that method is Spatial heterogeneity is an inherent feature of that samples from various sites can be included in soil faunal communities with significant functional the analysis. -

Applied Time Series Analysis
Applied Time Series Analysis SS 2018 February 12, 2018 Dr. Marcel Dettling Institute for Data Analysis and Process Design Zurich University of Applied Sciences CH-8401 Winterthur Table of Contents 1 INTRODUCTION 1 1.1 PURPOSE 1 1.2 EXAMPLES 2 1.3 GOALS IN TIME SERIES ANALYSIS 8 2 MATHEMATICAL CONCEPTS 11 2.1 DEFINITION OF A TIME SERIES 11 2.2 STATIONARITY 11 2.3 TESTING STATIONARITY 13 3 TIME SERIES IN R 15 3.1 TIME SERIES CLASSES 15 3.2 DATES AND TIMES IN R 17 3.3 DATA IMPORT 21 4 DESCRIPTIVE ANALYSIS 23 4.1 VISUALIZATION 23 4.2 TRANSFORMATIONS 26 4.3 DECOMPOSITION 29 4.4 AUTOCORRELATION 50 4.5 PARTIAL AUTOCORRELATION 66 5 STATIONARY TIME SERIES MODELS 69 5.1 WHITE NOISE 69 5.2 ESTIMATING THE CONDITIONAL MEAN 70 5.3 AUTOREGRESSIVE MODELS 71 5.4 MOVING AVERAGE MODELS 85 5.5 ARMA(P,Q) MODELS 93 6 SARIMA AND GARCH MODELS 99 6.1 ARIMA MODELS 99 6.2 SARIMA MODELS 105 6.3 ARCH/GARCH MODELS 109 7 TIME SERIES REGRESSION 113 7.1 WHAT IS THE PROBLEM? 113 7.2 FINDING CORRELATED ERRORS 117 7.3 COCHRANE‐ORCUTT METHOD 124 7.4 GENERALIZED LEAST SQUARES 125 7.5 MISSING PREDICTOR VARIABLES 131 8 FORECASTING 137 8.1 STATIONARY TIME SERIES 138 8.2 SERIES WITH TREND AND SEASON 145 8.3 EXPONENTIAL SMOOTHING 152 9 MULTIVARIATE TIME SERIES ANALYSIS 161 9.1 PRACTICAL EXAMPLE 161 9.2 CROSS CORRELATION 165 9.3 PREWHITENING 168 9.4 TRANSFER FUNCTION MODELS 170 10 SPECTRAL ANALYSIS 175 10.1 DECOMPOSING IN THE FREQUENCY DOMAIN 175 10.2 THE SPECTRUM 179 10.3 REAL WORLD EXAMPLE 186 11 STATE SPACE MODELS 187 11.1 STATE SPACE FORMULATION 187 11.2 AR PROCESSES WITH MEASUREMENT NOISE 188 11.3 DYNAMIC LINEAR MODELS 191 ATSA 1 Introduction 1 Introduction 1.1 Purpose Time series data, i.e. -

Quantitative Risk Management in R
QUANTITATIVE RISK MANAGEMENT IN R Characteristics of volatile return series Quantitative Risk Management in R Log-returns compared with iid data ● Can financial returns be modeled as independent and identically distributed (iid)? ● Random walk model for log asset prices ● Implies that future price behavior cannot be predicted ● Instructive to compare real returns with iid data ● Real returns o!en show volatility clustering QUANTITATIVE RISK MANAGEMENT IN R Let’s practice! QUANTITATIVE RISK MANAGEMENT IN R Estimating serial correlation Quantitative Risk Management in R Sample autocorrelations ● Sample autocorrelation function (acf) measures correlation between variables separated by lag (k) ● Stationarity is implicitly assumed: ● Expected return constant over time ● Variance of return distribution always the same ● Correlation between returns k apart always the same ● Notation for sample autocorrelation: ⇢ˆ(k) Quantitative Risk Management in R The sample acf plot or correlogram > acf(ftse) Quantitative Risk Management in R The sample acf plot or correlogram > acf(abs(ftse)) QUANTITATIVE RISK MANAGEMENT IN R Let’s practice! QUANTITATIVE RISK MANAGEMENT IN R The Ljung-Box test Quantitative Risk Management in R Testing the iid hypothesis with the Ljung-Box test ● Numerical test calculated from squared sample autocorrelations up to certain lag ● Compared with chi-squared distribution with k degrees of freedom (df) ● Should also be carried out on absolute returns k ⇢ˆ(j)2 X2 = n(n + 2) n j j=1 X − Quantitative Risk Management in R Example of -

Autocorrelation and Seasonality Otexts.Com/Fpp/2/ Otexts.Com/Fpp/6/1
Rob J Hyndman Forecasting using 3. Autocorrelation and seasonality OTexts.com/fpp/2/ OTexts.com/fpp/6/1 Forecasting using R 1 Outline 1 Time series graphics 2 Seasonal or cyclic? 3 Autocorrelation Forecasting using R Time series graphics 2 Time series graphics Time plots R command: plot or plot.ts Seasonal plots R command: seasonplot Seasonal subseries plots R command: monthplot Lag plots R command: lag.plot ACF plots R command: Acf Forecasting using R Time series graphics 3 Time series graphics Economy class passengers: Melbourne−Sydney plot(melsyd[,"Economy.Class"]) 30 25 20 15 Thousands 10 5 0 1988 1989 1990 1991 1992 1993 Year Forecasting using R Time series graphics 4 Time series graphics Antidiabetic drug sales 30 > plot(a10) 25 20 15 $ million 10 5 1995 2000 2005 Year Forecasting using R Time series graphics 5 Time series graphics Seasonal plot: antidiabetic drug sales 30 2008 ● 2007 ● ● 2007 ● 25 ● ● 2006 ● ● ● ● ● ● 2006 ● ● ● ● 2005 ● ● ● ● 2005 20 ● ● ● ● 2004 ● ● 2004 ● ● ● ● ● ● ● ● ● 2003 ● ● ● ● ● ● 2003 2002 ● ● ● ● ● ● $ million ● 2002 15 ● ● 2001 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 2001 2000 ● ● ● ● ● ● ● 2000 ● ● ● 1999 ● ● ● ● ● ● ● ● ● ● 1998 1999 ● ● ● ● ● ● ● 1997 10 ● ● ● ● ● ● ● ● ● ● ● 1998 ● ● 1996 19961997 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 19931995 ● ● ● ● ● 19941995 ● ● ● ● ● ● ● ● ● ● ● ● 1993 ● ● ● 1994 ● ● ● ● ● ● ● 1992 ● ● ● ● ● ● ● ● ● 5 1992 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1991 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec Year Forecasting using R Time series graphics 6 Seasonal plots Data plotted against the individual “seasons” in which the data were observed. (In this case a “season” is a month.) Something like a time plot except that the data from each season are overlapped. Enables the underlying seasonal pattern to be seen more clearly, and also allows any substantial departures from the seasonal pattern to be easily identified. -

1 Sample Sign Test 1
Non-Parametric Univariate Tests: 1 Sample Sign Test 1 1 SAMPLE SIGN TEST A non-parametric equivalent of the 1 SAMPLE T-TEST. ASSUMPTIONS: Data is non-normally distributed, even after log transforming. This test makes no assumption about the shape of the population distribution, therefore this test can handle a data set that is non-symmetric, that is skewed either to the left or the right. THE POINT: The SIGN TEST simply computes a significance test of a hypothesized median value for a single data set. Like the 1 SAMPLE T-TEST you can choose whether you want to use a one-tailed or two-tailed distribution based on your hypothesis; basically, do you want to test whether the median value of the data set is equal to some hypothesized value (H0: η = ηo), or do you want to test whether it is greater (or lesser) than that value (H0: η > or < ηo). Likewise, you can choose to set confidence intervals around η at some α level and see whether ηo falls within the range. This is equivalent to the significance test, just as in any T-TEST. In English, the kind of question you would be interested in asking is whether some observation is likely to belong to some data set you already have defined. That is to say, whether the observation of interest is a typical value of that data set. Formally, you are either testing to see whether the observation is a good estimate of the median, or whether it falls within confidence levels set around that median. -

Signed-Rank Tests for ARMA Models
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector JOURNAL OF MULTIVARIATE ANALYSIS 39, l-29 ( 1991) Time Series Analysis via Rank Order Theory: Signed-Rank Tests for ARMA Models MARC HALLIN* Universith Libre de Bruxelles, Brussels, Belgium AND MADAN L. PURI+ Indiana University Communicated by C. R. Rao An asymptotic distribution theory is developed for a general class of signed-rank serial statistics, and is then used to derive asymptotically locally optimal tests (in the maximin sense) for testing an ARMA model against other ARMA models. Special cases yield Fisher-Yates, van der Waerden, and Wilcoxon type tests. The asymptotic relative efficiencies of the proposed procedures with respect to each other, and with respect to their normal theory counterparts, are provided. Cl 1991 Academic Press. Inc. 1. INTRODUCTION 1 .l. Invariance, Ranks and Signed-Ranks Invariance arguments constitute the theoretical cornerstone of rank- based methods: whenever weaker unbiasedness or similarity properties can be considered satisfying or adequate, permutation tests, which generally follow from the usual Neyman structure arguments, are theoretically preferable to rank tests, since they are less restrictive and thus allow for more powerful results (though, of course, their practical implementation may be more problematic). Which type of ranks (signed or unsigned) should be adopted-if Received May 3, 1989; revised October 23, 1990. AMS 1980 subject cIassifications: 62Gl0, 62MlO. Key words and phrases: signed ranks, serial rank statistics, ARMA models, asymptotic relative effhziency, locally asymptotically optimal tests. *Research supported by the the Fonds National de la Recherche Scientifique and the Minist&e de la Communaute Franpaise de Belgique. -

6 Single Sample Methods for a Location Parameter
6 Single Sample Methods for a Location Parameter If there are serious departures from parametric test assumptions (e.g., normality or symmetry), nonparametric tests on a measure of central tendency (usually the median) are used. Recall: M is a median of a random variable X if P (X M) = P (X M) = :5. • ≤ ≥ The distribution of X is symmetric about c if P (X c x) = P (X c + x) for all x. • ≤ − ≥ For symmetric continuous distributions, the median M = the mean µ. Thus, all conclusions • about the median can also be applied to the mean. If X be a binomial random variable with parameters n and p (denoted X B(n; p)) then • n ∼ P (X = x) = px(1 p)n−x for x = 0; 1; : : : ; n x − n n! where = and k! = k(k 1)(k 2) 2 1: • x x!(n x)! − − ··· · − Tables exist for the cdf P (X x) for various choices of n and p. The probabilities and • cdf values are also easy to produce≤ using SAS or R. Thus, if X B(n; :5), we have • ∼ n P (X = x) = (:5)n x x n P (X x) = (:5)n ≤ k k X=0 P (X x) = P (X n x) because the B(n; :5) distribution is symmetric. ≤ ≥ − For sample sizes n > 20 and p = :5, a normal approximation (with continuity correction) • to the binomial probabilities is often used instead of binomial tables. (x :5) :5n { Calculate z = ± − : Use x+:5 when x < :5n and use x :5 when x > :5n. :5pn − { The value of z is compared to N(0; 1), the standard normal distribution. -

Tests of Hypotheses Using Statistics
Tests of Hypotheses Using Statistics Adam Massey¤and Steven J. Millery Mathematics Department Brown University Providence, RI 02912 Abstract We present the various methods of hypothesis testing that one typically encounters in a mathematical statistics course. The focus will be on conditions for using each test, the hypothesis tested by each test, and the appropriate (and inappropriate) ways of using each test. We conclude by summarizing the di®erent tests (what conditions must be met to use them, what the test statistic is, and what the critical region is). Contents 1 Types of Hypotheses and Test Statistics 2 1.1 Introduction . 2 1.2 Types of Hypotheses . 3 1.3 Types of Statistics . 3 2 z-Tests and t-Tests 5 2.1 Testing Means I: Large Sample Size or Known Variance . 5 2.2 Testing Means II: Small Sample Size and Unknown Variance . 9 3 Testing the Variance 12 4 Testing Proportions 13 4.1 Testing Proportions I: One Proportion . 13 4.2 Testing Proportions II: K Proportions . 15 4.3 Testing r £ c Contingency Tables . 17 4.4 Incomplete r £ c Contingency Tables Tables . 18 5 Normal Regression Analysis 19 6 Non-parametric Tests 21 6.1 Tests of Signs . 21 6.2 Tests of Ranked Signs . 22 6.3 Tests Based on Runs . 23 ¤E-mail: [email protected] yE-mail: [email protected] 1 7 Summary 26 7.1 z-tests . 26 7.2 t-tests . 27 7.3 Tests comparing means . 27 7.4 Variance Test . 28 7.5 Proportions . 28 7.6 Contingency Tables .