Extraction of Statistically Significant Malware Behaviors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A the Hacker
A The Hacker Madame Curie once said “En science, nous devons nous int´eresser aux choses, non aux personnes [In science, we should be interested in things, not in people].” Things, however, have since changed, and today we have to be interested not just in the facts of computer security and crime, but in the people who perpetrate these acts. Hence this discussion of hackers. Over the centuries, the term “hacker” has referred to various activities. We are familiar with usages such as “a carpenter hacking wood with an ax” and “a butcher hacking meat with a cleaver,” but it seems that the modern, computer-related form of this term originated in the many pranks and practi- cal jokes perpetrated by students at MIT in the 1960s. As an example of the many meanings assigned to this term, see [Schneier 04] which, among much other information, explains why Galileo was a hacker but Aristotle wasn’t. A hack is a person lacking talent or ability, as in a “hack writer.” Hack as a verb is used in contexts such as “hack the media,” “hack your brain,” and “hack your reputation.” Recently, it has also come to mean either a kludge, or the opposite of a kludge, as in a clever or elegant solution to a difficult problem. A hack also means a simple but often inelegant solution or technique. The following tentative definitions are quoted from the jargon file ([jargon 04], edited by Eric S. Raymond): 1. A person who enjoys exploring the details of programmable systems and how to stretch their capabilities, as opposed to most users, who prefer to learn only the minimum necessary. -

1.Computer Virus Reported (1) Summary for This Quarter
Attachment 1 1.Computer Virus Reported (1) Summary for this Quarter The number of the cases reported for viruses*1 in the first quarter of 2013 decreased from that of the fourth quarter of 2012 (See Figure 1-1). As for the number of the viruses detected*2 in the first quarter of 2013, W32/Mydoom accounted for three-fourths of the total (See Figure 1-2). Compared to the fourth quarter of 2012, however, both W32/Mydoom and W32/Netsky showed a decreasing trend. When we looked into the cases reported for W32/Netsky, we found that in most of those cases, the virus code had been corrupted, for which the virus was unable to carry out its infection activity. So, it is unlikely that the number of cases involving this virus will increase significantly in the future As for W32/IRCbot, it has greatly decreased from the level of the fourth quarter of 2012. W32/IRCbot carries out infection activities by exploiting vulnerabilities within Windows or programs, and is often used as a foothold for carrying out "Targeted Attack". It is likely that that there has been a shift to attacks not using this virus. XM/Mailcab is a mass-mailing type virus that exploits mailer's address book and distributes copies of itself. By carelessly opening this type of email attachment, the user's computer is infected and if the number of such users increases, so will the number of the cases reported. As for the number of the malicious programs detected in the first quarter of 2013, Bancos, which steals IDs/Passwords for Internet banking, Backdoor, which sets up a back door on the target PC, and Webkit, which guides Internet users to a maliciously-crafted Website to infect with another virus, were detected in large numbers. -

Detecting Botnets Using File System Indicators
Detecting botnets using file system indicators Master's thesis University of Twente Author: Committee members: Peter Wagenaar Prof. Dr. Pieter H. Hartel Dr. Damiano Bolzoni Frank Bernaards LLM (NHTCU) December 12, 2012 Abstract Botnets, large groups of networked zombie computers under centralised control, are recognised as one of the major threats on the internet. There is a lot of research towards ways of detecting botnets, in particular towards detecting Command and Control servers. Most of the research is focused on trying to detect the commands that these servers send to the bots over the network. For this research, we have looked at botnets from a botmaster's perspective. First, we characterise several botnet enhancing techniques using three aspects: resilience, stealth and churn. We see that these enhancements are usually employed in the network communications between the C&C and the bots. This leads us to our second contribution: we propose a new botnet detection method based on the way C&C's are present on the file system. We define a set of file system based indicators and use them to search for C&C's in images of hard disks. We investigate how the aspects resilience, stealth and churn apply to each of the indicators and discuss countermeasures botmasters could take to evade detection. We validate our method by applying it to a test dataset of 94 disk images, 16 of which contain C&C installations, and show that low false positive and false negative ratio's can be achieved. Approaching the botnet detection problem from this angle is novel, which provides a basis for further research. -

System Center Endpoint Protection for Mac
System Center Endpoint Protection for Mac Installation Manual and User Guide Contents Context menu 19 System Center Endpoint Protection 3 System requirements 3 Advanced user 20 Import and export settings 20 Installation 4 Import settings 20 Typical installation 4 Export settings 20 Proxy server setup 20 Custom installation 4 Removable media blocking 20 Uninstallation 5 21 Beginners guide 6 Glossary Types of infiltrations 21 User interface 6 Viruses 21 Checking operation of the system 6 Worms 21 What to do if the program does not work properly 7 Trojan horses 21 Work with System Center Endpoint Adware 22 Spyware 22 Protection 8 Potentially unsafe applications 22 Antivirus and antispyware protection 8 Potentially unwanted applications 22 Real-time file system protection 8 Real-time Protection setup 8 Scan on (Event triggered scanning) 8 Advanced scan options 8 Exclusions from scanning 8 When to modify Real-time protection configuration 9 Checking Real-time protection 9 What to do if Real-time protection does not work 9 On-demand computer scan 10 Type of scan 10 Smart scan 10 Custom scan 11 Scan targets 11 Scan profiles 11 Engine parameters setup 12 Objects 12 Options 12 Cleaning 13 Extensions 13 Limits 13 Others 13 An infiltration is detected 14 Updating the program 14 Update setup 15 How to create update tasks 15 Upgrading to a new build 15 Scheduler 16 Purpose of scheduling tasks 16 Creating new tasks 16 Creating user-defined task 17 Quarantine 17 Quarantining files 17 Restoring from Quarantine 17 Log files 18 Log maintenance 18 Log filtering 18 User interface 18 Alerts and notifications 19 Alerts and notifications advanced setup 19 Privileges 19 System Center Endpoint Protection As the popularity of Unix-based operating systems increases, malware authors are developing more threats to target Mac users. -

Computer Viruses, in Order to Detect Them
Behaviour-based Virus Analysis and Detection PhD Thesis Sulaiman Amro Al amro This thesis is submitted in partial fulfilment of the requirements for the degree of Doctor of Philosophy Software Technology Research Laboratory Faculty of Technology De Montfort University May 2013 DEDICATION To my beloved parents This thesis is dedicated to my Father who has been my supportive, motivated, inspired guide throughout my life, and who has spent every minute of his life teaching and guiding me and my brothers and sisters how to live and be successful. To my Mother for her support and endless love, daily prayers, and for her encouragement and everything she has sacrificed for us. To my Sisters and Brothers for their support, prayers and encouragements throughout my entire life. To my beloved Family, My Wife for her support and patience throughout my PhD, and my little boy Amro who has changed my life and relieves my tiredness and stress every single day. I | P a g e ABSTRACT Every day, the growing number of viruses causes major damage to computer systems, which many antivirus products have been developed to protect. Regrettably, existing antivirus products do not provide a full solution to the problems associated with viruses. One of the main reasons for this is that these products typically use signature-based detection, so that the rapid growth in the number of viruses means that many signatures have to be added to their signature databases each day. These signatures then have to be stored in the computer system, where they consume increasing memory space. Moreover, the large database will also affect the speed of searching for signatures, and, hence, affect the performance of the system. -

2007 Threat Report | 2008 Threat and Technology Forecast Executive Summary
2007 Threat Report | 2008 Threat and Technology Forecast Executive Summary Last year, Trend Micro’s 2006 Annual Roundup As we highlight the threats that made rounds and 2007 Forecast (The Trend of Threats Today) in 2007, it will become clear that all of these predicted the full emergence of Web threats predictions have indeed materialized, and some as the prevailing security threat in 2007. Web in an interesting fashion. threats include a broad array of threats that The shifting threat landscape demands a move operate through the Internet, typically comprise away from the traditional concept of malicious more than one fi le component, spawn a large code. Digital threats today cover more ground number of variants, and target a relatively smaller than ever. They may come to a user through audience. This was predicted to continue the simply having a vulnerable PC, visiting trusted “high focus/low spread” themes seen by some Web sites that are silently compromised, clicking attacks in 2006. an innocent-looking link, or by belonging to a Trend Micro also predicted that the growth and network that is under attack by a Distributed expansion of botnets during 2007 would be Denial of Service attacker. mostly based on new methods, ingenious social In the following roundup, Trend Micro summarizes engineering, and the exploitation of software the threats, malware trends, and security vulnerabilities. The roundup also indicated highlights seen during 2007. Real-life victims of that crimeware would continue to increase and these security threats include interest groups, become the prevailing threat motivation in 2007 individuals, organizations, and on some occasions and onwards. -

Vmwatcher.Pdf
Stealthy Malware Detection and Monitoring through VMM-Based “Out-of-the-Box” 12 Semantic View Reconstruction XUXIAN JIANG North Carolina State University XINYUAN WANG George Mason University and DONGYAN XU Purdue University An alarming trend in recent malware incidents is that they are armed with stealthy techniques to detect, evade, and subvert malware detection facilities of the victim. On the defensive side, a fundamental limitation of traditional host-based antimalware systems is that they run inside the very hosts they are protecting (“in-the-box”), making them vulnerable to counter detection and subversion by malware. To address this limitation, recent solutions based on virtual machine (VM) technologies advocate placing the malware detection facilities outside of the protected VM (“out-of- the-box”). However, they gain tamper resistance at the cost of losing the internal semantic view of the host, which is enjoyed by “in-the-box” approaches. This poses a technical challenge known as the semantic gap. In this article, we present the design, implementation, and evaluation of VMwatcher—an “out- of-the-box” approach that overcomes the semantic gap challenge. A new technique called guest view casting is developed to reconstruct internal semantic views (e.g., files, processes, and ker- nel modules) of a VM nonintrusively from the outside. More specifically, the new technique casts semantic definitions of guest OS data structures and functions on virtual machine monitor (VMM)- level VM states, so that the semantic view can be reconstructed. Furthermore, we extend guest view casting to reconstruct details of system call events (e.g., the process that makes the system This work was supported in part by the US National Science Foundation (NSF) under Grants CNS-0716376, CNS-0716444 and CNS-0546173. -

CONTENTS in THIS ISSUE Fighting Malware and Spam
JANUARY 2008 Fighting malware and spam CONTENTS IN THIS ISSUE 2 COMMENT MONITORING THE NET A richer, but more dangerous web Despite the best efforts of the IT security industry it looks like the 3 NEWS malicious bot is here to Guidelines issued for UK hacker tool ban stay. Andrei Gherman looks at how botnet monitoring can provide information about bots as 3 VIRUS PREVALENCE TABLE well as helping to keep the threat under control. page 4 FEATURES HIJACKED IN A FLASH 4 Botnet monitoring As malicious web ads become increasingly 9 Rule-driven malware identification and classification common, Dennis Elser and Micha Pekrul take a close look at a Flash advertising banner belonging 12 Inside rogue Flash ads to the SWF.AdHijack family. page 12 16 CALL FOR PAPERS OUTPOST IN THE SPOTLIGHT VB2008 John Hawes discovers how firewall expert Agnitum has fared after having added malware detection to 17 PRODUCT REVIEW its Outpost Security Suite. Agnitum Outpost Security Suite Pro 2008 page 17 22 END NOTES & NEWS This month: anti-spam news and events, and Martin Overton looks at how malware authors have started to borrow techniques from phishers. ISSN 1749-7027 COMMENT “The accessing of The accessing of media-rich, collaborative sites by employees is already cause for concern in terms of both media-rich, employee productivity and security. Businesses and collaborative sites individuals are creating and uploading content to the web with little or no control over what is hosted, and this by employees is trend is set to increase. As businesses capitalize on RIAs already cause for by expanding their online services, more and more data will be stored online – and as the explosion in social concern.” networking has already shown us, the more opportunities Mark Murtagh, Websense the Internet gives us, the more points of access it gives criminals. -

Reporting Status of Computer Virus - Details for January 2010
Attachment 1 Reporting Status of Computer Virus - Details for January 2010 I. Details for Reported Number of Virus 1. Detection Number of Virus by Month 2. Reported Number of Virus by Month 1 Attachment 1 3. Reported Number of Virus/Year 2 Attachment 1 4. Reported Virus in January 2010 The total reported virus type was 54: The virus count for Windows/DoS relevant with 1,111 and for Macro and Script relevant with 43. i) Windows (*) = newly emerged virus for the month. Windows/DOS Virus Reported Number Windows/DOS Virus Reported Number W32/Netsky 216 W32/Mota 1 W32/Mydoom 213 W32/Neeris 1 W32/Autorun 154 W32/Pinit 1 W32/Mytob 96 W32/Sohanad 1 W32/Downad 67 W32/Stration 1 W32/Mumu 57 Sub Total 1,111 W32/Klez 55 W32/Virut 43 Script Virus Reported Number W32/Bagle 40 VBS/Solow 12 W32/Lovegate 25 VBS/SST 10 W32/Gammima 22 VBS/Redlof 3 W32/Mywife 20 VBS/Freelink 1 W32/Sality 18 VBS/LOVELETTER 1 W32/Gaobot 12 Sub Total 27 W32/Zafi 9 W32/Funlove 6 Macro Virus Reported Number W32/Mabezat 5 XM/Laroux 13 W32/Bugbear 4 WM/Cap 1 W32/Koobface 4 X97M/Divi 1 W32/Whybo 4 XF/Sic 1 W32/Bagz 3 Sub Total 16 W32/Chir 3 W32/Harakit 3 ii) Macintosh W32/Mimail 3 None W32/Palevo 3 W32/Waledac 3 iii) OSS (OpenSource Software): Linux, BSD Anti-CMOS 2 inculusive of UNIX W32/Almanahe 2 None W32/Fakerecy 2 W32/Nimda 2 iv) Mobile Terminal Cascade 1 None Form 1 <Reference> W32/Antinny 1 Windows/DOS Virus: work under Windows, W32/Bacterra 1 MS-DOS environment. -

Computer Virus / Unauthorized Computer Access Incident Report
Attachment 1 1.Computer Virus Reported (1) Summary for this Quarter The number of the cases reported for viruses*1 in the third quarter of 2012 decreased from that of the second quarter of 2012 (See Figure 1-1). By virus type, W32/Mydoom was reported most. As for XM/Laroux which is a type of macro virus, although the number of the cases reported decreased from that of the second quarter of 2012, it had slightly been increasing since the second quarter of 2011 (See Figure 1-2). This is due to the spread of infection by the subspecies of XM/Laroux. Meanwhile, the number of the cases reported for W32/Autorun decreased to one-third of that of the second quarter of 2011. This is because the "Autorun" function, which is often exploited for W32/Autorun infection, came to be disabled*2 automatically by a security patch for Windows. As for the number of the viruses detected*3 in the third quarter of 2012, W32/Mydoom accounted for over half of the total; it was on the increase (See Figure 1-3). On the contrary, W32/Netsky was on the decrease and in the second quarter of 2012 and later, it was outpaced by W32/Mydoom in terms of both the number of the cases reported and the number of the viruses detected. W32/Mydoom and W32/Netsky attach copies of themselves to an e-mail attachment, with the goal of spreading infection to the recipients of such e-mail. It is assumed that there are still a large number of the servers and PCs that are infected with these viruses. -

Open Sirinda Main Final.Pdf
The Pennsylvania State University The Graduate School College of Engineering A FRAMEWORK FOR MINING SIGNIFICANT SUBGRAPHS AND ITS APPLICATION IN MALWARE ANALYSIS A Dissertation in Computer Science and Engineering by Sirinda Palahan © 2014 Sirinda Palahan Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy August 2014 The dissertation of Sirinda Palahan was reviewed and approved∗ by the following: Daniel Kifer Assistant Professor of Computer Science and Engineering Dissertation Advisor, Chair of Committee Robert Collins Associate Professor of Computer Science and Engineering John Hannan Associate Professor of Computer Science and Engineering C. Lee Giles David Reese Professor of Information Sciences and Technology Lee Coraor Associate Professor of Computer Science and Engineering, Graduate Officer ∗Signatures are on file in the Graduate School. ii Abstract The growth of graph data has encouraged research in graph mining algorithms, especially subgraph pattern mining from graph databases. Discovered patterns could help researchers understand inherent properties and characteristics in large and complex graphs. Frequent subgraph mining has been widely applied successfully in many applications, such as mining network motifs in a complex network, identifying malicious behaviors or mining biochemical structures. However, the high frequency of a subgraph does not always indicate that a subgraph is statistically significant. In this dissertation, we propose a framework for mining statistically significant subgraphs. Our framework is based on a new method for measuring the statistical significance of subgraphs. Given a training set of graphs from two classes (e.g., positive and negative graphs), our method utilizes the class labels provided in the training data to calculate p-values. -
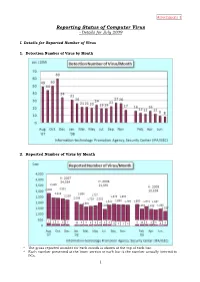
Reporting Status of Computer Virus - Details for July 2009
Attachment 1 Reporting Status of Computer Virus - Details for July 2009 I. Details for Reported Number of Virus 1. Detection Number of Virus by Month 2. Reported Number of Virus by Month * The gross reported number for each month is shown at the top of each bar. * Each number presented at the lower section of each bar is the number actually infected to PCs. 1 Attachment 1 3. Reported Number of Virus/Year 2 Attachment 1 4. Reported Virus in July 2009 The total reported virus type in July was 50: The virus counts for Windows/DoS relevant was 1,220 and for Macro and Script relevant was 36. i) Windows (*) = newly emerged virus for the month. Windows/DOS Virus Reported Number Windows/DOS Virus Reported Number W32/Netsky 312 W32/Licum 1 W32/Mydoom 200 W32/Magistr 1 W32/Mytob 113 W32/Waledac 1 W32/Bagle 95 W32/Welchia 1 W32/Autorun 77 W32/Klez 73 Sub Total 1,220 W32/Downad 59 W32/Mimail 22 Script Virus Reported Number W32/Bugbear 21 VBS/Solow 27 W32/Mywife 21 VBS/Redlof 2 W32/Zafi 19 VBS/Freelink 1 W32/Funlove 18 VBS/LOVELETTER 1 W32/Gammima 14 VBS/SST 1 W32/Womble 9 W32/Harakit 7 Sub Total 32 W32/Rontokbro 5 W32/Stration 3 Macro Virus Reported Number W32/Bagz 2 XM/Laroux 3 W32/Joydotto 2 X97M/Yini 1 W32/Mabezat 2 W32/Mabutu 2 Sub Total 4 W32/Nimda 2 W32/Nuwar 2 ii) Macintosh W32/Parite 2 None W32/Rinbot 2 W32/Sobig 2 iii) OSS*: incl.