The Bayesian Approach to Statistics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

DSA 5403 Bayesian Statistics: an Advancing Introduction 16 Units – Each Unit a Week’S Work
DSA 5403 Bayesian Statistics: An Advancing Introduction 16 units – each unit a week’s work. The following are the contents of the course divided into chapters of the book Doing Bayesian Data Analysis . by John Kruschke. The course is structured around the above book but will be embellished with more theoretical content as needed. The book can be obtained from the library : http://www.sciencedirect.com/science/book/9780124058880 Topics: This is divided into three parts From the book: “Part I The basics: models, probability, Bayes' rule and r: Introduction: credibility, models, and parameters; The R programming language; What is this stuff called probability?; Bayes' rule Part II All the fundamentals applied to inferring a binomial probability: Inferring a binomial probability via exact mathematical analysis; Markov chain Monte C arlo; J AG S ; Hierarchical models; Model comparison and hierarchical modeling; Null hypothesis significance testing; Bayesian approaches to testing a point ("Null") hypothesis; G oals, power, and sample size; S tan Part III The generalized linear model: Overview of the generalized linear model; Metric-predicted variable on one or two groups; Metric predicted variable with one metric predictor; Metric predicted variable with multiple metric predictors; Metric predicted variable with one nominal predictor; Metric predicted variable with multiple nominal predictors; Dichotomous predicted variable; Nominal predicted variable; Ordinal predicted variable; C ount predicted variable; Tools in the trunk” Part 1: The Basics: Models, Probability, Bayes’ Rule and R Unit 1 Chapter 1, 2 Credibility, Models, and Parameters, • Derivation of Bayes’ rule • Re-allocation of probability • The steps of Bayesian data analysis • Classical use of Bayes’ rule o Testing – false positives etc o Definitions of prior, likelihood, evidence and posterior Unit 2 Chapter 3 The R language • Get the software • Variables types • Loading data • Functions • Plots Unit 3 Chapter 4 Probability distributions. -

Practical Statistics for Particle Physics Lecture 1 AEPS2018, Quy Nhon, Vietnam
Practical Statistics for Particle Physics Lecture 1 AEPS2018, Quy Nhon, Vietnam Roger Barlow The University of Huddersfield August 2018 Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 1 / 34 Lecture 1: The Basics 1 Probability What is it? Frequentist Probability Conditional Probability and Bayes' Theorem Bayesian Probability 2 Probability distributions and their properties Expectation Values Binomial, Poisson and Gaussian 3 Hypothesis testing Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 2 / 34 Question: What is Probability? Typical exam question Q1 Explain what is meant by the Probability PA of an event A [1] Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 3 / 34 Four possible answers PA is number obeying certain mathematical rules. PA is a property of A that determines how often A happens For N trials in which A occurs NA times, PA is the limit of NA=N for large N PA is my belief that A will happen, measurable by seeing what odds I will accept in a bet. Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 4 / 34 Mathematical Kolmogorov Axioms: For all A ⊂ S PA ≥ 0 PS = 1 P(A[B) = PA + PB if A \ B = ϕ and A; B ⊂ S From these simple axioms a complete and complicated structure can be − ≤ erected. E.g. show PA = 1 PA, and show PA 1.... But!!! This says nothing about what PA actually means. Kolmogorov had frequentist probability in mind, but these axioms apply to any definition. Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 5 / 34 Classical or Real probability Evolved during the 18th-19th century Developed (Pascal, Laplace and others) to serve the gambling industry. -

Bayesian Inference in Linguistic Analysis Stephany Palmer 1
Bayesian Inference in Linguistic Analysis Stephany Palmer 1 | Introduction: Besides the dominant theory of probability, Frequentist inference, there exists a different interpretation of probability. This other interpretation, Bayesian inference, factors in prior knowledge of the situation of interest and lends itself to allow strongly worded conclusions from the sample data. Although having not been widely used until recently due to technological advancements relieving the computationally heavy nature of Bayesian probability, it can be found in linguistic studies amongst others to update or sustain long-held hypotheses. 2 | Data/Information Analysis: Before performing a study, one should ask themself what they wish to get out of it. After collecting the data, what does one do with it? You can summarize your sample with descriptive statistics like mean, variance, and standard deviation. However, if you want to use the sample data to make inferences about the population, that involves inferential statistics. In inferential statistics, probability is used to make conclusions about the situation of interest. 3 | Frequentist vs Bayesian: The classical and dominant school of thought is frequentist probability, which is what I have been taught throughout my years learning statistics, and I assume is the same throughout the American education system. In taking a sample, one is essentially trying to estimate an unknown parameter. When interpreting the result through a confidence interval (CI), it is not allowed to interpret that the actual parameter lies within the CI, so you have to circumvent and say that “we are 95% confident that the actual value of the unknown parameter lies within the CI, that in infinite repeated trials, 95% of the CI’s will contain the true value, and 5% will not.” Bayesian probability says that only the data is real, and as the unknown parameter is abstract, thus some potential values of it are more plausible than others. -
3.3 Bayes' Formula
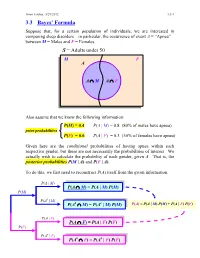
Ismor Fischer, 5/29/2012 3.3-1 3.3 Bayes’ Formula Suppose that, for a certain population of individuals, we are interested in comparing sleep disorders – in particular, the occurrence of event A = “Apnea” – between M = Males and F = Females. S = Adults under 50 M F A A ∩ M A ∩ F Also assume that we know the following information: P(M) = 0.4 P(A | M) = 0.8 (80% of males have apnea) prior probabilities P(F) = 0.6 P(A | F) = 0.3 (30% of females have apnea) Given here are the conditional probabilities of having apnea within each respective gender, but these are not necessarily the probabilities of interest. We actually wish to calculate the probability of each gender, given A. That is, the posterior probabilities P(M | A) and P(F | A). To do this, we first need to reconstruct P(A) itself from the given information. P(A | M) P(A ∩ M) = P(A | M) P(M) P(M) P(Ac | M) c c P(A ∩ M) = P(A | M) P(M) P(A) = P(A | M) P(M) + P(A | F) P(F) P(A | F) P(A ∩ F) = P(A | F) P(F) P(F) P(Ac | F) c c P(A ∩ F) = P(A | F) P(F) Ismor Fischer, 5/29/2012 3.3-2 So, given A… P(M ∩ A) P(A | M) P(M) P(M | A) = P(A) = P(A | M) P(M) + P(A | F) P(F) (0.8)(0.4) 0.32 = (0.8)(0.4) + (0.3)(0.6) = 0.50 = 0.64 and posterior P(F ∩ A) P(A | F) P(F) P(F | A) = = probabilities P(A) P(A | M) P(M) + P(A | F) P(F) (0.3)(0.6) 0.18 = (0.8)(0.4) + (0.3)(0.6) = 0.50 = 0.36 S Thus, the additional information that a M F randomly selected individual has apnea (an A event with probability 50% – why?) increases the likelihood of being male from a prior probability of 40% to a posterior probability 0.32 0.18 of 64%, and likewise, decreases the likelihood of being female from a prior probability of 60% to a posterior probability of 36%. -

3 Autocorrelation
3 Autocorrelation Autocorrelation refers to the correlation of a time series with its own past and future values. Autocorrelation is also sometimes called “lagged correlation” or “serial correlation”, which refers to the correlation between members of a series of numbers arranged in time. Positive autocorrelation might be considered a specific form of “persistence”, a tendency for a system to remain in the same state from one observation to the next. For example, the likelihood of tomorrow being rainy is greater if today is rainy than if today is dry. Geophysical time series are frequently autocorrelated because of inertia or carryover processes in the physical system. For example, the slowly evolving and moving low pressure systems in the atmosphere might impart persistence to daily rainfall. Or the slow drainage of groundwater reserves might impart correlation to successive annual flows of a river. Or stored photosynthates might impart correlation to successive annual values of tree-ring indices. Autocorrelation complicates the application of statistical tests by reducing the effective sample size. Autocorrelation can also complicate the identification of significant covariance or correlation between time series (e.g., precipitation with a tree-ring series). Autocorrelation implies that a time series is predictable, probabilistically, as future values are correlated with current and past values. Three tools for assessing the autocorrelation of a time series are (1) the time series plot, (2) the lagged scatterplot, and (3) the autocorrelation function. 3.1 Time series plot Positively autocorrelated series are sometimes referred to as persistent because positive departures from the mean tend to be followed by positive depatures from the mean, and negative departures from the mean tend to be followed by negative departures (Figure 3.1). -

Naïve Bayes Classifier
CS 60050 Machine Learning Naïve Bayes Classifier Some slides taken from course materials of Tan, Steinbach, Kumar Bayes Classifier ● A probabilistic framework for solving classification problems ● Approach for modeling probabilistic relationships between the attribute set and the class variable – May not be possible to certainly predict class label of a test record even if it has identical attributes to some training records – Reason: noisy data or presence of certain factors that are not included in the analysis Probability Basics ● P(A = a, C = c): joint probability that random variables A and C will take values a and c respectively ● P(A = a | C = c): conditional probability that A will take the value a, given that C has taken value c P(A,C) P(C | A) = P(A) P(A,C) P(A | C) = P(C) Bayes Theorem ● Bayes theorem: P(A | C)P(C) P(C | A) = P(A) ● P(C) known as the prior probability ● P(C | A) known as the posterior probability Example of Bayes Theorem ● Given: – A doctor knows that meningitis causes stiff neck 50% of the time – Prior probability of any patient having meningitis is 1/50,000 – Prior probability of any patient having stiff neck is 1/20 ● If a patient has stiff neck, what’s the probability he/she has meningitis? P(S | M )P(M ) 0.5×1/50000 P(M | S) = = = 0.0002 P(S) 1/ 20 Bayesian Classifiers ● Consider each attribute and class label as random variables ● Given a record with attributes (A1, A2,…,An) – Goal is to predict class C – Specifically, we want to find the value of C that maximizes P(C| A1, A2,…,An ) ● Can we estimate -

Numerical Physics with Probabilities: the Monte Carlo Method and Bayesian Statistics Part I for Assignment 2
Numerical Physics with Probabilities: The Monte Carlo Method and Bayesian Statistics Part I for Assignment 2 Department of Physics, University of Surrey module: Energy, Entropy and Numerical Physics (PHY2063) 1 Numerical Physics part of Energy, Entropy and Numerical Physics This numerical physics course is part of the second-year Energy, Entropy and Numerical Physics mod- ule. It is online at the EENP module on SurreyLearn. See there for assignments, deadlines etc. The course is about numerically solving ODEs (ordinary differential equations) and PDEs (partial differential equations), and introducing the (large) part of numerical physics where probabilities are used. This assignment is on numerical physics of probabilities, and looks at the Monte Carlo (MC) method, and at the Bayesian statistics approach to data analysis. It covers MC and Bayesian statistics, in that order. MC is a widely used numerical technique, it is used, amongst other things, for modelling many random processes. MC is used in fields from statistical physics, to nuclear and particle physics. Bayesian statistics is a powerful data analysis method, and is used everywhere from particle physics to spam-email filters. Data analysis is fundamental to science. For example, analysis of the data from the Large Hadron Collider was required to extract a most probable value for the mass of the Higgs boson, together with an estimate of the region of masses where the scientists think the mass is. This region is typically expressed as a range of mass values where the they think the true mass lies with high (e.g., 95%) probability. Many of you will be analysing data (physics data, commercial data, etc) for your PTY or RY, or future careers1 . -

Posterior Propriety and Admissibility of Hyperpriors in Normal
The Annals of Statistics 2005, Vol. 33, No. 2, 606–646 DOI: 10.1214/009053605000000075 c Institute of Mathematical Statistics, 2005 POSTERIOR PROPRIETY AND ADMISSIBILITY OF HYPERPRIORS IN NORMAL HIERARCHICAL MODELS1 By James O. Berger, William Strawderman and Dejun Tang Duke University and SAMSI, Rutgers University and Novartis Pharmaceuticals Hierarchical modeling is wonderful and here to stay, but hyper- parameter priors are often chosen in a casual fashion. Unfortunately, as the number of hyperparameters grows, the effects of casual choices can multiply, leading to considerably inferior performance. As an ex- treme, but not uncommon, example use of the wrong hyperparameter priors can even lead to impropriety of the posterior. For exchangeable hierarchical multivariate normal models, we first determine when a standard class of hierarchical priors results in proper or improper posteriors. We next determine which elements of this class lead to admissible estimators of the mean under quadratic loss; such considerations provide one useful guideline for choice among hierarchical priors. Finally, computational issues with the resulting posterior distributions are addressed. 1. Introduction. 1.1. The model and the problems. Consider the block multivariate nor- mal situation (sometimes called the “matrix of means problem”) specified by the following hierarchical Bayesian model: (1) X ∼ Np(θ, I), θ ∼ Np(B, Σπ), where X1 θ1 X2 θ2 Xp×1 = . , θp×1 = . , arXiv:math/0505605v1 [math.ST] 27 May 2005 . X θ m m Received February 2004; revised July 2004. 1Supported by NSF Grants DMS-98-02261 and DMS-01-03265. AMS 2000 subject classifications. Primary 62C15; secondary 62F15. Key words and phrases. Covariance matrix, quadratic loss, frequentist risk, posterior impropriety, objective priors, Markov chain Monte Carlo. -

Scalable and Robust Bayesian Inference Via the Median Posterior
Scalable and Robust Bayesian Inference via the Median Posterior CS 584: Big Data Analytics Material adapted from David Dunson’s talk (http://bayesian.org/sites/default/files/Dunson.pdf) & Lizhen Lin’s ICML talk (http://techtalks.tv/talks/scalable-and-robust-bayesian-inference-via-the-median-posterior/61140/) Big Data Analytics • Large (big N) and complex (big P with interactions) data are collected routinely • Both speed & generality of data analysis methods are important • Bayesian approaches offer an attractive general approach for modeling the complexity of big data • Computational intractability of posterior sampling is a major impediment to application of flexible Bayesian methods CS 584 [Spring 2016] - Ho Existing Frequentist Approaches: The Positives • Optimization-based approaches, such as ADMM or glmnet, are currently most popular for analyzing big data • General and computationally efficient • Used orders of magnitude more than Bayes methods • Can exploit distributed & cloud computing platforms • Can borrow some advantages of Bayes methods through penalties and regularization CS 584 [Spring 2016] - Ho Existing Frequentist Approaches: The Drawbacks • Such optimization-based methods do not provide measure of uncertainty • Uncertainty quantification is crucial for most applications • Scalable penalization methods focus primarily on convex optimization — greatly limits scope and puts ceiling on performance • For non-convex problems and data with complex structure, existing optimization algorithms can fail badly CS 584 [Spring 2016] - -

LINEAR REGRESSION MODELS Likelihood and Reference Bayesian
{ LINEAR REGRESSION MODELS { Likeliho o d and Reference Bayesian Analysis Mike West May 3, 1999 1 Straight Line Regression Mo dels We b egin with the simple straight line regression mo del y = + x + i i i where the design p oints x are xed in advance, and the measurement/sampling i 2 errors are indep endent and normally distributed, N 0; for each i = i i 1;::: ;n: In this context, wehavelooked at general mo delling questions, data and the tting of least squares estimates of and : Now we turn to more formal likeliho o d and Bayesian inference. 1.1 Likeliho o d and MLEs The formal parametric inference problem is a multi-parameter problem: we 2 require inferences on the three parameters ; ; : The likeliho o d function has a simple enough form, as wenow show. Throughout, we do not indicate the design p oints in conditioning statements, though they are implicitly conditioned up on. Write Y = fy ;::: ;y g and X = fx ;::: ;x g: Given X and the mo del 1 n 1 n parameters, each y is the corresp onding zero-mean normal random quantity i plus the term + x ; so that y is normal with this term as its mean and i i i 2 variance : Also, since the are indep endent, so are the y : Thus i i 2 2 y j ; ; N + x ; i i with conditional density function 2 2 2 2 1=2 py j ; ; = expfy x =2 g=2 i i i for each i: Also, by indep endence, the joint density function is n Y 2 2 : py j ; ; = pY j ; ; i i=1 1 Given the observed resp onse values Y this provides the likeliho o d function for the three parameters: the joint density ab ove evaluated at the observed and 2 hence now xed values of Y; now viewed as a function of ; ; as they vary across p ossible parameter values. -

The Deviance Information Criterion: 12 Years On
J. R. Statist. Soc. B (2014) The deviance information criterion: 12 years on David J. Spiegelhalter, University of Cambridge, UK Nicola G. Best, Imperial College School of Public Health, London, UK Bradley P. Carlin University of Minnesota, Minneapolis, USA and Angelika van der Linde Bremen, Germany [Presented to The Royal Statistical Society at its annual conference in a session organized by the Research Section on Tuesday, September 3rd, 2013, Professor G. A.Young in the Chair ] Summary.The essentials of our paper of 2002 are briefly summarized and compared with other criteria for model comparison. After some comments on the paper’s reception and influence, we consider criticisms and proposals for improvement made by us and others. Keywords: Bayesian; Model comparison; Prediction 1. Some background to model comparison Suppose that we have a given set of candidate models, and we would like a criterion to assess which is ‘better’ in a defined sense. Assume that a model for observed data y postulates a density p.y|θ/ (which may include covariates etc.), and call D.θ/ =−2log{p.y|θ/} the deviance, here considered as a function of θ. Classical model choice uses hypothesis testing for comparing nested models, e.g. the deviance (likelihood ratio) test in generalized linear models. For non- nested models, alternatives include the Akaike information criterion AIC =−2log{p.y|θˆ/} + 2k where θˆ is the maximum likelihood estimate and k is the number of parameters in the model (dimension of Θ). AIC is built with the aim of favouring models that are likely to make good predictions. -

1 Estimation and Beyond in the Bayes Universe
ISyE8843A, Brani Vidakovic Handout 7 1 Estimation and Beyond in the Bayes Universe. 1.1 Estimation No Bayes estimate can be unbiased but Bayesians are not upset! No Bayes estimate with respect to the squared error loss can be unbiased, except in a trivial case when its Bayes’ risk is 0. Suppose that for a proper prior ¼ the Bayes estimator ±¼(X) is unbiased, Xjθ (8θ)E ±¼(X) = θ: This implies that the Bayes risk is 0. The Bayes risk of ±¼(X) can be calculated as repeated expectation in two ways, θ Xjθ 2 X θjX 2 r(¼; ±¼) = E E (θ ¡ ±¼(X)) = E E (θ ¡ ±¼(X)) : Thus, conveniently choosing either EθEXjθ or EX EθjX and using the properties of conditional expectation we have, θ Xjθ 2 θ Xjθ X θjX X θjX 2 r(¼; ±¼) = E E θ ¡ E E θ±¼(X) ¡ E E θ±¼(X) + E E ±¼(X) θ Xjθ 2 θ Xjθ X θjX X θjX 2 = E E θ ¡ E θ[E ±¼(X)] ¡ E ±¼(X)E θ + E E ±¼(X) θ Xjθ 2 θ X X θjX 2 = E E θ ¡ E θ ¢ θ ¡ E ±¼(X)±¼(X) + E E ±¼(X) = 0: Bayesians are not upset. To check for its unbiasedness, the Bayes estimator is averaged with respect to the model measure (Xjθ), and one of the Bayesian commandments is: Thou shall not average with respect to sample space, unless you have Bayesian design in mind. Even frequentist agree that insisting on unbiasedness can lead to bad estimators, and that in their quest to minimize the risk by trading off between variance and bias-squared a small dosage of bias can help.