Morphological Cross Reference Method for English to Telugu Transliteration
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Technical Reference Manual for the Standardization of Geographical Names United Nations Group of Experts on Geographical Names
ST/ESA/STAT/SER.M/87 Department of Economic and Social Affairs Statistics Division Technical reference manual for the standardization of geographical names United Nations Group of Experts on Geographical Names United Nations New York, 2007 The Department of Economic and Social Affairs of the United Nations Secretariat is a vital interface between global policies in the economic, social and environmental spheres and national action. The Department works in three main interlinked areas: (i) it compiles, generates and analyses a wide range of economic, social and environmental data and information on which Member States of the United Nations draw to review common problems and to take stock of policy options; (ii) it facilitates the negotiations of Member States in many intergovernmental bodies on joint courses of action to address ongoing or emerging global challenges; and (iii) it advises interested Governments on the ways and means of translating policy frameworks developed in United Nations conferences and summits into programmes at the country level and, through technical assistance, helps build national capacities. NOTE The designations employed and the presentation of material in the present publication do not imply the expression of any opinion whatsoever on the part of the Secretariat of the United Nations concerning the legal status of any country, territory, city or area or of its authorities, or concerning the delimitation of its frontiers or boundaries. The term “country” as used in the text of this publication also refers, as appropriate, to territories or areas. Symbols of United Nations documents are composed of capital letters combined with figures. ST/ESA/STAT/SER.M/87 UNITED NATIONS PUBLICATION Sales No. -

Download Download
Judaica Librarianship Volume 9 Number 1–2 17-28 12-31-1995 Climbing Benjacob's Ladder: An Evaluation of Vinograd's Thesaurus of the Hebrew Book Roger S. Kohn Library of Congress, Washington, DC, [email protected] Follow this and additional works at: http://ajlpublishing.org/jl Part of the Bilingual, Multilingual, and Multicultural Education Commons, Information Literacy Commons, Jewish Studies Commons, and the Reading and Language Commons Recommended Citation Kohn, Roger S.. 1995. "Climbing Benjacob's Ladder: An Evaluation of Vinograd's Thesaurus of the Hebrew Book." Judaica Librarianship 9: 17-28. doi:10.14263/2330-2976.1178. , Association of Jewish Libraries, 30th Annual Convention, Chicago '.! I APPROBATIONS Climbing -Benjacob's Ladder: An Evaluation of Vinograd's Thesaurus of the Hebrew Book* Rogers.Kohn Stanford University Libraries Stanford, CA [Vinograd, Yeshayahu. Otsar ha-sefer ha '/vri: reshimat ha-sefarim she :,~yn ,.!>t,n ,~lN •ln,yw, ,,,n:m nidpesu be-ot '/vrit me 11,~y nuo W.!rTlWc,,.non 1ltl'W1 , reshit ha-def us ha- '/vri bi-shenat 229 (1469) 'ad· ""!:nmvr.i ~Yn Ol.!rTn 11,wNitl shenat 623 (186~. :c,~wl,, .(1863) l"!:>111nlW ;y C1469) Yerushalayim: ha-Makhon ,mwmtltl m.nill'~~~ 1l~tln le-bibliyografyah .n"lW1l·i"lW1l memuhshevet, 754-5, c1993-1995]. Vinograd, Yeshayahu. Abstract: The Thesaurus of the Hebrew The foremost French bibliographer of the Thesaurus of the Hebrew Book, by Yeshayahu Vinograd, is re previous generation, Louise-Noelle Malcles viewed in the context of both general (1899-1977), defines the term bibliography Book: Listing of Books bibliography and of general Hebraica thus: printed in Hebrew Letters bibliography. -

Hebrew Names and Name Authority in Library Catalogs by Daniel D
Hebrew Names and Name Authority in Library Catalogs by Daniel D. Stuhlman BHL, BA, MS LS, MHL In support of the Doctor of Hebrew Literature degree Jewish University of America Skokie, IL 2004 Page 1 Abstract Hebrew Names and Name Authority in Library Catalogs By Daniel D. Stuhlman, BA, BHL, MS LS, MHL Because of the differences in alphabets, entering Hebrew names and words in English works has always been a challenge. The Hebrew Bible (Tanakh) is the source for many names both in American, Jewish and European society. This work examines given names, starting with theophoric names in the Bible, then continues with other names from the Bible and contemporary sources. The list of theophoric names is comprehensive. The other names are chosen from library catalogs and the personal records of the author. Hebrew names present challenges because of the variety of pronunciations. The same name is transliterated differently for a writer in Yiddish and Hebrew, but Yiddish names are not covered in this document. Family names are included only as they relate to the study of given names. One chapter deals with why Jacob and Joseph start with “J.” Transliteration tables from many sources are included for comparison purposes. Because parents may give any name they desire, there can be no absolute rules for using Hebrew names in English (or Latin character) library catalogs. When the cataloger can not find the Latin letter version of a name that the author prefers, the cataloger uses the rules for systematic Romanization. Through the use of rules and the understanding of the history of orthography, a library research can find the materials needed. -

Run Date: 08/30/21 12Th District Court Page
RUN DATE: 09/27/21 12TH DISTRICT COURT PAGE: 1 312 S. JACKSON STREET JACKSON MI 49201 OUTSTANDING WARRANTS DATE STATUS -WRNT WARRANT DT NAME CUR CHARGE C/M/F DOB 5/15/2018 ABBAS MIAN/ZAHEE OVER CMV V C 1/01/1961 9/03/2021 ABBEY STEVEN/JOH TEL/HARASS M 7/09/1990 9/11/2020 ABBOTT JESSICA/MA CS USE NAR M 3/03/1983 11/06/2020 ABDULLAH ASANI/HASA DIST. PEAC M 11/04/1998 12/04/2020 ABDULLAH ASANI/HASA HOME INV 2 F 11/04/1998 11/06/2020 ABDULLAH ASANI/HASA DRUG PARAP M 11/04/1998 11/06/2020 ABDULLAH ASANI/HASA TRESPASSIN M 11/04/1998 10/20/2017 ABERNATHY DAMIAN/DEN CITYDOMEST M 1/23/1990 8/23/2021 ABREGO JAIME/SANT SPD 1-5 OV C 8/23/1993 8/23/2021 ABREGO JAIME/SANT IMPR PLATE M 8/23/1993 2/16/2021 ABSTON CHERICE/KI SUSPEND OP M 9/06/1968 2/16/2021 ABSTON CHERICE/KI NO PROOF I C 9/06/1968 2/16/2021 ABSTON CHERICE/KI SUSPEND OP M 9/06/1968 2/16/2021 ABSTON CHERICE/KI NO PROOF I C 9/06/1968 2/16/2021 ABSTON CHERICE/KI SUSPEND OP M 9/06/1968 8/04/2021 ABSTON CHERICE/KI OPERATING M 9/06/1968 2/16/2021 ABSTON CHERICE/KI REGISTRATI C 9/06/1968 8/09/2021 ABSTON TYLER/RENA DRUGPARAPH M 7/16/1988 8/09/2021 ABSTON TYLER/RENA OPERATING M 7/16/1988 8/09/2021 ABSTON TYLER/RENA OPERATING M 7/16/1988 8/09/2021 ABSTON TYLER/RENA USE MARIJ M 7/16/1988 8/09/2021 ABSTON TYLER/RENA OWPD M 7/16/1988 8/09/2021 ABSTON TYLER/RENA SUSPEND OP M 7/16/1988 8/09/2021 ABSTON TYLER/RENA IMPR PLATE M 7/16/1988 8/09/2021 ABSTON TYLER/RENA SEAT BELT C 7/16/1988 8/09/2021 ABSTON TYLER/RENA SUSPEND OP M 7/16/1988 8/09/2021 ABSTON TYLER/RENA SUSPEND OP M 7/16/1988 8/09/2021 ABSTON -

Download This PDF File
Cyrillic Transliteration and Its Users Alena L. Aissing A wide diversity exists in the current practice of transliterating Cyrillic scripts for use in bibliographic records in online catalogs. Without knowing which transliteration table was used, it is difficult to retrieve the desired record successfully or efficiently. Retrieving an item (e.g., titles or an author's name) from a library's online catalog (OPAC) where it is given only in transliterated form can be a confusing task, even for users who know the Russian language or at least the Cyrillic alphabet. This study explores the problems besetting three groups of Russian-language students faced with romanized Cyrillic bib liographic records. It also tries to investigate students' ability in searching the Russian records romanized according to the Library of Congress (LC) translit eration table. Analysis of the test results show the students' success-and-error rate before and after instruction. The findings of this study establish that transliteration is one of the factors limiting access _by Russian language stu dents to the Slavic collections. tudents in foreign language eration needs to be distinguished from classes usually experience transcription, in which the sounds of the various difficulties in finding source words are conveyed by letters in library materials in the lan the target language. For example, an guages they study.1 One of the most in English transcription of former Presi tractable problems confronts readers of dent Mikhail Gorbachev's name would Russian, since records they want to ac have to be Gorbachoff, to reflect the way cess have been modified (i.e, romanized) it·is pronounced in Russian.2 by transliteration or transcription into There are several different translitera the Roman (English) alphabet. -

Curriculum Vitae Roger E. Olson Present Position and Address
CURRICULUM VITAE ROGER E. OLSON PRESENT POSITION AND ADDRESS Professor of Theology, George W. Truett Theological Seminary, Baylor University (1999- present); P.O. Box 97126, Waco, TX 76798. BIOGRAPHY AND PERSONAL INFORMATION Born in Des Moines, Iowa February 2, 1952. Raised in Pastor's home. Graduated from High School in Sioux Falls, South Dakota in 1970. Married Becky Jeanne Sandahl in 1973. Two children: Sonja Kristen and Amanda Joy. Interested in geography and current events, amateur photography, bowling, gardening and gospel music. EDUCATION B.A. in Biblical and Theological Studies, Open Bible College, Des Moines, Iowa, 1974 (magna cum laude) M.A. in Religious Studies, North American Baptist Seminary, Sioux Falls, South Dakota, 1978 (magna cum laude) M.A. in Religious Studies, Rice University, Houston, Texas, 1982 ("With Honor") Ph.D. in Religious Studies, Rice University, Houston, Texas, 1984 Courses in German language and culture: University of Houston, Houston, Texas, 1980; Goethe Institute, Munich, West Germany, 1981; University of Munich, 1981 Graduate courses in Theology: SHALOM (Center for Continuing Theological Studies), Sioux Falls, South Dakota, 1975 and 1976; Bethel Theological Seminary, St. Paul, Minnesota, 1985 Research and studies at the Institut für Ökumene und Fundamentaltheologie of the Evangelische Fakultät of the University of Munich (Prof. Dr. Wolfhart Pannenberg, Chairman), Munich, West Germany, 1981-1982 SCHOLARSHIPS, FELLOWSHIPS, AND GRANTS Full Tuition Scholarships and Teaching Assistantships, Rice University, Houston, Texas, 1978-1981 University Fellowship for Overseas Study, Rice University, Houston, Texas, 1981-1982 Faculty Development Grant for research on nineteenth and twentieth century theology, 1988 Alumni Grant for research and development of companion volume of readings for book 1 Roger E. -

Temein Languages Comparative Wordlist
Comparative Temein wordlists Roger Blench Mallam Dendo 8, Guest Road Cambridge CB1 2AL United Kingdom Voice/ Ans 0044-(0)1223-560687 Mobile worldwide (00-44)-(0)7967-696804 E-mail [email protected] http://www.rogerblench.info/RBOP.htm Notes: 1. The principal source for these wordlists are the material collected by Roland Stevenson in the 1970s and early 1980s. For further details see the accompanying paper ‘The Temein languages’. Also incorporated are lexical items form the phonology of T(h)ese by May Yip (2004) and from the unpublished notes of Gerrit Dimmendaal. The materials should therefore be treated as provisional. 2. The comparisons in the final column have been added by Roger Blench and are cross-cited from comparative sources, principally materials from Stevenson. As a consequence, they have not yet been checked against the originals, and newer data that has appeared since Stevenson. I hope to do this in future. 3. Identifying cognates in Nilo-Saharan is not simple; it depends on the analysis of the affixes. In the case of Temein, these are multiple and combined with syllable deletion, can often mean that only a single consonant remains, even between singular and plural in Temein. The comparisons will generally show what element of the word I speculate is the underlying root. But further analysis may change this and thereby the words that are cognate elsewhere. 4. It will be seen that the classification of Temein is far from obvious; although it has slightly more cognates with East Sudanic than other branches of Nilo-Saharan, there are, for example, an elevated number of cognates with Berta. -

Epigraphy, Philology, and the Hebrew Bible
EPIGRAPHY, PHILOLOGY, & THE HEBREW BIBLE Methodological Perspectives on Philological & Comparative Study of the Hebrew Bible in Honor of Jo Ann Hackett Edited by Jeremy M. Hutton and Aaron D. Rubin Ancient Near East Monographs – Monografías sobre el Antiguo Cercano Oriente Society of Biblical Literature Centro de Estudios de Historia del Antiguo Oriente (UCA) EPIGRAPHY, PHILOLOGY, AND THE HEBREW BIBLE Ancient Near East Monographs General Editors Ehud Ben Zvi Roxana Flammini Alan Lenzi Juan Manuel Tebes Editorial Board: Reinhard Achenbach Esther J. Hamori Steven W. Holloway René Krüger Steven L. McKenzie Martti Nissinen Graciela Gestoso Singer Number 12 EPIGRAPHY, PHILOLOGY, AND THE HEBREW BIBLE Methodological Perspectives on Philological and Comparative Study of the Hebrew Bible in Honor of Jo Ann Hackett Edited by Jeremy M. Hutton and Aaron D. Rubin SBL Press Atlanta Copyright © 2015 by SBL Press All rights reserved. No part of this work may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying and recording, or by means of any information storage or retrieval system, except as may be expressly permit- ted by the 1976 Copyright Act or in writing from the publisher. Requests for permission should be addressed in writing to the Rights and Permissions Office, SBL Press, 825 Hous- ton Mill Road, Atlanta, GA 30329 USA. Library of Congress has catologued the print edition: Names: Hackett, Jo Ann, honouree. | Hutton, Jeremy Michael, editor. | Rubin, Aaron D., 1976- editor. Title: Epigraphy, philology, and the Hebrew Bible : methodological perspectives on philological and comparative study of the Hebrew Bible in honor of Jo Ann Hackett / edited by Jeremy M. -

Soziologie – Sociology in the German-Speaking World
Soziologie – Sociology in the German-Speaking World Soziologie — Sociology in the German-Speaking World Special Issue Soziologische Revue 2020 Edited by Betina Hollstein, Rainer Greshoff, Uwe Schimank, and Anja Weiß ISBN 978-3-11-062333-8 e-ISBN (PDF) 978-3-11-062727-5 e-ISBN (EPUB) 978-3-11-062351-2 ISSN 0343-4109 DOI https://doi.org/10.1515/9783110627275 This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License. For details go to https://creativecommons.org/licenses/by-nc-nd/4.0/ Library of Congress Control Number: 2020947720 Bibliographic information published by the Deutsche Nationalbibliothek The Deutsche Nationalbibliothek lists this publication in the Deutsche Nationalbibliografie; detailed bibliographic data are available on the Internet at http://dnb.dnb.de. © 2021 Betina Hollstein, Rainer Greshoff, Uwe Schimank, and Anja Weiß, published by Walter de Gruyter GmbH, Berlin/Boston Printing and binding: CPI books GmbH, Leck www.degruyter.com Contents ACompanion to German-Language Sociology 1 Culture 9 Uta Karstein and Monika Wohlrab-Sahr Demography and Aging 27 FrançoisHöpflinger EconomicSociology 39 AndreaMaurer Education and Socialization 53 Matthias Grundmann Environment 67 Anita Engels Europe 83 Monika Eigmüller Family and IntimateRelationships 99 Dirk Konietzka, Michael Feldhaus, Michaela Kreyenfeld, and Heike Trappe (Felt) Body.Sports, Medicine, and Media 117 Robert Gugutzerand Claudia Peter Gender 133 Paula-Irene Villa and Sabine Hark Globalization and Transnationalization 149 Anja Weiß GlobalSouth 165 EvaGerharz and Gilberto Rescher HistoryofSociology 181 Stephan Moebius VI Contents Life Course 197 Johannes Huinink and Betina Hollstein Media and Communication 211 Andreas Hepp Microsociology 227 RainerSchützeichel Migration 245 Ludger Pries Mixed-Methods and MultimethodResearch 261 FelixKnappertsbusch, Bettina Langfeldt, and Udo Kelle Organization 273 Raimund Hasse Political Sociology 287 Jörn Lamla Qualitative Methods 301 Betina Hollstein and Nils C. -

Ammon in the Hebrew Bible: a Textual Analysis and Archaeological Context of Selected References to the Ammonites of Transjordan
Andrews University Digital Commons @ Andrews University Dissertations Graduate Research 1998 Ammon in the Hebrew Bible: a Textual Analysis and Archaeological Context of Selected References to the Ammonites of Transjordan James Roger Fisher Andrews University Follow this and additional works at: https://digitalcommons.andrews.edu/dissertations Part of the Biblical Studies Commons, History of Art, Architecture, and Archaeology Commons, and the Near Eastern Languages and Societies Commons Recommended Citation Fisher, James Roger, "Ammon in the Hebrew Bible: a Textual Analysis and Archaeological Context of Selected References to the Ammonites of Transjordan" (1998). Dissertations. 50. https://digitalcommons.andrews.edu/dissertations/50 This Dissertation is brought to you for free and open access by the Graduate Research at Digital Commons @ Andrews University. It has been accepted for inclusion in Dissertations by an authorized administrator of Digital Commons @ Andrews University. For more information, please contact [email protected]. Thank you for your interest in the Andrews University Digital Library of Dissertations and Theses. Please honor the copyright of this document by not duplicating or distributing additional copies in any form without the author’s express written permission. Thanks for your cooperation. INFORMATION TO USERS This manuscript has been reproduced from the microfilm master. UMI films the text directly from the original or copy submitted. Thus, some thesis and dissertation copies are in typewriter face, while others may be from any type of computer printer. The quality of this reproduction is dependent upon the quality of the copy submitted. Broken or indistinct print, colored or poor quality illustrations and photographs, print bleedthrough, substandard margins, and improper alignment can adversely afreet reproduction. -
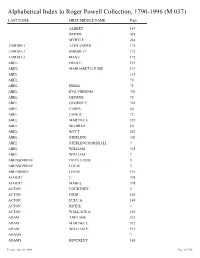
Alphabetical Index to Roger Powell Collection, 1790-1996 (M 037) LAST NAME FIRST/MIDDLE NAME Page
Alphabetical Index to Roger Powell Collection, 1790-1996 (M 037) LAST NAME FIRST/MIDDLE NAME Page ALBERT 147 BERTIE 424 MYRTLE 268 CORNELL ALEXANDER 172 CORNELL HARRIETT 172 CORNELL IRENE 172 ABEE FRED E. 139 ABEE MARGARET LOUISE 139 ABEL 318 ABEL 70 ABEL EMMA 72 ABEL EVA VIRGINIA 302 ABEL GEORGE 72 ABEL GEORGE F. 323 ABEL JAMES 60 ABEL JANE D. 72 ABEL MARTHA E. 323 ABEL MILDRED 60 ABEL ROY T. 253 ABEL STERLING 302 ABEL STERLING MARSHALL 7 ABEL WILLIAM 318 ABEL WILLIAM 7 ABENSCHIENE DEAN LOUIS 5 ABENSCHIENE LOUIS 5 ABENSHIEN LOUIS 110 ACHERT C. 398 ACHERT MABEL 398 ACTON COURTNEY 5 ACTON JOHN 150 ACTON LULU A. 169 ACTON RICH E. 3 ACTON WALLACE A. 150 ADAM ADELANE 512 ADAM MARTHA L. 512 ADAM WILLIAM F. 512 ADAMS 7 ADAMS BEVERLEY 160 Tuesday, June 02, 2009 Page 1 of 468 LAST NAME FIRST/MIDDLE NAME Page ADAMS CARLOS 512 ADAMS DELL 395 ADAMS EDITH 324 ADAMS EDWIN CARL 2 ADAMS ELIZ. 17 ADAMS ELLA 225 ADAMS ELLA 354 ADAMS ELLA 70 ADAMS F. MASON 160 ADAMS MARY T. 118 ADAMS O. BUFORD 188 ADIE FANNIE 149 ADIE FANNIE A. 142 ADIE FRANCES 189 ADIE FRANCES A. 179 ADIE JAMES 149 ADIE JENNIE 62 ADKINS DOROTHY 2 ADKINS LESTER ALFRED 2 ADLER MATILDA 161 ADLER MATILDA 169 ADLER MAURICE 169 ADLER MAURICE E. 161 ADLER MAURICE J. 161 ADLER MAURICE J. 169 ADRAIN 3 ADRAIN ADA 174 ADRAIN ADA CONSTANCE 417 ADRAIN ANNIE 3 ADRAIN DOROTHY ELIZ. 3 ADRAIN EDITH 7 ADRAIN EUGENE 152 ADRAIN EUGENE 5 ADRAIN EUGENE S. -

Germans in Kansas
Review Essay Series GERMANS IN KANSAS Eleanor L. Turk he history of Kansas presents a color- EDITORS’INTRODUCTION ful mosaic of peoples and events and Our original vision for this essay can be studied from many perspec- series included widening our knowl- tives. Perhaps the richest of these is edge of well-known historical topics Tthe history of the peoples who have resided in and how historians have treated them, drawing our attention to new the state and built it: the Native Americans who topics, new methods, and new inter- have lived here through the ages; the migrants pretations. We hoped the essays from the eastern and southern states, driven by would reflect historians’ ongoing their concept of “manifest destiny” to incorpo- search for a more complete and in- rate Kansas Territory into their new nation; the sightful understanding of our past Border Ruffians and Jayhawkers who fought to and suggest new research directions. define its political and social character; the Exo- Dr. Eleanor Turk’s essay meets these expectations admirably. dusters from the South who hoped to find a Turk discusses older works that peaceful haven for African Americans in “free” share many characteristics. In partic- Kansas after the Civil War; and the thousands ular they focus almost exclusively on upon thousands of Europeans, lured by the migration and settlement. We learn prospects of land and independence, who chose why European Germans and Russ- to leave their ancient homelands for the chal- ian Germans came to this country and where they settled in Kansas. lenges of the American frontier.