A Widely Applicable Bayesian Information Criterion
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Recursive Formula for Moments of a Binomial Distribution Arp´ Ad´ Benyi´ ([email protected]), University of Massachusetts, Amherst, MA 01003 and Saverio M
A Recursive Formula for Moments of a Binomial Distribution Arp´ ad´ Benyi´ ([email protected]), University of Massachusetts, Amherst, MA 01003 and Saverio M. Manago ([email protected]) Naval Postgraduate School, Monterey, CA 93943 While teaching a course in probability and statistics, one of the authors came across an apparently simple question about the computation of higher order moments of a ran- dom variable. The topic of moments of higher order is rarely emphasized when teach- ing a statistics course. The textbooks we came across in our classes, for example, treat this subject rather scarcely; see [3, pp. 265–267], [4, pp. 184–187], also [2, p. 206]. Most of the examples given in these books stop at the second moment, which of course suffices if one is only interested in finding, say, the dispersion (or variance) of a ran- 2 2 dom variable X, D (X) = M2(X) − M(X) . Nevertheless, moments of order higher than 2 are relevant in many classical statistical tests when one assumes conditions of normality. These assumptions may be checked by examining the skewness or kurto- sis of a probability distribution function. The skewness, or the first shape parameter, corresponds to the the third moment about the mean. It describes the symmetry of the tails of a probability distribution. The kurtosis, also known as the second shape pa- rameter, corresponds to the fourth moment about the mean and measures the relative peakedness or flatness of a distribution. Significant skewness or kurtosis indicates that the data is not normal. However, we arrived at higher order moments unintentionally. -

A Computer Algebra System for R: Macaulay2 and the M2r Package
A computer algebra system for R: Macaulay2 and the m2r package David Kahle∗1, Christopher O'Neilly2, and Jeff Sommarsz3 1Department of Statistical Science, Baylor University 2Department of Mathematics, University of California, Davis 3Department of Mathematics, Statistics, and Computer Science, University of Illinois at Chicago Abstract Algebraic methods have a long history in statistics. The most prominent manifestation of modern algebra in statistics can be seen in the field of algebraic statistics, which brings tools from commutative algebra and algebraic geometry to bear on statistical problems. Now over two decades old, algebraic statistics has applications in a wide range of theoretical and applied statistical domains. Nevertheless, algebraic statistical methods are still not mainstream, mostly due to a lack of easy off-the-shelf imple- mentations. In this article we debut m2r, an R package that connects R to Macaulay2 through a persistent back-end socket connection running locally or on a cloud server. Topics range from basic use of m2r to applications and design philosophy. 1 Introduction Algebra, a branch of mathematics concerned with abstraction, structure, and symmetry, has a long history of applications in statistics. For example, Pearson's early work on method of moments estimation in mixture models ultimately involved systems of polynomial equations that he painstakingly and remarkably solved by hand (Pearson, 1894; Am´endolaet al., 2016). Fisher's work in design was strongly algebraic and combinato- rial, focusing on topics such as Latin squares (Fisher, 1934). Invariance and equivariance continue to form a major pillar of mathematical statistics through the lens of location-scale families (Pitman, 1939; Bondesson, 1983; Lehmann and Romano, 2005). -

DSA 5403 Bayesian Statistics: an Advancing Introduction 16 Units – Each Unit a Week’S Work
DSA 5403 Bayesian Statistics: An Advancing Introduction 16 units – each unit a week’s work. The following are the contents of the course divided into chapters of the book Doing Bayesian Data Analysis . by John Kruschke. The course is structured around the above book but will be embellished with more theoretical content as needed. The book can be obtained from the library : http://www.sciencedirect.com/science/book/9780124058880 Topics: This is divided into three parts From the book: “Part I The basics: models, probability, Bayes' rule and r: Introduction: credibility, models, and parameters; The R programming language; What is this stuff called probability?; Bayes' rule Part II All the fundamentals applied to inferring a binomial probability: Inferring a binomial probability via exact mathematical analysis; Markov chain Monte C arlo; J AG S ; Hierarchical models; Model comparison and hierarchical modeling; Null hypothesis significance testing; Bayesian approaches to testing a point ("Null") hypothesis; G oals, power, and sample size; S tan Part III The generalized linear model: Overview of the generalized linear model; Metric-predicted variable on one or two groups; Metric predicted variable with one metric predictor; Metric predicted variable with multiple metric predictors; Metric predicted variable with one nominal predictor; Metric predicted variable with multiple nominal predictors; Dichotomous predicted variable; Nominal predicted variable; Ordinal predicted variable; C ount predicted variable; Tools in the trunk” Part 1: The Basics: Models, Probability, Bayes’ Rule and R Unit 1 Chapter 1, 2 Credibility, Models, and Parameters, • Derivation of Bayes’ rule • Re-allocation of probability • The steps of Bayesian data analysis • Classical use of Bayes’ rule o Testing – false positives etc o Definitions of prior, likelihood, evidence and posterior Unit 2 Chapter 3 The R language • Get the software • Variables types • Loading data • Functions • Plots Unit 3 Chapter 4 Probability distributions. -

Algebraic Statistics Tutorial I Alleles Are in Hardy-Weinberg Equilibrium, the Genotype Frequencies Are
Example: Hardy-Weinberg Equilibrium Suppose a gene has two alleles, a and A. If allele a occurs in the population with frequency θ (and A with frequency 1 − θ) and these Algebraic Statistics Tutorial I alleles are in Hardy-Weinberg equilibrium, the genotype frequencies are P(X = aa)=θ2, P(X = aA)=2θ(1 − θ), P(X = AA)=(1 − θ)2 Seth Sullivant The model of Hardy-Weinberg equilibrium is the set North Carolina State University July 22, 2012 2 2 M = θ , 2θ(1 − θ), (1 − θ) | θ ∈ [0, 1] ⊂ ∆3 2 I(M)=paa+paA+pAA−1, paA−4paapAA Seth Sullivant (NCSU) Algebraic Statistics July 22, 2012 1 / 32 Seth Sullivant (NCSU) Algebraic Statistics July 22, 2012 2 / 32 Main Point of This Tutorial Phylogenetics Problem Given a collection of species, find the tree that explains their history. Many statistical models are described by (semi)-algebraic constraints on a natural parameter space. Generators of the vanishing ideal can be useful for constructing algorithms or analyzing properties of statistical model. Two Examples Phylogenetic Algebraic Geometry Sampling Contingency Tables Data consists of aligned DNA sequences from homologous genes Human: ...ACCGTGCAACGTGAACGA... Chimp: ...ACCTTGGAAGGTAAACGA... Gorilla: ...ACCGTGCAACGTAAACTA... Seth Sullivant (NCSU) Algebraic Statistics July 22, 2012 3 / 32 Seth Sullivant (NCSU) Algebraic Statistics July 22, 2012 4 / 32 Model-Based Phylogenetics Phylogenetic Models Use a probabilistic model of mutations Assuming site independence: Parameters for the model are the combinatorial tree T , and rate Phylogenetic Model is a latent class graphical model parameters for mutations on each edge Vertex v ∈ T gives a random variable Xv ∈ {A, C, G, T} Models give a probability for observing a particular aligned All random variables corresponding to internal nodes are latent collection of DNA sequences ACCGTGCAACGTGAACGA Human: X1 X2 X3 Chimp: ACGTTGCAAGGTAAACGA Gorilla: ACCGTGCAACGTAAACTA Y 2 Assuming site independence, data is summarized by empirical Y 1 distribution of columns in the alignment. -

Elect Your Council
Volume 41 • Issue 3 IMS Bulletin April/May 2012 Elect your Council Each year IMS holds elections so that its members can choose the next President-Elect CONTENTS of the Institute and people to represent them on IMS Council. The candidate for 1 IMS Elections President-Elect is Bin Yu, who is Chancellor’s Professor in the Department of Statistics and the Department of Electrical Engineering and Computer Science, at the University 2 Members’ News: Huixia of California at Berkeley. Wang, Ming Yuan, Allan Sly, The 12 candidates standing for election to the IMS Council are (in alphabetical Sebastien Roch, CR Rao order) Rosemary Bailey, Erwin Bolthausen, Alison Etheridge, Pablo Ferrari, Nancy 4 Author Identity and Open L. Garcia, Ed George, Haya Kaspi, Yves Le Jan, Xiao-Li Meng, Nancy Reid, Laurent Bibliography Saloff-Coste, and Richard Samworth. 6 Obituary: Franklin Graybill The elected Council members will join Arnoldo Frigessi, Steve Lalley, Ingrid Van Keilegom and Wing Wong, whose terms end in 2013; and Sandrine Dudoit, Steve 7 Statistical Issues in Assessing Hospital Evans, Sonia Petrone, Christian Robert and Qiwei Yao, whose terms end in 2014. Performance Read all about the candidates on pages 12–17, and cast your vote at http://imstat.org/elections/. Voting is open until May 29. 8 Anirban’s Angle: Learning from a Student Left: Bin Yu, candidate for IMS President-Elect. 9 Parzen Prize; Recent Below are the 12 Council candidates. papers: Probability Surveys Top row, l–r: R.A. Bailey, Erwin Bolthausen, Alison Etheridge, Pablo Ferrari Middle, l–r: Nancy L. Garcia, Ed George, Haya Kaspi, Yves Le Jan 11 COPSS Fisher Lecturer Bottom, l–r: Xiao-Li Meng, Nancy Reid, Laurent Saloff-Coste, Richard Samworth 12 Council Candidates 18 Awards nominations 19 Terence’s Stuff: Oscars for Statistics? 20 IMS meetings 24 Other meetings 27 Employment Opportunities 28 International Calendar of Statistical Events 31 Information for Advertisers IMS Bulletin 2 . -

Algebraic Statistics of Design of Experiments
Thammasat University, Bangkok Algebraic Statistics of Design of Experiments Giovanni Pistone Bangkok, March 14 2012 The talk 1. A short history of AS from a personal perspective. See a longer account by E. Riccomagno in • E. Riccomagno, Metrika 69(2-3), 397 (2009), ISSN 0026-1335, http://dx.doi.org/10.1007/s00184-008-0222-3. 2. The algebraic description of a designed experiment. I use the tutorial by M.P. Rogantin: • http://www.dima.unige.it/~rogantin/AS-DOE.pdf 3. Topics from the theory, cfr. the course teached by E. Riccomagno, H. Wynn and Hugo Maruri-Aguilar in 2009 at the Second de Brun Workshop in Galway: • http://hamilton.nuigalway.ie/DeBrunCentre/ SecondWorkshop/online.html. CIMPA Ecole \Statistique", 1980 `aNice (France) Sumate Sompakdee, GP, and Chantaluck Na Pombejra First paper People • Roberto Fontana, DISMA Politecnico di Torino. • Fabio Rapallo, Universit`adel Piemonte Orientale. • Eva Riccomagno DIMA Universit`adi Genova. • Maria Piera Rogantin, DIMA, Universit`adi Genova. • Henry P. Wynn, LSE London. AS and DoE: old biblio and state of the art Beginning of AS in DoE • G. Pistone, H.P. Wynn, Biometrika 83(3), 653 (1996), ISSN 0006-3444 • L. Robbiano, Gr¨obnerBases and Statistics, in Gr¨obnerBases and Applications (Proc. of the Conf. 33 Years of Gr¨obnerBases), edited by B. Buchberger, F. Winkler (Cambridge University Press, 1998), Vol. 251 of London Mathematical Society Lecture Notes, pp. 179{204 • R. Fontana, G. Pistone, M. Rogantin, Journal of Statistical Planning and Inference 87(1), 149 (2000), ISSN 0378-3758 • G. Pistone, E. Riccomagno, H.P. Wynn, Algebraic statistics: Computational commutative algebra in statistics, Vol. -

Practical Statistics for Particle Physics Lecture 1 AEPS2018, Quy Nhon, Vietnam
Practical Statistics for Particle Physics Lecture 1 AEPS2018, Quy Nhon, Vietnam Roger Barlow The University of Huddersfield August 2018 Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 1 / 34 Lecture 1: The Basics 1 Probability What is it? Frequentist Probability Conditional Probability and Bayes' Theorem Bayesian Probability 2 Probability distributions and their properties Expectation Values Binomial, Poisson and Gaussian 3 Hypothesis testing Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 2 / 34 Question: What is Probability? Typical exam question Q1 Explain what is meant by the Probability PA of an event A [1] Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 3 / 34 Four possible answers PA is number obeying certain mathematical rules. PA is a property of A that determines how often A happens For N trials in which A occurs NA times, PA is the limit of NA=N for large N PA is my belief that A will happen, measurable by seeing what odds I will accept in a bet. Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 4 / 34 Mathematical Kolmogorov Axioms: For all A ⊂ S PA ≥ 0 PS = 1 P(A[B) = PA + PB if A \ B = ϕ and A; B ⊂ S From these simple axioms a complete and complicated structure can be − ≤ erected. E.g. show PA = 1 PA, and show PA 1.... But!!! This says nothing about what PA actually means. Kolmogorov had frequentist probability in mind, but these axioms apply to any definition. Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 5 / 34 Classical or Real probability Evolved during the 18th-19th century Developed (Pascal, Laplace and others) to serve the gambling industry. -

Common Quandaries and Their Practical Solutions in Bayesian Network Modeling
Ecological Modelling 358 (2017) 1–9 Contents lists available at ScienceDirect Ecological Modelling journa l homepage: www.elsevier.com/locate/ecolmodel Common quandaries and their practical solutions in Bayesian network modeling Bruce G. Marcot U.S. Forest Service, Pacific Northwest Research Station, 620 S.W. Main Street, Suite 400, Portland, OR, USA a r t i c l e i n f o a b s t r a c t Article history: Use and popularity of Bayesian network (BN) modeling has greatly expanded in recent years, but many Received 21 December 2016 common problems remain. Here, I summarize key problems in BN model construction and interpretation, Received in revised form 12 May 2017 along with suggested practical solutions. Problems in BN model construction include parameterizing Accepted 13 May 2017 probability values, variable definition, complex network structures, latent and confounding variables, Available online 24 May 2017 outlier expert judgments, variable correlation, model peer review, tests of calibration and validation, model overfitting, and modeling wicked problems. Problems in BN model interpretation include objec- Keywords: tive creep, misconstruing variable influence, conflating correlation with causation, conflating proportion Bayesian networks and expectation with probability, and using expert opinion. Solutions are offered for each problem and Modeling problems researchers are urged to innovate and share further solutions. Modeling solutions Bias Published by Elsevier B.V. Machine learning Expert knowledge 1. Introduction other fields. Although the number of generally accessible journal articles on BN modeling has continued to increase in recent years, Bayesian network (BN) models are essentially graphs of vari- achieving an exponential growth at least during the period from ables depicted and linked by probabilities (Koski and Noble, 2011). -
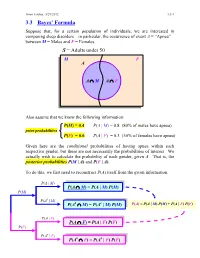
3.3 Bayes' Formula
Ismor Fischer, 5/29/2012 3.3-1 3.3 Bayes’ Formula Suppose that, for a certain population of individuals, we are interested in comparing sleep disorders – in particular, the occurrence of event A = “Apnea” – between M = Males and F = Females. S = Adults under 50 M F A A ∩ M A ∩ F Also assume that we know the following information: P(M) = 0.4 P(A | M) = 0.8 (80% of males have apnea) prior probabilities P(F) = 0.6 P(A | F) = 0.3 (30% of females have apnea) Given here are the conditional probabilities of having apnea within each respective gender, but these are not necessarily the probabilities of interest. We actually wish to calculate the probability of each gender, given A. That is, the posterior probabilities P(M | A) and P(F | A). To do this, we first need to reconstruct P(A) itself from the given information. P(A | M) P(A ∩ M) = P(A | M) P(M) P(M) P(Ac | M) c c P(A ∩ M) = P(A | M) P(M) P(A) = P(A | M) P(M) + P(A | F) P(F) P(A | F) P(A ∩ F) = P(A | F) P(F) P(F) P(Ac | F) c c P(A ∩ F) = P(A | F) P(F) Ismor Fischer, 5/29/2012 3.3-2 So, given A… P(M ∩ A) P(A | M) P(M) P(M | A) = P(A) = P(A | M) P(M) + P(A | F) P(F) (0.8)(0.4) 0.32 = (0.8)(0.4) + (0.3)(0.6) = 0.50 = 0.64 and posterior P(F ∩ A) P(A | F) P(F) P(F | A) = = probabilities P(A) P(A | M) P(M) + P(A | F) P(F) (0.3)(0.6) 0.18 = (0.8)(0.4) + (0.3)(0.6) = 0.50 = 0.36 S Thus, the additional information that a M F randomly selected individual has apnea (an A event with probability 50% – why?) increases the likelihood of being male from a prior probability of 40% to a posterior probability 0.32 0.18 of 64%, and likewise, decreases the likelihood of being female from a prior probability of 60% to a posterior probability of 36%. -

Section 7 Testing Hypotheses About Parameters of Normal Distribution. T-Tests and F-Tests
Section 7 Testing hypotheses about parameters of normal distribution. T-tests and F-tests. We will postpone a more systematic approach to hypotheses testing until the following lectures and in this lecture we will describe in an ad hoc way T-tests and F-tests about the parameters of normal distribution, since they are based on a very similar ideas to confidence intervals for parameters of normal distribution - the topic we have just covered. Suppose that we are given an i.i.d. sample from normal distribution N(µ, ν2) with some unknown parameters µ and ν2 : We will need to decide between two hypotheses about these unknown parameters - null hypothesis H0 and alternative hypothesis H1: Hypotheses H0 and H1 will be one of the following: H : µ = µ ; H : µ = µ ; 0 0 1 6 0 H : µ µ ; H : µ < µ ; 0 ∼ 0 1 0 H : µ µ ; H : µ > µ ; 0 ≈ 0 1 0 where µ0 is a given ’hypothesized’ parameter. We will also consider similar hypotheses about parameter ν2 : We want to construct a decision rule α : n H ; H X ! f 0 1g n that given an i.i.d. sample (X1; : : : ; Xn) either accepts H0 or rejects H0 (accepts H1). Null hypothesis is usually a ’main’ hypothesis2 X in a sense that it is expected or presumed to be true and we need a lot of evidence to the contrary to reject it. To quantify this, we pick a parameter � [0; 1]; called level of significance, and make sure that a decision rule α rejects H when it is2 actually true with probability �; i.e. -

The Composite Marginal Likelihood (CML) Inference Approach with Applications to Discrete and Mixed Dependent Variable Models
Technical Report 101 The Composite Marginal Likelihood (CML) Inference Approach with Applications to Discrete and Mixed Dependent Variable Models Chandra R. Bhat Center for Transportation Research September 2014 Data-Supported Transportation Operations & Planning Center (D-STOP) A Tier 1 USDOT University Transportation Center at The University of Texas at Austin D-STOP is a collaborative initiative by researchers at the Center for Transportation Research and the Wireless Networking and Communications Group at The University of Texas at Austin. DISCLAIMER The contents of this report reflect the views of the authors, who are responsible for the facts and the accuracy of the information presented herein. This document is disseminated under the sponsorship of the U.S. Department of Transportation’s University Transportation Centers Program, in the interest of information exchange. The U.S. Government assumes no liability for the contents or use thereof. Technical Report Documentation Page 1. Report No. 2. Government Accession No. 3. Recipient's Catalog No. D-STOP/2016/101 4. Title and Subtitle 5. Report Date The Composite Marginal Likelihood (CML) Inference Approach September 2014 with Applications to Discrete and Mixed Dependent Variable 6. Performing Organization Code Models 7. Author(s) 8. Performing Organization Report No. Chandra R. Bhat Report 101 9. Performing Organization Name and Address 10. Work Unit No. (TRAIS) Data-Supported Transportation Operations & Planning Center (D- STOP) 11. Contract or Grant No. The University of Texas at Austin DTRT13-G-UTC58 1616 Guadalupe Street, Suite 4.202 Austin, Texas 78701 12. Sponsoring Agency Name and Address 13. Type of Report and Period Covered Data-Supported Transportation Operations & Planning Center (D- STOP) The University of Texas at Austin 14. -

Bayesian Network Modelling with Examples
Bayesian Network Modelling with Examples Marco Scutari [email protected] Department of Statistics University of Oxford November 28, 2016 What Are Bayesian Networks? Marco Scutari University of Oxford What Are Bayesian Networks? A Graph and a Probability Distribution Bayesian networks (BNs) are defined by: a network structure, a directed acyclic graph G = (V;A), in which each node vi 2 V corresponds to a random variable Xi; a global probability distribution X with parameters Θ, which can be factorised into smaller local probability distributions according to the arcs aij 2 A present in the graph. The main role of the network structure is to express the conditional independence relationships among the variables in the model through graphical separation, thus specifying the factorisation of the global distribution: p Y P(X) = P(Xi j ΠXi ;ΘXi ) where ΠXi = fparents of Xig i=1 Marco Scutari University of Oxford What Are Bayesian Networks? How the DAG Maps to the Probability Distribution Graphical Probabilistic DAG separation independence A B C E D F Formally, the DAG is an independence map of the probability distribution of X, with graphical separation (??G) implying probabilistic independence (??P ). Marco Scutari University of Oxford What Are Bayesian Networks? Graphical Separation in DAGs (Fundamental Connections) separation (undirected graphs) A B C d-separation (directed acyclic graphs) A B C A B C A B C Marco Scutari University of Oxford What Are Bayesian Networks? Graphical Separation in DAGs (General Case) Now, in the general case we can extend the patterns from the fundamental connections and apply them to every possible path between A and B for a given C; this is how d-separation is defined.