A Covariance Structural Analysis of a Conceptual Neighborhood Model
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
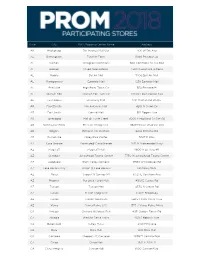
Prom 2018 Event Store List 1.17.18
State City Mall/Shopping Center Name Address AK Anchorage 5th Avenue Mall-Sur 406 W 5th Ave AL Birmingham Tutwiler Farm 5060 Pinnacle Sq AL Dothan Wiregrass Commons 900 Commons Dr Ste 900 AL Hoover Riverchase Galleria 2300 Riverchase Galleria AL Mobile Bel Air Mall 3400 Bell Air Mall AL Montgomery Eastdale Mall 1236 Eastdale Mall AL Prattville High Point Town Ctr 550 Pinnacle Pl AL Spanish Fort Spanish Fort Twn Ctr 22500 Town Center Ave AL Tuscaloosa University Mall 1701 Macfarland Blvd E AR Fayetteville Nw Arkansas Mall 4201 N Shiloh Dr AR Fort Smith Central Mall 5111 Rogers Ave AR Jonesboro Mall @ Turtle Creek 3000 E Highland Dr Ste 516 AR North Little Rock Mc Cain Shopg Cntr 3929 Mccain Blvd Ste 500 AR Rogers Pinnacle Hlls Promde 2202 Bellview Rd AR Russellville Valley Park Center 3057 E Main AZ Casa Grande Promnde@ Casa Grande 1041 N Promenade Pkwy AZ Flagstaff Flagstaff Mall 4600 N Us Hwy 89 AZ Glendale Arrowhead Towne Center 7750 W Arrowhead Towne Center AZ Goodyear Palm Valley Cornerst 13333 W Mcdowell Rd AZ Lake Havasu City Shops @ Lake Havasu 5651 Hwy 95 N AZ Mesa Superst'N Springs Ml 6525 E Southern Ave AZ Phoenix Paradise Valley Mall 4510 E Cactus Rd AZ Tucson Tucson Mall 4530 N Oracle Rd AZ Tucson El Con Shpg Cntr 3501 E Broadway AZ Tucson Tucson Spectrum 5265 S Calle Santa Cruz AZ Yuma Yuma Palms S/C 1375 S Yuma Palms Pkwy CA Antioch Orchard @Slatten Rch 4951 Slatten Ranch Rd CA Arcadia Westfld Santa Anita 400 S Baldwin Ave CA Bakersfield Valley Plaza 2501 Ming Ave CA Brea Brea Mall 400 Brea Mall CA Carlsbad Shoppes At Carlsbad -

IN the SUPREME COURT of OHIO STATE of OHIO, : Case No. 2014-0313 : Appellee, : : Death Penalty Case - Vs - : : RICHARD JAMES BEASLEY, : : Appellant
Supreme Court of Ohio Clerk of Court - Filed February 06, 2015 - Case No. 2014-0313 IN THE SUPREME COURT OF OHIO STATE OF OHIO, : Case No. 2014-0313 : Appellee, : : Death Penalty Case - vs - : : RICHARD JAMES BEASLEY, : : Appellant. : On Appeal from the Summit County Court of Common Pleas Summit County, Ohio, Case No. CR201201069 MERIT BRIEF OF APPELLEE STATE OF OHIO SHERRI BEVAN WALSH (#0030038) TYSON FLEMING* (#0073135) Summit County Prosecutor *Counsel of Record 53 University Avenue OHIO PUBLIC DEFENDER’S OFFICE Akron, OH 44308 250 E. Broad Street, Suite 1400 330-643-2800 (voice) Columbus, OH 43215 330-643-8277 (facsimile) 614-644-9651 (voice) 614-644-0708 (facsimile) Special Assistant Summit County Prosecutor [email protected] THOMAS E. MADDEN (#0077069) DANIEL PAUL JONES (#0041224) Senior Assistant Attorney General OHIO PUBLIC DEFENDER’S OFFICE 150 E. Gay Street, 16th Floor 250 E. Broad Street, Suite 14001 Columbus, OH 43215 Columbus, OH 43215 614-995-3234 (voice) 614-466-5394 (voice) 866-239-5489 (facsimile) 614-644-0708 (facsimile) [email protected] [email protected] STEPHEN MAHER* (#0032279) RANDALL LEE PORTER (#0005835) *Counsel of Record OHIO PUBLIC DEFENDER’S OFFICE Senior Assistant Attorney General 250 E. Broad Street, Suite 1400 [email protected] Columbus, OH 43215 614-466-5394 (voice) Counsel for Appellee, State of Ohio 614-644-0708 (facsimile) [email protected] Counsel for Appellant, Richard Beasley TABLE OF CONTENTS TABLE OF CONTENTS ................................................................................................................ -

The Afterlife of Malls
The Afterlife of Malls John Drain INTRODUCTION teenage embarrassments and rejection, along with fonder It seems like it was yesterday: Grandpa imagined the search memories – from visiting Mall Santa to getting fitted for my for some new music would distract him from an illness prom tux. that was reaching its terminal stage. This meant a trip to the Rolling Acres Mall at Akron’s western fringe; probably Some spectators interpret the decline of malls as a signal the destination was a Sam Goody, which in 1996 was as that auto-oriented suburban sprawl is finally unwinding. synonymous with record store as iTunes is with music today. Iconoclasts might attribute their abrupt collapse to a Grandpa bought a couple tapes and then happily strolled conspiracy of “planned obsolescence,” or even declare this the mall concourse. But his relief quickly faded; he slowed a symptom of a decadent society. Some will fault today’s his clip and sidled into a composite bench-planter on a politics or the Great Recession (anachronistically, in most carpeted oasis, confessing, “I am so tired.” cases). Some attribute the decline to a compromised sense of safety among crowds of people who aren’t exposed Grandpa and his cohort – the rubber workers – have mostly to an intensive security screening (certainly the violent vanished from Akron. The Rolling Acres Mall is abandoned. incidents in Ward Parkway Mall in Kansas City2 or the City The so-called “shadow retail” that gradually built up around Center in Columbus3 lend some credence to this view that the mall is today the shadow of a ghost. -

Analysis and Evaluation of the Spatial Structure of Cittaslow Towns on the Example of Selected Regions in Central Italy and North-Eastern Poland
land Article Analysis and Evaluation of the Spatial Structure of Cittaslow Towns on the Example of Selected Regions in Central Italy and North-Eastern Poland Marek Zagroba , Katarzyna Pawlewicz and Adam Senetra * Department of Socio-Economic Geography, Faculty of Geoengineering, University of Warmia and Mazury in Olsztyn, Prawoche´nskiego15, 10-720 Olsztyn, Poland; [email protected] (M.Z.); [email protected] (K.P.) * Correspondence: [email protected]; Tel.: +48-89-5234948 Abstract: Cittaslow International promotes harmonious development of small towns based on sustainable relationships between economic growth, protection of local traditions, cultural heritage and the environment, and an improvement in the quality of local life. The aim of this study was to analyze and evaluate the differences and similarities in the spatial structure of Cittaslow towns in the Italian regions of Tuscany and Umbria and the Polish region of Warmia and Mazury. The study examined historical towns which are situated in different parts of Europe and have evolved in different cultural and natural environments. The presented research attempts to determine whether the spatial structure of historical towns established in different European regions promotes the dissemination of the Cittaslow philosophy and the adoption of sustainable development principles. The urban design, architectural features and the composition of urban and architectural factors which Citation: Zagroba, M.; are largely responsible for perceptions of multi-dimensional space were evaluated. These goals were Pawlewicz, K.; Senetra, A. Analysis achieved with the use of a self-designed research method which supported a subjective evaluation and Evaluation of the Spatial of spatial structure defined by historical urban planning and architectural solutions. -

The Functions of a Capital City: Williamsburg and Its "Public Times," 1699-1765
W&M ScholarWorks Dissertations, Theses, and Masters Projects Theses, Dissertations, & Master Projects 1980 The functions of a capital city: Williamsburg and its "Public Times," 1699-1765 Mary S. Hoffschwelle College of William & Mary - Arts & Sciences Follow this and additional works at: https://scholarworks.wm.edu/etd Part of the United States History Commons Recommended Citation Hoffschwelle, Mary S., "The functions of a capital city: Williamsburg and its "Public Times," 1699-1765" (1980). Dissertations, Theses, and Masters Projects. Paper 1539625107. https://dx.doi.org/doi:10.21220/s2-ja0j-0893 This Thesis is brought to you for free and open access by the Theses, Dissertations, & Master Projects at W&M ScholarWorks. It has been accepted for inclusion in Dissertations, Theses, and Masters Projects by an authorized administrator of W&M ScholarWorks. For more information, please contact [email protected]. THE FUNCTIONS OF A CAPITAL CITY: »» WILLIAMSBURG AND ITS "PUBLICK T I M E S 1699-1765 A Thesis Presented to The Faculty of the Department of History The College of William and Mary in Virginia In Partial Fulfillment Of the Requirements for the Degree of Master of Arts by Mary S„ Hoffschwelle 1980 APPROVAL SHEET This thesis is submitted in partial fulfillment of the requirements for the degree of Master of Arts Mary S. Hoffschwelle Approved, August 1980 i / S A /] KdJL, C.£PC„ Kevin Kelly Q TABLE OF CONTENTS Page ABSTRACT ........................... ................... iv CHAPTER I. THEORETICAL BACKGROUND ........................... 2 CHAPTER II. THE URBAN IMPULSE IN COLONIAL VIRGINIA AND ITS IMPLEMENTATION ........................... 14 CHAPTER III. THE CAPITAL ACQUIRES A LIFE OF ITS OWN: PUBLIC TIMES ................... -

09 WBB Guide.Indd
TABLE OF CONTENTS GENERAL INFORMATION Table of Contents 1 City of Akron, Ohio 2 The Akron Advantage 3 Colleges and Law School 4 Diversity and Student Support 5 Dr. Luis M. Proenza, President 6 2009 Board of Trustees 7 This is Akron Basketball 8-9 This is Rhodes Arena 10-11 UA Athletics Mission Statement / Athlete Involvement 12 Akron Athletics Accomplishments 13 COACHING STAFF Head Coach Jodi Kest 14-15 Associate Head Coach Curtis Loyd 16 Assistant Coaches / Support Staff 16-17 2009-10 SEASON PREVIEW Roster Information 20 TV / Radio Roster 21 Season Outook 22-23 Returner Profiles 24-39 Newcomer Profiles 40-41 MAC Composite Schedule 42 Opponent Information / Lodging Schedule 43 2008-09 SEASON REVIEW Season Statistics 46-49 Career Game-by-Game 50-51 Game Recaps / Box Scores 52-61 AKRON RECORDS & HISTORY All-Time Letterwinners 63 Annual Leaders 64-65 Team Records 66 Single-Game Records 67 Season Records 68 Career Records / All-Americans / Coaching History 69 Team Records 70 Postseason History 71 Year-by-Year Team Statistics 72 All-Time Series Records 73 Year-by-Year Results 74-78 THE UNIVERSITY Quick Facts / Media Policies 80 Tom Wistrcill / Senior Staff 81 ISP Sports Network 82 ISP / Corporate Sponsors 83 Staff Directory 84-85 Mid-American Conference 86-87 Media Outlets 88 CREDITS Writing, Layout and Design: Paul Warner Editorial Assistance: Amanda Aller, Gregg Bach, Mike Cawood Cover Design: David Morris, The Berry Company Photography: John Ashley, Jeff Harwell Printing: Herald Printing (New Washington, Ohio) Follow Akron women’s Basketball on the offi cial web site of UA athletics, www.GoZips.com. -

RICHARD BEASLEY Appellant
rii %^^L IN THE SUPREME COURT OF OHIO STATE OF OHIO Appellee, CASE NO. 14-0313 -vs- RICHARD BEASLEY Death Penalty Case Appellant. ;"I' ". R ';l H; ; On Appeal from the Court of Common Pleas, Summit, Ohio Case No. CR-2012 01 0169(A) APPENDIX TO MERI'I' BRIEF OF APPELLANT RICHARD BEASLEY Office of the Summit County Prosecutor Office of the Ohio Public Defender SHERI BEVAN-WALSH - 0012084 RANDALL PORTER - 0005835 Hamilton County Prosecutor Assistant State Public Defender Office of the Summit County Prosecutor TYSON FLEMING - 0073135 Summit County Safety Building Assistant State Public Defender 53 University Avenue, 6th Floor Akron, Ohio 44308 DANIEL JONES - 0041224 (330) 643-7459 Assistant State Public Defender and Office of the Ohio Public Defender 250 East Broad St., Suite 1400 THOMAS E. MADDEN - 0077019 Columbus, Ohio 43215 Counsel of Record (614) 466-5394 (614) 644-0708 (FAX) STEPHEN MAHER - 0032279 Randall.Portergopd.ohio. gov. Tyson.Flemingkopd.ohio.gov Special Summit County Prosecutors Daniel.Jones(cr,opd.ohio. ov Office of the Ohio Attorney General 150 E. Gay Street, 16th Floor Columbus, Ohio 43215 (614) 728-7055 COUNSEL FOR APPELLEE COUNSEL FOR APPELLANT INDEX TO APPENDIX OF RICHARD BEASLEY Notice of Appeal ............................................................................................................. A-1 Journal Entry ................................................................................................................... A-4 Sentencing Opinion ...................................................................................................... -

Environmental Pressures and Population Concentration
AMBIVALENCES AND ASYMMETRIES IN THE URBANIZATION PROCESS IN THE GULF OF MEXICO: ENVIRONMENTAL PRESSURES AND POPULATION CONCENTRATION Cuauhtémoc León and Hipólito Rodríguez FRAMEWORK: A DEFINITION OF THIS SPACE Three different countries surround this great marine water body; human activities both inland and in coastal zones and marine areas have modified, and will continue to modify this space’s biochemical, ecosystemic and, of course, socio-economic conditions. Such activities can be formally identified as the Gulf of Mexico’s economic and social space. From a historical perspective, they have had certain common traits and have perhaps been evolving at different intensities, but at least in a parallel fashion. The pace of changes has left marks shaping the landscape that can be “read,” yet unfortunately, in most instances these comprise an expansion and sequence of deleterious transformations. The boundaries of the Gulf of Mexico and, therefore, of what is considered to be its coastal zone, were defined a priori. Actually, they are of an operational nature so as to be able to deal simultaneously with three dimensions: the terrestrial landscape analyzed as ecoregions; socio-demographic dynamics studied on the basis of municipalities (or counties); and urban cores or cities, which enable us to easily visualize population concentration. Thus, the coastal zone was delimited as a mostly terrestrial strip having municipal boundaries (and therefore jurisdictional ones) and landscape features. As a result, this is not necessarily a region in the economic or geographic sense but rather, most likely, it is composed of asymmetrical, disconnected, and perhaps complementary territorial and political units which at most depend upon one another to a certain degree. -

Internal Structure of the City " Brian J
INTERNAL STRUCTURE OF THE CITY " BRIAN J. L. BERRY- I INTRODUCTION: EXTERNAL DETERIMINANTS OF INTERNAL STRUCTUE Cities are the central elements in spatial organization of regional, national, and supranational socioeconomies by virtue of the interregional organization in a total "ecological field" of the functions they perform.' In a specialized society economic activities are undertaken by design, or survive in the market place, at those locations which afford the greatest competitive advantage. Among these activities, those most efficiently performed in limited local concentrations provide the basic support for cities. The location theorist commonly classifies locally-concentrated economic activi- ties into those which are raw material oriented, those located at points which are intermediate between raw materials and markets, and those which are market oriented.2 Raw material orientation includes direct exploitation of resources and the processing of raw materials, and its character is that of the developed resource en- dowment of different places. Activities in intermediate locations are usually of a processing kind, involved in intermediate and final processing and transformation of raw materials, and most frequently locate at some favorable spot on the transport network, such as an assembly point, a gateway, a break-of-bulk point, or a port. Market oriented activities may be secondary (for example, where there is a weight gain involved in the final processing of raw materials on intermediates prior to de- livery), but are dominantly tertiary, concerned with the direct service of the con- suming population through wholesale, retail, and service functions. The consuming population comprises the workers in the other specialized activities, of course, plus the local population supported by the tertiary trades. -

CBL & Associates Properties 2012 Annual Report
COVER PROPERTIES : Left to Right/Top to Bottom MALL DEL NORTE, LAREDO, TX CROSS CREEK MALL, FAYETTEVILLE, NC BURNSVILLE CENTER, BURNSVILLE, MN OAK PARK MALL, KANSAS CITY, KS CBL & Associates Properties, Inc. 2012 Annual When investors, business partners, retailers Report CBL & ASSOCIATES PROPERTIES, INC. and shoppers think of CBL they think of the leading owner of market-dominant malls in CORPORATE OFFICE BOSTON REGIONAL OFFICE DALLAS REGIONAL OFFICE ST. LOUIS REGIONAL OFFICE the U.S. In 2012, CBL once again demon- CBL CENTER WATERMILL CENTER ATRIUM AT OFFICE CENTER 1200 CHESTERFIELD MALL THINK SUITE 500 SUITE 395 SUITE 750 CHESTERFIELD, MO 63017-4841 strated why it is thought of among the best 2030 HAMILTON PLACE BLVD. 800 SOUTH STREET 1320 GREENWAY DRIVE (636) 536-0581 THINK 2012 Annual Report CHATTANOOGA, TN 37421-6000 WALTHAM, MA 02453-1457 IRVING, TX 75038-2503 CBLCBL & &Associates Associates Properties Properties, 2012 Inc. Annual Report companies in the shopping center industry. (423) 855-0001 (781) 398-7100 (214) 596-1195 CBLPROPERTIES.COM HAMILTON PLACE, CHATTANOOGA, TN: Our strategy of owning the The 2012 CBL & Associates Properties, Inc. Annual Report saved the following resources by printing on paper containing dominant mall in SFI-00616 10% postconsumer recycled content. its market helps attract in-demand new retailers. At trees waste water energy solid waste greenhouse gases waterborne waste Hamilton Place 5 1,930 3,217,760 214 420 13 Mall, Chattanooga fully grown gallons million BTUs pounds pounds pounds shoppers enjoy the market’s only Forever 21. COVER PROPERTIES : Left to Right/Top to Bottom MALL DEL NORTE, LAREDO, TX CROSS CREEK MALL, FAYETTEVILLE, NC BURNSVILLE CENTER, BURNSVILLE, MN OAK PARK MALL, KANSAS CITY, KS CBL & Associates Properties, Inc. -

The Urban History of Osaka
City, Culture and Society 3 (2012) 1–8 Contents lists available at SciVerse ScienceDirect City, Culture and Society journal homepage: www.elsevier.com/locate/ccs Introduction The Urban History of Osaka Introduction in the 1960s. They attempted instead to illuminate the struc- tural features of the Japanese feudal system, which, unlike In this special issue, we examine the city of Osaka, an the Europe’s decentralized feudal system, was characterized urban area with a long history. Focusing on a range of by strong centralization. Much of the research on cities con- themes, this volume attempts to reconstruct the historical ducted during this period focused on the place of the city and world of Osaka’s ‘‘urban lower classes’’ (toshi kaso¯). The its significance within the broader feudal system. While the authors who have contributed articles have taken special research initiated in the 1960s produced some important re- care to explain the perspectives and methods that they have sults, it failed to sufficiently examine the internal structure employed in support of their analyses. In addition, many of cities and reconstruct the world of the urban masses consider the significance of the topics that they address in (Tsukada, 1997). That limitation was only overcome in the a comparative historical context. 1980s, when scholars of urban history once again shifted fo- During the early modern period, Osaka was a ‘‘mega- cus and began to examine the significance of the lives of the castle town’’ (kyo¯dai jo¯kamachi), which at its peak had a people who inhabited early modern cities. The work of Yos- population of 400,000. -

Do the Suburbs Exist? Discovering Complexity and Specificity In
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by UCL Discovery Do the suburbs exist? Discovering complexity and specificity in suburban built form This is a pre-publication version of a paper to be published in Transactions of the Institute of British Geographers in October 2009. Authors: Laura Vaughan,1 Sam Griffiths,1 Mordechai (Muki) Haklay2 and Catherine (Kate) Emma Jones2 1The Bartlett School of Graduate Studies, University College London, 1-19 Torrington Place, London, WC1E 7HB. 2 Department of Civil, Environmental and Geomatic Engineering, University College London, Gower Street, London, WC1E 6BT. Tel. +44 (0)20 7679 4188 Fax + 44 (0)207 9161887. www.sstc.ucl.ac.uk Abstract In human geography cities are routinely acknowledged as complex and dynamic built environments. This description is rarely extended to the suburbs, which are generally regarded as epiphenomena of the urbs and therefore of little intrinsic theoretical interest in themselves. This article presents a detailed critique of this widely held assumption by showing how the idea of ‘the suburban’ as an essentially non-problematic domain has been perpetuated from a range of contrasting disciplinary perspectives, including those which directly address suburban subject matter. The result has been that attempts to articulate the complex social possibilities of suburban space are easily caught between theories of urbanisation that are insensitive to suburban specificity and competing representations of the suburb that rarely move beyond the culturally specific to consider their generic significance. This article proposes that the development of a distinctively suburban theory would help to undermine one- dimensional approaches to the built environment, by focusing on the relationship between social organisation and the dynamics of emergent built form.