Practical Statistics for Particle Physics Lecture 1 AEPS2018, Quy Nhon, Vietnam
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Bayesian Versus Frequentist Statistics for Uncertainty Analysis
- 1 - Disentangling Classical and Bayesian Approaches to Uncertainty Analysis Robin Willink1 and Rod White2 1email: [email protected] 2Measurement Standards Laboratory PO Box 31310, Lower Hutt 5040 New Zealand email(corresponding author): [email protected] Abstract Since the 1980s, we have seen a gradual shift in the uncertainty analyses recommended in the metrological literature, principally Metrologia, and in the BIPM’s guidance documents; the Guide to the Expression of Uncertainty in Measurement (GUM) and its two supplements. The shift has seen the BIPM’s recommendations change from a purely classical or frequentist analysis to a purely Bayesian analysis. Despite this drift, most metrologists continue to use the predominantly frequentist approach of the GUM and wonder what the differences are, why there are such bitter disputes about the two approaches, and should I change? The primary purpose of this note is to inform metrologists of the differences between the frequentist and Bayesian approaches and the consequences of those differences. It is often claimed that a Bayesian approach is philosophically consistent and is able to tackle problems beyond the reach of classical statistics. However, while the philosophical consistency of the of Bayesian analyses may be more aesthetically pleasing, the value to science of any statistical analysis is in the long-term success rates and on this point, classical methods perform well and Bayesian analyses can perform poorly. Thus an important secondary purpose of this note is to highlight some of the weaknesses of the Bayesian approach. We argue that moving away from well-established, easily- taught frequentist methods that perform well, to computationally expensive and numerically inferior Bayesian analyses recommended by the GUM supplements is ill-advised. -

This History of Modern Mathematical Statistics Retraces Their Development
BOOK REVIEWS GORROOCHURN Prakash, 2016, Classic Topics on the History of Modern Mathematical Statistics: From Laplace to More Recent Times, Hoboken, NJ, John Wiley & Sons, Inc., 754 p. This history of modern mathematical statistics retraces their development from the “Laplacean revolution,” as the author so rightly calls it (though the beginnings are to be found in Bayes’ 1763 essay(1)), through the mid-twentieth century and Fisher’s major contribution. Up to the nineteenth century the book covers the same ground as Stigler’s history of statistics(2), though with notable differences (see infra). It then discusses developments through the first half of the twentieth century: Fisher’s synthesis but also the renewal of Bayesian methods, which implied a return to Laplace. Part I offers an in-depth, chronological account of Laplace’s approach to probability, with all the mathematical detail and deductions he drew from it. It begins with his first innovative articles and concludes with his philosophical synthesis showing that all fields of human knowledge are connected to the theory of probabilities. Here Gorrouchurn raises a problem that Stigler does not, that of induction (pp. 102-113), a notion that gives us a better understanding of probability according to Laplace. The term induction has two meanings, the first put forward by Bacon(3) in 1620, the second by Hume(4) in 1748. Gorroochurn discusses only the second. For Bacon, induction meant discovering the principles of a system by studying its properties through observation and experimentation. For Hume, induction was mere enumeration and could not lead to certainty. Laplace followed Bacon: “The surest method which can guide us in the search for truth, consists in rising by induction from phenomena to laws and from laws to forces”(5). -
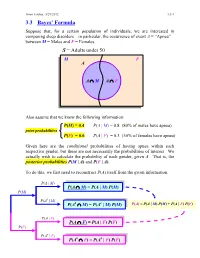
3.3 Bayes' Formula
Ismor Fischer, 5/29/2012 3.3-1 3.3 Bayes’ Formula Suppose that, for a certain population of individuals, we are interested in comparing sleep disorders – in particular, the occurrence of event A = “Apnea” – between M = Males and F = Females. S = Adults under 50 M F A A ∩ M A ∩ F Also assume that we know the following information: P(M) = 0.4 P(A | M) = 0.8 (80% of males have apnea) prior probabilities P(F) = 0.6 P(A | F) = 0.3 (30% of females have apnea) Given here are the conditional probabilities of having apnea within each respective gender, but these are not necessarily the probabilities of interest. We actually wish to calculate the probability of each gender, given A. That is, the posterior probabilities P(M | A) and P(F | A). To do this, we first need to reconstruct P(A) itself from the given information. P(A | M) P(A ∩ M) = P(A | M) P(M) P(M) P(Ac | M) c c P(A ∩ M) = P(A | M) P(M) P(A) = P(A | M) P(M) + P(A | F) P(F) P(A | F) P(A ∩ F) = P(A | F) P(F) P(F) P(Ac | F) c c P(A ∩ F) = P(A | F) P(F) Ismor Fischer, 5/29/2012 3.3-2 So, given A… P(M ∩ A) P(A | M) P(M) P(M | A) = P(A) = P(A | M) P(M) + P(A | F) P(F) (0.8)(0.4) 0.32 = (0.8)(0.4) + (0.3)(0.6) = 0.50 = 0.64 and posterior P(F ∩ A) P(A | F) P(F) P(F | A) = = probabilities P(A) P(A | M) P(M) + P(A | F) P(F) (0.3)(0.6) 0.18 = (0.8)(0.4) + (0.3)(0.6) = 0.50 = 0.36 S Thus, the additional information that a M F randomly selected individual has apnea (an A event with probability 50% – why?) increases the likelihood of being male from a prior probability of 40% to a posterior probability 0.32 0.18 of 64%, and likewise, decreases the likelihood of being female from a prior probability of 60% to a posterior probability of 36%. -

The Likelihood Principle
1 01/28/99 ãMarc Nerlove 1999 Chapter 1: The Likelihood Principle "What has now appeared is that the mathematical concept of probability is ... inadequate to express our mental confidence or diffidence in making ... inferences, and that the mathematical quantity which usually appears to be appropriate for measuring our order of preference among different possible populations does not in fact obey the laws of probability. To distinguish it from probability, I have used the term 'Likelihood' to designate this quantity; since both the words 'likelihood' and 'probability' are loosely used in common speech to cover both kinds of relationship." R. A. Fisher, Statistical Methods for Research Workers, 1925. "What we can find from a sample is the likelihood of any particular value of r [a parameter], if we define the likelihood as a quantity proportional to the probability that, from a particular population having that particular value of r, a sample having the observed value r [a statistic] should be obtained. So defined, probability and likelihood are quantities of an entirely different nature." R. A. Fisher, "On the 'Probable Error' of a Coefficient of Correlation Deduced from a Small Sample," Metron, 1:3-32, 1921. Introduction The likelihood principle as stated by Edwards (1972, p. 30) is that Within the framework of a statistical model, all the information which the data provide concerning the relative merits of two hypotheses is contained in the likelihood ratio of those hypotheses on the data. ...For a continuum of hypotheses, this principle -

People's Intuitions About Randomness and Probability
20 PEOPLE’S INTUITIONS ABOUT RANDOMNESS AND PROBABILITY: AN EMPIRICAL STUDY4 MARIE-PAULE LECOUTRE ERIS, Université de Rouen [email protected] KATIA ROVIRA Laboratoire Psy.Co, Université de Rouen [email protected] BRUNO LECOUTRE ERIS, C.N.R.S. et Université de Rouen [email protected] JACQUES POITEVINEAU ERIS, Université de Paris 6 et Ministère de la Culture [email protected] ABSTRACT What people mean by randomness should be taken into account when teaching statistical inference. This experiment explored subjective beliefs about randomness and probability through two successive tasks. Subjects were asked to categorize 16 familiar items: 8 real items from everyday life experiences, and 8 stochastic items involving a repeatable process. Three groups of subjects differing according to their background knowledge of probability theory were compared. An important finding is that the arguments used to judge if an event is random and those to judge if it is not random appear to be of different natures. While the concept of probability has been introduced to formalize randomness, a majority of individuals appeared to consider probability as a primary concept. Keywords: Statistics education research; Probability; Randomness; Bayesian Inference 1. INTRODUCTION In recent years Bayesian statistical practice has considerably evolved. Nowadays, the frequentist approach is increasingly challenged among scientists by the Bayesian proponents (see e.g., D’Agostini, 2000; Lecoutre, Lecoutre & Poitevineau, 2001; Jaynes, 2003). In applied statistics, “objective Bayesian techniques” (Berger, 2004) are now a promising alternative to the traditional frequentist statistical inference procedures (significance tests and confidence intervals). Subjective Bayesian analysis also has a role to play in scientific investigations (see e.g., Kadane, 1996). -

Numerical Physics with Probabilities: the Monte Carlo Method and Bayesian Statistics Part I for Assignment 2
Numerical Physics with Probabilities: The Monte Carlo Method and Bayesian Statistics Part I for Assignment 2 Department of Physics, University of Surrey module: Energy, Entropy and Numerical Physics (PHY2063) 1 Numerical Physics part of Energy, Entropy and Numerical Physics This numerical physics course is part of the second-year Energy, Entropy and Numerical Physics mod- ule. It is online at the EENP module on SurreyLearn. See there for assignments, deadlines etc. The course is about numerically solving ODEs (ordinary differential equations) and PDEs (partial differential equations), and introducing the (large) part of numerical physics where probabilities are used. This assignment is on numerical physics of probabilities, and looks at the Monte Carlo (MC) method, and at the Bayesian statistics approach to data analysis. It covers MC and Bayesian statistics, in that order. MC is a widely used numerical technique, it is used, amongst other things, for modelling many random processes. MC is used in fields from statistical physics, to nuclear and particle physics. Bayesian statistics is a powerful data analysis method, and is used everywhere from particle physics to spam-email filters. Data analysis is fundamental to science. For example, analysis of the data from the Large Hadron Collider was required to extract a most probable value for the mass of the Higgs boson, together with an estimate of the region of masses where the scientists think the mass is. This region is typically expressed as a range of mass values where the they think the true mass lies with high (e.g., 95%) probability. Many of you will be analysing data (physics data, commercial data, etc) for your PTY or RY, or future careers1 . -

The Bayesian Approach to Statistics
THE BAYESIAN APPROACH TO STATISTICS ANTHONY O’HAGAN INTRODUCTION the true nature of scientific reasoning. The fi- nal section addresses various features of modern By far the most widely taught and used statisti- Bayesian methods that provide some explanation for the rapid increase in their adoption since the cal methods in practice are those of the frequen- 1980s. tist school. The ideas of frequentist inference, as set out in Chapter 5 of this book, rest on the frequency definition of probability (Chapter 2), BAYESIAN INFERENCE and were developed in the first half of the 20th century. This chapter concerns a radically differ- We first present the basic procedures of Bayesian ent approach to statistics, the Bayesian approach, inference. which depends instead on the subjective defini- tion of probability (Chapter 3). In some respects, Bayesian methods are older than frequentist ones, Bayes’s Theorem and the Nature of Learning having been the basis of very early statistical rea- Bayesian inference is a process of learning soning as far back as the 18th century. Bayesian from data. To give substance to this statement, statistics as it is now understood, however, dates we need to identify who is doing the learning and back to the 1950s, with subsequent development what they are learning about. in the second half of the 20th century. Over that time, the Bayesian approach has steadily gained Terms and Notation ground, and is now recognized as a legitimate al- ternative to the frequentist approach. The person doing the learning is an individual This chapter is organized into three sections. -

The Interplay of Bayesian and Frequentist Analysis M.J.Bayarriandj.O.Berger
Statistical Science 2004, Vol. 19, No. 1, 58–80 DOI 10.1214/088342304000000116 © Institute of Mathematical Statistics, 2004 The Interplay of Bayesian and Frequentist Analysis M.J.BayarriandJ.O.Berger Abstract. Statistics has struggled for nearly a century over the issue of whether the Bayesian or frequentist paradigm is superior. This debate is far from over and, indeed, should continue, since there are fundamental philosophical and pedagogical issues at stake. At the methodological level, however, the debate has become considerably muted, with the recognition that each approach has a great deal to contribute to statistical practice and each is actually essential for full development of the other approach. In this article, we embark upon a rather idiosyncratic walk through some of these issues. Key words and phrases: Admissibility, Bayesian model checking, condi- tional frequentist, confidence intervals, consistency, coverage, design, hierar- chical models, nonparametric Bayes, objective Bayesian methods, p-values, reference priors, testing. CONTENTS 5. Areas of current disagreement 6. Conclusions 1. Introduction Acknowledgments 2. Inherently joint Bayesian–frequentist situations References 2.1. Design or preposterior analysis 2.2. The meaning of frequentism 2.3. Empirical Bayes, gamma minimax, restricted risk 1. INTRODUCTION Bayes Statisticians should readily use both Bayesian and 3. Estimation and confidence intervals frequentist ideas. In Section 2 we discuss situations 3.1. Computation with hierarchical, multilevel or mixed in which simultaneous frequentist and Bayesian think- model analysis ing is essentially required. For the most part, how- 3.2. Assessment of accuracy of estimation ever, the situations we discuss are situations in which 3.3. Foundations, minimaxity and exchangeability 3.4. -

Paradoxes and Priors in Bayesian Regression
Paradoxes and Priors in Bayesian Regression Dissertation Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Agniva Som, B. Stat., M. Stat. Graduate Program in Statistics The Ohio State University 2014 Dissertation Committee: Dr. Christopher M. Hans, Advisor Dr. Steven N. MacEachern, Co-advisor Dr. Mario Peruggia c Copyright by Agniva Som 2014 Abstract The linear model has been by far the most popular and most attractive choice of a statistical model over the past century, ubiquitous in both frequentist and Bayesian literature. The basic model has been gradually improved over the years to deal with stronger features in the data like multicollinearity, non-linear or functional data pat- terns, violation of underlying model assumptions etc. One valuable direction pursued in the enrichment of the linear model is the use of Bayesian methods, which blend information from the data likelihood and suitable prior distributions placed on the unknown model parameters to carry out inference. This dissertation studies the modeling implications of many common prior distri- butions in linear regression, including the popular g prior and its recent ameliorations. Formalization of desirable characteristics for model comparison and parameter esti- mation has led to the growth of appropriate mixtures of g priors that conform to the seven standard model selection criteria laid out by Bayarri et al. (2012). The existence of some of these properties (or lack thereof) is demonstrated by examining the behavior of the prior under suitable limits on the likelihood or on the prior itself. -

Frequentism-As-Model
Frequentism-as-model Christian Hennig, Dipartimento di Scienze Statistiche, Universita die Bologna, Via delle Belle Arti, 41, 40126 Bologna [email protected] July 14, 2020 Abstract: Most statisticians are aware that probability models interpreted in a frequentist manner are not really true in objective reality, but only idealisations. I argue that this is often ignored when actually applying frequentist methods and interpreting the results, and that keeping up the awareness for the essential difference between reality and models can lead to a more appropriate use and in- terpretation of frequentist models and methods, called frequentism-as-model. This is elaborated showing connections to existing work, appreciating the special role of i.i.d. models and subject matter knowledge, giving an account of how and under what conditions models that are not true can be useful, giving detailed interpreta- tions of tests and confidence intervals, confronting their implicit compatibility logic with the inverse probability logic of Bayesian inference, re-interpreting the role of model assumptions, appreciating robustness, and the role of “interpretative equiv- alence” of models. Epistemic (often referred to as Bayesian) probability shares the issue that its models are only idealisations and not really true for modelling reasoning about uncertainty, meaning that it does not have an essential advantage over frequentism, as is often claimed. Bayesian statistics can be combined with frequentism-as-model, leading to what Gelman and Hennig (2017) call “falsifica- arXiv:2007.05748v1 [stat.OT] 11 Jul 2020 tionist Bayes”. Key Words: foundations of statistics, Bayesian statistics, interpretational equiv- alence, compatibility logic, inverse probability logic, misspecification testing, sta- bility, robustness 1 Introduction The frequentist interpretation of probability and frequentist inference such as hy- pothesis tests and confidence intervals have been strongly criticised recently (e.g., Hajek (2009); Diaconis and Skyrms (2018); Wasserstein et al. -

The P–T Probability Framework for Semantic Communication, Falsification, Confirmation, and Bayesian Reasoning
philosophies Article The P–T Probability Framework for Semantic Communication, Falsification, Confirmation, and Bayesian Reasoning Chenguang Lu School of Computer Engineering and Applied Mathematics, Changsha University, Changsha 410003, China; [email protected] Received: 8 July 2020; Accepted: 16 September 2020; Published: 2 October 2020 Abstract: Many researchers want to unify probability and logic by defining logical probability or probabilistic logic reasonably. This paper tries to unify statistics and logic so that we can use both statistical probability and logical probability at the same time. For this purpose, this paper proposes the P–T probability framework, which is assembled with Shannon’s statistical probability framework for communication, Kolmogorov’s probability axioms for logical probability, and Zadeh’s membership functions used as truth functions. Two kinds of probabilities are connected by an extended Bayes’ theorem, with which we can convert a likelihood function and a truth function from one to another. Hence, we can train truth functions (in logic) by sampling distributions (in statistics). This probability framework was developed in the author’s long-term studies on semantic information, statistical learning, and color vision. This paper first proposes the P–T probability framework and explains different probabilities in it by its applications to semantic information theory. Then, this framework and the semantic information methods are applied to statistical learning, statistical mechanics, hypothesis evaluation (including falsification), confirmation, and Bayesian reasoning. Theoretical applications illustrate the reasonability and practicability of this framework. This framework is helpful for interpretable AI. To interpret neural networks, we need further study. Keywords: statistical probability; logical probability; semantic information; rate-distortion; Boltzmann distribution; falsification; verisimilitude; confirmation measure; Raven Paradox; Bayesian reasoning 1. -

A Widely Applicable Bayesian Information Criterion
JournalofMachineLearningResearch14(2013)867-897 Submitted 8/12; Revised 2/13; Published 3/13 A Widely Applicable Bayesian Information Criterion Sumio Watanabe [email protected] Department of Computational Intelligence and Systems Science Tokyo Institute of Technology Mailbox G5-19, 4259 Nagatsuta, Midori-ku Yokohama, Japan 226-8502 Editor: Manfred Opper Abstract A statistical model or a learning machine is called regular if the map taking a parameter to a prob- ability distribution is one-to-one and if its Fisher information matrix is always positive definite. If otherwise, it is called singular. In regular statistical models, the Bayes free energy, which is defined by the minus logarithm of Bayes marginal likelihood, can be asymptotically approximated by the Schwarz Bayes information criterion (BIC), whereas in singular models such approximation does not hold. Recently, it was proved that the Bayes free energy of a singular model is asymptotically given by a generalized formula using a birational invariant, the real log canonical threshold (RLCT), instead of half the number of parameters in BIC. Theoretical values of RLCTs in several statistical models are now being discovered based on algebraic geometrical methodology. However, it has been difficult to estimate the Bayes free energy using only training samples, because an RLCT depends on an unknown true distribution. In the present paper, we define a widely applicable Bayesian information criterion (WBIC) by the average log likelihood function over the posterior distribution with the inverse temperature 1/logn, where n is the number of training samples. We mathematically prove that WBIC has the same asymptotic expansion as the Bayes free energy, even if a statistical model is singular for or unrealizable by a statistical model.