Marginal Likelihood
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Practical Statistics for Particle Physics Lecture 1 AEPS2018, Quy Nhon, Vietnam
Practical Statistics for Particle Physics Lecture 1 AEPS2018, Quy Nhon, Vietnam Roger Barlow The University of Huddersfield August 2018 Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 1 / 34 Lecture 1: The Basics 1 Probability What is it? Frequentist Probability Conditional Probability and Bayes' Theorem Bayesian Probability 2 Probability distributions and their properties Expectation Values Binomial, Poisson and Gaussian 3 Hypothesis testing Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 2 / 34 Question: What is Probability? Typical exam question Q1 Explain what is meant by the Probability PA of an event A [1] Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 3 / 34 Four possible answers PA is number obeying certain mathematical rules. PA is a property of A that determines how often A happens For N trials in which A occurs NA times, PA is the limit of NA=N for large N PA is my belief that A will happen, measurable by seeing what odds I will accept in a bet. Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 4 / 34 Mathematical Kolmogorov Axioms: For all A ⊂ S PA ≥ 0 PS = 1 P(A[B) = PA + PB if A \ B = ϕ and A; B ⊂ S From these simple axioms a complete and complicated structure can be − ≤ erected. E.g. show PA = 1 PA, and show PA 1.... But!!! This says nothing about what PA actually means. Kolmogorov had frequentist probability in mind, but these axioms apply to any definition. Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 5 / 34 Classical or Real probability Evolved during the 18th-19th century Developed (Pascal, Laplace and others) to serve the gambling industry. -
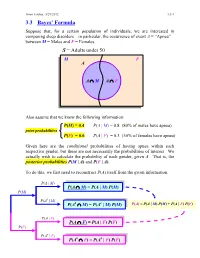
3.3 Bayes' Formula
Ismor Fischer, 5/29/2012 3.3-1 3.3 Bayes’ Formula Suppose that, for a certain population of individuals, we are interested in comparing sleep disorders – in particular, the occurrence of event A = “Apnea” – between M = Males and F = Females. S = Adults under 50 M F A A ∩ M A ∩ F Also assume that we know the following information: P(M) = 0.4 P(A | M) = 0.8 (80% of males have apnea) prior probabilities P(F) = 0.6 P(A | F) = 0.3 (30% of females have apnea) Given here are the conditional probabilities of having apnea within each respective gender, but these are not necessarily the probabilities of interest. We actually wish to calculate the probability of each gender, given A. That is, the posterior probabilities P(M | A) and P(F | A). To do this, we first need to reconstruct P(A) itself from the given information. P(A | M) P(A ∩ M) = P(A | M) P(M) P(M) P(Ac | M) c c P(A ∩ M) = P(A | M) P(M) P(A) = P(A | M) P(M) + P(A | F) P(F) P(A | F) P(A ∩ F) = P(A | F) P(F) P(F) P(Ac | F) c c P(A ∩ F) = P(A | F) P(F) Ismor Fischer, 5/29/2012 3.3-2 So, given A… P(M ∩ A) P(A | M) P(M) P(M | A) = P(A) = P(A | M) P(M) + P(A | F) P(F) (0.8)(0.4) 0.32 = (0.8)(0.4) + (0.3)(0.6) = 0.50 = 0.64 and posterior P(F ∩ A) P(A | F) P(F) P(F | A) = = probabilities P(A) P(A | M) P(M) + P(A | F) P(F) (0.3)(0.6) 0.18 = (0.8)(0.4) + (0.3)(0.6) = 0.50 = 0.36 S Thus, the additional information that a M F randomly selected individual has apnea (an A event with probability 50% – why?) increases the likelihood of being male from a prior probability of 40% to a posterior probability 0.32 0.18 of 64%, and likewise, decreases the likelihood of being female from a prior probability of 60% to a posterior probability of 36%. -

The Composite Marginal Likelihood (CML) Inference Approach with Applications to Discrete and Mixed Dependent Variable Models
Technical Report 101 The Composite Marginal Likelihood (CML) Inference Approach with Applications to Discrete and Mixed Dependent Variable Models Chandra R. Bhat Center for Transportation Research September 2014 Data-Supported Transportation Operations & Planning Center (D-STOP) A Tier 1 USDOT University Transportation Center at The University of Texas at Austin D-STOP is a collaborative initiative by researchers at the Center for Transportation Research and the Wireless Networking and Communications Group at The University of Texas at Austin. DISCLAIMER The contents of this report reflect the views of the authors, who are responsible for the facts and the accuracy of the information presented herein. This document is disseminated under the sponsorship of the U.S. Department of Transportation’s University Transportation Centers Program, in the interest of information exchange. The U.S. Government assumes no liability for the contents or use thereof. Technical Report Documentation Page 1. Report No. 2. Government Accession No. 3. Recipient's Catalog No. D-STOP/2016/101 4. Title and Subtitle 5. Report Date The Composite Marginal Likelihood (CML) Inference Approach September 2014 with Applications to Discrete and Mixed Dependent Variable 6. Performing Organization Code Models 7. Author(s) 8. Performing Organization Report No. Chandra R. Bhat Report 101 9. Performing Organization Name and Address 10. Work Unit No. (TRAIS) Data-Supported Transportation Operations & Planning Center (D- STOP) 11. Contract or Grant No. The University of Texas at Austin DTRT13-G-UTC58 1616 Guadalupe Street, Suite 4.202 Austin, Texas 78701 12. Sponsoring Agency Name and Address 13. Type of Report and Period Covered Data-Supported Transportation Operations & Planning Center (D- STOP) The University of Texas at Austin 14. -

Numerical Physics with Probabilities: the Monte Carlo Method and Bayesian Statistics Part I for Assignment 2
Numerical Physics with Probabilities: The Monte Carlo Method and Bayesian Statistics Part I for Assignment 2 Department of Physics, University of Surrey module: Energy, Entropy and Numerical Physics (PHY2063) 1 Numerical Physics part of Energy, Entropy and Numerical Physics This numerical physics course is part of the second-year Energy, Entropy and Numerical Physics mod- ule. It is online at the EENP module on SurreyLearn. See there for assignments, deadlines etc. The course is about numerically solving ODEs (ordinary differential equations) and PDEs (partial differential equations), and introducing the (large) part of numerical physics where probabilities are used. This assignment is on numerical physics of probabilities, and looks at the Monte Carlo (MC) method, and at the Bayesian statistics approach to data analysis. It covers MC and Bayesian statistics, in that order. MC is a widely used numerical technique, it is used, amongst other things, for modelling many random processes. MC is used in fields from statistical physics, to nuclear and particle physics. Bayesian statistics is a powerful data analysis method, and is used everywhere from particle physics to spam-email filters. Data analysis is fundamental to science. For example, analysis of the data from the Large Hadron Collider was required to extract a most probable value for the mass of the Higgs boson, together with an estimate of the region of masses where the scientists think the mass is. This region is typically expressed as a range of mass values where the they think the true mass lies with high (e.g., 95%) probability. Many of you will be analysing data (physics data, commercial data, etc) for your PTY or RY, or future careers1 . -

The Bayesian Approach to Statistics
THE BAYESIAN APPROACH TO STATISTICS ANTHONY O’HAGAN INTRODUCTION the true nature of scientific reasoning. The fi- nal section addresses various features of modern By far the most widely taught and used statisti- Bayesian methods that provide some explanation for the rapid increase in their adoption since the cal methods in practice are those of the frequen- 1980s. tist school. The ideas of frequentist inference, as set out in Chapter 5 of this book, rest on the frequency definition of probability (Chapter 2), BAYESIAN INFERENCE and were developed in the first half of the 20th century. This chapter concerns a radically differ- We first present the basic procedures of Bayesian ent approach to statistics, the Bayesian approach, inference. which depends instead on the subjective defini- tion of probability (Chapter 3). In some respects, Bayesian methods are older than frequentist ones, Bayes’s Theorem and the Nature of Learning having been the basis of very early statistical rea- Bayesian inference is a process of learning soning as far back as the 18th century. Bayesian from data. To give substance to this statement, statistics as it is now understood, however, dates we need to identify who is doing the learning and back to the 1950s, with subsequent development what they are learning about. in the second half of the 20th century. Over that time, the Bayesian approach has steadily gained Terms and Notation ground, and is now recognized as a legitimate al- ternative to the frequentist approach. The person doing the learning is an individual This chapter is organized into three sections. -

Paradoxes and Priors in Bayesian Regression
Paradoxes and Priors in Bayesian Regression Dissertation Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Agniva Som, B. Stat., M. Stat. Graduate Program in Statistics The Ohio State University 2014 Dissertation Committee: Dr. Christopher M. Hans, Advisor Dr. Steven N. MacEachern, Co-advisor Dr. Mario Peruggia c Copyright by Agniva Som 2014 Abstract The linear model has been by far the most popular and most attractive choice of a statistical model over the past century, ubiquitous in both frequentist and Bayesian literature. The basic model has been gradually improved over the years to deal with stronger features in the data like multicollinearity, non-linear or functional data pat- terns, violation of underlying model assumptions etc. One valuable direction pursued in the enrichment of the linear model is the use of Bayesian methods, which blend information from the data likelihood and suitable prior distributions placed on the unknown model parameters to carry out inference. This dissertation studies the modeling implications of many common prior distri- butions in linear regression, including the popular g prior and its recent ameliorations. Formalization of desirable characteristics for model comparison and parameter esti- mation has led to the growth of appropriate mixtures of g priors that conform to the seven standard model selection criteria laid out by Bayarri et al. (2012). The existence of some of these properties (or lack thereof) is demonstrated by examining the behavior of the prior under suitable limits on the likelihood or on the prior itself. -

A Widely Applicable Bayesian Information Criterion
JournalofMachineLearningResearch14(2013)867-897 Submitted 8/12; Revised 2/13; Published 3/13 A Widely Applicable Bayesian Information Criterion Sumio Watanabe [email protected] Department of Computational Intelligence and Systems Science Tokyo Institute of Technology Mailbox G5-19, 4259 Nagatsuta, Midori-ku Yokohama, Japan 226-8502 Editor: Manfred Opper Abstract A statistical model or a learning machine is called regular if the map taking a parameter to a prob- ability distribution is one-to-one and if its Fisher information matrix is always positive definite. If otherwise, it is called singular. In regular statistical models, the Bayes free energy, which is defined by the minus logarithm of Bayes marginal likelihood, can be asymptotically approximated by the Schwarz Bayes information criterion (BIC), whereas in singular models such approximation does not hold. Recently, it was proved that the Bayes free energy of a singular model is asymptotically given by a generalized formula using a birational invariant, the real log canonical threshold (RLCT), instead of half the number of parameters in BIC. Theoretical values of RLCTs in several statistical models are now being discovered based on algebraic geometrical methodology. However, it has been difficult to estimate the Bayes free energy using only training samples, because an RLCT depends on an unknown true distribution. In the present paper, we define a widely applicable Bayesian information criterion (WBIC) by the average log likelihood function over the posterior distribution with the inverse temperature 1/logn, where n is the number of training samples. We mathematically prove that WBIC has the same asymptotic expansion as the Bayes free energy, even if a statistical model is singular for or unrealizable by a statistical model. -

Part IV: Monte Carlo and Nonparametric Bayes Outline
Part IV: Monte Carlo and nonparametric Bayes Outline Monte Carlo methods Nonparametric Bayesian models Outline Monte Carlo methods Nonparametric Bayesian models The Monte Carlo principle • The expectation of f with respect to P can be approximated by 1 n E P(x)[ f (x)] " # f (xi ) n i=1 where the xi are sampled from P(x) • Example: the average # of spots on a die roll ! The Monte Carlo principle The law of large numbers n E P(x)[ f (x)] " # f (xi ) i=1 Average number of spots ! Number of rolls Two uses of Monte Carlo methods 1. For solving problems of probabilistic inference involved in developing computational models 2. As a source of hypotheses about how the mind might solve problems of probabilistic inference Making Bayesian inference easier P(d | h)P(h) P(h | d) = $P(d | h ") P(h ") h " # H Evaluating the posterior probability of a hypothesis requires considering all hypotheses ! Modern Monte Carlo methods let us avoid this Modern Monte Carlo methods • Sampling schemes for distributions with large state spaces known up to a multiplicative constant • Two approaches: – importance sampling (and particle filters) – Markov chain Monte Carlo Importance sampling Basic idea: generate from the wrong distribution, assign weights to samples to correct for this E p(x)[ f (x)] = " f (x)p(x)dx p(x) = f (x) q(x)dx " q(x) n ! 1 p(xi ) " # f (xi ) for xi ~ q(x) n i=1 q(xi ) ! ! Importance sampling works when sampling from proposal is easy, target is hard An alternative scheme… n 1 p(xi ) E p(x)[ f (x)] " # f (xi ) for xi ~ q(x) n i=1 q(xi ) n p(xi -

Categorical Distributions in Natural Language Processing Version 0.1
Categorical Distributions in Natural Language Processing Version 0.1 MURAWAKI Yugo 12 May 2016 MURAWAKI Yugo Categorical Distributions in NLP 1 / 34 Categorical distribution Suppose random variable x takes one of K values. x is generated according to categorical distribution Cat(θ), where θ = (0:1; 0:6; 0:3): RYG In many task settings, we do not know the true θ and need to infer it from observed data x = (x1; ··· ; xN). Once we infer θ, we often want to predict new variable x0. NOTE: In Bayesian settings, θ is usually integrated out and x0 is predicted directly from x. MURAWAKI Yugo Categorical Distributions in NLP 2 / 34 Categorical distributions are a building block of natural language models N-gram language model (predicting the next word) POS tagging based on a Hidden Markov Model (HMM) Probabilistic context-free grammar (PCFG) Topic model (Latent Dirichlet Allocation (LDA)) MURAWAKI Yugo Categorical Distributions in NLP 3 / 34 Example: HMM-based POS tagging BOS DT NN VBZ VBN EOS the sun has risen Let K be the number of POS tags and V be the vocabulary size (ignore BOS and EOS for simplicity). The transition probabilities can be computed using K categorical θTRANS; θTRANS; ··· distributions ( DT NN ), with the dimension K. θTRANS = : ; : ; : ; ··· DT (0 21 0 27 0 09 ) NN NNS ADJ Similarly, the emission probabilities can be computed using K θEMIT; θEMIT; ··· categorical distributions ( DT NN ), with the dimension V. θEMIT = : ; : ; : ; ··· NN (0 012 0 002 0 005 ) sun rose cat MURAWAKI Yugo Categorical Distributions in NLP 4 / 34 Outline Categorical and multinomial distributions Conjugacy and posterior predictive distribution LDA (Latent Dirichlet Applocation) as an application Gibbs sampling for inference MURAWAKI Yugo Categorical Distributions in NLP 5 / 34 Categorical distribution: 1 observation Suppose θ is known. -

Binomial and Multinomial Distributions
Binomial and multinomial distributions Kevin P. Murphy Last updated October 24, 2006 * Denotes more advanced sections 1 Introduction In this chapter, we study probability distributions that are suitable for modelling discrete data, like letters and words. This will be useful later when we consider such tasks as classifying and clustering documents, recognizing and segmenting languages and DNA sequences, data compression, etc. Formally, we will be concerned with density models for X ∈{1,...,K}, where K is the number of possible values for X; we can think of this as the number of symbols/ letters in our alphabet/ language. We assume that K is known, and that the values of X are unordered: this is called categorical data, as opposed to ordinal data, in which the discrete states can be ranked (e.g., low, medium and high). If K = 2 (e.g., X represents heads or tails), we will use a binomial distribution. If K > 2, we will use a multinomial distribution. 2 Bernoullis and Binomials Let X ∈{0, 1} be a binary random variable (e.g., a coin toss). Suppose p(X =1)= θ. Then − p(X|θ) = Be(X|θ)= θX (1 − θ)1 X (1) is called a Bernoulli distribution. It is easy to show that E[X] = p(X =1)= θ (2) Var [X] = θ(1 − θ) (3) The likelihood for a sequence D = (x1,...,xN ) of coin tosses is N − p(D|θ)= θxn (1 − θ)1 xn = θN1 (1 − θ)N0 (4) n=1 Y N N where N1 = n=1 xn is the number of heads (X = 1) and N0 = n=1(1 − xn)= N − N1 is the number of tails (X = 0). -

Bayesian Monte Carlo
Bayesian Monte Carlo Carl Edward Rasmussen and Zoubin Ghahramani Gatsby Computational Neuroscience Unit University College London 17 Queen Square, London WC1N 3AR, England edward,[email protected] http://www.gatsby.ucl.ac.uk Abstract We investigate Bayesian alternatives to classical Monte Carlo methods for evaluating integrals. Bayesian Monte Carlo (BMC) allows the in- corporation of prior knowledge, such as smoothness of the integrand, into the estimation. In a simple problem we show that this outperforms any classical importance sampling method. We also attempt more chal- lenging multidimensional integrals involved in computing marginal like- lihoods of statistical models (a.k.a. partition functions and model evi- dences). We find that Bayesian Monte Carlo outperformed Annealed Importance Sampling, although for very high dimensional problems or problems with massive multimodality BMC may be less adequate. One advantage of the Bayesian approach to Monte Carlo is that samples can be drawn from any distribution. This allows for the possibility of active design of sample points so as to maximise information gain. 1 Introduction Inference in most interesting machine learning algorithms is not computationally tractable, and is solved using approximations. This is particularly true for Bayesian models which require evaluation of complex multidimensional integrals. Both analytical approximations, such as the Laplace approximation and variational methods, and Monte Carlo methods have recently been used widely for Bayesian machine learning problems. It is interesting to note that Monte Carlo itself is a purely frequentist procedure [O’Hagan, 1987; MacKay, 1999]. This leads to several inconsistencies which we review below, outlined in a paper by O’Hagan [1987] with the title “Monte Carlo is Fundamentally Unsound”. -

Bayesian Inference
Bayesian Inference Thomas Nichols With thanks Lee Harrison Bayesian segmentation Spatial priors Posterior probability Dynamic Causal and normalisation on activation extent maps (PPMs) Modelling Attention to Motion Paradigm Results SPC V3A V5+ Attention – No attention Büchel & Friston 1997, Cereb. Cortex Büchel et al. 1998, Brain - fixation only - observe static dots + photic V1 - observe moving dots + motion V5 - task on moving dots + attention V5 + parietal cortex Attention to Motion Paradigm Dynamic Causal Models Model 1 (forward): Model 2 (backward): attentional modulation attentional modulation of V1→V5: forward of SPC→V5: backward Photic SPC Attention Photic SPC V1 V1 - fixation only V5 - observe static dots V5 - observe moving dots Motion Motion - task on moving dots Attention Bayesian model selection: Which model is optimal? Responses to Uncertainty Long term memory Short term memory Responses to Uncertainty Paradigm Stimuli sequence of randomly sampled discrete events Model simple computational model of an observers response to uncertainty based on the number of past events (extent of memory) 1 2 3 4 Question which regions are best explained by short / long term memory model? … 1 2 40 trials ? ? Overview • Introductory remarks • Some probability densities/distributions • Probabilistic (generative) models • Bayesian inference • A simple example – Bayesian linear regression • SPM applications – Segmentation – Dynamic causal modeling – Spatial models of fMRI time series Probability distributions and densities k=2 Probability distributions