Computational Models of Music Similarity and Their Applications In
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
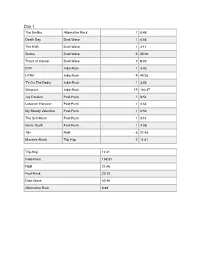
Lab Data.Pages
Day 1 The Smiths Alternative Rock 1 6:48 Death Day Dark Wave 1 4:56 The KVB Dark Wave 1 4:11 Suuns Dark Wave 6 35:00 Tropic of Cancer Dark Wave 2 8:09 DIIV Indie Rock 1 3:43 HTRK Indie Rock 9 40:35 TV On The Radio Indie Rock 1 3:26 Warpaint Indie Rock 19 110:47 Joy Division Post-Punk 1 3:54 Lebanon Hanover Post-Punk 1 4:53 My Bloody Valentine Post-Punk 1 6:59 The Soft Moon Post-Punk 1 3:14 Sonic Youth Post-Punk 1 4:08 18+ R&B 6 21:46 Massive Attack Trip Hop 2 11:41 Trip-Hop 11:41 Indie Rock 158:31 R&B 21:46 Post-Punk 22:15 Dark Wave 52:16 Alternative Rock 6:48 Day 2 Blonde Redhead Alternative Rock 1 5:19 Mazzy Star Alternative Rock 1 4:51 Pixies Alternative Rock 1 3:31 Radiohead Alternative Rock 1 3:54 The Smashing Alternative Rock 1 4:26 Pumpkins The Stone Roses Alternative Rock 1 4:53 Alabama Shakes Blues Rock 3 12:05 Suuns Dark Wave 2 9:37 Tropic of Cancer Dark Wave 1 3:48 Com Truise Electronic 2 7:29 Les Sins Electronic 1 5:18 A Tribe Called Quest Hip Hop 1 4:04 Best Coast Indie Pop 1 2:07 The Drums Indie Pop 2 6:48 Future Islands Indie Pop 1 3:46 The Go! Team Indie Pop 1 4:15 Mr Twin Sister Indie Pop 3 12:27 Toro y Moi Indie Pop 1 2:28 Twin Sister Indie Pop 2 7:21 Washed Out Indie Pop 1 3:15 The xx Indie Pop 1 2:57 Blood Orange Indie Rock 6 27:34 Cherry Glazerr Indie Rock 6 21:14 Deerhunter Indie Rock 2 11:42 Destroyer Indie Rock 1 6:18 DIIV Indie Rock 1 3:33 Kurt Vile Indie Rock 1 6:19 Real Estate Indie Rock 2 10:38 The Soft Pack Indie Rock 1 3:52 Warpaint Indie Rock 1 4:45 The Jesus and Mary Post-Punk 1 3:02 Chain Joy Division Post-Punk -

Nqiefecta the Brink of Super Stardom
NEWSSTAND PRICE S6.50 JULY 16, 2004 Universal Scores Big Four Universal Records lands the No. 1 song this week on tour R &R charts, with JoJo's "Leave (Get Out)" at CHR/Pop: Juvenile's "Slow A New Lifestyle Motion" at CHR/ R &R AC Editor Julie Kertes nas assembled this year's AC Rhythmic and Urban; special, AC Lifestyles. It contains WLTW/New York PD Jim and the big comeback Ryan's advice on how to attract younger women, articles from R &B diva Teena by consultant Gary Berkowitz and the RAB's Dolores Nolan Marie, "Still in Love," and an interview with John Tesh. It all begins on at Urban AC. the next page. Emotion surges through when slie sings, a floodffeelin so.: owerful that first-time- listeners ; d music :it dusty v vethans, Often d their ja4's dropping and tearOisit Há > u MAJ. "JD Nato.Natasha is ntakingheads turn in the music industry . A. she on nqiefecta the brink of super stardom . ." CBS ¿ews ÌN 9TOfiS NOW.! !Thisiover-night sensation is on -, re "Lágrimas" IS ON ROTION ÁT tö'fatne and fortune ..." ); AB en'c' WPAT WXYX , '° KOMM -w "I think she lias the most KLVE KEMR ' enchanting voice, and is bou - J bA =IUKIE KLQV t be the best female pop artist f J RIA moment. She has the potential of -,: VIV KLNV WZCH being a much better. Britney r'i4alE WRMD !MY Spears, since she masters both the VO KR English and Spanish langua " J! r . C . Tony Campos, Pro amining Dir !ur or . -

Chance the Rapper's Creation of a New Community of Christian
Bates College SCARAB Honors Theses Capstone Projects 5-2020 “Your Favorite Rapper’s a Christian Rapper”: Chance the Rapper’s Creation of a New Community of Christian Hip Hop Through His Use of Religious Discourse on the 2016 Mixtape Coloring Book Samuel Patrick Glenn [email protected] Follow this and additional works at: https://scarab.bates.edu/honorstheses Recommended Citation Glenn, Samuel Patrick, "“Your Favorite Rapper’s a Christian Rapper”: Chance the Rapper’s Creation of a New Community of Christian Hip Hop Through His Use of Religious Discourse on the 2016 Mixtape Coloring Book" (2020). Honors Theses. 336. https://scarab.bates.edu/honorstheses/336 This Open Access is brought to you for free and open access by the Capstone Projects at SCARAB. It has been accepted for inclusion in Honors Theses by an authorized administrator of SCARAB. For more information, please contact [email protected]. “Your Favorite Rapper’s a Christian Rapper”: Chance the Rapper’s Creation of a New Community of Christian Hip Hop Through His Use of Religious Discourse on the 2016 Mixtape Coloring Book An Honors Thesis Presented to The Faculty of the Religious Studies Department Bates College in partial fulfillment of the requirements for the Degree of Bachelor of Arts By Samuel Patrick Glenn Lewiston, Maine March 30 2020 Acknowledgements I would first like to acknowledge my thesis advisor, Professor Marcus Bruce, for his never-ending support, interest, and positivity in this project. You have supported me through the lows and the highs. You have endlessly made sacrifices for myself and this project and I cannot express my thanks enough. -

AUSTRALIAN SINGLES REPORT 19Th December, 2016 Compiled by the Music Network© FREE SIGN UP
AUSTRALIAN SINGLES REPORT 19th December, 2016 Compiled by The Music Network© FREE SIGN UP ARTIST TOP 50 Combines airplay, downloads & streams #1 SINGLE ACROSS AUSTRALIA Starboy 1 The Weeknd | UMA starboy Rockabye The Weeknd ft. Daft Punk | UMA 2 Clean Bandit | WMA Say You Won't Let Go 3 James Arthur | SME Riding the year out at #1 on the Artist Top 50 is The Weeknd’s undeniable hit Starboy ft. Daft Punk. Black Beatles Overtaking Clean Bandit’s Rockabye ft. Sean Paul & Anne-Marie which now sits at #2, Starboy has 4 Rae Sremmurd | UMA stuck it out and finally taken the crown. Vying for #1 since the very first issue of the Australian Singles Scars to your beautiful Report and published Artist Top 50, Starboy’s peak at #1 isn’t as clear cut as previous chart toppers. 5 Alessia Cara | UMA Capsize The biggest push for Starboy has always come from Spotify. Now on its eighth week topping the 6 Frenship | SME streaming service’s Australian chart, the rest of the music platforms have finally followed suit.Starboy Don't Wanna Know 7 Maroon 5 | UMA holds its peak at #2 on the iTunes chart as well as the Hot 100. With no shared #1 across either Starvi n g platforms, it’s been given a rare opportunity to rise. 8 Hailee Steinfeld | UMA Last week’s #1, Rockabye, is still #1 on the iTunes chart and #2 on Spotify, but has dropped to #5 on after the afterparty 9 Charli XCX | WMA the Hot 100. It’s still unclear whether there will be one definitive ‘summer anthem’ that makes itself Catch 22 known over the Christmas break. -

Rock Music Is a Genre of Popular Music That Entered the Mainstream in the 1950S
Rock music is a genre of popular music that entered the mainstream in the 1950s. It has its roots in 1940s and 1950s rock and roll, rhythm and blues, country music and also drew on folk music, jazz and classical music. The sound of rock often revolves around the electric guitar, a back beat laid down by a rhythm section of electric bass guitar, drums, and keyboard instruments such as Hammond organ, piano, or, since the 1970s, synthesizers. Along with the guitar or keyboards, saxophone and blues-style harmonica are sometimes used as soloing instruments. In its "purest form", it "has three chords, a strong, insistent back beat, and a catchy melody."[1] In the late 1960s and early 1970s, rock music developed different subgenres. When it was blended with folk music it created folk rock, with blues to create blues-rock and with jazz, to create jazz-rock fusion. In the 1970s, rock incorporated influences from soul, funk, and Latin music. Also in the 1970s, rock developed a number of subgenres, such as soft rock, glam rock, heavy metal, hard rock, progressive rock, and punk rock. Rock subgenres that emerged in the 1980s included new wave, hardcore punk and alternative rock. In the 1990s, rock subgenres included grunge, Britpop, indie rock, and nu metal. A group of musicians specializing in rock music is called a rock band or rock group. Many rock groups consist of an electric guitarist, lead singer, bass guitarist, and a drummer, forming a quartet. Some groups omit one or more of these roles or utilize a lead singer who plays an instrument while singing, sometimes forming a trio or duo; others include additional musicians such as one or two rhythm guitarists or a keyboardist. -

A Fast-Moving Storm
University of Kentucky UKnowledge Theses and Dissertations--English English 2017 A FAST-MOVING STORM Amanda Kelley Corbin University of Kentucky, [email protected] Digital Object Identifier: https://doi.org/10.13023/ETD.2017.207 Right click to open a feedback form in a new tab to let us know how this document benefits ou.y Recommended Citation Corbin, Amanda Kelley, "A FAST-MOVING STORM" (2017). Theses and Dissertations--English. 58. https://uknowledge.uky.edu/english_etds/58 This Master's Thesis is brought to you for free and open access by the English at UKnowledge. It has been accepted for inclusion in Theses and Dissertations--English by an authorized administrator of UKnowledge. For more information, please contact [email protected]. STUDENT AGREEMENT: I represent that my thesis or dissertation and abstract are my original work. Proper attribution has been given to all outside sources. I understand that I am solely responsible for obtaining any needed copyright permissions. I have obtained needed written permission statement(s) from the owner(s) of each third-party copyrighted matter to be included in my work, allowing electronic distribution (if such use is not permitted by the fair use doctrine) which will be submitted to UKnowledge as Additional File. I hereby grant to The University of Kentucky and its agents the irrevocable, non-exclusive, and royalty-free license to archive and make accessible my work in whole or in part in all forms of media, now or hereafter known. I agree that the document mentioned above may be made available immediately for worldwide access unless an embargo applies. -

Sooloos Collections: Advanced Guide
Sooloos Collections: Advanced Guide Sooloos Collectiions: Advanced Guide Contents Introduction ...........................................................................................................................................................3 Organising and Using a Sooloos Collection ...........................................................................................................4 Working with Sets ..................................................................................................................................................5 Organising through Naming ..................................................................................................................................7 Album Detail ....................................................................................................................................................... 11 Finding Content .................................................................................................................................................. 12 Explore ............................................................................................................................................................ 12 Search ............................................................................................................................................................. 14 Focus .............................................................................................................................................................. -

Grammy® Awards 2018
60th Annual Grammy Awards - 2018 Record Of The Year Childish Gambino $13.98 Awaken My Love. Glassnote Records GN 20902 UPC: 810599021405 Contents: Me and Your Mama -- Have Some Love -- Boogieman -- Zombies -- Riot -- Redbone -- California -- Terrified -- Baby Boy -- The Night Me and Your Mama Met -- Stand Tall. http://www.tfront.com/p-449560-awaken-my-love.aspx Luis Fonsi $20.98 Despacito & Mis Grandes Exitos. Universal Records UNIV 5378012 UPC: 600753780121 Contents: Despacito -- Despacito (Remix) [Feat. Justin Bieber] -- Wave Your Flag [Feat. Luis Fonsi] -- Corazón en la Maleta -- Llegaste TÚ [Feat. Juan Luis Guerra] -- Tentación -- Explícame -- http://www.tfront.com/p-449563-despacito-mis-grandes-exitos.aspx Jay-Z. $13.98 4:44. Roc Nation Records ROCN B002718402 UPC: 854242007583 Contents: Kill Jay-Z -- The Story of O.J -- Smile -- Caught Their Eyes -- (4:44) -- Family Feud -- Bam -- Moonlight -- Marcy Me -- Legacy. http://www.tfront.com/p-449562-444.aspx Kendrick Lamar $13.98 Damn [Explicit Content]. Aftermath / Interscope Records AFTM B002671602 UPC: 602557611755 OCLC Number: 991298519 http://www.tfront.com/p-435550-damn-explicit-content.aspx Bruno Mars $18.98 24k Magic. Atlantic Records ATL 558305 UPC: 075678662737 http://www.tfront.com/p-449564-24k-magic.aspx Theodore Front Musical Literature, Inc. ● 26362 Ruether Avenue ● Santa Clarita CA 91350-2990 USA Tel: (661) 250-7189 Toll-Free: (844) 350-7189 Fax: (661) 250-7195 ● [email protected] ● www.tfront.com - 1 - 60th Annual Grammy Awards - 2018 Album Of The Year Childish Gambino $13.98 Awaken My Love. Glassnote Records GN 20902 UPC: 810599021405 Contents: Me and Your Mama -- Have Some Love -- Boogieman -- Zombies -- Riot -- Redbone -- California -- Terrified -- Baby Boy -- The Night Me and Your Mama Met -- Stand Tall. -

Distant Music: Recorded Music, Manners, and American Identity Jacklyn Attaway
Florida State University Libraries Electronic Theses, Treatises and Dissertations The Graduate School 2012 Distant Music: Recorded Music, Manners, and American Identity Jacklyn Attaway Follow this and additional works at the FSU Digital Library. For more information, please contact [email protected] THE FLORIDA STATE UNIVERSITY COLLEGE OF ARTS AND SCIENCES DISTANT MUSIC: RECORDED MUSIC, MANNERS, AND AMERICAN IDENTITY By JACKLYN ATTAWAY A Thesis submitted to the American and Florida Studies Program in the Department of Humanities in partial fulfillment of the requirements for the degree of Master of Arts Degree Awarded: Fall Semester, 2012 Jacklyn Attaway defended this thesis on November 5, 2012 The members of the supervisory committee were: Barry J. Faulk Professor Directing Thesis Neil Jumonville Committee Member Jerrilyn McGregory Committee Member The Graduate School has verified and approved the above-named committee members, and certifies that the dissertation has been approved in accordance with university requirements. ii I dedicate this to Stuart Fletcher, a true heir-ethnographer who exposed me to the deepest wells of cultural memory in the recorded music format; Shawn Christy, for perking my interest in the musicians who exhibited the hauntological aesthetic effect; and to all the members of WVFS Tallahassee, 89.7 FM—without V89, I probably would not have ever written about music. Thank you all so much for the knowledge, love, and support. iii ACKNOWLEDGEMENTS I would like to acknowledge Dr. Barry J. Faulk, Dr. Neil Jumonville, Dr. Jerrilyn McGregory, Leon Anderson, Dr. John Fenstermaker, Peggy Wright-Cleveland, Ben Yadon, Audrey Langham, Andrew Childs, Micah Vandegrift, Nicholas Yanes, Mara Ginnane, Jason Gibson, Stuart Fletcher, Dr. -

PUNK KUULUU KAIKILLE! Punk-Kokoelman Kartoitus, Arviointi Ja Esiintuominen Oulun Kaupunginkirjastossa
Veli-Pekka Marjoniemi PUNK KUULUU KAIKILLE! Punk-kokoelman kartoitus, arviointi ja esiintuominen Oulun kaupunginkirjastossa. PUNK KUULUU KAIKILLE! Punk-kokoelman kartoitus, arviointi ja esiintuominen Oulun kaupunginkirjastossa. Veli-Pekka Marjoniemi Opinnäytetyö Kevät 2018 Kirjasto- ja tietopalveluala Oulun ammattikorkeakoulu TIIVISTELMÄ Oulun ammattikorkeakoulu Kirjasto- ja tietopalvelualan tutkinto-ohjelma Tekijä: Veli-Pekka Marjoniemi Opinnäytetyön nimi: Punk kuuluu kaikille! Punk-kokoelman kartoitus, arviointi ja esiintuominen Ou- lun kaupunginkirjastossa. Työn ohjaaja: Teija Harju Työn valmistumislukukausi- ja vuosi: Kevät 2018 Sivumäärä: 57 + 6 Opinnäytteeni aiheena on Oulun kaupunginkirjaston punk-kokoelman kehittäminen. Oulun kaupunginkirjasto on osa OUTI-kimppaa, johon kuuluu kaikkiaan viisitoista eri kaupungin- ja kunnankirjastoa. Koska OUTI-kirjastoilla on yhteinen aineisto- ja lainaajarekisteri, on työssä otettu huomioon kirjastojen muodostama yhteiskokoelma. Opinnäytetyö on tehty kuitenkin Oulun näkökulmasta, ja joiltain osin (karsinta, tarroitus, punkhylly) se keskittyy vain Oulun pääkirjaston musiikkiosastoon. Työssä keskitytään CD-levyihin, rajauksesta päätettiin yhdessä toimeksiantajan kanssa. Työssä on kaksi keskeistä tavoitetta: punk-kokoelman kehittäminen ja musiikin löydettävyyden parantaminen. Punk-kokoelman kehittämisessä hyödynnän Evansin mallia, jonka kuusi osa-aluetta käyn yksitellen läpi. Tärkeimpinä tuloksina kehittämisessä voidaan pitää tekemääni kokoelma- arviota, sekä sen pohjalta tehtyjä valinta- ja karsintalistoja. -

Triple J Hottest 100 of the Decade Voting List: AZ Artists
triple j Hottest 100 of the Decade voting list: A-Z artists ARTIST SONG 360 Just Got Started {Ft. Pez} 360 Boys Like You {Ft. Gossling} 360 Killer 360 Throw It Away {Ft. Josh Pyke} 360 Child 360 Run Alone 360 Live It Up {Ft. Pez} 360 Price Of Fame {Ft. Gossling} #1 Dads So Soldier {Ft. Ainslie Wills} #1 Dads Two Weeks {triple j Like A Version 2015} 6LACK That Far A Day To Remember Right Back At It Again A Day To Remember Paranoia A Day To Remember Degenerates A$AP Ferg Shabba {Ft. A$AP Rocky} (2013) A$AP Rocky F**kin' Problems {Ft. Drake, 2 Chainz & Kendrick Lamar} A$AP Rocky L$D A$AP Rocky Everyday {Ft. Rod Stewart, Miguel & Mark Ronson} A$AP Rocky A$AP Forever {Ft. Moby/T.I./Kid Cudi} A$AP Rocky Babushka Boi A.B. Original January 26 {Ft. Dan Sultan} Dumb Things {Ft. Paul Kelly & Dan Sultan} {triple j Like A Version A.B. Original 2016} A.B. Original 2 Black 2 Strong Abbe May Karmageddon Abbe May Pony {triple j Like A Version 2013} Action Bronson Baby Blue {Ft. Chance The Rapper} Action Bronson, Mark Ronson & Dan Auerbach Standing In The Rain Active Child Hanging On Adele Rolling In The Deep (2010) Adrian Eagle A.O.K. Adrian Lux Teenage Crime Afrojack & Steve Aoki No Beef {Ft. Miss Palmer} Airling Wasted Pilots Alabama Shakes Hold On Alabama Shakes Hang Loose Alabama Shakes Don't Wanna Fight Alex Lahey You Don't Think You Like People Like Me Alex Lahey I Haven't Been Taking Care Of Myself Alex Lahey Every Day's The Weekend Alex Lahey Welcome To The Black Parade {triple j Like A Version 2019} Alex Lahey Don't Be So Hard On Yourself Alex The Astronaut Not Worth Hiding Alex The Astronaut Rockstar City triple j Hottest 100 of the Decade voting list: A-Z artists Alex the Astronaut Waste Of Time Alex the Astronaut Happy Song (Shed Mix) Alex Turner Feels Like We Only Go Backwards {triple j Like A Version 2014} Alexander Ebert Truth Ali Barter Girlie Bits Ali Barter Cigarette Alice Ivy Chasing Stars {Ft. -

Augmented Renaissance: from Creation to Revelation Christopher Atkinson Louisiana State University and Agricultural and Mechanical College
Louisiana State University LSU Digital Commons LSU Master's Theses Graduate School 2015 Augmented Renaissance: From Creation to Revelation Christopher Atkinson Louisiana State University and Agricultural and Mechanical College Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_theses Part of the Theatre and Performance Studies Commons Recommended Citation Atkinson, Christopher, "Augmented Renaissance: From Creation to Revelation" (2015). LSU Master's Theses. 3378. https://digitalcommons.lsu.edu/gradschool_theses/3378 This Thesis is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Master's Theses by an authorized graduate school editor of LSU Digital Commons. For more information, please contact [email protected]. AUGMENTED RENAISSANCE: FROM CREATION TO REVELATION A Thesis Submitted to the Graduate Faculty of the Louisiana State University and Agricultural and Mechanical College in partial fulfillment of the requirements for the degree of Master of Fine Arts in The Department of Theatre by Christopher A. Atkinson B.A., Albany State University, 2012 May 2015 Acknowledgment I would first like to thank my Lord and Savior, Jesus Christ, who is the head of my life. To my Mother and Father: Words can ‘t begin to express how grateful I am to be your son. You’ve instilled pivotal attributes in me that shaped and molded me into the man that I am today. I marvel at your unwavering support and I love you from the bottom of my heart and depths of my soul! To Shelby Atkinson: We bump heads constantly, but I appreciate you being such a fantastic little sister.